Kubernetes核心组件解析及部署实践
发布时间: 2024-03-06 01:56:35 阅读量: 35 订阅数: 21 

Kubernetes 实践指南
# 1. Kubernetes简介
Kubernetes(容器编排引擎)是一个开源的容器编排引擎,可以自动化地部署、扩展和操作应用程序容器。在本章中,我们将介绍Kubernetes的基本概念、优势和特点,以及它的核心组件。
## 1.1 什么是Kubernetes
Kubernetes是一个用于自动化容器化应用程序部署、扩展和管理的开源平台。它最初由Google开发,现已成为Cloud Native Computing Foundation(CNCF)的一部分。Kubernetes提供了一个强大的平台,使开发人员能够轻松地构建、部署和运行容器化应用程序。
## 1.2 Kubernetes的优势和特点
Kubernetes具有以下优势和特点:
- 自动化部署和扩展:Kubernetes可以自动部署和扩展容器化应用程序,根据负载自动调整应用程序实例数量。
- 服务发现与负载均衡:Kubernetes提供了内置的服务发现和负载均衡功能,使应用程序能够轻松地相互通信。
- 自愈能力:Kubernetes可以自动检测和替换出现故障的容器实例,确保应用程序的高可用性。
- 滚动升级和回滚:Kubernetes支持滚动升级和回滚应用程序的版本,以确保最小化对用户的影响。
- 多环境支持:Kubernetes可以在各种公共云、私有云和混合云环境中部署和运行应用程序。
## 1.3 Kubernetes的核心概念
在使用Kubernetes时,需要理解以下核心概念:
- Pod:是Kubernetes中最小的调度单位,可以包含一个或多个容器。
- Deployment:用于定义和管理应用程序的部署,确保指定数量的Pod实例在集群中运行。
- Service:用于定义一组Pod实例的访问方式,提供负载均衡和服务发现能力。
- Namespace:用于在集群中创建多个虚拟集群,并对资源进行隔离和限制访问。
通过学习这些概念,可以更好地理解和使用Kubernetes来管理容器化应用程序。
# 2. Kubernetes核心组件解析
Kubernetes的核心组件主要分为Master节点的组件和Node节点的组件。在本章中,我们将深入解析它们的功能和作用,帮助读者更好地理解Kubernetes的架构和运行机制。
### 2.1 Master节点的核心组件
Master节点是整个Kubernetes集群的控制中心,负责管理集群的状态和执行集群的操作。其核心组件包括:
#### 2.1.1 etcd
etcd是Kubernetes集群中的分布式键值存储系统,用于保存集群的状态数据和配置信息。它是Kubernetes的“大脑”,负责存储集群的各种信息,包括节点信息、Pod信息、Service信息等。etcd的稳定性和可靠性对整个集群的运行至关重要。
```go
// 示例代码:使用etcd的Go客户端向etcd中写入数据
package main
import (
"context"
"log"
"time"
"go.etcd.io/etcd/clientv3"
)
func main() {
cli, err := clientv3.New(clientv3.Config{
Endpoints: []string{"http://etcd1.example.com:2379", "http://etcd2.example.com:2379", "http://etcd3.example.com:2379"},
DialTimeout: 5 * time.Second,
})
if err != nil {
log.Fatal(err)
}
defer cli.Close()
ctx, cancel := context.WithTimeout(context.Background(), time.Second)
_, err = cli.Put(ctx, "key1", "value1")
cancel()
if err != nil {
log.Fatal(err)
}
}
```
**代码说明:** 以上示例代码演示了一个使用etcd的Go客户端向etcd写入数据的过程。首先创建etcd的客户端,然后通过Put方法向etcd中存入键值对,其中包括要存储的键“key1”和对应的值“value1”。
#### 2.1.2 kube-apiserver
kube-apiserver是Kubernetes集群的API服务端,负责提供HTTP REST接口,供其他组件和外部用户访问和操作集群。所有的操作和资源管理都是通过kube-apiserver来实现的,它是集群内所有操作的入口。
```yaml
# 示例代码:kube-apiserver的配置文件示例
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
```
**代码说明:** 以上示例是一个Pod的配置文件,通过kube-apiserver可以使用类似的配置文件创建、更新、删除Pod等操作。
#### 2.1.3 kube-controller-manager
kube-controller-manager是Kubernetes集群中运行的控制器管理器,负责处理集群中各种资源对象的状态。它通过控制器来确保集群的状态符合预期,并调节集群的状态至预期状态。
```go
// 示例代码:自定义控制器的实现示例
package main
import (
"fmt"
"time"
"k8s.io/client-go/tools/cache"
"k8s.io/client-go/util/workqueue"
)
func main() {
queue := workqueue.NewRateLimitingQueue(workqueue.DefaultControllerRateLimiter())
indexer, informer := newInformer()
controller := newController(indexer, queue)
go controller.Run(2, time.Second, stopCh)
fmt.Println("Controller started")
select {}
}
```
**代码说明:** 以上示例代码展示了一个自定义控制器的实现,通过使用client-go库中的工具和缓存来创建控制器,并运行一个循环监视队列来处理事件。
#### 2.1.4 kube-scheduler
kube-scheduler是Kubernetes集群中的调度器,负责为新创建的Pod选择合适的Node来运行。它根据Pod的资源需求、调度策略等信息,将Pod调度到合适的Node节点上运行。
```go
// 示例代码:自定义调度算法示例
package main
import (
"fmt"
"k8s.io/api/core/v1"
)
func main() {
pods := []v1.Pod{pod1, pod2, pod3} // 假设有三个Pod需要调度
for _, pod := range pods {
node := myScheduler(pod) // 使用自定义的调度算法为Pod选择合适的Node
fmt.Printf("Pod %s 被调度到 Node %s 运行\n", pod.Name, node)
}
}
func myScheduler(pod v1.Pod) string {
// 自定义调度算法的具体实现
// ...
}
```
**代码说明:** 以上示例代码展示了一个简单的自定义调度算法示例,通过实现自定义的调度算法来为Pod选择合适的Node节点进行运行。
### 2.2 Node节点的核心组件
Node节点是Kubernetes集群中的工作节点,负责运行应用程序和管理容器化的工作负载。其核心组件包括:
#### 2.2.1 kubelet
kubelet是运行在每个Node节点上的代理,负责管理容器的生命周期、监控容器的运行状态、执行容器的创建和销毁等操作。
```yaml
# 示例代码:kubelet的配置文件示例
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
```
**代码说明:** 以上示例是一个Pod的配置文件,kubelet通过读取类似的配置文件来创建和管理Pod。
#### 2.2.2 kube-proxy
kube-proxy是Kubernetes集群中的网络代理,负责为Pod创建网络规则和转发规则。它通过维护网络规则来实现集群内部的服务发现、负载均衡等网络功能。
```yaml
# 示例代码:kube-proxy的配置文件示例
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
```
**代码说明:** 以上示例是一个Service的配置文件,kube-proxy通过维护类似的配置来实现Service的代理和转发功能。
#### 2.2.3 容器运行时(Container Runtime)
容器运行时是Kubernetes集群中的容器运行时引擎,负责管理容器的生命周期、执行容器的创建和销毁、管理容器的资源等。常见的容器运行时包括Docker、containerd等。
```yaml
# 示例代码:Pod中容器的运行时配置示例
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
runtimeClassName: "docker" # 指定容器运行时为Docker
```
**代码说明:** 以上示例展示了一个Pod中容器的运行时配置示例,通过runtimeClassName字段指定了容器的运行时引擎为Docker。
以上就是Kubernetes核心组件的详细解析,通过深入理解这些组件的功能和作用,读者可以更好地掌握Kubernetes的架构和运行机制。
# 3. Kubernetes网络与存储
Kubernetes作为一个容器编排平台,提供了丰富的网络与存储支持,本章将深入探讨Kubernetes的网络模型、网络插件、存储模型以及存储插件。
### 3.1 网络模型与插件
在Kubernetes中,每个Pod都有自己的IP地址,并且所有的Pod都可以相互通信,这是通过Kubernetes的网络模型来实现的。Kubernetes中常用的网络模型包括:
- Pod间通信的网络模型
- 容器访问外部网络的网络模型
常用的网络插件包括:
- Flannel
- Calico
- Cilium
- Weave Net
### 3.2 存储模型与插件
Kubernetes提供了丰富的存储支持,包括持久化存储卷、存储类别等,常用的存储插件包括:
- NFS
- GlusterFS
- Ceph
- Rook
通过本章的学习,读者将能够深入了解Kubernetes中网络与存储相关的核心概念和实践应用,为构建稳定可靠的Kubernetes集群提供帮助。
以上是第三章内容,希望对您有所帮助!
# 4. Kubernetes部署实践
在本章中,我们将介绍如何在实际场景中部署和管理Kubernetes集群,包括创建Kubernetes集群、部署应用程序以及扩展和管理Kubernetes集群。让我们逐步深入了解这些内容。
### 4.1 创建Kubernetes集群
#### 场景描述:
假设我们需要在三台虚拟机上创建一个简单的Kubernetes集群,其中一台作为Master节点,另外两台作为Worker节点。
#### 代码示例:
```python
# 使用kubeadm在Master节点上初始化Kubernetes集群
kubeadm init
# 将Worker节点加入Kubernetes集群
kubeadm join <Master节点的IP>:<端口号> --token <token> --discovery-token-ca-cert-hash <hash值>
```
#### 代码总结:
上述代码中,我们首先在Master节点上使用`kubeadm init`初始化Kubernetes集群,然后在每个Worker节点上使用`kubeadm join`命令将它们加入到集群中。
#### 结果说明:
成功执行以上代码后,我们将在三台虚拟机上成功创建一个简单的Kubernetes集群。
### 4.2 部署应用程序
#### 场景描述:
现在我们将在创建好的Kubernetes集群上部署一个简单的Web应用程序,比如一个基本的Nginx服务。
#### 代码示例:
```java
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
```
#### 代码总结:
以上代码是一个简单的Deployment配置,定义了一个名为`nginx-deployment`的Deployment,指定了副本数为3,使用Nginx镜像,并将容器端口暴露为80。
#### 结果说明:
部署该应用程序后,Kubernetes集群将会运行3个Nginx实例,可以通过Service暴露服务以对外提供访问。
### 4.3 扩展和管理Kubernetes集群
#### 场景描述:
为了确保Kubernetes集群的高可用性和性能,我们需要定期对集群进行扩展和管理,包括添加新的节点、更新应用程序、监控集群状态等。
#### 代码示例:
```go
// 在集群中添加新的Worker节点
kubectl scale --replicas=3 deployment/nginx-deployment
// 使用Horizontal Pod Autoscaler自动扩展应用程序
kubectl autoscale deployment nginx-deployment --min=3 --max=5 --cpu-percent=80
```
#### 代码总结:
上述代码演示了如何通过kubectl命令手动扩展Deployment的副本数,以及如何设置Horizontal Pod Autoscaler来自动根据CPU使用率扩展应用程序。
#### 结果说明:
通过定期的扩展和管理操作,我们可以保证Kubernetes集群的稳定性和可靠性,确保应用程序能够高效运行并满足业务需求。
通过本章的实践,我们深入了解了如何创建Kubernetes集群、部署应用程序以及扩展和管理集群,这些内容对于理解Kubernetes的实际应用至关重要。希望读者通过实践能够更好地掌握Kubernetes的部署和管理技能。
# 5. Kubernetes集群安全
Kubernetes作为一个强大的容器编排平台,安全性一直是使用者关注的焦点。在部署和管理Kubernetes集群时,必须重视集群的安全性,包括认证与授权、网络安全以及容器安全等方面。
## 5.1 认证与授权
认证(Authentication)和授权(Authorization)是Kubernetes集群安全的重要组成部分。认证是确定用户/实体的身份,而授权是确定用户/实体有权执行的操作。
在Kubernetes中,常见的认证方式包括:
- X.509 证书
- Service Account
- OpenID Connect Token
授权方面,Kubernetes使用RBAC(Role-Based Access Control)来控制对集群资源的访问权限。管理员可以为不同角色分配不同的权限,确保集群的安全性。
以下是一个使用Service Account进行认证的Python示例代码:
```python
from kubernetes import client, config
config.load_kube_config()
v1 = client.CoreV1Api()
ret = v1.list_pod_for_all_namespaces(watch=False)
for i in ret.items:
print(i.metadata.name)
```
**代码说明:**
- 通过 `config.load_kube_config()` 载入Kubernetes配置
- 使用 `client.CoreV1Api()` 创建CoreV1Api实例
- 通过 Service Account 认证访问集群中的所有Pod信息
## 5.2 网络安全
Kubernetes集群中的网络安全也至关重要。通过Network Policy可以定义网络规则,控制Pod之间的通信流量,从而限制不必要的网络暴露和提高安全性。
另外,使用网络插件(如Calico、Flannel等)可以帮助构建安全的集群网络,实现网络隔离、流量加密等功能,保护集群免受网络攻击。
以下是一个使用Calico网络策略的Java示例代码:
```java
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-db-access
spec:
podSelector:
matchLabels:
app: mydb
policyTypes:
- Ingress
- Egress
ingress:
- from:
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 3306
egress:
- to:
- podSelector:
matchLabels:
role: backend
ports:
- protocol: TCP
port: 3306
```
**代码说明:**
- 定义了一个名为 `allow-db-access` 的网络策略,允许 `frontend` Pod 访问 `mydb` Pod 的 3306 端口,以及 `mydb` Pod 访问 `backend` Pod 的 3306 端口。
## 5.3 容器安全
容器安全是Kubernetes集群安全的重要组成部分。在部署容器时,需要注意以下几点来提高容器安全性:
- 使用不同的Namespace隔离应用
- 避免特权容器的使用
- 定期更新镜像,确保应用组件不受已知安全漏洞影响
- 启用安全上下文(Security Context)和容器资源限制
Kubernetes提供了一些安全特性和最佳实践,管理员和开发者应该结合实际情况,全面考虑集群的安全性。
通过以上对Kubernetes集群安全的介绍,希望可以为您的Kubernetes安全实践提供一些参考和指导。
# 6. Kubernetes最佳实践与未来发展
Kubernetes作为目前最流行的容器编排平台之一,在实际应用中有许多最佳实践值得我们借鉴。同时,随着技术的不断发展,Kubernetes也在不断完善与演进。本章将介绍一些Kubernetes的最佳实践指南以及未来发展方向。
#### 6.1 最佳实践指南
在实际应用Kubernetes时,有一些最佳实践可以帮助我们更好地使用和管理Kubernetes集群。以下是一些实践建议:
- **资源管理**:合理规划和管理Pod的资源,包括CPU和内存。可以通过Resource Quotas来限制每个Namespace的资源使用情况。
- **横向扩展**:充分利用Kubernetes的横向扩展能力,合理设置Pod的副本数量和自动伸缩策略。
- **监控与日志**:使用合适的监控和日志系统来监控集群和应用程序的健康状态,例如Prometheus和EFK(Elasticsearch、Fluentd、Kibana)等。
- **安全策略**:制定合适的安全策略,包括网络安全和容器安全,保障集群的安全稳定运行。
#### 6.2 Kubernetes未来发展方向
Kubernetes作为容器编排领域的领军者,其未来发展方向备受关注。未来Kubernetes可能在以下方向进行进一步的发展:
- **支持更多工作负载类型**:除了容器之外,Kubernetes可能会支持更多类型的工作负载,如VM、Serverless等。
- **更加智能的调度器**:将进一步优化调度算法,实现更智能的资源调度和工作负载调度。
- **更丰富的生态系统**:Kubernetes的生态系统可能会更加丰富,支持更多的插件和扩展,为用户提供更多选择。
- **更强大的运维能力**:进一步完善Kubernetes的运维能力,包括更全面的监控、日志、安全策略等方面的支持。
总的来说,Kubernetes作为一个开源项目,其未来发展方向将会更加多样化和智能化,为用户提供更加强大和便利的容器编排服务。
希望这些内容能给您带来一些启发和帮助!

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【EDA课程进阶秘籍】:优化仿真流程,强化设计与仿真整合

# 摘要
随着集成电路设计复杂性的增加,EDA(电子设计自动化)课程与设计仿真整合的重要性愈发凸显。本文全面探讨了EDA工具的基础知识与应用,强调了设计流程中仿真验证和优化的重要性。文章分析了仿真流程的优化策略,包括高
DSPF28335 GPIO故障排查速成课:快速解决常见问题的专家指南

# 摘要
本文详细探讨了DSPF28335的通用输入输出端口(GPIO)的各个方面,从基础理论到高级故障排除策略,包括GPIO的硬件接口、配置、模式、功能、中断管理,以及在实践中的故障诊断和高级故障排查技术。文章提供了针对常见故障类型的诊断技巧、工具使用方法,并通过实际案例分析了故障排除的过程。此外,文章还讨论了预防和维护GPIO的策略,旨在帮助
掌握ABB解包工具的最佳实践:高级技巧与常见误区

# 摘要
本文旨在介绍ABB解包工具的基础知识及其在不同场景下的应用技巧。首先,通过解包工具的工作原理与基础操作流程的讲解,为用户搭建起使用该工具的初步框架。随后,探讨了在处理复杂包结构时的应用技巧,并提供了编写自定义解包脚本的方法。文章还分析了在实际应用中的案例,以及如何在面对环境配置错误和操
【精确控制磁悬浮小球】:PID控制算法在单片机上的实现
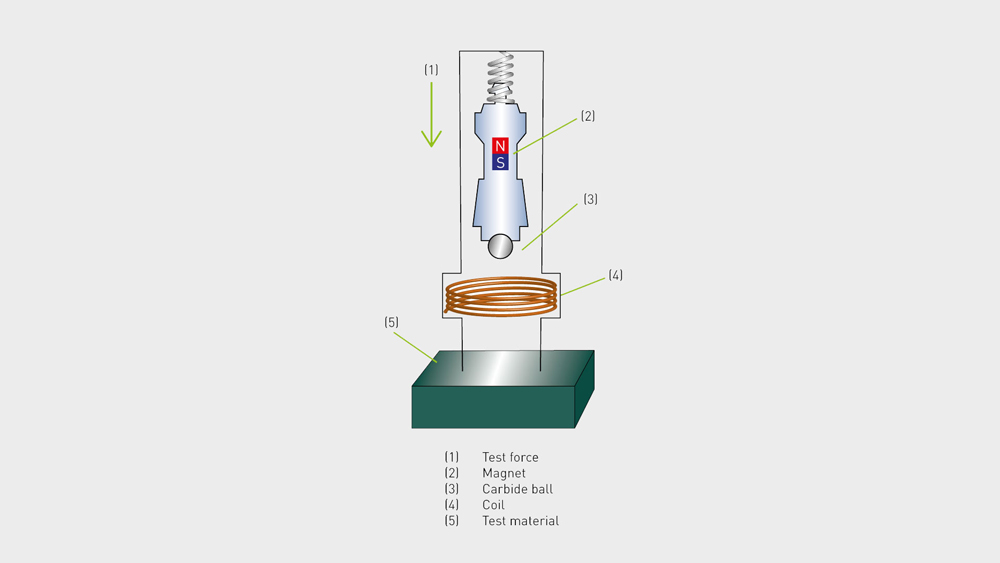
# 摘要
本文综合介绍了PID控制算法及其在单片机上的应用实践。首先概述了PID控制算法的基本原理和参数整定方法,随后深入探讨了单片机的基础知识、开发环境搭建和PID算法的优化技术。通过理论与实践相结合的方式,分析了PID算法在磁悬浮小球系统中的具体实现,并展示了硬件搭建、编程以及调试的过程和结果。最终,文章展望了PID控制算法的高级应用前景和磁悬浮技术在工业与教育中的重要性。本文旨在为控制工程领
图形学中的纹理映射:高级技巧与优化方法,提升性能的5大策略
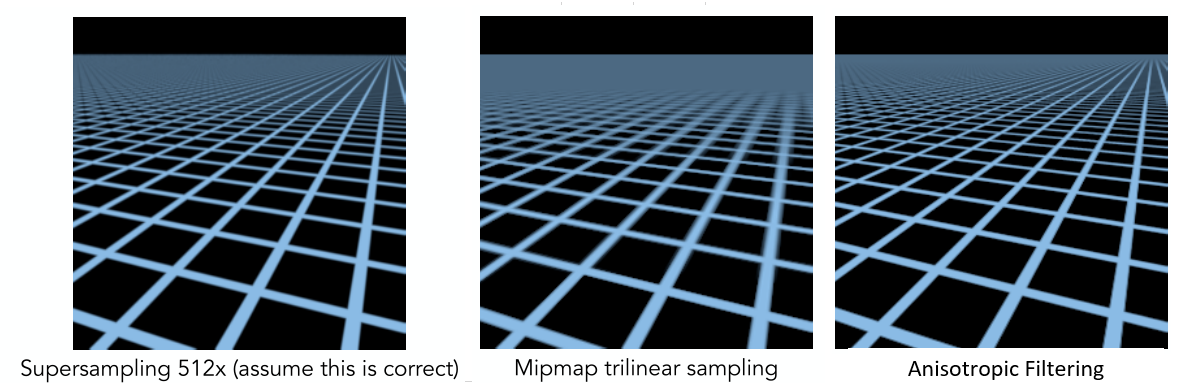
# 摘要
本文系统地探讨了纹理映射的基础理论、高级技术和优化方法,以及在提升性能和应用前景方面的策略。纹理映射作为图形渲染中的核心概念,对于增强虚拟场景的真实感和复杂度至关重要。文章首先介绍了纹理映射的基本定义及其重要性,接着详述了不同类型的纹理映射及应用场景。随后,本文深入探讨了高级纹理映射技术,包括纹理压缩、缓存与内存管理和硬件加速,旨在减少资源消耗并提升
【Typora插件应用宝典】:提升写作效率与体验的15个必备插件
# 摘要
本论文详尽探讨了Typora这款Markdown编辑器的界面设计、编辑基础以及通过插件提升写作效率和阅读体验的方法。文章首先介绍了Typora的基本界面与编辑功能,随后深入分析了多种插件如何辅助文档结构整理、代码编写、写作增强、文献管理、多媒体内容嵌入及个性化定制等方面。此外,文章还讨论了插件管理、故障排除以及如何保证使用插件时
RML2016.10a字典文件深度解读:数据结构与案例应用全攻略
# 摘要
本文全面介绍了RML2016.10a字典文件的结构、操作以及应用实践。首先概述了字典文件的基本概念和组成,接着深入解析了其数据结构,包括头部信息、数据条目以及关键字与值的关系,并探讨了数据操作技术。文章第三章重点分析了字典文件在数据存储、检索和分析中的应用,并提供了实践中的交互实例。第四章通过案例分析,展示了字典文件在优化、错误处理、安全分析等方面的应用及技巧。最后,第五章探讨了字典文件的高
【Ansoft软件精通秘籍】:一步到位掌握电磁仿真精髓
# 摘要
本文详细介绍了Ansoft软件的功能及其在电磁仿真领域的应用。首先概述了Ansoft软件的基本使用和安装配置,随后深入讲解了基础电磁仿真理论,包括电磁场原理、仿真模型建立、仿真参数设置和网格划分的技巧。在实际操作实践章节中,作者通过多个实例讲述了如何使用Ansoft HFSS、Maxwell和Q3D Extractor等工具进行天线、电路板、电机及变压器等的电磁仿真。进而探讨了Ansoft的高级技巧
负载均衡性能革新:天融信背后的6个优化秘密
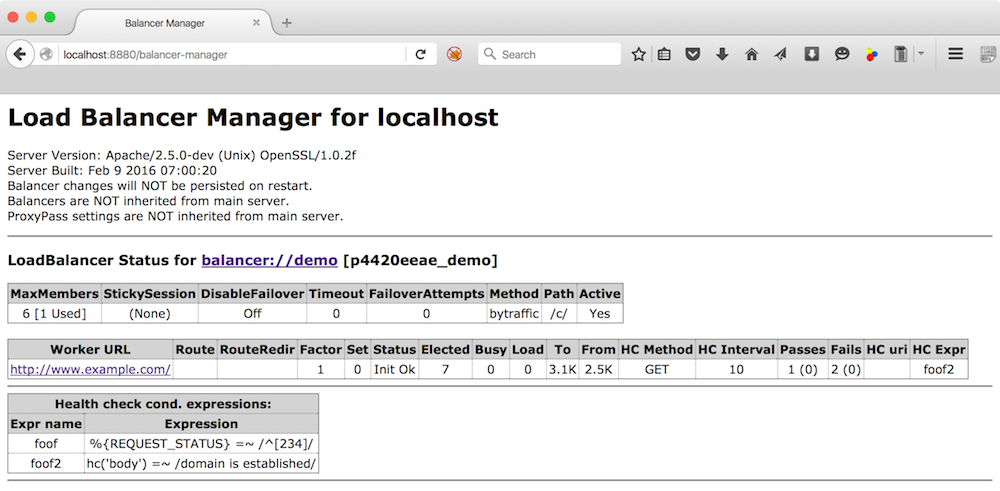
# 摘要
负载均衡技术是保障大规模网络服务高可用性和扩展性的关键技术之一。本文首先介绍了负载均衡的基本原理及其在现代网络架构中的重要性。继而深入探讨了天融信的负载均衡技术,重点分析了负载均衡算法的选择标准、效率与公平性的平衡以及动态资源分配机制。本文进一步阐述了高可用性设计原理,包括故障转移机制、多层备份策略以及状态同步与一致性维护。在优化实践方面,本文讨论了硬件加速、性能调优、软件架构优化以及基于AI的自适应优化算法。通过案例
【MAX 10 FPGA模数转换器时序控制艺术】:精确时序配置的黄金法则
# 摘要
本文主要探讨了FPGA模数转换器时序控制的基础知识、理论、实践技巧以及未来发展趋势。首先,从时序基础出发,强调了时序控制在保证FPGA性能中的重要性,并介绍了时序分析的基本方法。接着,在实践技巧方面,探讨了时序仿真、验证、高级约束应用和动态时序调整。文章还结合MAX 10 FPGA的案例,详细阐述了模数转换器的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )