RabbitMQ中Exchange、Queue和Binding的原理与应用
发布时间: 2023-12-30 15:13:09 阅读量: 34 订阅数: 19 
# 第一章:RabbitMQ简介
## 1.1 RabbitMQ的概念和作用
RabbitMQ是一个开源的消息中间件,它实现了AMQP(Advanced Message Queuing Protocol)协议。作为分布式系统中重要的组件之一,RabbitMQ提供了可靠的消息传递机制,能够在不同的应用程序之间传递数据。
RabbitMQ的作用主要体现在以下几个方面:
- 解耦:通过使用RabbitMQ,可以实现生产者和消费者之间的解耦。生产者只需要将消息发送到RabbitMQ中,而无需关心消息具体是如何被消费者处理的。
- 异步通信:RabbitMQ可以实现异步通信,生产者和消费者之间不需要直接进行通信,而是通过消息队列进行消息传递,提高了系统的并发性能。
- 消息持久化:RabbitMQ提供了消息的持久化功能,即使在RabbitMQ服务器出现故障时,也能够保证消息的可靠性传递。
- 负载均衡:RabbitMQ支持多个消费者同时消费一个队列中的消息,能够实现负载均衡,提高系统的处理能力。
## 1.2 RabbitMQ的核心组件和特点
RabbitMQ由以下几个核心组件构成:
- Producer(生产者):负责发送消息到RabbitMQ中。
- Exchange(交换机):接收从生产者发送的消息,并根据规则路由到相应的队列中。
- Queue(消息队列):存储从Exchange接收到的消息,等待消费者进行消费。
- Consumer(消费者):从队列中获取消息,并进行相应的处理。
RabbitMQ的特点包括:
- 可靠性:RabbitMQ通过持久化消息和ACK机制来保证消息的可靠传递。
- 灵活性:RabbitMQ通过Exchange和Binding的方式实现消息的灵活路由和分发。
- 可扩展性:RabbitMQ支持集群和分布式部署,可以根据实际需求进行扩展和高可用性部署。
- 应用广泛:RabbitMQ作为一个开源的消息中间件,被广泛应用于分布式系统、微服务架构、物联网等场景。
## 1.3 RabbitMQ在分布式系统中的应用
在分布式系统中,RabbitMQ通常被用于以下几个方面:
- 异步任务处理:当系统中需要处理耗时的任务时,可以将任务封装成消息发送到RabbitMQ中,由消费者异步处理,提高系统的并发性能。
- 发布/订阅模式:通过使用不同的Exchange和Binding类型,可以实现发布/订阅模式,将消息广播给所有订阅者。
- 消息过滤与路由:Exchange和Binding的灵活配置,可以实现基于消息内容的过滤和路由,确保消息被发送到指定的消费者。
- 延迟消息队列:通过使用RabbitMQ的插件或者自定义延迟队列,可以实现延迟发送消息的功能,常用于订单超时、定时任务等场景。
以上是第一章的内容,介绍了RabbitMQ的简介、核心组件以及在分布式系统中的应用。在接下来的章节中,我们将深入探讨Exchange、Queue和Binding的原理与应用。
## 第二章:Exchange的原理与类型
### 2.1 Exchange的作用和概念
在RabbitMQ中,Exchange(交换机)是用于接收消息并将其路由到相关的队列的组件。它充当着生产者和消费者之间的中介。当生产者发送消息时,它们将消息发送到Exchange,Exchange根据预定的规则(Binding)将消息路由到一个或多个队列中。消费者可以从这些队列中接收并处理消息。
Exchange有不同的类型,每种类型有不同的路由规则。RabbitMQ支持以下几种Exchange类型:
- Direct Exchange:根据消息的Routing Key将消息路由到与之完全匹配的队列。
- Fanout Exchange:将消息路由至所有与Exchange绑定的队列。
- Topic Exchange:根据消息的Routing Key与队列的Binding Key进行模式匹配,将消息路由到符合模式的队列。
- Headers Exchange:根据消息的Header属性进行匹配,将消息路由到与消息Header中指定内容匹配的队列。
### 2.2 Direct Exchange的原理与应用
Direct Exchange按消息的Routing Key将消息路由到与之精确匹配的队列。当消息发送给Direct Exchange时,Exchange会检查消息的Routing Key和队列的Binding Key,如果它们完全匹配,则将消息路由到相应的队列中。
```python
import pika
# 连接RabbitMQ
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 定义Direct Exchange
channel.exchange_declare(exchange='direct_exchange', exchange_type='direct')
# 定义队列
channel.queue_declare(queue='queue1')
channel.queue_declare(queue='queue2')
# 绑定队列到Direct Exchange,并指定Binding Key
channel.queue_bind(exchange='direct_exchange', queue='queue1', routing_key='info')
channel.queue_bind(exchange='direct_exchange', queue='queue2', routing_key='error')
# 发送消息至Direct Exchange,指定Routing Key
channel.basic_publish(exchange='direct_exchange', routing_key='info', body='This is an info message.')
channel.basic_publish(exchange='direct_exchange', routing_key='error', body='This is an error message.')
# 关闭连接
connection.close()
```
上述代码演示了如何创建一个Direct Exchange,并将两个队列绑定到该Exchange上。其中,队列`queue1`绑定了Routing Key为`info`的消息,队列`queue2`绑定了Routing Key为`error`的消息。然后,通过调用`channel.basic_publish()`方法将消息发送到Exchange,并指定相应的Routing Key。
### 2.3 Fanout Exchange的原理与应用
Fanout Exchange是一种最简单的Exchange类型,它将消息路由到所有与之绑定的队列。无论消息的Routing Key是什么,它都会将消息广播到所有绑定的队列。
```java
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
import java.io.IOException;
public class FanoutExchangeExample {
private static final String EXCHANGE_NAME = "fanout_exchange";
public static void main(String[] args) throws IOException {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
// 定义Fanout Exchange
channel.exchangeDeclare(EXCHANGE_NAME, "fanout");
// 定义队列
channel.queueDeclare("queue1", false, false, false, null);
channel.queueDeclare("queue2", false, false, false, null);
// 绑定队列到Fanout Exchange
channel.queueBind("queue1", EXCHANGE_NAME, "");
channel.queueBind("queue2", EXCHANGE_NAME, "");
// 发送消息至Fanout Exchange
channel.basicPublish(EXCHANGE_NAME, "", null, "This is a fanout message.".getBytes("UTF-8"));
channel.close();
connection.close();
}
}
```
上述示例代码展示了如何创建一个Fanout Exchange,并将两个队列绑定到该Exchange上。无需指定Routing Key,只需调用`channel.basicPublish()`方法发送消息即可,Fanout Exchange会将消息广播到所有绑定的队列中。
### 2.4 Topic Exchange的原理与应用
Topic Exchange根据消息的Routing Key与队列的Binding Key进行模式匹配,将消息路由到符合模式的队列。Binding Key可以使用通配符进行模糊匹配,可以匹配多个队列。
```go
package main
import (
"github.com/streadway/amqp"
"log"
)
func main() {
conn, err := amqp.Dial("amqp://guest:guest@localhost:5672/")
if err != nil {
log.Fatalf("Failed to connect to RabbitMQ: %v", err)
}
defer conn.Close()
ch, err := conn.Channel()
if err != nil {
log.Fatalf("Failed to open a channel: %v", err)
}
defer ch.Close()
// 定义Topic Exchange
err = ch.ExchangeDeclare("topic_exchange", "topic", true, false, false, false, nil)
if err != nil {
log.Fatalf("Failed to declare exchange: %v", err)
}
// 定义队列
q1, err := ch.QueueDeclare("queue1", true, false, false, false, nil)
if err != nil {
log.Fatalf("Failed to declare a queue: %v", err)
}
q2, err := ch.QueueDeclare("queue2", true, false, false, false, nil)
if err != nil {
log.Fatalf("Failed to declare a queue: %v", err)
}
// 绑定队列到Topic Exchange,并指定Binding Key模式
err = ch.QueueBind(q1.Name, "routing.key.*", "topic_exchange", false, nil)
if err != nil {
log.Fatalf("Failed to bind queue to exchange: %v", err)
}
err = ch.QueueBind(q2.Name, "routing.#", "topic_exchange", false, nil)
if err != nil {
log.Fatalf("Failed to bind queue to exchange: %v", err)
}
// 发送消息至Topic Exchange,指定Routing Key
err = ch.Publish("topic_exchange", "routing.key.1", false, false,
amqp.Publishing{ContentType: "text/plain", Body: []byte("This is a topic message.")})
if err != nil {
log.Fatalf("Failed to publish a message: %v", err)
}
}
```
上述代码显示了如何创建一个Topic Exchange,并将两个队列绑定到该Exchange上。通过调用`ch.QueueBind()`方法,可以指定Binding Key的模式,使用通配符`*`匹配一个词,`#`匹配多个词。然后,通过调用`ch.Publish()`方法发送消息,并指定Routing Key。
### 2.5 Headers Exchange的原理与应用
Headers Exchange根据消息的Header属性进行匹配,将消息路由到与消息Header中指定内容匹配的队列。与其他Exchange类型不同,Headers Exchange不关心消息的Routing Key和Binding Key,而是根据消息的Header属性进行匹配和路由。
```javascript
const amqp = require('amqplib');
async function main() {
const connection = await amqp.connect('amqp://localhost');
const channel = await connection.createChannel();
// 定义Headers Exchange
await channel.assertExchange('headers_exchange', 'headers', { durable: true });
// 定义队列
await channel.assertQueue('queue1');
await channel.assertQueue('queue2');
// 定义Header属性
const headers1 = { 'x-match': 'all', 'key1': 'value1', 'key2': 'value2' };
const headers2 = { 'x-match': 'any', 'key3': 'value3', 'key4': 'value4' };
// 绑定队列到Headers Exchange,并指定Header属性
await channel.bindQueue('queue1', 'headers_exchange', '', headers1);
await channel.bindQueue('queue2', 'headers_exchange', '', headers2);
// 发送消息至Headers Exchange,指定Header属性
channel.publish('headers_exchange', '', Buffer.from('This is a headers message.'), { headers: headers1 });
channel.close();
connection.close();
}
main().catch(console.error);
```
上述示例代码展示了如何创建一个Headers Exchange,并将两个队列绑定到该Exchange上。通过定义Header属性,可以灵活指定匹配规则。然后,通过调用`channel.publish()`方法发送消息,并指定Header属性。
以上是对Exchange的原理与类型的介绍,每种Exchange类型都有不同的路由规则,开发人员可以根据实际需求选择合适的Exchange类型。
## 第三章:Queue的原理与应用
### 3.1 Queue的定义和特点
在RabbitMQ中,队列(Queue)是消息的容器,用于存储发布到Exchange的消息,它是消息的终点,消费者从队列中接收消息并进行处理。队列具有以下特点:
- 队列是存储消息的地方,可以有多个消费者订阅一个队列,并竞争获取消息。
- 队列是有名字的,应用程序通过名称来声明一个队列,并向该队列发送和接收消息。
- 队列可以在服务器重启后保留消息,这取决于队列和消息的持久化设置。
### 3.2 Queue的持久化与非持久化
在RabbitMQ中,队列可以配置为持久化或非持久化。持久化的队列将在服务器重启后仍然存在,而非持久化的队列会在服务器重启后消失。
以下是使用Python语言声明一个持久化的队列的示例:
```python
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='my_queue', durable=True)
```
在上面的示例中,使用`channel.queue_declare()`方法声明了一个名为`my_queue`的持久化队列,并设置了参数`durable=True`。
### 3.3 Queue的优先级
在某些场景下,我们希望消息在队列中具有优先级,RabbitMQ 3.5.0版本后引入了队列的优先级特性。当消息具有不同的优先级时,具有较高优先级的消息将会优先被消费。
以下是使用Java语言声明一个具有优先级的队列的示例:
```java
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
public class QueuePriority {
private final static String QUEUE_NAME = "priority_queue";
public static void main(String[] args) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
try (Connection connection = factory.newConnection();
Channel channel = connection.createChannel()) {
// 声明一个具有优先级的队列
channel.queueDeclare(QUEUE_NAME, true, false, false,
java.util.Collections.singletonMap("x-max-priority", 10));
}
}
}
```
在上面的示例中,使用`channel.queueDeclare()`方法声明了一个名为`priority_queue`的队列,并通过参数`x-max-priority`设置了队列的最大优先级为10。
### 3.4 Queue的应用场景和最佳实践
队列作为消息的缓冲区,在分布式系统、异步任务处理和日志收集等场景中有着广泛的应用。在使用队列时,需要注意以下最佳实践:
- 避免长时间阻塞队列,及时处理消息以提高系统的吞吐量。
- 合理设置队列的持久化策略,根据业务需求选择适当的持久化配置。
- 合理设置队列的优先级,对于需要优先处理的消息进行优先级设置。
以上是队列的原理与应用的章节内容,包括了队列的特点、持久化配置、优先级设置以及最佳实践。
## 第四章:Binding的原理与应用
### 4.1 Binding的概念和作用
Binding是RabbitMQ中用于将Exchange和Queue进行绑定的操作。通过Binding,可以将Producer发送的消息路由到对应的Queue中。Binding的作用是定义了Exchange和Queue之间的消息路由规则,通过这些规则可以实现灵活的消息传递方式。
### 4.2 Exchange和Queue的绑定关系
在RabbitMQ中,Binding是通过指定Exchange和Queue的名称以及路由键来实现绑定操作的。当一个Queue与一个Exchange进行绑定时,需要指定一个路由键(routing key)。Exchange会将消息按照指定的规则(根据路由键)递送到与之绑定的Queue中。
以下是一个使用Python代码进行Binding绑定的例子:
```python
import pika
# 建立与RabbitMQ服务器的连接
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 创建一个direct类型的Exchange
channel.exchange_declare(exchange='my_exchange', exchange_type='direct')
# 创建一个Queue
channel.queue_declare(queue='my_queue')
# 绑定Exchange和Queue,使用指定的路由键
channel.queue_bind(exchange='my_exchange', queue='my_queue', routing_key='my_routing_key')
# 关闭连接
connection.close()
```
### 4.3 动态绑定与静态绑定
在RabbitMQ中,Binding可以分为动态绑定和静态绑定两种方式。
动态绑定是指在运行时动态地进行Binding的操作,可以根据实际情况动态地添加和移除Binding关系。动态绑定的优势是灵活性高,可以根据需要动态地调整消息路由规则。
静态绑定是指在RabbitMQ服务器启动时即进行配置好的Binding关系。静态绑定的优势是配置简单,性能稳定,适用于一些固定的消息路由场景。
### 4.4 Binding的用例和案例分析
#### 场景一:消息分发
假设我们有一个包含多个Worker的任务队列,我们希望将任务消息均匀地分发到各个Worker进行处理。我们可以使用RabbitMQ的direct类型Exchange进行绑定操作,将Exchange与多个Queue绑定,并设置不同的路由键。每个Worker监听一个Queue,Exchange将任务消息按照路由键的规则进行分发。
以下是一个使用Python代码进行消息分发的例子:
```python
import pika
# 建立与RabbitMQ服务器的连接
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 创建一个direct类型的Exchange
channel.exchange_declare(exchange='task_exchange', exchange_type='direct')
# 创建多个Queue
channel.queue_declare(queue='worker1_queue')
channel.queue_declare(queue='worker2_queue')
channel.queue_declare(queue='worker3_queue')
# 绑定Exchange和Queue,使用不同的路由键
channel.queue_bind(exchange='task_exchange', queue='worker1_queue', routing_key='worker1')
channel.queue_bind(exchange='task_exchange', queue='worker2_queue', routing_key='worker2')
channel.queue_bind(exchange='task_exchange', queue='worker3_queue', routing_key='worker3')
# 发送任务消息到Exchange
channel.basic_publish(exchange='task_exchange', routing_key='worker1', body='Task 1')
channel.basic_publish(exchange='task_exchange', routing_key='worker2', body='Task 2')
channel.basic_publish(exchange='task_exchange', routing_key='worker3', body='Task 3')
# 关闭连接
connection.close()
```
在上述例子中,我们创建了一个名为`task_exchange`的direct类型的Exchange,并创建了3个Worker对应的Queue。然后,我们将Exchange与每个Worker的Queue进行绑定,并通过指定不同的路由键来实现消息的分发。最后,我们发送了3个任务消息到Exchange,Exchange会根据路由键的规则将消息分发到对应的Queue中。
#### 场景二:消息过滤
假设我们有一个消息队列,其中包含了来自不同来源的消息。我们希望将特定来源的消息发送到特定的消费者进行处理。我们可以使用RabbitMQ的topic类型Exchange进行绑定操作,将Exchange与不同来源的Queue绑定,并设置对应的路由键。每个消费者只监听与之相关的Queue,Exchange会将消息按照路由键的规则进行过滤和分发。
以下是一个使用Python代码进行消息过滤的例子:
```python
import pika
# 建立与RabbitMQ服务器的连接
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 创建一个topic类型的Exchange
channel.exchange_declare(exchange='news_exchange', exchange_type='topic')
# 创建多个Queue
channel.queue_declare(queue='sports_queue')
channel.queue_declare(queue='finance_queue')
channel.queue_declare(queue='weather_queue')
# 绑定Exchange和Queue,使用不同的路由键
channel.queue_bind(exchange='news_exchange', queue='sports_queue', routing_key='sports.*')
channel.queue_bind(exchange='news_exchange', queue='finance_queue', routing_key='finance.*')
channel.queue_bind(exchange='news_exchange', queue='weather_queue', routing_key='weather.*')
# 发送消息到Exchange
channel.basic_publish(exchange='news_exchange', routing_key='sports.news', body='Sports News 1')
channel.basic_publish(exchange='news_exchange', routing_key='finance.news', body='Finance News 1')
channel.basic_publish(exchange='news_exchange', routing_key='weather.forecast', body='Weather Forecast 1')
# 关闭连接
connection.close()
```
在上述例子中,我们创建了一个名为`news_exchange`的topic类型的Exchange,并创建了3个与不同来源的Queue。然后,我们将Exchange与每个来源的Queue进行绑定,并通过指定不同的路由键来实现消息的过滤。最后,我们发送了一些不同来源的消息到Exchange,Exchange会根据路由键的规则将消息过滤并分发到对应的Queue中。
通过上述两个场景的例子,我们可以看到Binding在RabbitMQ中的重要作用。它为我们提供了灵活和可靠的消息路由机制,使得消息能够准确地传递到目标Queue中,实现了不同场景下的应用需求。
## 第五章:RabbitMQ中Exchange、Queue和Binding的实际应用
在前面的章节中,我们详细介绍了RabbitMQ中Exchange、Queue和Binding的原理和应用场景。本章将以实际的应用为例,演示如何使用Exchange、Queue和Binding构建不同类型的系统。
### 5.1 使用Exchange、Queue和Binding构建发布/订阅系统
发布/订阅模式是一种常见的消息传递模式,用于同时向多个消费者广播消息。在RabbitMQ中,我们可以使用Fanout Exchange来实现这种模式。
首先,我们创建一个Fanout Exchange(`fanout_exchange`),让它和一个或多个Queue(`queue1`、`queue2`、`queue3`)进行绑定。这样,当消息发布到Fanout Exchange时,它会被广播到所有绑定的Queue中。
以下是一个示例的Python代码:
```python
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
exchange_name = 'fanout_exchange'
queue_names = ['queue1', 'queue2', 'queue3']
# 创建Fanout Exchange
channel.exchange_declare(exchange=exchange_name, exchange_type='fanout')
# 创建Queue并绑定到Exchange
for queue_name in queue_names:
channel.queue_declare(queue=queue_name)
channel.queue_bind(exchange=exchange_name, queue=queue_name)
# 发布消息到Exchange
message = 'Hello RabbitMQ!'
channel.basic_publish(exchange=exchange_name, routing_key='', body=message)
print("消息已发送")
connection.close()
```
在上述代码中,我们首先通过`channel.exchange_declare()`方法创建了一个名为`fanout_exchange`的Fanout Exchange。然后,通过循环创建了三个Queue,并将它们分别绑定到该Exchange上。最后,使用`channel.basic_publish()`方法将消息发布到Exchange。
### 5.2 使用Exchange、Queue和Binding实现消息过滤与路由
有时候,我们需要将特定类型的消息路由到指定的消费者,而不是广播给所有消费者。在RabbitMQ中,可以通过使用Direct Exchange来实现消息过滤与路由。
假设我们有两个消费者:ConsumerA和ConsumerB。我们创建一个Direct Exchange(`direct_exchange`),并将不同的Routing Key与不同的Queue进行绑定。当消息发布到Exchange时,只有与Routing Key匹配的Queue会收到该消息。
以下是一个示例的Java代码:
```java
import com.rabbitmq.client.*;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.Random;
public class DirectExchangeExample {
private static final String EXCHANGE_NAME = "direct_exchange";
private static final String QUEUE_NAME_A = "queue_A";
private static final String QUEUE_NAME_B = "queue_B";
private static final String[] ROUTING_KEYS = {"key1", "key2", "key3"};
public static void main(String[] args) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
// 创建Direct Exchange
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.DIRECT);
// 创建QueueA并绑定到指定的Routing Key
String queueNameA = channel.queueDeclare(QUEUE_NAME_A, false, false, false, null).getQueue();
String routingKeyA = ROUTING_KEYS[new Random().nextInt(ROUTING_KEYS.length)];
channel.queueBind(queueNameA, EXCHANGE_NAME, routingKeyA);
// 创建QueueB并绑定到所有的Routing Key
String queueNameB = channel.queueDeclare(QUEUE_NAME_B, false, false, false, null).getQueue();
for (String routingKey : ROUTING_KEYS) {
channel.queueBind(queueNameB, EXCHANGE_NAME, routingKey);
}
// 订阅消息并处理
Consumer consumerA = new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
String message = new String(body, StandardCharsets.UTF_8);
System.out.println("ConsumerA 接收到消息:" + message);
channel.basicAck(envelope.getDeliveryTag(), false);
}
};
channel.basicConsume(queueNameA, false, consumerA);
Consumer consumerB = new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
String message = new String(body, StandardCharsets.UTF_8);
System.out.println("ConsumerB 接收到消息:" + message);
channel.basicAck(envelope.getDeliveryTag(), false);
}
};
channel.basicConsume(queueNameB, false, consumerB);
// 发布消息到Exchange
String routingKey = ROUTING_KEYS[new Random().nextInt(ROUTING_KEYS.length)];
String message = "Hello RabbitMQ! Routing Key: " + routingKey;
channel.basicPublish(EXCHANGE_NAME, routingKey, null, message.getBytes(StandardCharsets.UTF_8));
System.out.println("消息已发送");
channel.close();
connection.close();
}
}
```
在上述代码中,我们首先使用`channel.exchangeDeclare()`方法创建了一个名为`direct_exchange`的Direct Exchange。然后,通过`channel.queueDeclare()`方法创建了两个Queue(`queue_A`和`queue_B`)。接下来,我们将QueueA与一个随机选择的Routing Key绑定,将QueueB与所有的Routing Key绑定。最后,通过`channel.basicPublish()`方法发布了一条带有随机Routing Key的消息。
### 5.3 使用Exchange、Queue和Binding实现延迟消息队列
延迟消息队列是指消息在发送后不会立即被消费,而是要等待一段预定的时间后才能被消费。在RabbitMQ中,我们可以使用TTL(Time-To-Live)和死信队列(Dead Letter Queue)来实现延迟消息队列。
以下是一个示例的Go语言代码(使用`github.com/streadway/amqp`库):
```go
package main
import (
"fmt"
"log"
"math/rand"
"strconv"
"time"
"github.com/streadway/amqp"
)
func main() {
conn, err := amqp.Dial("amqp://guest:guest@localhost:5672/")
if err != nil {
log.Fatalf("无法连接到RabbitMQ:%v", err)
}
defer conn.Close()
ch, err := conn.Channel()
if err != nil {
log.Fatalf("无法打开RabbitMQ通道:%v", err)
}
defer ch.Close()
// 创建Exchange
err = ch.ExchangeDeclare(
"delay_exchange", // exchange名称
"fanout", // exchange类型
true, // 持久化
false, // auto-delete
false, // internal
false, // no-wait
nil, // args
)
if err != nil {
log.Fatalf("无法创建Exchange:%v", err)
}
// 创建Queue
_, err = ch.QueueDeclare(
"delay_queue", // queue名称
true, // 持久化
false, // auto-delete
false, // exclusive
false, // no-wait
nil, // args
)
if err != nil {
log.Fatalf("无法创建Queue:%v", err)
}
// 创建Binding
err = ch.QueueBind(
"delay_queue", // queue名称
"", // binding key
"delay_exchange", // exchange名称
false, // no-wait
nil, // args
)
if err != nil {
log.Fatalf("无法创建Binding:%v", err)
}
// 消费消息
go consume(ch)
// 发布延迟消息
for i := 1; i <= 10; i++ {
delay := time.Duration(rand.Intn(5000)) * time.Millisecond
message := "延迟消息 " + strconv.Itoa(i)
err = ch.Publish(
"delay_exchange", // exchange名称
"", // routing key
false, // mandatory
false, // immediate
amqp.Publishing{
Timestamp: time.Now().Add(delay), // 延迟时间
ContentType: "text/plain",
Body: []byte(message),
Expiration: strconv.Itoa(int(delay.Milliseconds())),
DeliveryMode: amqp.Persistent, // 持久化
Priority: uint8(0), // 优先级
CorrelationId: "", // correlationID
ReplyTo: "", // replyTo
MessageId: "", // messageID
Type: "", // type
ContentEncoding: "", // contentEncoding
Headers: amqp.Table{}, // headers
})
if err != nil {
log.Fatalf("无法发布消息:%v", err)
}
fmt.Printf("延迟 %dms 后发送消息:%s\n", delay.Milliseconds(), message)
time.Sleep(1 * time.Second)
}
time.Sleep(10 * time.Second)
}
func consume(ch *amqp.Channel) {
msgs, err := ch.Consume(
"delay_queue", // queue名称
"", // consumer tag
false, // auto-ack
false, // exclusive
false, // no-local
false, // no-wait
nil, // args
)
if err != nil {
log.Fatalf("无法消费消息:%v", err)
}
for msg := range msgs {
message := string(msg.Body)
log.Printf("接收到消息:%s", message)
msg.Ack(false)
}
}
```
在上述代码中,我们首先通过`ch.ExchangeDeclare()`方法创建了一个名为`delay_exchange`的Fanout Exchange。然后,通过`ch.QueueDeclare()`方法创建了一个名为`delay_queue`的Queue,并将它与Exchange进行绑定。接下来,通过循环发布了10条延迟消息,每条消息的延迟时间和消息内容都是随机生成的。
同时,我们还使用了消息的TTL和死信队列来实现延迟。通过将消息的TTL设置为延迟的时间,并使用死信队列来接收已过期的消息,从而实现了延迟消息队列的效果。
### 5.4 使用Exchange、Queue和Binding构建异步任务处理系统
在分布式系统中,异步任务处理是一种常见的需求。通过将任务发布到RabbitMQ中,多个消费者可以异步地处理这些任务,从而提高系统的吞吐量和响应速度。
以下是一个示例的JavaScript代码(使用`amqplib`库):
```javascript
const amqp = require('amqplib');
const QUEUE_NAME = 'task_queue';
async function main() {
const connection = await amqp.connect('amqp://localhost');
const channel = await connection.createChannel();
await channel.assertQueue(QUEUE_NAME, { durable: true });
await channel.prefetch(1);
console.log('等待接收消息...');
channel.consume(
QUEUE_NAME,
async (msg) => {
const message = msg.content.toString();
console.log('接收到消息:', message);
// 异步处理任务
await simulateAsyncProcessing();
console.log('任务处理完成:', message);
channel.ack(msg);
},
{ noAck: false }
);
}
async function simulateAsyncProcessing() {
return new Promise((resolve) => {
setTimeout(resolve, Math.random() * 5000);
});
}
main().catch((err) => console.error(err));
```
在上述代码中,我们首先使用`channel.assertQueue()`方法创建了一个名为`task_queue`的Queue。然后,通过`channel.prefetch(1)`方法设置每次只处理一个任务,并使用`channel.consume()`方法消费消息。
当消费者接收到消息后,会调用异步处理函数`simulateAsyncProcessing()`来模拟任务的异步执行。在实际的应用中,可以根据具体的业务逻辑来处理任务。当任务处理完成后,调用`channel.ack()`方法告诉RabbitMQ该消息已成功处理。
通过以上的代码示例,我们了解了如何使用Exchange、Queue和Binding构建不同类型的系统。在实际的应用中,可以根据具体的需求和场景来选择适合的Exchange类型、Queue设置和Binding关系。使用RabbitMQ的Exchange、Queue和Binding机制,可以帮助我们构建可靠、高性能的消息系统。
## 第六章:性能调优与最佳实践
### 6.1 RabbitMQ中Exchange、Queue和Binding的性能优化策略
在使用RabbitMQ时,为了提高系统的性能和可靠性,需要注意一些性能优化的策略。下面介绍一些可行的优化策略:
#### 6.1.1 使用持久化的Exchange和Queue
默认情况下,RabbitMQ中的Exchange和Queue都是非持久化的,这意味着它们在RabbitMQ服务器重启之后会丢失。为了避免消息丢失,可以将Exchange和Queue设置为持久化的,这样即使服务器重启,也能保证消息的持久性。
```java
// Java代码示例
// 声明一个持久化的Exchange
channel.exchangeDeclare("exchangeName", "direct", true);
// 声明一个持久化的Queue
channel.queueDeclare("queueName", true, false, false, null);
```
#### 6.1.2 调整RabbitMQ服务器的内存限制
RabbitMQ服务器默认会使用一定数量的内存用于缓存消息,为了避免内存溢出,可以调整RabbitMQ服务器的内存限制。
```python
# Python代码示例
# 设置RabbitMQ服务器的内存限制为500MB
rabbitmqctl set_vm_memory_high_watermark 500MB
```
#### 6.1.3 使用消息持久化
除了将Exchange和Queue设置为持久化外,还可以通过将消息设置为持久化来确保消息的可靠性。这样即使在发送消息时发生故障,消息也能够被存储在磁盘上,并在服务器重启后被重新发送。
```go
// Go代码示例
// 将消息设置为持久化
msg := amqp.Publishing{
DeliveryMode: amqp.Persistent,
Body: []byte("Hello RabbitMQ"),
}
// 发布消息
channel.Publish("exchangeName", "routingKey", false, false, msg)
```
#### 6.1.4 使用多个连接和通道
为了提高并发性能,可以使用多个连接和通道来同时进行消息的发送和接收。这样可以充分利用系统的资源,并提高处理消息的吞吐量。
```javascript
// JavaScript代码示例
// 创建多个连接和通道
const connection1 = await amqp.connect('amqp://localhost');
const channel1 = await connection1.createChannel();
const connection2 = await amqp.connect('amqp://localhost');
const channel2 = await connection2.createChannel();
```
### 6.2 RabbitMQ集群中Exchange、Queue和Binding的最佳实践
在RabbitMQ集群中使用Exchange、Queue和Binding时,需要注意以下最佳实践:
#### 6.2.1 使用HA模式配置Exchange和Queue
在集群中使用Exchange和Queue时,可以将它们配置为高可用(Highly Available)模式,这样即使某个节点发生故障,也能够保证消息的持久性和可靠性。
```java
// Java代码示例
// 声明一个具有HA模式的Exchange
channel.exchangeDeclare("exchangeName", "direct", true, false, false, null, Arguments{
"ha-mode": "all",
})
// 声明一个具有HA模式的Queue
channel.queueDeclare("queueName", true, false, false, Arguments{
"ha-mode": "all",
})
```
#### 6.2.2 使用镜像队列来提高可靠性
镜像队列(Mirrored Queue)是一种特殊类型的队列,在集群中的每个节点上都有一个副本,这样即使某个节点发生故障,其他节点上的副本仍然可以正常工作,从而提高队列的可靠性。
```python
# Python代码示例
# 声明一个镜像队列
channel.queue_declare(queue='queueName', arguments={
'x-ha-policy': 'all',
})
```
#### 6.2.3 使用Consistent Hashing来实现消息路由
在集群中使用Exchange和Binding时,可以使用Consistent Hashing来实现消息的路由,这样可以保证相同的消息始终被发送到同一个节点上,并避免不必要的消息转发和重复消费。
```go
// Go代码示例
// 创建一个基于Consistent Hashing的Exchange
args := amqp.Table{
"hash-header": "message_id",
}
channel.ExchangeDeclare("exchangeName", "x-consistent-hash", true, false, false, false, false, args)
// 创建一个Binding
channel.QueueBind("queueName", "routingKey", "exchangeName", false, amqp.Table{})
```
### 6.3 RabbitMQ中Exchange、Queue和Binding的故障处理和排错方法
在使用RabbitMQ时,可能会遇到一些故障和错误。下面介绍一些常见的故障处理和排错方法:
#### 6.3.1 查看节点状态和队列状态
使用命令`rabbitmqctl`可以查看集群中各个节点的状态和队列的状态,通过这些信息可以找出故障的原因并进行修复。
```shell
# 查看节点状态
rabbitmqctl cluster_status
# 查看队列状态
rabbitmqctl list_queues
```
#### 6.3.2 查看日志和错误日志
RabbitMQ将日志和错误日志输出到指定的文件中,通过查看这些日志可以获取更详细的错误信息,帮助排查和解决故障。
```
# 日志文件路径
/var/log/rabbitmq/rabbit@hostname.log
# 错误日志文件路径
/var/log/rabbitmq/rabbit@hostname-sasl.log
```
### 6.4 RabbitMQ中Exchange、Queue和Binding的安全性优化
在使用RabbitMQ时,为了保证系统的安全性,需要做一些安全性优化的措施。下面介绍一些常见的安全性优化方法:
#### 6.4.1 使用TLS/SSL进行通信加密
为了保护数据传输过程中的安全性,可以使用TLS/SSL对RabbitMQ的通信进行加密。通过使用证书认证和加密算法,可以有效防止数据泄露和劫持。
#### 6.4.2 使用权限控制
通过设置RabbitMQ的用户和权限,可以对Exchange、Queue和Binding进行细粒度的访问控制,确保只有授权的用户才能进行相关操作。
#### 6.4.3 防止拒绝服务攻击
为了防止拒绝服务(Denial of Service)攻击,可以设置RabbitMQ的资源限制,例如限制每个连接的最大并发数和每个队列的最大消息数量。
以上是RabbitMQ中Exchange、Queue和Binding的性能调优与最佳实践的一些方法和建议,希望对您有所帮助。
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏《java-rabbitmq》围绕着Java语言在RabbitMQ消息队列应用中的方方面面展开全面而深入的探讨。从RabbitMQ基础入门指南、Java中的消息队列开发,到Exchange、Queue和Binding的原理与应用,再到消息确认和持久化的最佳实践,以及消息的发布与订阅模式等,覆盖了RabbitMQ的核心概念和实际应用。同时也涵盖了Spring Boot整合RabbitMQ、集群部署与负载均衡实践、消息队列安全与权限控制等高级话题,并深入剖析了如何保证RabbitMQ的高可用性与可靠性,以及性能优化与吞吐量提升等实践技巧。通过本专栏,读者能够系统地掌握Java中使用RabbitMQ的方法,对消息队列的原理和实际应用有深入理解,并能够结合Spring Cloud Stream进行应用实践。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【实战演练】时间序列预测项目:天气预测-数据预处理、LSTM构建、模型训练与评估

# 1. 时间序列预测概述**
时间序列预测是指根据历史数据预测未来值。它广泛应用于金融、天气、交通等领域,具有重要的实际意义。时间序列数据通常具有时序性、趋势性和季节性等特点,对其进行预测需要考虑这些特性。
# 2. 数据预处理
### 2.1 数据收集和清洗
#### 2.1.1 数据源介绍
时间序列预测模型的构建需要可靠且高质量的数据作为基础。数据源的选择至关重要,它将影响模型的准确性和可靠性。常见的时序数据源包括:
【实战演练】通过强化学习优化能源管理系统实战
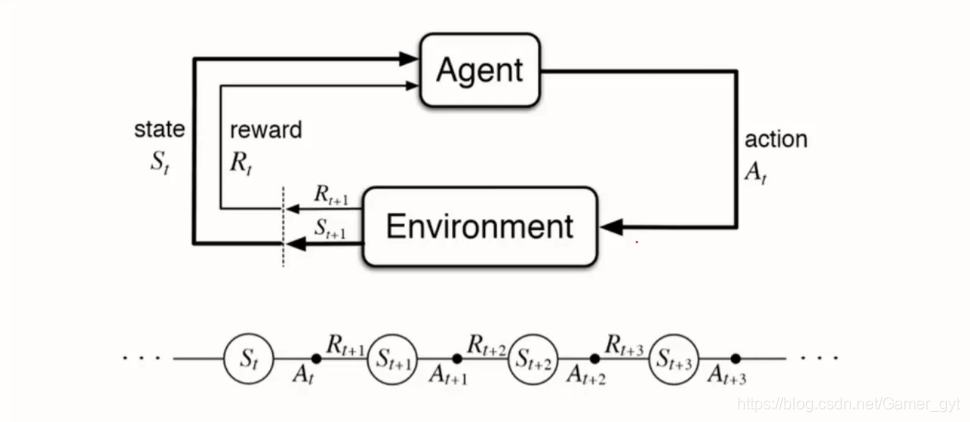
# 2.1 强化学习的基本原理
强化学习是一种机器学习方法,它允许智能体通过与环境的交互来学习最佳行为。在强化学习中,智能体通过执行动作与环境交互,并根据其行为的
【实战演练】使用Docker与Kubernetes进行容器化管理
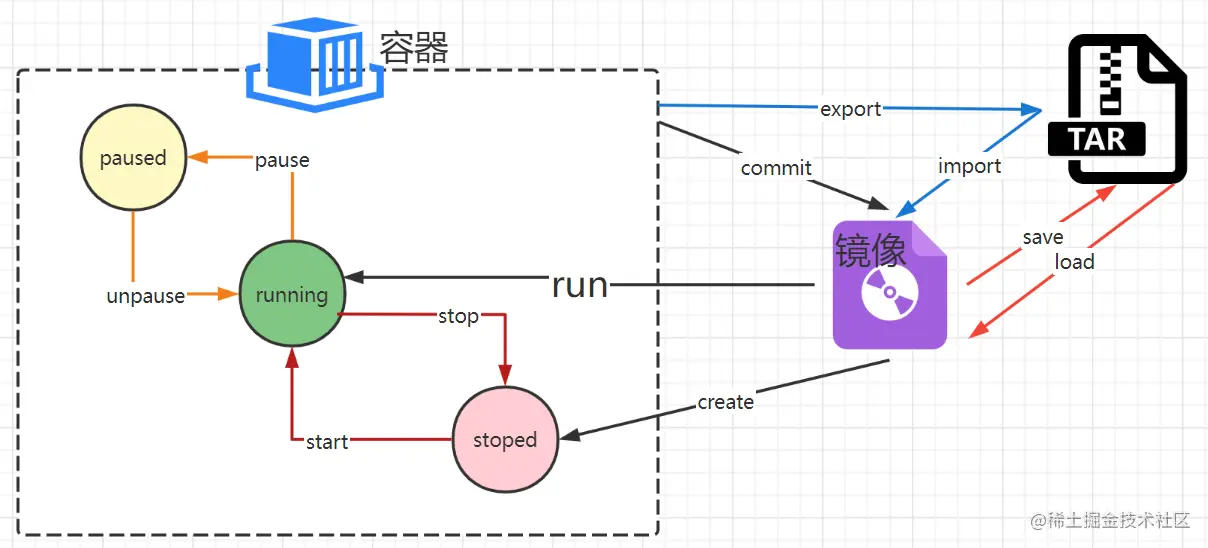
# 2.1 Docker容器的基本概念和架构
Docker容器是一种轻量级的虚拟化技术,它允许在隔离的环境中运行应用程序。与传统虚拟机不同,Docker容器共享主机内核,从而减少了资源开销并提高了性能。
Docker容器基于镜像构建。镜像是包含应用程序及
【实战演练】综合案例:数据科学项目中的高等数学应用

# 1. 数据科学项目中的高等数学基础**
高等数学在数据科学中扮演着至关重要的角色,为数据分析、建模和优化提供了坚实的理论基础。本节将概述数据科学
【实战演练】CVSS漏洞评估打分原则
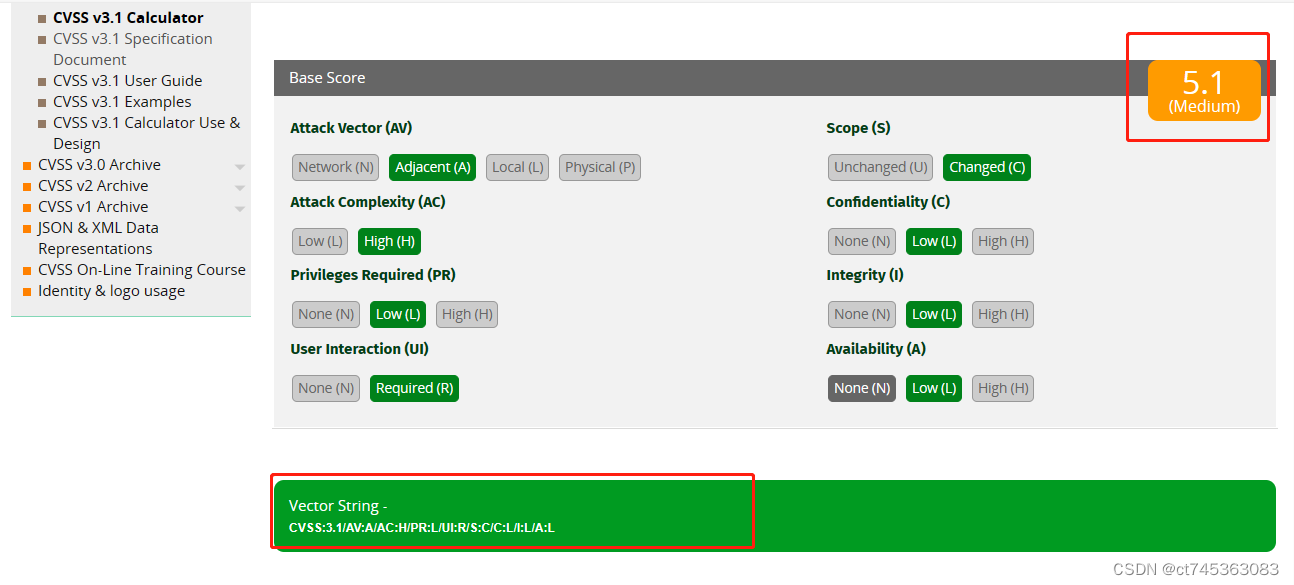
# 2.1 CVSS v3.1评分体系
CVSS v3.1评分体系由三个评分向量组成:基本评分、时间评分和环境评分。
### 2.1.1 基本评分
基本评分反映了漏洞的固有严重性,不受时间或环境因素的影响。它由以下三个度量组成:
- 攻击向量(AV):描述攻击者利用漏洞所需的技术和资源。
- 攻击复杂度(AC):衡量攻击者成功利用漏洞所需的技能和知识。
- 权限要求(PR):表示攻击者需要获得的目
【实战演练】深度学习在计算机视觉中的综合应用项目

# 1. 计算机视觉概述**
计算机视觉(CV)是人工智能(AI)的一个分支,它使计算机能够“看到”和理解图像和视频。CV 旨在赋予计算机人类视觉系统的能力,包括图像识别、对象检测、场景理解和视频分析。
CV 在广泛的应用中发挥着至关重要的作用,包括医疗诊断、自动驾驶、安防监控和工业自动化。它通过从视觉数据中提取有意义的信息,为计算机提供环境感知能力,从而实现这些应用。
# 2.1 卷积
【实战演练】虚拟宠物:开发一个虚拟宠物游戏,重点在于状态管理和交互设计。

# 2.1 虚拟宠物的状态模型
### 2.1.1 宠物的基本属性
虚拟宠物的状态由一系列基本属性决定,这些属性描述了宠物的当前状态,包括:
- **生命值 (HP)**:宠物的健康状况,当 HP 为 0 时,宠物死亡。
- **饥饿值 (Hunger)**:宠物的饥饿程度,当 Hunger 为 0 时,宠物会饿死。
- **口渴
【实战演练】python云数据库部署:从选择到实施
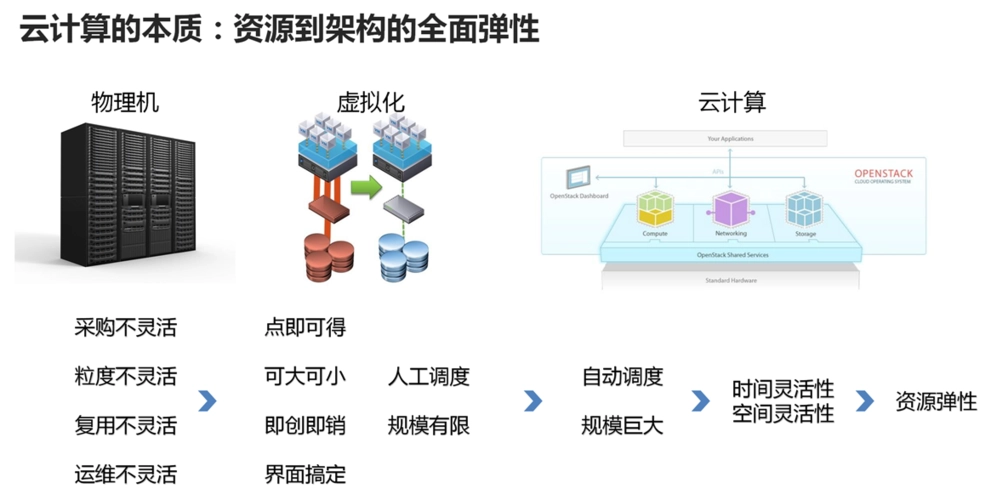
# 2.1 云数据库类型及优劣对比
**关系型数据库(RDBMS)**
* **优点:**
* 结构化数据存储,支持复杂查询和事务
* 广泛使用,成熟且稳定
* **缺点:**
* 扩展性受限,垂直扩展成本高
* 不适合处理非结构化或半结构化数据
**非关系型数据库(NoSQL)**
* **优点:**
* 可扩展性强,水平扩展成本低
【实战演练】构建简单的负载测试工具

# 1. 负载测试基础**
负载测试是一种性能测试,旨在模拟实际用户负载,评估系统在高并发下的表现。它通过向系统施加压力,识别瓶颈并验证系统是否能够满足预期性能需求。负载测试对于确保系统可靠性、可扩展性和用户满意度至关重要。
# 2. 构建负载测试工具
### 2.1 确定测试目标和指标
在构建负载测试工具之前,至关重要的是确定测试目标和指标。这将指导工具的设计和实现。以下是一些需要考虑的关键因素:
【实战演练】前沿技术应用:AutoML实战与应用

# 1. AutoML概述与原理**
AutoML(Automated Machine Learning),即自动化机器学习,是一种通过自动化机器学习生命周期
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )