利用Python中的Matplotlib制作长方形区域图
发布时间: 2024-03-28 07:54:54 阅读量: 44 订阅数: 27 
# 1. **介绍**
在本章中,我们将首先介绍Matplotlib库及长方形区域图的概念,为后续的学习和实践做好准备。
# 2. **准备工作**
在开始制作长方形区域图之前,我们需要进行一些准备工作,包括安装Matplotlib库和导入所需的库。接下来让我们一步步完成这些准备工作。
# 3. 创建长方形区域图的基本设置
在本节中我们将进行长方形区域图的基本设置,包括设置图表样式和创建数据。
- **设置图表样式:**
在绘制长方形区域图之前,我们需要设置图表的样式,包括背景颜色、坐标轴样式等。这可以通过Matplotlib中的相关函数和方法来实现。
- **创建数据:**
在绘制长方形区域图时,我们需要准备相应的数据。在这里,我们可以创建一些示例数据,以便后续绘制长方形区域图时使用。
# 4. **绘制长方形区域图**
在这一部分,我们将使用Matplotlib库来绘制长方形区域图。通过以下步骤,您将学会如何创建长方形并添加标签和标题。
#### 4.1 通过Matplotlib绘制长方形
下面是绘制长方形区域图的基本代码示例:
```python
import matplotlib.pyplot as plt
# 创建数据
categories = ['A', 'B', 'C', 'D']
values = [20, 35, 30, 25]
colors = ['red', 'blue', 'green', 'purple']
# 绘制长方形
plt.bar(categories, values, color=colors)
# 显示图表
plt.show()
```
通过以上代码,您可以创建一个简单的长方形区域图,并显示出来。
#### 4.2 添加标签和标题
您可以通过以下代码向图表添加标签和标题:
```python
import matplotlib.pyplot as plt
#
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏涵盖了关于长方形绘制的各种技术与方法,包括使用HTML、CSS、JavaScript、Python等多种工具实现长方形的各种效果与处理方式。从简单的红色填充到复杂的3D渲染,从SVG到Canvas,从CSS动画到WebGL,从数据绑定到交互操作,本专栏将为读者呈现长方形绘制的全貌。不仅有基础技术介绍,还有高级技巧分享,旨在帮助读者掌握各种工具下长方形绘制的精华,拓展视野,提升技术。适合对前端开发、数据可视化、图形学有兴趣的读者阅读学习,为他们打造一个深入学习与交流的平台。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【用例优化秘籍】:提高硬件测试效率与准确性的策略

# 摘要
随着现代硬件技术的快速发展,硬件测试的效率和准确性变得越来越重要。本文详细探讨了硬件测试的基础知识、测试用例设计与管理的最佳实践,以及提升测试效率和用例准确性的策略。文章涵盖了测试用例的理论基础、管理实践、自动化和性能监控等关键领域,同时提出了硬件故障模拟和分析方法。为了进一步提高测试用例的精准度,文章还讨论了影响测试用例精准度的因素以及精确性测试工具的应用。
【ROSTCM自然语言处理基础】:从文本清洗到情感分析,彻底掌握NLP全过程
# 摘要
本文全面探讨了自然语言处理(NLP)的各个方面,涵盖了从文本预处理到高级特征提取、情感分析和前沿技术的讨论。文章首先介绍了NLP的基本概念,并深入研究了文本预处理与清洗的过程,包括理论基础、实践技术及其优
【面积分与线积分】:选择最佳计算方法,揭秘适用场景
# 摘要
本文详细介绍了面积分与线积分的理论基础及其计算方法,并探讨了这些积分技巧在不同学科中的应用。通过比较矩形法、梯形法、辛普森法和高斯积分法等多种计算面积分的方法,深入分析了各方法的适用条件、原理和误差控制。同时,对于线积分,本文阐述了参数化方法、矢量积分法以及格林公式与斯托克斯定理的应用。实践应用案例分析章节展示了这些积分技术在物理学、工程计算
MIKE_flood性能调优专家指南:关键参数设置详解

# 摘要
本文对MIKE_flood模型的性能调优进行了全面介绍,从基础性能概述到深入参数解析,再到实际案例实践,以及高级优化技术和工具应用。本文详细阐述了关键参数,包括网格设置、时间步长和
【Ubuntu系统监控与日志管理】:维护系统稳定的关键步骤
# 摘要
随着信息技术的迅速发展,监控系统和日志管理在确保Linux系统尤其是Ubuntu平台的稳定性和安全性方面扮演着至关重要的角色。本文从基础监控概念出发,系统地介绍了Ubuntu系统监控工具的选择与使用、监控数据的分析、告警设置以及日志的生成、管理和安全策略。通过对系统日志的深入分析
【蓝凌KMSV15.0:性能调优实战技巧】:提升系统运行效率的秘密武器
# 摘要
本文详细介绍了蓝凌KMSV15.0系统,并对其性能进行了全面评估与监控。文章首先概述了系统的基本架构和功能,随后深入分析了性能评估的重要性和常用性能指标。接着,文中探讨了如何使用监控工具和日志分析来收集和分析性能数据,提出了瓶颈诊断的理论基础和实际操作技巧,并通过案例分析展示了在真实环境中如何处理性能瓶颈问题。此外,本文还提供了系统配置优化、数据库性能
Dev-C++ 5.11Bug猎手:代码调试与问题定位速成

# 摘要
本文旨在全面介绍Dev-C++ 5.11这一集成开发环境(IDE),重点讲解其安装配置、调试工具的使用基础、高级应用以及代码调试实践。通过逐步阐述调试窗口的设置、断点、控制按钮以及观察窗口、堆栈、线程和内存窗口的使用,文章为开发者提供了一套完整的调试工具应用指南。同时,文章也探讨了常见编译错误的解读和修复,性能瓶颈的定
Mamba SSM版本对比深度分析:1.1.3 vs 1.2.0的全方位差异
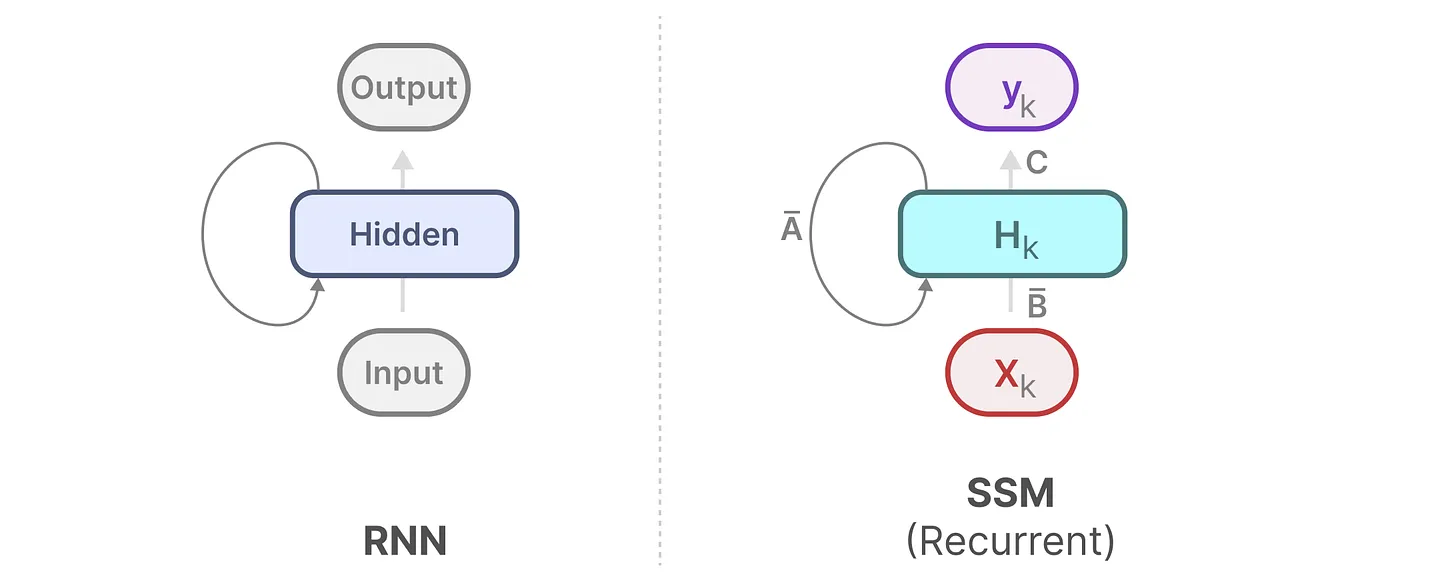
# 摘要
本文全面介绍了Mamba SSM的发展历程,特别着重于最新版本的核心功能演进、架构改进、代码质量提升以及社区和用户反馈。通过对不同版本功能模块更新的对比、性能优化的分析以及安全性的对比评估,本文详细阐述了Mamba SSM在保障软件性能与安全方面的持续进步。同时,探讨了架构设计理念的演变、核心组件的重构以及部署与兼容性的调整对整体系统稳定性的影响。本文还讨
【Java内存管理:堆栈与GC攻略】
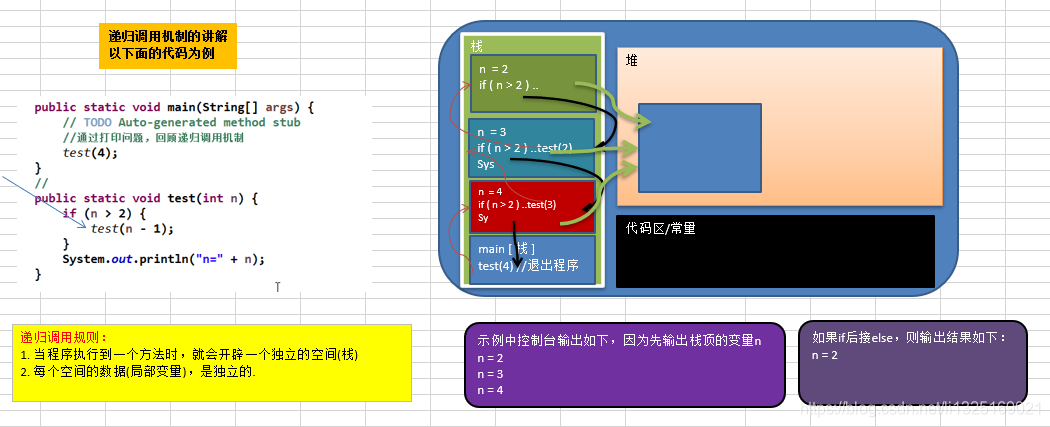
# 摘要
Java内存模型、堆内存和栈内存管理、垃圾收集机制、以及内存泄漏和性能监控是Java性能优化的关键领域。本文首先概述Java内存模型,然后深入探讨了堆内
BP1048B2应用案例分析:行业专家分享的3个解决方案与最佳实践
# 摘要
本文详细探讨了BP1048B2在多个行业中的应用案例及其解决方案。首先对BP1048B2的产品特性和应用场景进行了概述,紧接着提出行业解决方案的理论基础,包括需求分析和设计原则。文章重点分析了三个具体解决方案的理论依据、实践步骤和成功案例,展示了从理论到实践的过程。最后,文章总结了BP1048B2的最佳实践价值,预测了行业发展趋势,并给出了专家的建议和启示。通过案例分析和理论探讨,本文旨在为从业人
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )