文本处理专家指南:Linux工具在APPN104平台的应用
发布时间: 2024-12-19 05:19:27 阅读量: 4 订阅数: 1 

03-APPN104(V1.06)-FMQL系列开发平台Linux应用教程-基于AG102.pdf
# 摘要
本文对Linux文本处理工具及其应用进行了全面的介绍和探讨。首先,概览了Linux文本处理的常用工具,然后从理论基础讲起,包括文本文件的结构、编码标准,以及文本处理命令如grep、sed和awk的应用。接着,文章深入介绍了文本处理实践技巧,包括数据的提取、过滤、转换和重组,以及文本处理的自动化。在应用层面,分析了文本处理在APPN104平台上的具体应用,重点探讨了日志分析、配置文件管理和数据处理报告的生成。最后,文章讨论了复杂文本处理场景的分析、性能优化以及文本处理技术的未来发展趋势,展望了人工智能在文本分析中的应用和开源工具的贡献。
# 关键字
Linux文本处理;编码标准;正则表达式;自动化脚本;性能优化;人工智能
参考资源链接:[FMQL系列Linux应用教程(v1.06)- AG102开发平台详解](https://wenku.csdn.net/doc/1vqr2r9di3?spm=1055.2635.3001.10343)
# 1. Linux文本处理工具概览
Linux操作系统作为IT领域的基石,拥有丰富的文本处理工具,这些工具是日常运维和开发工作中不可或缺的帮手。本章将带您快速了解Linux文本处理工具的概览,为后续深入学习和应用打下坚实的基础。
## 1.1 Linux中的文本处理工具
Linux系统中常见的文本处理工具有grep、sed、awk、cut、sort、uniq等。这些工具以强大的文本操作功能和流处理模式,广泛应用于数据提取、过滤、转换和重组等任务中。理解并掌握这些工具的使用,对于提高工作效率、进行自动化处理以及数据分析都具有重要意义。
## 1.2 为什么选择Linux文本处理工具
文本处理是处理日志、配置文件和数据分析等任务的日常需求。相比图形界面工具或复杂的编程语言,Linux文本处理工具轻量高效,易于自动化。它们能够通过简单的命令行指令快速完成复杂的文本操作,从而帮助用户节省时间,提升工作效率。
本章通过初步介绍Linux文本处理工具的种类和重要性,为后续章节的深入探讨奠定基础。在接下来的内容中,我们将详细讨论文本处理工具的理论基础,并通过实践技巧,深入探索文本处理工具在不同场景中的应用。
# 2. 文本处理理论基础
## 2.1 文本文件的结构和编码
### 2.1.1 ASCII和Unicode编码差异
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是一种用于字符编码的标准,旨在用于电子通讯。它主要用于显示现代英语和其他西欧语言。它是现代字符编码的起源,并且奠定了现代编码系统的基础。ASCII码使用7位二进制数(bit)来表示128个不同的字符,包括大小写英文字母、数字、标点符号和控制字符。
Unicode是一个国际标准,旨在为世界上所有的字符提供一个唯一的数字表示。它是一个统一的、全球的编码系统,可以表示来自任何语言的字符。Unicode使用16位二进制数(bit),因此它可以表示2^16,即65536个不同的字符。由于这个数量比ASCII码多得多,它能够覆盖几乎所有人类语言中的字符。
二者的差异在于,ASCII编码只能表示128个字符,适用于英文文本处理,而Unicode能够覆盖几乎全球所有字符,适用于多语言文本处理。在文本处理工具的选择和使用上,考虑到文件内容的国际化,Unicode已经成为一个更加通用和推荐的选择。
### 2.1.2 文本文件格式标准
文本文件格式标准定义了文本文件的结构和存储方式,这些标准对于文本处理工具的开发和使用至关重要。文本文件格式可以分为两大类:纯文本和富文本。
纯文本文件(Plain Text)是由字符组成的简单文本文件,没有复杂的格式和格式控制命令。它仅包含字符数据,不包含任何关于如何显示的指令或信息。纯文本文件通常采用UTF-8编码,因为它兼容ASCII且能够表示Unicode字符。Linux命令行工具通常处理的是纯文本文件。
富文本文件(Rich Text)包含了格式化的信息,例如字体样式、颜色、大小等。一个典型的富文本格式是RTF(Rich Text Format),它允许文本处理软件存储和交换格式化文本。但是,富文本文件往往更难以处理,因为它们不仅仅是字符数据,还包括了格式数据。
在文本处理过程中,文本文件的格式标准需要被识别和理解,这样文本处理工具才能正确地进行数据提取、转换和输出。
## 2.2 常用文本处理命令
### 2.2.1 grep的模式匹配技术
`grep`是一个在文本文件中查找模式(pattern)并打印匹配行的强大的工具。它的名字来自于`global regular expression print`的首字母缩写。
模式匹配技术包括基本正则表达式(BRE)和扩展正则表达式(ERE)。`grep`默认使用BRE,并可以通过`-E`选项使用ERE。模式可以包含普通字符和特殊字符。普通字符匹配它们自身,而特殊字符(如`*`、`?`、`[]`、`{}`、`()`、`|`等)具有特殊的含义,它们定义了模式匹配的规则。
**示例:**
```bash
grep 'error' /var/log/syslog
```
此命令会检查`/var/log/syslog`文件中包含"error"这个词的所有行。
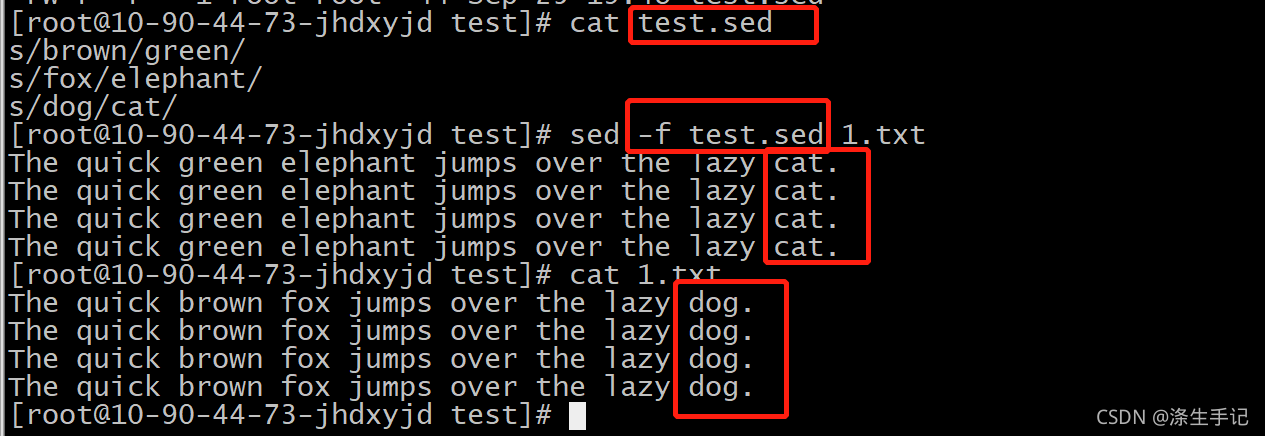
### 2.2.2 sed和awk的流编辑器功能
`sed`(stream editor)是一个用于对文本进行流编辑的命令。它通过脚本来处理文本,一次处理一行,并可以执行各种文本处理任务,如插入、删除、替换或转换文本数据。
**示例:**
```bash
sed 's/old_string/new_string/g' filename
```
这将把`filename`文件中所有的`old_string`替换为`new_string`。
`awk`是一个用于模式扫描和处理的编程语言。`awk`自动将输入的文本行分割成记录(通常是换行符分隔),并进一步分割成字段(通常是空格分隔)。它允许用户编写小程序来对这些字段进行复杂的处理。
**示例:**
```bash
awk '{print $1}' filename
```
这将打印`filename`文件中每行的第一个字段。
在处理文本时,`sed`和`awk`经常被一起使用,因为它们可以非常灵活地处理流式文本数据。通过组合这些工具,用户可以创建复杂的文本处理任务和自动化脚本,从而提高工作效率。
## 2.3 文本处理的正则表达式
### 2.3.1 正则表达式的基本规则
正则表达式是一串字符和符号,它定义了一个搜索模式。这个模式可能是一个字面字符,也可能是一个更复杂的结构。正则表达式广泛应用于文本处理工具中,如`grep`、`sed`、`awk`、`find`等,它们通过正则表达式来识别和处理文本。
正则表达式的基本元素包括:
- **字面值匹配**:匹配输入字符串中的单个字符。例如,正则表达式`hello`将匹配任何包含"hello"的字符串。
- **元字符**:包括点号(`.`)、星号(`*`)、加号(`+`)、问号(`?`)、方括号(`[]`)等,它们有特殊含义并用于构建复杂的模式。
- **字符集**:用方括号表示,允许匹配一系列字符中的任何一个。例如,`[abc]`将匹配任何包含`a`、`b`或`c`的字符串。
- **边界匹配**:如脱字符(`^`)和美元符号(`$`)分别匹配行的开始和结束。
- **特殊字符的转义**:用反斜杠(`\`)转义那些在正则表达式中具有特殊意义的字符。
**示例:**
```bash
grep '192\.168\.[0-9]+\.[0-9]+' /etc/network/interfaces
```
此命令会匹配IP地址,其中IP地址的前两部分是固定的,而后面的两部分是任意数字。
### 2.3.2 正则表达式的高级匹配技巧
正则表达式不仅限于简单匹配,它还提供高级匹配技巧,包括:
- **分组和捕获**:通过圆括号来创建子表达式,可以在匹配的同时捕获一部分字符串供后续使用。例如,`(a|b|c)`会匹配`a`、`b`或`c`中的任意一个字符。
- **回溯引用**:使用`\1`、`\2`等表示法,引用前面分组中匹配到的字符串。例如,`([a-z]+)\1`将匹配重复的单词。
- **前瞻和后顾**:用于检查匹配的部分前后是否满足某些条件,但不消耗字符。前瞻使用`(?=...)`,后顾使用`(?!...)`。例如,`(?<=foo)bar`将匹配`bar`,如果`bar`前面是`foo`,但不包括`foo`在内的匹配结果中。
- **量词**:用于指定一个元素可以出现的次数。包括贪婪量词(如`*`匹配零次或多次)和非贪婪量词(如`*?`匹配尽可能少的次数)。
**示例:**
```bash
grep '^\s*[0-9]+\s*;' /path/to/file
```
此命令使用了量词`*`和边界匹配符`^`与`$`,匹配以任意数量的空白符开始,后跟一个或多个数字,最后是分号的行。
正则表达式是文本处理的核心技术之一,熟练使用正则表达式对于进行复杂的数据提取、过滤和转换至关重要。
# 3. 文本处理实践技巧
在前一章节中,我们探讨了文本处理的理论基础,包括文本文件的结构与编码、常用文本处理命令,以及正则表达式的相关知识。这些基础知识为接下来探讨实践技巧奠定了坚实的基础。在本章节中,我们将进一步深入,具体介绍如何在实际工作中应用这些理论知识来解决具体问题。
## 3.1 数据提取和过滤
文本数据提取和过滤是文本处理中非常常见的需求。这包括从大量数据中找到符合特定模式的行,提取感兴趣的数据字段,以及排除不需要的信息。`grep`和`awk`是实现这些功能的两个非常重要的命令。
### 3.1.1 使用grep进行数据检索
`grep`(Global Regular Expression Print)是一个强大的文本搜索工具,它使用正则表达式搜索文本,并打印匹配的行。`grep`命令的基本使用方法是:
```bash
grep [options] pattern [files]
```
- `[options]`:代表 grep 命令的选项,比如`-i`用于忽略大小写,`-r`用于递归搜索等。
- `pattern`:要搜索的正则表达式模式。
- `[files]`:一个或多个文件名,指定在哪个文件或文件集上执行搜索。
下面是一个具体的例子,搜索`/var/log/syslog`文件中所有的"error"日志行:
```bash
grep "error" /var/log/syslog
```
`grep`的高级用法还可以通过扩展正则表达式实现更复杂的模式匹配。例如,下面的命令搜索包含"error"或"warn"的行:
```bash
grep -E "error|warn" /var/log/syslog
```
### 3.1.2 利用awk进行字段提取
`awk`是一个用于模式扫描和处理的编程语言,非常适合于从文件中提取特定的列或字段。`awk`默认按照空格分隔数据,并对每一行进行逐行处理。
`awk`命令的基本形式如下:
```bash
awk 'pattern {action}' file
```
- `pattern`:指定要处理的数据行的模式。
- `{action}`:对匹配`pattern`的行所执行的操作。
例如,下面的命令从`/etc/passwd`文件中提取用户名和用户ID:
```bash
awk -F: '{print $1, $3}' /etc/passwd
```
这里`-F:`指定了输入字段的分隔符为冒号(`:`),`{print $1, $3}`则打印出第一和第三个字段。
`awk`能够提供非常灵活的文本处理能力,可以配合数组、循环、条件语句等实现复杂的文本数据处理逻辑。在实践中,通过合理地构造`pattern`和`action`,`awk`能解决大量文本数据的提取和过滤需求。
## 3.2 数据转换和重组
数据转换和重组是指对文本文件中的数据进行重新格式化或转换,以满足特定的输出格式要求。这是文本处理中非常实用的一环,`sed`和`tr`是这方面的两个常用工具。
### 3.2.1 sed命令在文本替换中的应用
`sed`(stream editor)是流编辑器,可以对文本进行过滤和转换。`sed`命令的基本形式如下:
```bash
sed [options] 'command' file
```
- `[options]`:指定`sed`命令的选项,例如`-i`用于直接修改文件内容。
- `'command'`:定义要执行的操作,比如插入、删除、替换文本等。
- `file`:要处理的文件。
`sed`的替换命令格式为:
```bash
sed 's/pattern/replacement/' file
```
这里`s`表示替换操作,`pattern`是要替换的文本,`replacement`是替换后的文本。例如,将`/var/log/syslog`文件中所有的"error"替换成"ERROR":
```bash
sed 's/error/ERROR/g' /var/log/syslog
```
这个命令中的`g`标志表示全局替换,即在每一行中替换所有出现的"error"。
### 3.2.2 使用tr进行字符集转换
`tr`(translate)命令用于对来自标准输入的字符进行转换或删除操作。使用`tr`可以快速地实现字符集的转换或者删除特定字符。`tr`的命令形式如下:
```bash
tr [options] set1 [set2]
```
- `[options]`:可选项,例如`-d`用于删除字符集中的字符。
- `set1`:需要被操作的字符集。
- `set2`:替换`set1`中的字符。
例如,将`textfile.txt`中的所有小写字母转换为大写:
```bash
tr 'a-z' 'A-Z' < textfile.txt
```
这里使用了重定向`<`将`textfile.txt`的内容传递给`tr`命令。
`tr`命令非常适合于快速处理文本数据,特别是在文本预处理和清洗阶段。
## 3.3 文本处理自动化
文本处理自动化是提高工作效率的重要手段。通过构建管道命令和编写脚本,可以实现对复杂文本数据的快速处理。
### 3.3.1 构建管道命令实现复杂处理
管道命令是UNIX和Linux系统中将一个程序的输出作为另一个程序输入的一种方式。通过管道(`|`),我们可以将多个命令组合起来,形成一个处理流水线,以解决更复杂的数据处理任务。例如,我们可以结合`grep`、`awk`和`sed`来实现对日志文件的复杂分析:
```bash
cat /var/log/syslog | grep "error" | awk '{print $5}' | sort | uniq
```
这个命令串联了四个不同的文本处理工具:
- `cat`列出`/var/log/syslog`文件的内容。
- `grep`过滤出包含"error"的行。
- `awk`提取出这些行的第五个字段(通常为日期)。
- `sort`对结果进行排序。
- `uniq`去除重复的行。
通过这种方式,我们可以快速地从日志文件中提取出包含错误的日志条目的日期,且只显示唯一出现的日期。
### 3.3.2 脚本编写提升工作效率
为了提高效率,我们可以将经常需要执行的管道命令写入一个shell脚本。这样,每次需要执行该命令时,只需要运行脚本即可。例如,创建一个名为`extract_errors.sh`的脚本:
```bash
#!/bin/bash
# extract_errors.sh
cat /var/log/syslog | grep "error" | awk '{print $5}' | sort | uniq > errors.txt
```
然后通过以下命令给脚本添加执行权限:
```bash
chmod +x extract_errors.sh
```
之后,运行脚本:
```bash
./extract_errors.sh
```
运行后,所有包含"error"的日志条目日期将被提取出来并保存在`errors.txt`文件中。通过编写脚本,我们不仅能够快速地处理复杂的数据,还能够实现任务的自动化。
脚本的编写需要对shell编程有一定的了解,包括变量、条件判断、循环等基本的编程概念。一旦掌握了这些知识,就可以编写出功能更加强大和复杂的自动化脚本,从而在工作中实现效率的大幅提升。
在本章节中,我们具体介绍了文本处理中的数据提取和过滤技巧,数据转换和重组方法,以及自动化处理的实践。这些内容通过实际例子来讲解,希望能够帮助读者更好地理解并应用这些技巧到实际工作中。通过掌握这些实践技巧,可以显著提高文本数据处理的效率和准确性。
# 4. 文本处理在APPN104平台的应用
## 4.1 针对APPN104的日志分析
### 4.1.1 日志文件的结构和重要字段
在APPN104平台上,日志文件是诊断和解决网络问题的关键资源。日志文件通常包含了一系列记录,这些记录反映了网络设备在不同时间点的状态和事件。日志文件的结构一般包括时间戳、日志级别、消息类型、来源设备、事件描述等信息。
重要字段包括但不限于:
- **时间戳**:记录事件发生的准确时间,有助于追踪问题发生的历史。
- **日志级别**:表示事件的严重性,例如INFO、WARNING、ERROR等。
- **消息类型**:表明了事件的类型,比如设备连接、认证失败或配置更改等。
- **来源设备**:标识了生成日志的设备或接口,有助于快速定位问题设备。
- **事件描述**:提供有关事件的具体信息,是解决问题的最直接依据。
为了提高日志处理的效率,必须熟悉这些字段,以便于使用文本处理工具对日志进行有效的分析和管理。
### 4.1.2 利用文本工具进行异常监测
在APPN104平台上,进行异常监测是一个常见的任务。这需要管理员能够实时监控日志文件,以便快速响应网络异常。
使用`grep`命令可以迅速查找特定关键词或模式的日志条目。例如,要查找所有包含"ERROR"级别的日志,可以执行以下命令:
```bash
grep "ERROR" /var/log/appn104.log
```
该命令会遍历`/var/log/appn104.log`文件,并输出所有包含"ERROR"的行。
此外,可以编写脚本定期执行日志分析任务,将结果发送到管理员邮箱,从而实现自动化的异常监测。
```bash
#!/bin/bash
ERROR_LOG=$(grep "ERROR" /var/log/appn104.log)
if [ ! -z "$ERROR_LOG" ]; then
echo "$ERROR_LOG" | mail -s "Error Log Report" admin@example.com
fi
```
上述脚本首先使用`grep`命令提取错误日志,然后通过管道传输给`mail`命令,将错误信息发送给管理员。
为了使监测更加高效,可以通过设置定时任务(如cron job),定期运行脚本进行日志分析。
## 4.2 APPN104配置文件管理
### 4.2.1 配置文件的文本特性分析
APPN104的配置文件通常以文本格式存储,这使得文本处理工具在配置文件的管理上有着天然的优势。文本特性意味着我们可以使用文本编辑器进行手动编辑,或者利用脚本来自动化配置文件的更改。
一个典型的配置文件可能包含接口配置、路由信息、安全设置等。每一项配置通常以特定的关键词开始,并跟随其参数或值。
例如,下面是一个简单的接口配置段落:
```
interface GigabitEthernet0/0
ip address 192.168.1.1 255.255.255.0
no shutdown
```
分析该文本特性可以帮助我们快速定位需要修改的配置行,并使用如`sed`或`awk`这样的工具来自动化编辑过程。
### 4.2.2 使用文本工具进行快速修改
在维护大量的APPN104设备时,批量修改配置文件是常见需求。使用`sed`命令,我们可以对配置文件进行非交互式的快速修改。
例如,若需要为所有接口更改IP地址,可以使用以下`sed`命令:
```bash
sed -i 's/192.168.1.1/192.168.2.1/g' /etc/appn104.conf
```
该命令会将配置文件中所有出现的`192.168.1.1`替换为`192.168.2.1`。
还可以通过脚本结合循环语句,对多个设备或多个文件进行批量操作,从而实现配置的快速部署。
```bash
for file in /etc/appn104*.conf; do
sed -i 's/192.168.1.1/192.168.2.1/g' "$file"
done
```
执行上述脚本后,所有匹配的配置文件中指定的IP地址都会被更改。
## 4.3 APPN104数据处理和报告
### 4.3.1 提取关键性能指标(KPI)
APPN104平台的性能监控和报告是维护网络健康的关键。通常需要从日志和运行数据中提取关键性能指标(KPIs)。通过识别并持续监控这些KPIs,管理员可以确保网络性能符合标准。
例如,网络的延迟、丢包率、接口流量等是常见的KPIs。要提取这些数据,我们可以使用`awk`命令:
```bash
awk '/interface GigabitEthernet/ {print $2 " " $3}' /var/log/appn104.log
```
上述`awk`命令会提取日志文件中接口相关的延迟和吞吐量信息。
### 4.3.2 生成周期性报告的自动化脚本
为了定期监控网络性能,可以编写一个自动化脚本,以生成周期性的性能报告。这些报告通常包括了过去一段时间内的网络活动摘要和KPIs的趋势分析。
以下是一个简单的Shell脚本示例,使用`awk`和`mail`命令将报告发送给网络管理员:
```bash
#!/bin/bash
# Generate report
report=$(awk '{print $1, $2}' /var/log/appn104-performance.log)
# Send report via email
echo "APPN104 Performance Report" | mail -s "Weekly Performance Report" admin@example.com
echo "$report" | mail -s "Weekly Performance Report" admin@example.com
```
上述脚本将从性能日志文件中提取必要的数据,并通过电子邮件发送给网络管理员。
通过在定时任务中执行该脚本,管理员可以按周、按日或按其他预定周期接收性能报告,确保网络性能持续符合预定要求。
# 5. 进阶应用与优化策略
随着IT行业的发展,文本处理的需求越来越复杂,从业者必须不断掌握新的工具和策略以提高效率。本章将讨论在面对复杂文本处理任务时的策略,如何优化脚本性能,并探讨未来文本处理技术的发展趋势。
## 5.1 复杂文本处理场景分析
处理大规模文本数据时,单个工具可能无法满足需求,这就需要我们灵活使用多种工具协作处理。
### 5.1.1 处理大规模文本数据的策略
大规模文本数据处理的第一步是优化数据结构,比如可以将数据分割成更小的部分,以便并行处理。在Linux环境下,我们可以利用 `split` 命令来拆分大文件:
```bash
split -l 10000 large_file.txt split_
```
此命令将大文件 `large_file.txt` 按照每10000行分割成多个小文件,如 `split_00`、`split_01` 等。
接下来,可以使用 `xargs` 命令和管道操作来并行处理这些小文件:
```bash
cat split_*.txt | xargs -n1 -P4 ./process_file.sh
```
这里,`xargs` 读取输入流中的文件名,并使用 `-P4` 参数创建4个进程并行运行 `process_file.sh` 脚本。
### 5.1.2 利用多工具协作解决实际问题
在处理复杂的文本数据时,单一工具往往无法涵盖所有的处理需求。以日志分析为例,我们可能需要从日志中提取信息、排序、统计数量并生成报告。
一个实际操作流程可能如下:
```bash
cat log_file.txt | grep 'ERROR' | awk '{print $4}' | sort | uniq -c | sort -nr > report.txt
```
这个命令链先用 `grep` 提取包含 `ERROR` 的行,然后用 `awk` 提取每行的第四个字段(假设这是错误代码),接着用 `sort` 和 `uniq -c` 对错误代码进行统计,最后通过 `sort -nr` 对结果进行降序排序,并输出到 `report.txt` 文件。
## 5.2 文本处理的性能优化
在进行文本处理时,性能优化是一个重要的环节。对于长时间运行的脚本来说,哪怕是一点点性能提升也可能意味着显著的时间节约。
### 5.2.1 优化脚本提高处理速度
优化脚本的一个常见方法是减少磁盘I/O操作。例如,在处理大量数据时,可以避免不必要的输出重定向:
```bash
awk '{process($0)}' file.txt > /dev/null
```
在这个例子中,`awk` 处理的数据直接被丢弃,避免了磁盘写操作,这可以显著加快处理速度。
另外,对于包含大量条件判断的脚本,合理使用 `case` 语句代替多个 `if` 条件判断,可以提升脚本的执行效率。
### 5.2.2 资源和效率的平衡考量
在追求脚本性能优化的同时,也需要考虑到资源的消耗。有时,简单的脚本可能消耗更多内存,但执行速度更快。这时需要根据实际情况做出权衡。
比如,使用 `sort` 命令排序时,默认情况下,`sort` 使用快速排序算法,可以在最坏情况下达到 `O(n log n)` 的时间复杂度。但当数据量不是很大时,使用 `sort -o` 直接输出排序结果,虽然会多一次磁盘I/O操作,却可以减少内存使用。
## 5.3 文本处理的未来发展趋势
文本处理技术在不断发展,特别是结合了人工智能技术后,展现了新的可能性。
### 5.3.1 人工智能在文本分析中的应用
当前,人工智能技术越来越多地应用于文本处理领域。例如,自然语言处理(NLP)技术能够从文本中提取出有用的信息,并进行复杂的分析任务。使用机器学习库如TensorFlow或PyTorch训练的模型,能够识别文本中的模式和情感,用于情感分析、语言翻译、自动摘要等。
### 5.3.2 开源工具的贡献和未来展望
开源社区为文本处理提供了丰富的工具和库,极大地促进了该领域的发展。开源文本处理工具如Apache Lucene、Elasticsearch等提供了强大的文本索引和搜索能力,被广泛应用于搜索引擎和大数据分析领域。未来,随着机器学习技术与文本处理工具的进一步结合,以及对多语言和多模态数据处理能力的增强,开源社区将继续推动文本处理技术的进步。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【事务与锁机制深度分析】:确保INSERT INTO SELECT的数据一致性
# 摘要
本文全面探讨了事务与锁机制在现代数据库管理系统中的核心作用,重点分析了事务的ACID特性以及锁机制的分类和应用。通过对事务基本概念的阐述,以及对原子性、一致性、隔离性、持久性的深入解析,揭示了事务如何保证数据的正确性和稳定性。同时,文章详细介绍了锁的多种类型和它们在确保数据一致性中的作用,包括共享锁、排他锁、意向锁,以及死锁的避免与解决策略。本文还针对INSERT I
PDL语言错误处理全解析:构建健壮程序的秘诀

M.2技术问答集:权威解答引脚定义与规范疑惑

# 摘要
M.2技术作为现代计算机硬件领域的一项重要技术,以其小尺寸和高速性能特点,广泛应用于消费电子、服务器和存储解决方案中。本文对M.2技术进行了全面概述,详细介绍了其接口标准、物理规格、工作原理及性能,同时也分析了M.2技术的兼容性问题和应用场景。通过对M.2设备的常见故障诊断与维护方法的研究,本文旨
【系统性能提升】HP iLO4安装后的调整技巧

# 摘要
本文全面介绍了HP iLO4的安装、配置、监控、优化以及高级管理技巧。首先概述了iLO4的基本特性和安装流程,随后详细讲解了网络设置、用户账户管理、安全性强化等关键配置基础。接着,本文深入探讨了性能监控工具的使用、电源和冷却管理、虚拟媒体与远程控制的最佳实践。在硬件优化方面,重点介绍了固件更新、硬件配置调整的相关知识。此外,本文还分享了高级管理技巧,包括集群和高可用性设置、集成自动化工具以及与其他平台的协同工作
UniAccess日志管理:从分析到故障排查的高效技巧
# 摘要
UniAccess日志管理作为现代信息系统中不可或缺的一部分,是确保系统稳定运行和安全监控的关键。本文系统地介绍了UniAccess日志管理的各个方面,包括日志的作用、分析基础、故障诊断技术、实践案例、自动化及高级应用,以及对未来发展的展望。文章强调了日志分析工具和技术在问题诊断、性能优化和安全事件响应中的实际应用,同时也展望了利用机器学习、大数据技术进行自动化
【奥维地图高清图源集成指南】:融合新数据源,提升效率的关键步骤
# 摘要
随着地理信息系统(GIS)技术的发展,高清地图图源的集成对提升地图服务质量和用户体验变得至关重要。本文系统地探讨了奥维地图与高清图源集成的理论基础、实践指南和问题解决策略,详细分析了地图服务的工作原理、图源的重要性、集成的技术要求以及环境搭建和工具准备的必要步骤。同时,本文提供了图源添加与配置、动态图源集成等高级技巧,并针对集成问题提出了排
从零开始精通LWIP:TCP_IP协议栈在嵌入式系统中的完美应用

# 摘要
TCP/IP协议栈是互联网通信的基础,而LWIP作为专为嵌入式系统设计的轻量级TCP/IP协议栈,已成为物联网和工业控制网络中不可或缺的组件。本文首先介绍了TCP/IP协议栈的基本架构和关键协议功能,随后深入解析了LWIP的设计哲学、核心功能实现以及其扩展与定制能力。特别强调了LWIP在嵌入式系统中的实践应用,包括如何集成、编程
alc4050.pdf案例深度分析:系统思维在技术问题解决中的应用
# 摘要
系统思维是一种全面考虑问题和解决问题的方法论,尤其在技术问题解决中扮演着关键角色。本文从系统思维的理论基础出发,探讨了其定义、重要性以及核心原则,包括整体性原则、相互依存性原则和反馈循环原理,并分析了其在识别问题根本原因和构建问题解决模型中的应用。通过alc4050.pdf案例的深入分析,本文展示了系统思维在实际问题诊断、解决方案设计及实施中的有效性。此外,本文还讨论了系统思维工具
【RFID技术与ISO18000-6C协议】:无线通信无缝对接的终极指南

# 摘要
本文首先概述了射频识别(RFID)技术的基础知识及其在各行业的广泛应用。详细解析了ISO18000-6C协议的基础架构、技术参数、数据通信机制,以及安全性与隐私保护措施。接着,文章讨论了RFID系统在实际场景中的部署与集成,包括硬件组件、系统安装调试以及特定行业应用场景。深入探讨了RFID技术在零售业、医疗卫生以及制造业智能制造中的具体
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )