【数据科学新手】:Anaconda中的Pandas与NumPy安装与配置秘籍
发布时间: 2024-12-15 17:35:18 阅读量: 7 订阅数: 5 

详解Pycharm与anaconda安装配置指南
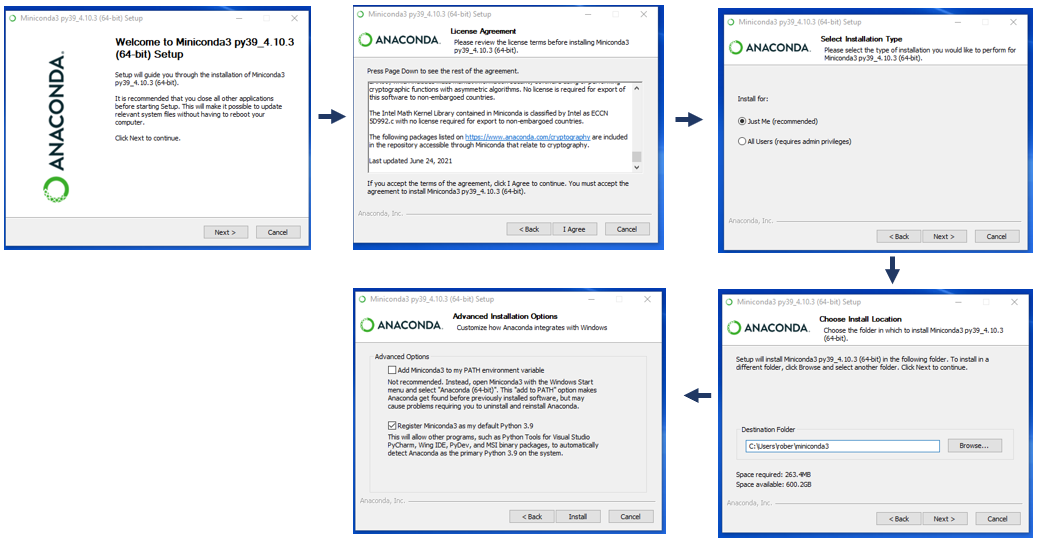
参考资源链接:[图文详述:Anaconda for Python的高效安装教程](https://wenku.csdn.net/doc/5cnjdkbbt6?spm=1055.2635.3001.10343)
# 1. 数据科学与Anaconda概述
在当今数字化时代,数据分析和机器学习已经成为推动科技创新的重要力量。数据科学家们利用各种工具和库,从海量数据中提取有价值的信息,为决策提供支持。其中,Python作为一种易于学习且功能强大的编程语言,在数据科学领域享有盛誉。Python在数据科学中的核心地位离不开众多强大的库,而Anaconda作为集成了大多数数据科学常用库的发行版,极大地简化了安装和配置过程,成为了数据科学工作流中的必备工具。
Anaconda不仅仅是一个Python发行版,它还是一个集成了包管理器和环境管理器的平台。Anaconda提供了conda命令行工具,使得用户能够便捷地安装和更新包、创建独立的环境等,极大地提高了工作效率。此外,Anaconda附带了丰富的预装包,其中包括了数据科学的重量级库Pandas、NumPy、Scikit-learn等。
在进入数据科学和机器学习的世界之前,理解Anaconda的工作原理和安装配置方法是非常必要的。这样可以确保在后续的学习和项目开发过程中,能够顺利地搭建起一个稳定高效的工作环境。接下来,我们将详细探讨如何安装和配置Anaconda,以及如何使用Anaconda创建数据科学项目。
# 2. Pandas库的基础安装与配置
## 2.1 Pandas库简介及安装流程
### 2.1.1 Pandas的定义和作用
Pandas是一个开源的Python数据分析库,它提供了高性能、易用的数据结构以及数据分析工具。它由Wes McKinney在2008年创建,并在金融领域得到了广泛的使用。Pandas的主要数据结构包括Series和DataFrame。Series是一维数组,而DataFrame则是二维表格结构,可以看作是一个表格或矩阵。Pandas库允许用户进行数据清洗、数据转换、数据合并、数据筛选等操作,极大地简化了数据分析的过程。
### 2.1.2 Pandas的安装步骤
#### 2.1.2.1 通过Anaconda安装
对于使用Anaconda的用户来说,安装Pandas相当简单。只需通过Anaconda Navigator的图形用户界面或者使用conda命令行工具即可进行安装。
使用conda命令行安装Pandas:
```
conda install pandas
```
#### 2.1.2.2 通过pip安装
如果用户选择使用pip作为主要的包管理工具,也可以通过以下命令来安装Pandas库:
```
pip install pandas
```
#### 2.1.2.3 检查Pandas安装状态
安装完成后,通过在Python解释器中执行以下代码,可以验证Pandas是否成功安装:
```python
import pandas as pd
print(pd.__version__)
```
如果安装成功,将显示Pandas库的版本号。
## 2.2 Pandas的基本数据结构
### 2.2.1 Series对象的理解与操作
Series是Pandas中最基本的数据结构之一,它是一个一维的数组结构,能够存储任何数据类型(整数、字符串、浮点数、Python对象等),并带有轴标签,这些标签统称为索引。轴标签通常用于从电子表格或数据库表中获取数据。
#### 2.2.1.1 Series的创建
可以通过列表或数组来创建Series对象。
```python
import pandas as pd
data = [1, 2, 3, 4, 5] # 列表
series = pd.Series(data)
print(series)
```
#### 2.2.1.2 索引与切片
Series的索引是它的核心特征,它允许我们通过标签访问数据。
```python
# 访问Series的特定元素
print(series[0]) # 输出第一个元素
print(series[1:4]) # 输出第二个至第四个元素
```
### 2.2.2 DataFrame对象的理解与操作
DataFrame是Pandas中最主要的数据结构,它是一个二维的、大小可变的、潜在异质型表格数据结构,带有索引。可以将其看作是一个电子表格或SQL表,或一个字典的集合。
#### 2.2.2.1 DataFrame的创建
使用字典来创建一个简单的DataFrame。
```python
import pandas as pd
data = {
'Column1': [1, 2, 3],
'Column2': ['a', 'b', 'c']
}
df = pd.DataFrame(data)
print(df)
```
#### 2.2.2.2 DataFrame的索引设置
DataFrame的索引可以是任何数据类型,包括字符串和时间序列。
```python
# 修改DataFrame索引
df.index = ['Row1', 'Row2', 'Row3']
print(df)
```
## 2.3 Pandas的配置与优化
### 2.3.1 环境配置的最佳实践
配置Pandas环境时,需要考虑以下几个方面:
- **内存管理**:使用适当的内存大小,以确保处理大数据集时不会耗尽内存。
- **并行处理**:启用并行计算可显著提高数据处理速度。
- **缓存策略**:合理配置缓存设置,以加速数据访问。
```python
# 设置Pandas的选项,例如显示的最大行数
pd.set_option('display.max_rows', 10)
```
### 2.3.2 性能优化技巧
性能优化是一个持续的过程,以下是一些常见的性能优化技巧:
- **选择合适的数据类型**:使用适当的数据类型来减少内存占用。
- **向量化操作**:尽可能使用Pandas的向量化操作,避免在循环中进行逐元素的操作。
- **利用Categorical数据类型**:对于重复的类别数据,使用Categorical数据类型可以节省内存并加速处理。
```python
# 将某列设置为Categorical类型
df['CategoryColumn'] = df['CategoryColumn'].astype('category')
```
通过上述方法,可以有效地提高Pandas在数据处理中的性能。在后续章节中,我们将深入探讨如何将Pandas与NumPy等其他库结合,进一步优化数据分析流程。
# 3. NumPy库的基础安装与配置
NumPy是一个强大的Python库,它支持大量的维度数组与矩阵运算,此外也针对数组运算提供了大量的数学函数库。它在数据分析、科学计算、机器学习等领域有着广泛应用。
## 3.1 NumPy库简介及安装流程
### 3.1.1 NumPy的定义和作用
NumPy是Numerical Python的简称,是一个开源的Python科学计算库。它提供了高性能的多维数组对象,以及用于处理这些数组的工具。通过使用NumPy,我们可以轻松地实现数组操作,并利用其丰富的函数库执行复杂的数学运算,从而在数据处理和分析时提高效率。
### 3.1.2 NumPy的安装步骤
安装NumPy通常非常直接,我们可以使用pip包管理器来安装它。以下是一个标准的安装步骤:
```bash
pip install numpy
```
如果是Python 2的环境,可能需要使用pip3来安装:
```bash
pip3 install numpy
```
完成安装后,可以在Python环境中导入NumPy库来确认是否安装成功:
```python
import numpy
print(numpy.__version__)
```
如果打印出了版本号,则说明NumPy安装成功。
## 3.2 NumPy的基础操作与数组结构
### 3.2.1 多维数组的理解与创建
NumPy的核心是多维数组对象——ndarray。这个ndarray对象提供了大量的属性和方法来处理数组。下面是如何创建一个一维数组和一个二维数组的例子:
```python
import numpy as np
# 创建一维数组
o
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
PSAT-2.0.0-ref功能详解:性能分析中的关键作用大揭秘

参考资源链接:[PSAT 2.0.0 中文使用指南:从入门到精通](https://wenku.csdn.net/doc/6412b6c4be7fbd1778d47e5a?spm=1055.2635.3001.10343)
# 1. PSAT-2.0.0-ref概述及安装
## 1.1 PSAT-2.0.0-ref简介
PSAT-2.0.0-ref是一个强大的性能分析工具,被广泛应用于I
【图层管理深度解析】:掌握SolidWorks打印优化技巧,提升输出质量!

参考资源链接:[solidworks2012工程图打印不黑、线型粗细颜色的设置](https://wenku.csdn.net/doc/6412b72dbe7fbd1778d495df?spm=1055.2635.3001.10343)
# 1. 图层管理基础
图层管理是现代CAD(计算机辅助设计)软件中不可或缺的一部分,尤其是在处
【遥感数据处理秘籍】:用Modtran破解大气影响的奥秘

参考资源链接:[MODTRAN软件使用详解:大气透过率计算指南](https://wenku.csdn.net/doc/6412b69fbe7fbd1778d47636?spm=1055.2635.3001.10343)
# 1. 遥感数据处理概述
遥感数据处理是一个涉及多个步骤的复杂过程,其目的是从远程感测器收集的原始信号中提取有用信息。遥感技术广泛应用于气象预测、环境监测、城市规划以及军事侦察等领域。
VMware演进秘籍:从vSphere到最新版的十大变革
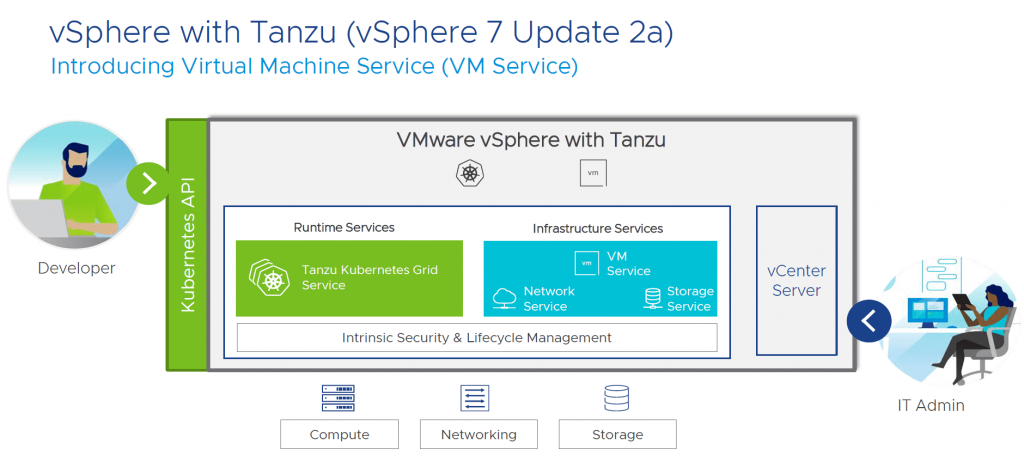
参考资源链接:[VMware产品详解:Workstation、Server、GSX、ESX和Player对比](https://wenku.csdn.net/doc/6493fbba9aecc961cb34d21f?spm=1055.2635.3001.10343)
# 1. VMware vSphere的核心概念与技术革新
## 1.1 虚拟化技术的历史
Allegro 16.6基础操作:新手也能实现快速上手
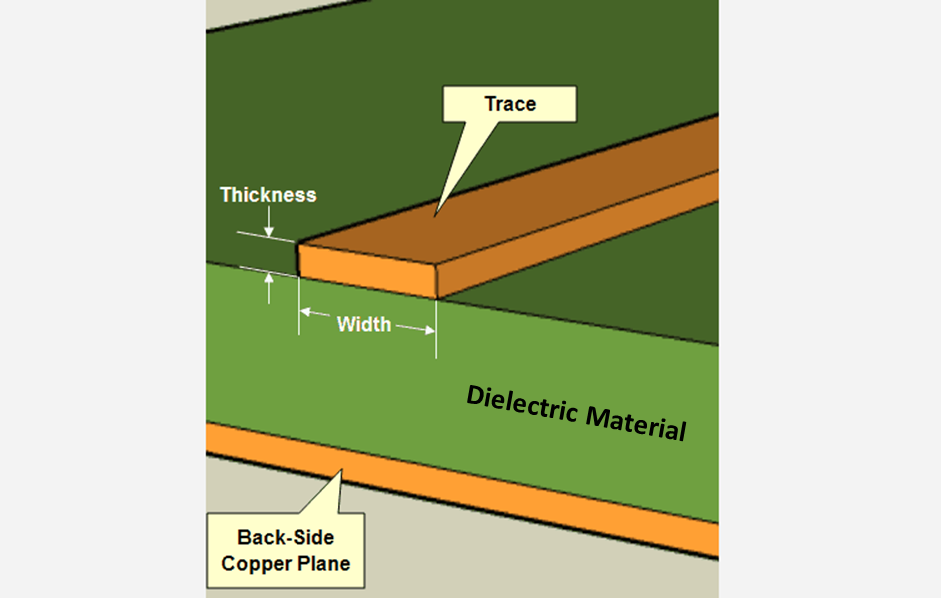
参考资源链接:[Allegro16.6约束管理器:线宽、差分、过孔与阻抗设置指南](https://wenku.csdn.net/doc/x9mbxw1bnc?spm=1055.2635.3001.10343)
# 1. Allegro 16.6简介与安装
## 简介
Allegro是Cadence公司推出的一款专业级PCB设计工具,广泛应用于电子行业,尤其在高速、多层板设计领域具
【计算机视觉的10个关键概念】:深入理解图像识别与深度学习的联姻
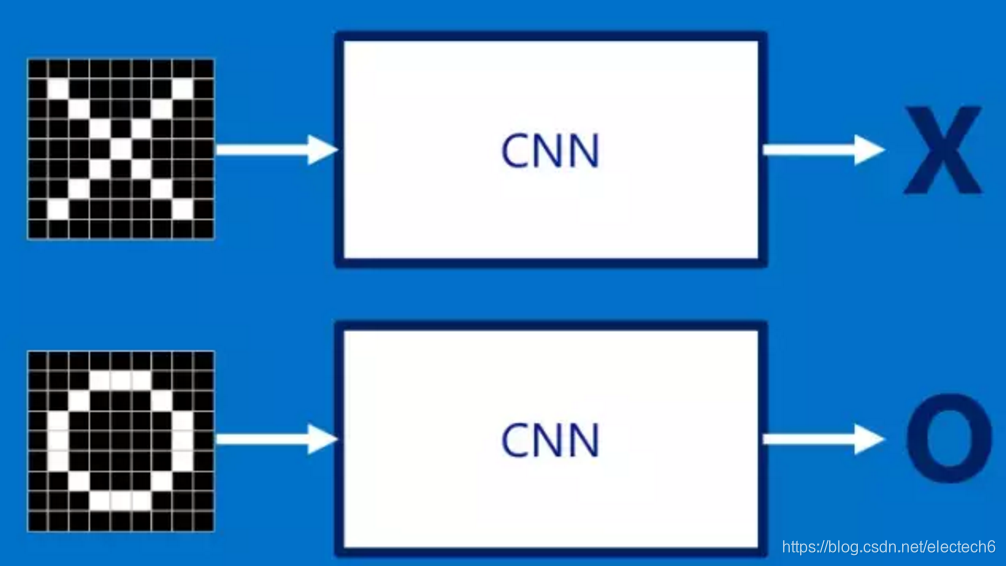
参考资源链接:[山东大学2020年1月计算机视觉期末考题:理论与实践](https://wenku.csdn.net/doc/6460a7c1543f844
单片机原理深度剖析:蓝桥杯竞赛知识点精粹
参考资源链接:[蓝桥杯单片机国赛历年真题合集(2011-2021)](https://wenku.csdn.net/doc/5ke723avj8?spm=1055.2635.3001.10343)
# 1. 单片机基础知识概述
## 单片机的概念与发展历程
单片机(Microcontroller Unit,MCU)是将微处理器(CPU)、内存(RAM)、只读内存(ROM)、输入/输出接口(I/O ports)和各
矩阵运算的优雅处理:进阶版线性代数解析

参考资源链接:[兰大版线性代数习题答案详解:覆盖全章节](https://wenku.csdn.net/doc/60km3dj39p?spm=1055.2635.3001.10343)
# 1. 线性代数的基本概念和矩阵运算
线性
层次化设计在DX Designer中的应用:轻松管理大型电路项目

参考资源链接:[PADS DX Designer中文教程:探索EE7.9.5版](https://wenku.csdn.net/doc/6412b4cebe7fbd1778d40e2b?spm=1055.2635.3001.10343)
# 1. 层次化设计概述
## 1.1 设计复杂性的挑战
随着科技的快速发展,IT行业的复杂性与日俱增,工程师们面临的挑战是如何在保证设计质量的同时,高效完成项
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )