【C#自定义模型绑定新手指南】:手把手教你入门到实战技巧
发布时间: 2024-10-22 11:20:28 阅读量: 47 订阅数: 32 
# 1. C#模型绑定概述
## 模型绑定简介
模型绑定是*** MVC框架中的一个核心概念,允许开发者将HTTP请求中的数据映射到后端的方法参数上。这项技术简化了数据从客户端到服务器端的传输过程,使得Web开发更加高效。了解模型绑定的工作原理,可以帮助我们更好地处理表单提交,RESTful API请求等,并且对数据进行适当的验证和转换。
## MVC框架中的数据流解析
在MVC中,数据流主要遵循以下步骤:当一个HTTP请求到达时,框架会根据路由配置找到相应的控制器和动作方法。随后,模型绑定器尝试将请求数据(如表单数据、路由数据、查询字符串等)绑定到动作方法的参数上。一旦绑定完成,动作方法将被调用,并且可以使用绑定好的数据执行业务逻辑。
## 模型绑定的默认行为和限制
模型绑定器的默认行为能够处理大部分常见场景,如字符串、整数、布尔值等基本类型,以及它们的集合类型。然而,当涉及到自定义类型或复杂的绑定逻辑时,我们可能需要自定义模型绑定器。默认绑定器可能无法处理如嵌套类型或特定的格式化需求,这就需要我们深入了解模型绑定的工作原理,并在必要时进行扩展。
```csharp
// 示例:简单模型绑定器使用默认行为将请求数据绑定到控制器动作方法的参数
public ActionResult SubmitForm(string username, int age)
{
// 在这里处理绑定好的数据
return View();
}
```
在本章中,我们首先概述了模型绑定的概念及其在Web开发中的重要性。随后,我们简要介绍了数据在MVC框架中的流动方式以及模型绑定器的默认行为和限制。这些基础知识为深入理解并掌握如何创建和配置自定义模型绑定器提供了坚实的理论基础。
# 2. 自定义模型绑定的理论基础
## 2.1 模型绑定在MVC中的作用
### 2.1.1 MVC框架中的数据流解析
在MVC(Model-View-Controller)框架中,模型绑定是一个核心机制,用于将客户端请求的数据(通常是表单数据或URL参数)映射到服务器端的模型(Model)对象上。这一过程是MVC数据处理的关键,它简化了从请求到业务逻辑处理的映射,提高了开发效率。
数据流从客户端发出后,经过路由器解析,请求最终由控制器(Controller)接收。控制器会根据请求的类型(如GET或POST)调用相应的动作方法(Action Method),然后框架会根据动作方法的参数类型,尝试将请求中的数据绑定到这些参数上。这一绑定过程,就是模型绑定发生的地方。
模型绑定器(Model Binder)是模型绑定的执行者,它使用约定好的规则将请求数据与模型对象的属性关联起来。一旦完成绑定,模型对象就会作为动作方法的参数被传递,动作方法就可以根据模型对象的状态执行相应的业务逻辑。
### 2.1.2 模型绑定的默认行为和限制
*** MVC框架提供了一系列默认的模型绑定器,例如默认的简单类型绑定器、集合类型绑定器等,它们能够处理常见场景下的模型绑定任务。例如,对于简单类型如int、string等,模型绑定器能够直接从请求中获取相应名称的值,并将其转换为参数类型。
尽管默认的模型绑定器功能强大,但在复杂的业务场景中,它们仍然存在限制。例如,当模型的属性名与请求中的数据字段名不匹配时,默认绑定器就无能为力。另外,对于复杂类型或自定义类型,以及需要复杂逻辑来转换或验证数据的情况,开发者就需要实现自定义模型绑定器。
## 2.2 自定义模型绑定的需求分析
### 2.2.1 典型应用场景
自定义模型绑定器在多个场景中可能成为必需,比如:
- 复杂对象绑定:当表单数据结构较为复杂,包含嵌套对象或者列表时,可能需要自定义绑定逻辑以处理属性嵌套的情况。
- 数据转换:在某些情况下,我们需要将字符串转换为非标准类型,比如日期格式转换,或者将字符串"true"转换为bool值。
- 验证逻辑:在绑定数据时添加额外的验证逻辑,比如验证时间范围、检查数字范围等。
- 自定义数据源:绑定到来自非HTTP请求的数据源,例如缓存、数据库或第三方服务。
### 2.2.2 需求分析的重要性
在实施自定义模型绑定之前,进行详细的需求分析至关重要。理解应用程序的数据流和用户交互的上下文是开发任何功能的基础。通过需求分析,开发者可以:
- 确定模型绑定需求的具体场景和条件。
- 明确绑定过程中数据的来源、类型和格式。
- 设计合理的错误处理和数据验证策略。
- 评估性能和安全影响,并制定相应的优化策略。
通过以上分析,开发者能够创建出既符合应用需求又具有最佳实践特性的自定义模型绑定器。
## 2.3 自定义模型绑定的实现原理
### 2.3.1 模型绑定的生命周期
自定义模型绑定器的生命周期从请求到达控制器动作方法开始,到模型绑定完成为止。以下是生命周期的关键步骤:
1. **请求处理**:当请求到达MVC框架时,框架会解析请求并确定要执行的动作方法。
2. **确定模型绑定器**:MVC框架尝试为动作方法的每个参数找到合适的模型绑定器。
3. **数据提取**:模型绑定器从请求中提取数据,这可能包括查询字符串、表单字段或路由数据。
4. **数据转换和绑定**:模型绑定器将提取的数据转换为目标参数的类型,并绑定到该参数。
5. **验证和错误处理**:在数据绑定之后,MVC框架可能会执行参数的验证逻辑。如果绑定器实现了IModelBinder接口中的`BindModelAsync`方法,则可以在绑定过程中进行错误处理。
6. **动作方法执行**:模型参数准备就绪后,动作方法得以执行。
### 2.3.2 关键接口和类的探讨
在实现自定义模型绑定器的过程中,涉及几个关键接口和类:
- `IModelBinder`:这是自定义模型绑定器必须实现的接口。它包含`BindModelAsync`方法,用于绑定数据到模型对象。
- `ModelBinderProviderContext`:自定义模型绑定器可以在`ModelBinderProvider`中注册,而`ModelBinderProviderContext`提供了上下文信息,用于决定是否提供特定的模型绑定器。
- `ModelBindingContext`:该类提供有关模型绑定操作的详细信息,包括模型名称、模型类型、绑定源等。自定义绑定器在执行绑定逻辑时可以利用这些信息。
自定义模型绑定器的实现通常涉及到对这些关键接口和类的深入理解和灵活运用,以达到高效且准确的数据绑定。
# 3. 自定义模型绑定器的创建与配置
## 3.1 创建自定义模型绑定器
### 3.1.1 实现IModelBinder接口
实现`IModelBinder`接口是创建自定义模型绑定器的首要步骤。`IModelBinder`接口定义了一个`BindModelAsync`方法,它负责从请求数据中提取并转换数据到指定的模型类型。这个过程包括读取请求数据、解析数据和验证数据的有效性等。
为了深入理解,下面是`BindModelAsync`方法的一个示例实现:
```csharp
public class MyCustomModelBinder : IModelBinder
{
public Task BindModelAsync(ModelBindingContext bindingContext)
{
if (bindingContext == null)
{
throw new ArgumentNullException(nameof(bindingContext));
}
// 获取模型名称,这是在路由模板中定义的参数名
var modelName = bindingContext.ModelName;
// 从请求中尝试获取对应的值,例如通过表单或查询字符串
var valueProviderResult = bindingContext.ValueProvider.GetValue(modelName);
if (valueProviderResult == ValueProviderResult.None)
{
***pletedTask;
}
// 解析和绑定操作
var value = valueProviderResult.FirstValue;
if (!string.IsNullOrEmpty(value))
{
// 尝试将值绑定到模型类型并验证
var model = ConvertStringToModelType(value);
// 成功绑定模型,将其设置到BindingContext中
bindingContext.Result = ModelBindingResult.Success(model);
}
else
{
// 值可能为null或空,进行相应处理
bindingContext.Result = ModelBindingResult.Success(null);
}
***pletedTask;
}
private MyModelType ConvertStringToModelType(string value)
{
// 这里应该包含将字符串转换为你的模型类型的具体实现
// 示例:解析JSON字符串为对象等
}
}
```
在上述代码中,`MyCustomModelBinder`类实现了`IModelBinder`接口,定义了`BindModelAsync`方法,该方法首先检查上下文中是否存在对应的模型名称,然后尝试从请求中获取这个模型的值。接下来,它使用`ConvertStringToModelType`方法将字符串转换为你的模型类型。如果转换成功,则通过`ModelBindingResult.Success`方法返回一个成功的绑定结果。
### 3.1.2 编写绑定逻辑
编写绑定逻辑是创建自定义模型绑定器中最为核心的部分。根据应用的需求,绑定逻辑可以非常简单,也可以异常复杂。在最简单的情况下,绑定逻辑可能只涉及将字符串值直接转换为模型类型。但在更复杂的情况下,你可能需要处理字符串到复杂对象的转换,或者需要验证转换后的数据是否满足特定的业务规则。
在实际编写绑定逻辑时,应当遵循以下步骤:
1. 获取请求数据并进行初步验证。
2. 执行必要的数据转换(例如,将JSON字符串转换为复杂对象)。
3. 验证转换后的数据是否符合业务逻辑和数据约束。
4. 如果在任何一个步骤中遇到错误,应当提供相应的错误信息。
为了演示更复杂的绑定逻辑,下面假设我们正在绑定一个自定义的`Person`对象,该对象包括`FirstName`、`LastName`等属性:
```csharp
public class Person
{
public string FirstName { get; set; }
public string LastName { get; set; }
// 其他相关属性
}
public class PersonModelBinder : IModelBinder
{
public Task BindModelAsync(ModelBindingContext bindingContext)
{
if (bindingContext == null)
{
throw new ArgumentNullException(nameof(bindingContext));
}
var modelName = bindingContext.ModelName;
var valueProviderResult = bindingContext.ValueProvider.GetValue(modelName);
if (valueProviderResult == ValueProviderResult.None)
{
***pletedTask;
}
var value = valueProviderResult.FirstValue;
if (string.IsNullOrEmpty(value))
{
***pletedTask;
}
// 示例:解析JSON字符串为Person对象
var person = JsonConvert.DeserializeObject<Person>(value);
// 验证Person对象的有效性
if (person == null || string.IsNullOrEmpty(person.FirstName) || string.IsNullOrEmpty(person.LastName))
{
bindingContext.ModelState.AddModelError(modelName, "Invalid person object.");
***pletedTask;
}
// 绑定成功
bindingContext.Result = ModelBindingResult.Success(person);
***pletedTask;
}
}
```
在这个例子中,我们使用`JsonConvert.DeserializeObject`方法将JSON格式的字符串解析为`Person`类型的对象。然后,我们检查`Person`对象是否有效,并将其返回给模型绑定上下文。
## 3.2 配置自定义模型绑定器
### 3.2.1 在控制器中应用自定义绑定器
在控制器中应用自定义模型绑定器,可以直接在控制器的`Action`方法参数前使用`ModelBinder`属性,指定使用的自定义绑定器。这种方式称为属性绑定。属性绑定为模型绑定提供了更细粒度的控制。
示例如下:
```csharp
[HttpPost]
public ActionResult Create([ModelBinder(BinderType = typeof(PersonModelBinder))] Person person)
{
// 在这里,person参数将由PersonModelBinder进行绑定和解析
// ...
return View();
}
```
在这个例子中,当接收到POST请求,并尝试调用`Create`方法时,`Person`类型的参数`person`将由`PersonModelBinder`进行绑定和解析。
### 3.2.2 全局配置与局部配置的对比
除了在控制器中对单个操作进行模型绑定器的配置之外,还可以在全局范围内配置模型绑定器。全局配置是在应用程序启动时完成的,因此它会影响所有操作和控制器。局部配置则是针对特定的操作或控制器进行的,提供了更灵活的配置方式。
全局配置的示例如下:
```csharp
services.AddControllers(options =>
{
options.ModelBinderProviders.Insert(0, new CustomModelBinderProvider());
});
```
`CustomModelBinderProvider`需要实现`IModelBinderProvider`接口,并在该接口的`GetBinder`方法中返回你的自定义模型绑定器。
## 3.3 自定义模型绑定器的高级特性
### 3.3.1 绑定器链的使用
在某些情况下,单一模型绑定器可能无法满足所有的绑定需求。这时,可以使用绑定器链来组合多个模型绑定器,依次尝试绑定模型直到成功。
```csharp
services.AddMvc(options =>
{
options.ModelBinderProviders.Insert(0, new BinderTypeModelBinderProvider());
});
public class BinderTypeModelBinderProvider : IModelBinderProvider
{
public IModelBinder GetBinder(ModelBinderProviderContext context)
{
// 列出可能的模型绑定器类型
var binderTypes = new List<Type>
{
typeof(MyCustomModelBinder),
typeof(AnotherCustomModelBinder),
// 其他绑定器类型...
};
// 如果在binderTypes中找到对应的绑定器类型,则创建并返回它
foreach (var binderType in binderTypes)
{
if (binderType.IsAssignableFrom(context.Metadata.ModelType))
{
return (IModelBinder)Activator.CreateInstance(binderType);
}
}
return null; // 如果没有找到,则返回null
}
}
```
在这个配置中,我们向`ModelBinderProviders`集合中插入了一个新的提供者`BinderTypeModelBinderProvider`。该提供者在`GetBinder`方法中尝试找到一个合适的绑定器来绑定模型。
### 3.3.2 异常处理和日志记录
在模型绑定的过程中,可能会出现各种异常情况,如数据格式错误、数据缺失等。为了保证系统的健壮性,需要对模型绑定器进行异常处理和日志记录,以便在出现错误时能够及时定位和解决问题。
```csharp
public class ExceptionHandlingModelBinder : IModelBinder
{
private readonly IModelBinder _innerBinder;
public ExceptionHandlingModelBinder(IModelBinder innerBinder)
{
_innerBinder = innerBinder;
}
public Task BindModelAsync(ModelBindingContext bindingContext)
{
try
{
return _innerBinder.BindModelAsync(bindingContext);
}
catch (Exception ex)
{
// 记录异常信息
bindingContext.ModelState.AddModelError(bindingContext.ModelName, ex.Message);
***pletedTask;
}
}
}
```
在`ExceptionHandlingModelBinder`中,我们对内部模型绑定器进行了包装,并在`BindModelAsync`方法中添加了异常捕获逻辑。如果捕获到异常,我们将异常信息添加到模型状态中,这样可以将错误信息展示给用户或记录到日志中。
通过这种方式,我们可以确保即使在发生异常的情况下,应用的稳定性也不会受到太大影响,同时提供了足够的信息以便后续的问题调查和修复。
至此,我们已经详细探讨了创建自定义模型绑定器的过程,包括如何实现`IModelBinder`接口、编写绑定逻辑以及如何在控制器中应用和全局配置自定义模型绑定器。我们还讨论了自定义模型绑定器的高级特性,如绑定器链的使用和异常处理,以及日志记录。在下一章节中,我们将通过实战演练深入理解如何构建一个简单的自定义模型绑定器,并处理复杂的数据类型。
# 4. 构建自定义模型绑定器
在本章中,我们将深入探讨如何实际创建和配置自定义模型绑定器,并演示如何在不同的复杂数据类型和错误处理场景下应用它。通过具体的代码示例和详细分析,我们将展示自定义模型绑定器的强大功能和灵活性。
## 构建一个简单的自定义绑定器
### 从一个具体需求开始
在开发中,经常会遇到标准模型绑定器无法满足特定场景需求的情况。例如,我们可能需要绑定一个时间范围,它由开始时间和结束时间组成。标准的模型绑定器不能直接处理这种复合类型。为了解决这一问题,我们需要创建一个能够理解这种需求的自定义模型绑定器。
### 完成绑定器的编码实现
为了创建一个自定义模型绑定器,首先需要实现`IModelBinder`接口。让我们开始编写一个名为`TimeRangeBinder`的自定义绑定器,它能够处理时间范围的绑定。
```csharp
public class TimeRangeBinder : IModelBinder
{
public Task BindModelAsync(ModelBindingContext bindingContext)
{
// 检查绑定模型是否有问题
if (bindingContext == null)
{
throw new ArgumentNullException(nameof(bindingContext));
}
// 获取模型名称
var modelName = bindingContext.ModelName;
// 尝试从模型状态中获取值
var valueProviderResult = bindingContext.ValueProvider.GetValue(modelName);
if (valueProviderResult == ValueProviderResult.None)
{
***pletedTask;
}
bindingContext.ModelState.SetModelValue(modelName, valueProviderResult);
var value = valueProviderResult.FirstValue;
if (string.IsNullOrEmpty(value))
{
***pletedTask;
}
var values = value.Split(new[] { '-' }, StringSplitOptions.RemoveEmptyEntries);
if (values.Length != 2)
{
bindingContext.ModelState.TryAddModelError(modelName, "Invalid format for timerange");
***pletedTask;
}
if (!DateTime.TryParse(values[0], out var startTime) || !DateTime.TryParse(values[1], out var endTime))
{
bindingContext.ModelState.TryAddModelError(modelName, "Invalid dates for timerange");
***pletedTask;
}
var timeRange = new TimeRange { Start = startTime, End = endTime };
bindingContext.Result = ModelBindingResult.Success(timeRange);
***pletedTask;
}
}
```
在上述代码中,`BindModelAsync`方法用于执行绑定逻辑。首先,检查是否存在绑定上下文和模型名称。然后,尝试从值提供者中获取值并验证它。如果值符合预期格式,我们将尝试解析它,并创建一个`TimeRange`对象。最后,将模型绑定结果设置为成功,并将`TimeRange`对象作为结果返回。
## 解析复杂数据类型
### 处理JSON和XML数据
在Web API中处理JSON和XML数据是非常常见的。通过自定义模型绑定器,我们可以简化这些数据类型到对象的绑定过程。假设我们有一个请求体中包含JSON格式的订单信息,需要将其绑定到一个`Order`类的实例中。
```csharp
public class Order
{
public int OrderId { get; set; }
public string CustomerName { get; set; }
// 其他属性省略...
}
```
我们可以创建一个自定义绑定器`JsonModelBinder`,用于处理JSON数据的绑定。
```csharp
public class JsonModelBinder : IModelBinder
{
public Task BindModelAsync(ModelBindingContext bindingContext)
{
if (bindingContext == null)
{
throw new ArgumentNullException(nameof(bindingContext));
}
var modelName = bindingContext.ModelName;
var valueProviderResult = bindingContext.ValueProvider.GetValue(modelName);
if (valueProviderResult == ValueProviderResult.None)
{
***pletedTask;
}
bindingContext.ModelState.SetModelValue(modelName, valueProviderResult);
var value = valueProviderResult.FirstValue;
if (string.IsNullOrEmpty(value))
{
***pletedTask;
}
try
{
var options = new JsonSerializerOptions { PropertyNameCaseInsensitive = true };
var model = JsonSerializer.Deserialize<Order>(value, options);
bindingContext.Result = ModelBindingResult.Success(model);
}
catch (JsonException)
{
bindingContext.ModelState.TryAddModelError(modelName, "Invalid JSON data");
}
***pletedTask;
}
}
```
### 集合和字典类型的绑定
在某些情况下,我们可能需要将表单数据或查询参数绑定到集合或字典类型。例如,绑定一个查询字符串`?colors=red&colors=green&colors=blue`到一个包含颜色集合的模型中。
我们可以创建一个`ListModelBinder`来处理这样的绑定。
```csharp
public class ListModelBinder : IModelBinder
{
private readonly IModelBinder elementBinder;
public ListModelBinder(IModelBinder elementBinder)
{
this.elementBinder = elementBinder ?? throw new ArgumentNullException(nameof(elementBinder));
}
public Task BindModelAsync(ModelBindingContext bindingContext)
{
if (bindingContext == null)
{
throw new ArgumentNullException(nameof(bindingContext));
}
var modelName = bindingContext.ModelName;
var valueProviderResult = bindingContext.ValueProvider.GetValue(modelName);
if (valueProviderResult == ValueProviderResult.None)
{
***pletedTask;
}
bindingContext.ModelState.SetModelValue(modelName, valueProviderResult);
var values = valueProviderResult翘起;
var list = new List<string>();
foreach (var value in values)
{
var modelState = new BindingState();
elementBinder.BindModelAsync(new ModelBindingContext
{
ModelName = modelName,
ModelType = bindingContext.ModelType,
FieldName = modelName,
BindingSource = BindingSource.Special,
ValueProvider = new SimpleValueProvider
{
{ modelName, value }
},
ModelState = modelState
});
if (modelState.ModelState.IsValid)
{
list.Add((string)modelState.Result.Model);
}
}
bindingContext.Result = ModelBindingResult.Success(list);
***pletedTask;
}
}
```
在上述代码中,`ListModelBinder`使用了一个内部`BindingState`来跟踪每个元素的绑定结果。它遍历所有值,并对每个值调用内部绑定逻辑,然后将有效的元素添加到列表中。
## 错误处理和验证
### 自定义验证逻辑的集成
在自定义模型绑定器中集成验证逻辑可以让验证过程更加直接和高效。假设我们正在处理一个用户注册表单,并希望确保密码和确认密码字段匹配。
```csharp
public class UserRegistration
{
public string Email { get; set; }
public string Password { get; set; }
public string ConfirmPassword { get; set; }
// 其他属性省略...
}
```
我们可以在`UserRegistrationBinder`中集成验证逻辑:
```csharp
// 在UserRegistrationBinder类中
if (!string.Equals(model.Password, model.ConfirmPassword))
{
bindingContext.ModelState.TryAddModelError("ConfirmPassword", "Passwords do not match");
}
```
### 异常情况下的用户提示
为了提供有用的错误消息给用户,我们需要在自定义模型绑定器中处理异常,并在用户界面上展示适当的错误提示。例如,如果绑定过程中发生异常,我们可以将这些异常转化为模型状态错误。
```csharp
try
{
// 绑定逻辑...
}
catch (Exception ex)
{
bindingContext.ModelState.TryAddModelError(bindingContext.ModelName, ex.Message);
}
```
通过上述实践,我们展示了如何构建一个简单的自定义绑定器,处理复杂数据类型,以及在错误处理和验证中集成自定义逻辑。在接下来的章节中,我们将探讨性能优化技巧和安全性注意事项,以确保我们的模型绑定器在生产环境中既高效又安全。
# 5. 性能优化和安全性考虑
## 5.1 性能优化技巧
### 5.1.1 缓存的利用
在处理Web应用程序时,性能至关重要。模型绑定器执行的工作通常涉及到从请求中提取数据并将其绑定到操作的参数上,这个过程可能会相当复杂,尤其是在处理大型数据集或复杂对象时。缓存是提高性能的有效方法之一,尤其是在模型绑定的上下文中,它可以减少数据处理的次数,加快响应时间。
缓存可以应用在多个层次上,从缓存整个HTTP请求到缓存模型绑定的中间结果不等。但是,缓存策略的选择必须谨慎,因为错误的缓存策略可能会导致数据不一致或者过多的内存消耗。例如,若数据更新频繁,则缓存的有效期应该设置得较短,以避免返回过时的数据。
```csharp
public class CachedModelBinder : IModelBinder
{
private readonly IModelBinder _decoratedBinder;
private readonly IMemoryCache _cache;
public CachedModelBinder(IModelBinder decoratedBinder, IMemoryCache cache)
{
_decoratedBinder = decoratedBinder;
_cache = cache;
}
public Task BindModelAsync(ModelBindingContext bindingContext)
{
var cacheKey = $"model_{bindingContext.ModelName}";
if (_cache.TryGetValue(cacheKey, out var cachedValue))
{
bindingContext.Result = ModelBindingResult.Success(cachedValue);
***pletedTask;
}
var result = _decoratedBinder.BindModelAsync(bindingContext).Result;
if (result.IsModelSet)
{
var model = result.Model;
// 设置缓存项,例如过期时间等
_cache.Set(cacheKey, model, new MemoryCacheEntryOptions
{
// 例如使用滑动过期
SlidingExpiration = TimeSpan.FromMinutes(5)
});
}
***pletedTask;
}
}
```
在上述代码中,`CachedModelBinder`类通过缓存中间结果来优化性能。它首先检查缓存中是否已存在之前的结果,如果存在,则直接返回,避免了重复的数据处理。如果缓存中没有,则执行原始的绑定器,然后将结果缓存起来以供将来使用。
缓存的实现依赖于`IMemoryCache`接口,这需要在依赖注入容器中配置好相应的缓存服务。缓存的键(key)需要能够唯一标识绑定上下文,否则可能会引起数据冲突或数据污染。
### 5.1.2 异步绑定的实现
在高流量的应用中,异步编程可以避免线程阻塞,释放线程资源用于其他操作,从而提升应用的吞吐量。模型绑定作为Web请求处理流程的一部分,实现异步操作可以进一步优化性能。
在C#中,异步操作通常通过`async`和`await`关键字来实现。在模型绑定的上下文中,异步绑定意味着模型绑定器可以异步地从请求中提取数据,而不会占用线程。
```csharp
public class AsyncModelBinder : IAsyncModelBinder
{
public async Task BindModelAsync(ModelBindingContext bindingContext)
{
if (bindingContext == null)
{
throw new ArgumentNullException(nameof(bindingContext));
}
var modelName = bindingContext.ModelName;
var valueProviderResult = bindingContext.ValueProvider.GetValue(modelName);
if (valueProviderResult != ValueProviderResult.None)
{
bindingContext.ModelState.SetModelValue(modelName, valueProviderResult);
var model = await SomeAsyncOperation(valueProviderResult.FirstValue);
bindingContext.Result = ModelBindingResult.Success(model);
}
}
private async Task<YourModelType> SomeAsyncOperation(string input)
{
// 这里是异步操作的代码,例如从数据库异步加载数据
// 返回值应当与绑定上下文中的ModelType相匹配
return await Task.FromResult(new YourModelType());
}
}
```
在代码示例中,`AsyncModelBinder`实现了`IAsyncModelBinder`接口。`BindModelAsync`方法中,我们首先从值提供者(`ValueProvider`)获取模型名称(`modelName`)对应的数据,然后执行了一个异步操作来加载数据,并返回了模型绑定的结果。这里的关键是使用了`await`关键字,它使得`SomeAsyncOperation`方法异步执行,而不会阻塞线程。
要使用异步模型绑定器,需要在控制器或动作方法上应用特定的特性,如`[ModelBinder]`特性,并指定异步绑定器。
```csharp
public class MyController : Controller
{
[HttpPost]
public async Task<IActionResult> MyActionAsync(
[ModelBinder(typeof(AsyncModelBinder))] MyModel model)
{
// Action方法的实现
}
}
```
异步绑定器为Web请求处理提供了一个高效、非阻塞的数据加载方式,有助于提升Web应用程序的性能。
## 5.2 安全性注意事项
### 5.2.1 防止模型绑定漏洞
模型绑定是一个强大但同时可能带来安全风险的功能。一个常见的问题是在Web应用程序中对用户输入的数据处理不当,这可能导致安全漏洞,例如SQL注入或跨站脚本攻击(XSS)。开发者需要意识到这些风险,并采取适当措施来防止它们。
防止模型绑定漏洞的一个关键步骤是在模型绑定之前验证和清理输入数据。首先,应当确保所有输入数据都经过了验证,以符合预期的格式。其次,对从模型绑定器中获取的数据进行适当的清理,避免执行或传递任何未经验证或不受信任的数据到后端系统中。
```csharp
public class SafeModelBinder : IModelBinder
{
private readonly IModelBinder _decoratedBinder;
public SafeModelBinder(IModelBinder decoratedBinder)
{
_decoratedBinder = decoratedBinder;
}
public Task BindModelAsync(ModelBindingContext bindingContext)
{
if (bindingContext == null)
{
throw new ArgumentNullException(nameof(bindingContext));
}
// 假设我们有一个验证器来检查和清理数据
if (bindingContext.ValueProvider.GetValue("someData").FirstValue == "unsafe")
{
bindingContext.ModelState.AddModelError(
bindingContext.ModelName, "Invalid data detected.");
bindingContext.Result = ModelBindingResult.Failed();
***pletedTask;
}
return _decoratedBinder.BindModelAsync(bindingContext);
}
}
```
在`SafeModelBinder`中,我们首先从值提供者获取名为`someData`的数据,然后根据业务规则进行验证。如果数据被标记为不安全,则拒绝绑定并记录错误,防止进一步的数据处理。
### 5.2.2 输入验证的最佳实践
为了确保输入数据的安全性,开发者需要在模型绑定之前应用输入验证的最佳实践。以下是一些关键的建议:
- **使用数据注解:*** Core 提供了数据注解(Data Annotations),这是一种声明式方式,在模型类上直接标记属性,例如`[Required]`、`[EmailAddress]`、`[Range]`等,来指定验证规则。
- **自定义验证属性:**如果内置的验证规则无法满足需求,可以创建自定义验证属性(Custom Validation Attributes),通过实现`ValidationAttribute`类并重写`IsValid`方法来定义自己的验证逻辑。
- **模型状态检查:**在控制器的动作方法中,应当检查`ModelState.IsValid`来验证绑定的数据。如果数据不合法,则返回相应的错误信息。
- **过滤敏感信息:**在绑定和验证的过程中,过滤掉不需要的或敏感的字段,防止它们被错误地使用或暴露。
- **持续测试:**使用集成测试和单元测试来确保验证逻辑按预期工作,从而保障应用程序的安全性。
```csharp
public class User
{
[Required(ErrorMessage = "Name is required")]
public string Name { get; set; }
[EmailAddress(ErrorMessage = "Invalid email address")]
public string Email { get; set; }
[Range(18, 99, ErrorMessage = "Age must be between 18 and 99")]
public int Age { get; set; }
}
[ApiController]
[Route("[controller]")]
public class UserController : ControllerBase
{
[HttpPost]
public IActionResult RegisterUser([FromBody] User user)
{
if (!ModelState.IsValid)
{
return BadRequest(ModelState);
}
// 注册用户的代码逻辑
return Ok("User registered successfully");
}
}
```
在上述例子中,`User`类使用数据注解来强制验证输入数据。在控制器的动作方法`RegisterUser`中,通过检查`ModelState.IsValid`来确定用户数据是否有效。如果验证失败,将返回相应的错误信息给客户端。
总结来说,良好的输入验证实践不仅可以提高应用程序的用户体验,还可以有效地防止潜在的安全风险,这是构建安全Web应用程序的重要一步。
# 6. 进阶应用和最佳实践
在C#的模型绑定实践中,我们已经探讨了基础知识和创建自定义模型绑定器的过程。本章节将深入探索一些更为复杂的绑定场景,并分享在实际开发过程中如何通过最佳实践来提升代码的质量和可维护性。最后,我们将展望自定义模型绑定的未来,看看它将如何与C#的演进和其他编程范式相结合。
## 6.1 探索复杂的绑定场景
在许多实际应用中,可能会遇到需要将数据绑定到基类或接口的复杂场景。自定义模型绑定器提供了灵活性,以适应这些复杂情况。
### 6.1.1 绑定到基类和接口
在某些情况下,我们可能需要绑定的模型是某个基类的实例,或者是一个接口的实现。在自定义模型绑定器中,我们可以这样处理:
```csharp
public class BaseClass
{
public string CommonProperty { get; set; }
}
public class DerivedClass : BaseClass
{
public string AdditionalProperty { get; set; }
}
public class BaseClassBinder : IModelBinder
{
public Task BindModelAsync(ModelBindingContext bindingContext)
{
if (bindingContext == null)
{
throw new ArgumentNullException(nameof(bindingContext));
}
// 获取绑定的基类属性
var modelType = bindingContext.ModelType;
var model = Activator.CreateInstance(modelType);
var properties = modelType.GetProperties();
foreach (var property in properties)
{
// 这里可以根据需要进行特殊处理,例如转换等
var valueProviderResult = bindingContext.ValueProvider.GetValue(property.Name);
if (valueProviderResult != ValueProviderResult.None)
{
var value = valueProviderResult.FirstValue;
if (!string.IsNullOrEmpty(value))
{
// 进行类型转换
var convertedValue = Convert.ChangeType(value, property.PropertyType);
property.SetValue(model, convertedValue);
}
}
}
bindingContext.Result = ModelBindingResult.Success(model);
***pletedTask;
}
}
```
### 6.1.2 依赖注入与模型绑定的集成
依赖注入是现代应用程序设计中的一项关键技术,它也可以和模型绑定集成起来。通过在模型绑定器中使用依赖注入,可以让绑定逻辑更加清晰和可测试。
```csharp
public class CustomModelBinder : IModelBinder
{
private readonly ILogger _logger;
private readonly ICustomService _customService;
public CustomModelBinder(ILogger<CustomModelBinder> logger, ICustomService customService)
{
_logger = logger;
_customService = customService;
}
public async Task BindModelAsync(ModelBindingContext bindingContext)
{
// 使用_logger和_customService执行逻辑...
}
}
```
在全局配置或具体控制器中,你可以配置模型绑定器,使其能够利用依赖注入:
```csharp
public void ConfigureServices(IServiceCollection services)
{
services.AddMvc(options =>
{
options.ModelBinderProviders.Insert(0, new CustomModelBinderProvider());
});
}
public class CustomModelBinderProvider : IModelBinderProvider
{
public IModelBinder GetBinder(ModelBinderProviderContext context)
{
if (context == null)
{
throw new ArgumentNullException(nameof(context));
}
if (context.Metadata.ModelType == typeof(DerivedClass))
{
return new BinderTypeModelBinder(typeof(CustomModelBinder));
}
return null;
}
}
```
## 6.2 最佳实践分享
最佳实践能够帮助开发者编写出更加高效、可靠且易于维护的代码。以下是一些在实现自定义模型绑定器时应当遵循的最佳实践。
### 6.2.1 代码复用和DRY原则
遵循DRY(Don't Repeat Yourself)原则,确保你的模型绑定逻辑尽可能地复用。创建可重用的组件和工具,可以减少代码的冗余并提高维护效率。
### 6.2.2 社区资源和框架支持
充分利用社区资源和现有的框架支持可以极大地提升开发效率。例如,*** Core已经内置了许多有用的模型绑定器和绑定器提供者,你可以基于这些内置功能构建更加复杂的绑定器。
## 6.3 自定义模型绑定的未来展望
随着C#语言的不断演进,以及现代编程范式的出现,自定义模型绑定器的应用场景和能力也在不断扩展。
### 6.3.1 新版C#中模型绑定的改进
新版的C#语言引入了更多的特性,如异步流(`IAsyncEnumerable`)和模式匹配,这些都将对模型绑定产生深远的影响。开发者可以期待在未来的框架版本中,能够更方便地处理复杂类型和异步数据。
### 6.3.2 与现代化编程范式的结合
函数式编程和响应式编程等现代化编程范式,正在逐渐影响着我们开发应用程序的方式。自定义模型绑定器如何与这些范式结合,为开发者提供更加强大和灵活的数据处理能力,将是未来的一个重要方向。
通过这一章节的探讨,我们可以看到自定义模型绑定器的潜力和未来发展方向。在开发实践中,开发者应当持续关注这些趋势,以便在工作中应用最前沿的技术,提高项目的整体质量和效率。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0

专栏简介
本专栏深入探讨了 C# 中 ASP.NET 模型绑定的方方面面,从入门指南到高级技巧。它揭秘了模型绑定机制,指导读者打造高效的数据处理流程,并分享了最佳实践,包括源码解析和数据转换验证。专栏还涵盖了自定义模型绑定的新特性、异步编程的深度结合、错误处理和调试策略,以及性能优化秘诀。此外,它还探讨了数据校验、多租户架构设计、复杂对象处理和单元测试等高级主题。通过深入的分析、代码示例和实际案例研究,本专栏为开发者提供了全面的指南,帮助他们掌握 C# 模型绑定并构建高效、健壮的 Web 应用程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Git大师课】:精通版本控制,提升项目效率的10个必备策略
# 摘要
Git作为现代软件开发中不可或缺的版本控制系统,其理论基础、基础操作和高级特性对团队协作和项目管理具有深远影响。本文旨在深入探讨Git的初始化、基本配置以及核心命令行操作,并着重讲解了版本控制的最佳实践,包括提交信息规范和分支模型选择。进一步地,文章详细阐述了Git的高级特性,如自定义钩子、标签管理以及版本发布流程,这些高级功能对维护项目健康和推进自动化工作流至关重要。在
打造响应式表单设计:JavaScript与HTML5的完美结合

# 摘要
响应式表单设计对于适应多样化的用户界面和提升用户体验至关重要。本文首先阐述了响应式表单设计的重要性和基础概念。随后,详细讨论了HTML5和CSS3在实现响应式表单中的具体应用,包括表单元素和属性的利用,视觉效果的增强,以及兼容性与适配问题的处理。第三章深入探讨了JavaScript在实现高级响应式表单功能方面的应用,如表单验证技术、动态行为以及性能优化与调试。第四章通过实际案例分析了响
【SEMI E5-0301深度解读】:提升产线效率与设备互操作性的终极指南

# 摘要
SEMI E5-0301标准作为半导体行业内部通信与设备集成的关键规范,对促进产线自动化和提高设备互操作性具有至关重要的作用。本文首先概述了SEMI E5-0301
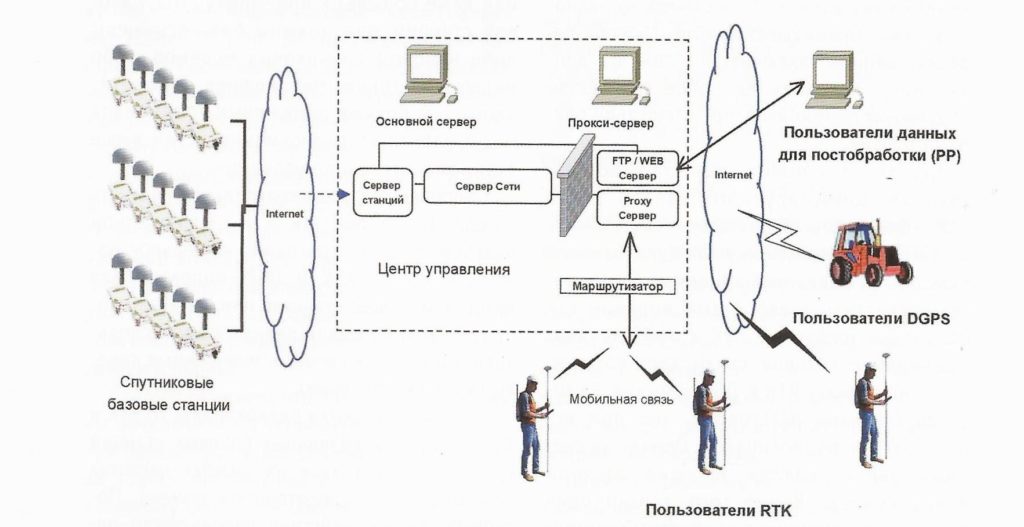
精准定位攻略
# 摘要
精准定位技术在移动设备、物联网以及室内外环境中的应用对于现代信息技术至关重要。本文首先探讨了精准定位的理论基础,随后介绍了数据分析与定位技术的策略、方法和应用。通过案例分析,深入研究了移动设备和物联网设备在不同场景下的精确定位实践。此外,文章还探讨了定位系统的优化与创新,并展望了精准定位技术未来的发展趋势及其面临的市场挑战与机遇。本文旨在为相关领域的研究者和从业者提供理论和实践上的指导,推动精准定
【网络延迟与数据同步解决方案】:确保Web远程控制的流畅性
# 摘要
本文综述了网络延迟与数据同步的基本概念、影响因素、技术原理及实践中的解决方案,并探讨了确保Web远程控制流畅性的综合策略。文章详细
用例图优化技巧:病房监护系统设计质量全面提升

# 摘要
病房监护系统用例图作为系统分析与设计阶段的关键文档,对于明确系统需求、指导系统开发和维护具有至关重要的作用。本文第一章介绍了用例图的基础知识,第二章探讨了设计原则及与UML其他视图的整合,第三章分享了用例图的实践应用技巧及常见问题解决方案。第四章讨论了用例图的优化方法及其与系统
【数据洞察】:家庭财务数据深度分析与数据库报表生成(数据分析篇)
# 摘要
家庭财务数据的管理和分析对于个人理财具有重要意义。本文从数据概述与重要性开始,详细介绍了数据收集、预处理的方法和技巧,并深入分析了财务数据,包括基础和高级分析技术。进一步地,本文探讨了数据库报表设计与实时数据分析的实现,以及如何保护家庭财务数据的安全与隐私。最后,文章展望了未来人工智能和大数据技术在家庭财务数据管理与分析领域的潜在应用和趋势,强调了这些技术在提升
【VMware Appliance部署专家】:ACS5.2河蟹版安装与优化实践大全

# 摘要
本文主要介绍了VMware Appliance的基础知识、ACS5.2河蟹版的安装与准备工作,以及安装后的系统优化策略和高级应
Fortran 8.0高级特性全面剖析:面向对象编程与类型扩展

# 摘要
本文旨在全面介绍Fortran 8.0语言,特别是在面向对象编程(OOP)方面的理论基础与实践应用。文章首先概述了Fortran 8.0的基本特性,并深入探讨了OOP的核心概念,包括类与对象、封装、继承及多态,并分析了其在Fortran中的具体实现方式。接着,文章探讨了类型扩展和模块化编程的原理与技术,以及这些技术如何促进代码的模块化和重用。在
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )