Redis管道技术优化与实践
发布时间: 2023-12-31 16:34:41 阅读量: 42 订阅数: 44 

Redis的改造与实践
# 第一章:Redis管道技术概述
## 1.1 管道技术的基本概念
管道技术是一种用于批量处理请求的机制,通过将多个请求合并成一个批量请求发送到服务器端,可以显著减少网络通信开销,提高系统性能和吞吐量。
## 1.2 Redis管道技术原理解析
Redis管道技术利用了批量请求的优势,通过将多个命令打包成一个请求一次性发送到服务器,然后服务器执行这些命令,并将结果一次性返回给客户端,从而减少了网络通信的开销。
## 1.3 管道技术与传统请求响应方式的对比
传统的请求响应方式下,客户端发送一个请求到服务器端,然后服务器端执行该请求并返回结果给客户端,而管道技术则可以将多个请求打包发送,减少了网络往返时间,极大地提高了请求的处理效率。
## 第二章:Redis管道技术的性能优化
在使用Redis时,为了提升读写性能,可以使用管道技术,通过减少网络通信的次数来加快数据的读写速度。本章将介绍管道技术对性能的影响分析,并探讨如何利用管道技术提升Redis的读写性能。
### 2.1 管道技术对性能的影响分析
管道技术通过批量发送多个命令到Redis服务器,减少了每个命令的网络往返时间,从而提高了性能。管道技术的性能优势主要体现在以下几个方面:
- 减少网络延迟:传统的Redis操作方式是一次操作对应一次网络往返,而管道技术可以将多个操作打包发送,减少了网络通信的次数,从而减少了网络延迟。
- 提高吞吐量:由于管道技术可以发送多个命令到Redis服务器,服务器可以并行执行这些命令,从而提高了吞吐量。
- 减少CPU消耗:管道技术可以减少网络通信的次数,从而减少了CPU的消耗,提高了Redis服务器的处理能力。
但是需要注意的是,管道技术的性能优化并不是无限制的,过多的命令批量发送可能会造成网络拥堵或增加服务器的负载,所以在实际应用中需要根据具体情况进行调优。
### 2.2 如何利用管道技术提升Redis读写性能
通过使用管道技术,可以有效地提升Redis的读写性能。下面以Python语言为例,演示如何使用管道技术进行数据写入和读取操作。
#### 2.2.1 管道技术的写入操作
在进行大量写入操作时,可以使用管道技术批量发送写入命令到Redis服务器,示例代码如下:
```python
import redis
r = redis.Redis(host='localhost', port=6379)
pipe = r.pipeline()
# 执行批量写入
for i in range(10000):
pipe.set(f'key{i}', f'value{i}')
pipe.execute()
```
上述代码中,首先创建一个Redis连接,然后创建一个管道对象,并使用`set`命令将多个键值对写入到Redis服务器,最后通过执行`pipeline.execute()`方法发送命令并执行。
#### 2.2.2 管道技术的读取操作
在进行大量读取操作时,也可以使用管道技术批量发送读取命令到Redis服务器,并一次性获取所有结果,示例代码如下:
```python
import redis
r = redis.Redis(host='localhost', port=6379)
pipe = r.pipeline()
# 执行批量读取
for i in range(10000):
pipe.get(f'key{i}')
results = pipe.execute()
# 解析读取结果
for i, result in enumerate(results):
print(f'key{i}: {result}')
```
上述代码中,首先创建一个Redis连接,然后创建一个管道对象,并使用`get`命令批量读取多个键的值,最后通过执行`pipeline.execute()`方法发送命令并获取结果。然后可以解析结果并进行相应的处理。
### 2.3 优化管道操作的注意事项
在使用管道技术进行性能优化时,需要注意以下几点:
- 合理地划分管道批次:将多个命令划分为合适的批次,避免一次性发送过多的命令导致网络拥堵或服务器负载过高。
- 关注命令的执行时间:通过监控命令的执行时间,可以了解到管道操作的性能情况,及时进行调优。
- 注意管道命令的顺序:由于管道操作是批量发送的,所以命令的顺序可能会对结果产生影响,需要根据实际需求进行合理的排列。
通过合理地使用管道技术,并结合实际业务需求进行调优,可以有效地提升Redis的读写性能。
在本章节中,我们介绍了管道技术对性能的影响分析,并演示了如何利用管道技术提升Redis的读写性能。同时,我们也强调了使用管道技术时需要注意的优化策略。在下一章节中,将重点介绍Redis管道技术的应用场景。
3. Redis管道技术的应用场景
### 3.1 在高并发场景下的管道技术应用
在高并发场景下,Redis管道技术能够显著提升系统性能和响应速度。以下是一些常见的高并发场景下的管道技术应用示例:
#### 场景一:批量数据写入
假设有一个电商平台,每秒需要将上万条订单数据写入到Redis中,使用传统的请求响应方式会导致频繁的网络通信和IO开销。而通过管道技术,可以将一批订单数据一次性发送给Redis服务器,减少了网络往返的次数,从而提高了写入速度。
```python
import redis
# 创建Redis连接
r = redis.Redis(host='localhost', port=6379)
# 模拟生成一批订单数据
orders = [{'order_id': '10001', 'product_id': '1001', 'quantity': 2},
{'order_id': '10002', 'product_id': '1002', 'quantity': 1},
{'order_id': '10003', 'product_id': '1003', 'quantity': 5}]
# 使用管道技术批量写入订单数据
pipeline = r.pipeline()
for order in orders:
pipeline.hmset(f"order:{order['order_id']}", order)
pipeline.execute()
```
上述代码中,我们使用了Python的`redis`库来创建Redis连接。首先,我们生成了一批订单数据,然后使用管道技术将订单数据批量写入Redis中。通过使用管道技术,我们可以将多条写入命令打包发送给Redis服务器,从而减少了网络通信的次数。
#### 场景二:并发读取数据
在一个用户量庞大的社交网络应用中,用户的关注列表存储在Redis中。当用户同时访问自己的关注列表时,使用传统的请求响应方式会导致大量的网络通信和响应延迟。而通过管道技术,可以同时发送多个读取命令给Redis服务器,加快数据读取速度。
```java
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Pipeline;
import redis.clients.jedis.Response;
// 创建Redis连接
Jedis jedis = new Jedis("localhost", 6379);
// 模拟多个用户并发读取关注列表
String[] users = {"user1", "user2", "user3"};
Pipeline pipeline = jedis.pipelined();
List<Response<List<String>>> responses = new ArrayList<>();
for (String user : users) {
Response<List<String>> response = pipeline.lrange("following:" + user, 0, 10);
responses.add(response);
}
pipeline.sync();
// 处理多个用户的关注列表数据
for (int i = 0; i < users.length; i++) {
String user = users[i];
List<String> followingList = responses.get(i).get();
System.out.println(user + "的关注列表:" + followingList);
}
```
上述代码中,我们使用了Java的Jedis库来创建和操作Redis连接。首先,我们模拟了多个用户并发读取关注列表的场景,使用管道技术将多个关注列表读取命令一次性发送给Redis服务器。然后,通过`pipeline.sync()`方法等待所有命令的执行结果,最后分别处理每个用户的关注列表数据。
通过使用管道技术,我们可以一次性发送多个读取命令给Redis服务器,减少了网络开销和响应延迟,提高了系统的并发读取能力。
### 3.2 管道技术在数据分析和实时计算中的应用
管道技术在数据分析和实时计算领域也有广泛的应用。这些场景通常需要对大量的数据进行计算和处理,而管道技术能够通过一次性发送多个计算命令,提高数据分析和实时计算的效率。
#### 场景一:数据聚合计算
假设我们有一个日志数据集,需要对某个时间段内的数据进行聚合计算,比如统计每小时的访问量。使用传统的请求响应方式会导致大量的网络通信和计算开销。而通过管道技术,可以一次性发送多个计算命令给Redis服务器,快速完成数据聚合计算。
```javascript
const redis = require("redis");
// 创建Redis连接
const client = redis.createClient();
// 模拟日志数据
const logs = [
{ timestamp: 1621458723, user: "user1", action: "login" },
{ timestamp: 1621458921, user: "user2", action: "logout" },
{ timestamp: 1621459127, user: "user3", action: "login" },
// ...
];
// 使用管道技术进行数据聚合计算
const pipeline = client.pipeline();
logs.forEach((log) => {
const hour = new Date(log.timestamp * 1000).getHours();
pipeline.zincrby("hourly_visits", 1, hour);
});
pipeline.exec((err, results) => {
if (err) {
console.error("数据聚合计算出错: ", err);
return;
}
console.log("每小时访问量统计结果: ", results);
});
```
上述代码中,我们使用Node.js的`redis`库来连接和操作Redis。首先,我们模拟生成了一批日志数据,然后使用管道技术将每条日志数据的小时部分作为键,对应的访问量作为值,使用`zincrby`命令进行累加计算。最后,通过`pipeline.exec()`方法执行管道命令并获取计算结果。
通过使用管道技术,我们可以将多个计算命令一次性发送给Redis服务器,减少了网络通信的次数和计算开销,加快了数据聚合计算的速度。
### 3.3 针对特定业务场景的管道技术实践案例
针对不同的业务场景,我们可以根据需求结合管道技术来实现更高效的数据操作和处理。以下是一些常见的针对特定业务场景的管道技术实践案例:
#### 案例一:秒杀活动
在一个秒杀活动中,每秒有大量用户同时提交订单请求。使用传统的请求响应方式会导致服务器压力过大,无法满足高并发访问需求。而通过管道技术,可以将多个订单写入命令一次性发送给Redis服务器,提高订单处理速度。
```go
package main
import (
"fmt"
"github.com/gomodule/redigo/redis"
)
func main() {
// 创建Redis连接
conn, err := redis.Dial("tcp", "localhost:6379")
if err != nil {
fmt.Println("Redis连接失败: ", err)
return
}
defer conn.Close()
// 模拟秒杀活动
orders := []string{"order1", "order2", "order3"}
// 使用管道技术批量处理订单
pipeline := redis.NewPipeline(conn)
for _, order := range orders {
pipeline.Do("SADD", "seckill_orders", order)
}
_, err = pipeline.Exec()
if err != nil {
fmt.Println("订单处理失败: ", err)
return
}
fmt.Println("订单处理成功")
}
```
上述代码中,我们使用Go语言的`gomodule/redigo`库来连接和操作Redis。首先,我们模拟了一个秒杀活动,生成了多个订单数据。然后,使用管道技术将每个订单的写入命令一次性发送给Redis服务器,使用`SADD`命令将订单添加到秒杀订单集合中。最后,通过`pipeline.Exec()`方法执行管道命令并获取执行结果。
通过使用管道技术,我们可以将多个写入命令一次性发送给Redis服务器,减少了网络通信的次数和服务器压力,提高了秒杀活动的订单处理速度。
### 总结
Redis管道技术在高并发场景、数据分析和实时计算以及特定业务场景中都有广泛的应用。通过合理地利用管道技术,我们可以提升系统的性能和响应速度,降低服务器压力,提高用户体验。在实际应用中,需要根据具体的业务需求和场景选择合适的管道技术实现方式,并进行性能监控和调优,以确保系统的高效运行。
### 第四章:Redis管道技术在分布式系统中的实践
在分布式系统中,Redis管道技术扮演着重要的角色。本章将深入探讨Redis管道技术在分布式系统中的实践,包括其在分布式事务中的应用、多节点协作下的实践,以及管道技术对分布式系统性能的影响。
#### 4.1 管道技术在分布式事务中的应用
在分布式系统中,事务处理是至关重要的。传统的Redis事务操作可能存在性能瓶颈,而管道技术能够在一定程度上解决这一问题。下面我们将以Python语言为例,演示管道技术在分布式事务中的应用。
```python
import redis
# 创建Redis连接
r = redis.Redis(host='localhost', port=6379, db=0)
# 创建管道
pipe = r.pipeline()
# 添加事务操作到管道
pipe.multi()
pipe.set('key1', 'value1')
pipe.set('key2', 'value2')
pipe.execute()
# 执行管道
pipe.execute()
```
上述代码中,我们通过Python的redis模块创建了一个Redis连接,并通过`pipeline()`方法创建了一个管道对象`pipe`。然后我们使用`multi()`开启一个事务,并通过`set()`方法向管道中添加操作,最后调用`execute()`方法执行事务。
#### 4.2 多节点协作下的管道技术实践
在多节点的分布式系统中,管道技术也能发挥重要作用。例如,在使用多个Redis节点进行数据处理时,我们可以针对不同的节点创建不同的管道,并通过管道技术实现多节点协作的高效数据处理。以下是一个简单的Node.js示例:
```javascript
const redis = require("redis");
// 连接多个Redis节点
const client1 = redis.createClient({host: 'host1', port: 6379});
const client2 = redis.createClient({host: 'host2', port: 6379});
// 创建管道
const pipeline1 = client1.batch();
const pipeline2 = client2.batch();
// 向管道中添加操作
pipeline1.set('key1', 'value1');
pipeline2.get('key1');
// 执行管道
pipeline1.exec((err, replies) => {
console.log("Pipeline 1 replies: " + replies);
});
pipeline2.exec((err, replies) => {
console.log("Pipeline 2 replies: " + replies);
});
```
上述Node.js代码中,我们使用`redis`模块创建了两个不同的Redis连接`client1`和`client2`,并分别针对不同的节点创建了两个管道`pipeline1`和`pipeline2`,然后向各自的管道中添加操作并执行。
#### 4.3 管道技术对分布式系统性能的影响
管道技术的引入可以显著提升分布式系统的性能。通过批量操作和异步执行,管道技术可以减少网络延迟和提升吞吐量,从而优化分布式系统的性能表现。
在实际生产环境中,合理利用管道技术可以有效地提升分布式系统的数据处理能力,减少系统的响应时间,提高用户体验。
在下一章节中,我们将进一步探讨Redis管道技术的监控与调优,以及相应的实时案例分析。
希望以上内容能够为您解决问题,如果有其他疑问,欢迎继续交流。
### 第五章:Redis管道技术的监控与调优
在实际应用中,对于Redis管道技术的监控与调优显得尤为重要。本章将介绍管道技术下的性能监控指标与工具、管道技术的调优策略以及监控与调优下的实时案例分析。
#### 5.1 管道技术下的性能监控指标与工具
在使用Redis管道技术时,需要关注以下性能监控指标:
- **管道执行数量:** 监控管道中批量操作的数量,可以通过Redis的monitor命令或者使用监控工具实时查看。
- **管道操作耗时:** 统计管道操作的耗时情况,可以通过Redis的slowlog功能记录慢查询,并结合监控工具进行分析。
- **网络IO情况:** 监控管道操作对网络IO的影响,包括网络流量、带宽利用率等指标。
- **命令成功率:** 统计管道中命令的成功率,及时发现管道操作异常情况。
常用的Redis性能监控工具包括:
- **Redis监控工具:** Redis官方提供的Redis-cli工具可以通过info命令查看Redis服务器的各项统计信息,结合命令用法和脚本编写可以实现定制化的监控需求。
- **第三方监控平台:** 例如Prometheus、Grafana等开源监控工具,可以通过插件或自定义metrics收集Redis性能指标,并展示在统一的监控平台上进行可视化监控。
#### 5.2 管道技术的调优策略
针对Redis管道技术的调优,可以从以下几个方面入手进行优化:
- **合理利用管道批量操作:** 通过合理的批量操作数量和大小,避免管道过大导致操作阻塞或消耗过多内存。
- **优化管道数据结构:** 合理选择数据结构和命令操作,减少不必要的操作和数据传输。
- **合理设置管道超时参数:** 针对不同的场景和网络环境,合理设置管道操作的超时时间,避免因网络等原因导致管道操作长时间阻塞。
#### 5.3 监控与调优下的实时案例分析
以下是一个基于Python的Redis管道技术的监控与调优实时案例分析:
```python
import redis
# 连接Redis
r = redis.StrictRedis(host='localhost', port=6379, db=0)
# 创建管道
pipe = r.pipeline()
# 批量执行操作
for i in range(1000):
pipe.set("key_"+str(i), "value_"+str(i))
pipe.get("key_"+str(i))
result = pipe.execute()
print("Redis管道批量操作结果:", result)
```
**代码说明:**
- 通过Python的Redis库创建管道,批量进行set和get操作。
- 结合Redis监控工具查看管道操作数量、耗时情况等指标。
- 根据监控结果,对管道的批量操作数量、数据结构进行优化调整。
以上是第五章Redis管道技术的监控与调优的部分内容,希望对您有所帮助。
### 第六章:未来Redis管道技术的发展趋势
随着大数据、云计算等领域的不断发展,Redis作为一种高性能的内存数据库,在未来的发展中也面临着新的挑战和机遇。在管道技术方面,未来的发展趋势可能包括以下几个方面:
#### 6.1 Redis管道技术的现状与挑战
当前,Redis管道技术在提升性能和降低网络开销方面取得了一定的成就,但也面临着一些挑战。比如在多节点协作下的一致性和容错性问题、在分布式事务中的复杂性等方面仍然有待突破。此外,随着数据量的不断增大,如何更好地应对海量数据下的管道操作也是当前面临的挑战之一。
#### 6.2 未来管道技术的发展方向
未来,Redis管道技术可能会朝着更加智能化、自适应化的方向发展。通过引入机器学习和人工智能技术,使得管道技术能够更好地适应不同业务场景下的需求,提供更加精准和高效的管道操作支持。同时,基于硬件的优化、网络传输协议的改进等方面也将是未来管道技术发展的重点方向。
#### 6.3 面向未来的管道技术优化建议
针对未来管道技术的发展,可以提出一些优化建议,比如在算法层面引入智能调度和优化策略,通过负载均衡和数据分片等技术优化多节点协作下的管道操作;在网络层面优化传输协议,减少网络延迟和数据传输开销;在硬件层面结合新型存储介质和硬件加速技术,提升管道操作的整体性能等方面进行优化。
以上是未来Redis管道技术的发展趋势,随着技术的不断演进和创新,相信Redis管道技术在未来会有更加广阔的应用前景和发展空间。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Redis的面试宝典》是一本涵盖了广泛的领域的专栏,通过全面深入的文章内容,深度探究了Redis数据库的各个方面。从Redis的基本介绍、数据结构与存储原理,到主从复制、高可用性方案、持久化机制与数据备份,再到事务与锁的实现原理、分布式锁设计与实现、以及发布订阅模式详解,专栏内容囊括了Redis在实际应用中面对的各种挑战和解决方案。同时,还涉及了Redis哨兵系统的作用与实现原理、集群方案比较与选择、并发控制与线程安全等内容,以及性能调优、客户端连接池设计与使用,以及与Spring集成应用指南等实际操作技术。此外,专栏还关注了Redis在分布式系统中的应用与挑战,以及Lua脚本的应用与案例分析,同时也对Redis与Memcached进行了对比与选择的探讨。该专栏内容全面,深入浅出,适用于对Redis有兴趣的读者,不仅有助于面试准备,还能帮助读者更深入地理解Redis数据库及其在实际项目中的应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【数据一致性守护神】:ClusterEngine浪潮集群数据同步与维护攻略
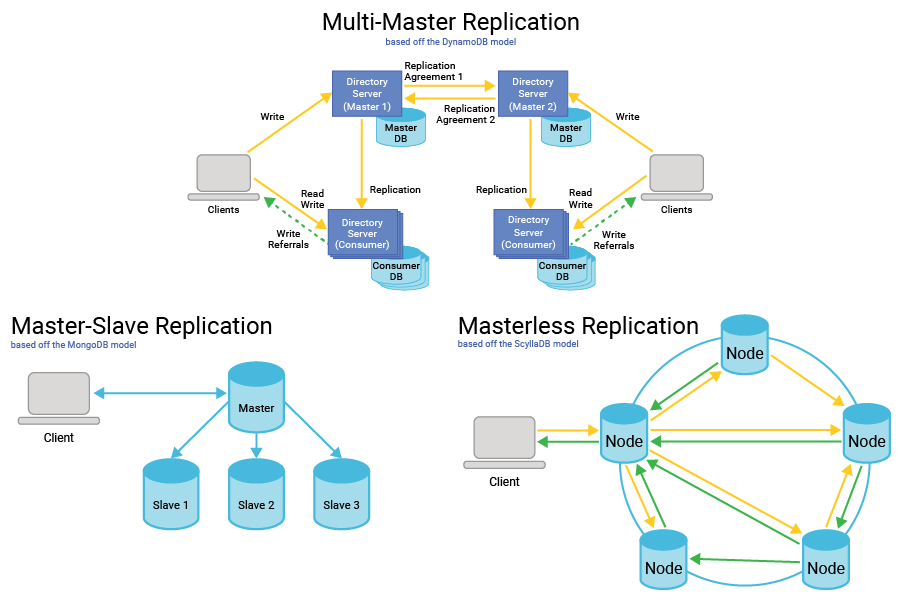
# 摘要
ClusterEngine集群技术在现代分布式系统中发挥着核心作用,本文对ClusterEngine集群进行了全面概述,并详细探讨了数据同步的基础理论与实践方法,包括数据一致性、同步机制以及同步技术的选型和优化策略。此外,文章深入分析了集群的维护与管理,涵盖配置管理、故障排除以及安全性加固。在高级应用方面,探讨了数据备份与恢复、负载均衡、高可用架构
提升用户体验:Vue动态表格数据绑定与渲染技术详解
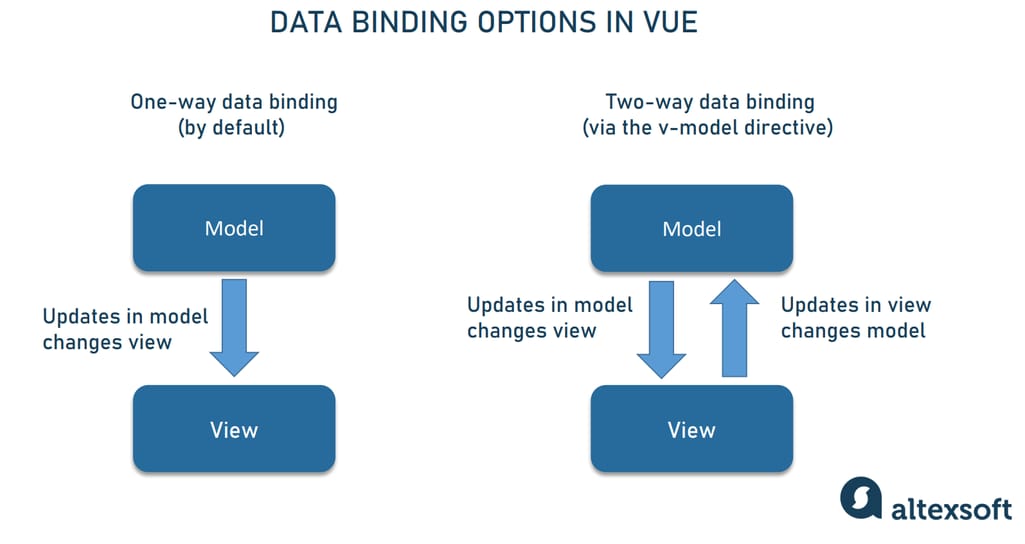
# 摘要
本文系统性地探讨了Vue框架中动态表格的设计、实现原理以及性能优化。首先,介绍Vue动态表格的基础概念和实现机制,包括数据绑定的原理与技巧,响应式原理以及双向数据绑定的实践。其次,深入分析了Vue动态表格的渲染技术,涉及渲染函数、虚拟DOM、列表和条件渲染的高级技巧,以及自定义指令的扩展应用。接着,本文着重探讨了Vue动态表格的性能优化方法和
MySQL性能调优实战:20个技巧助你从索引到查询全面提升性能
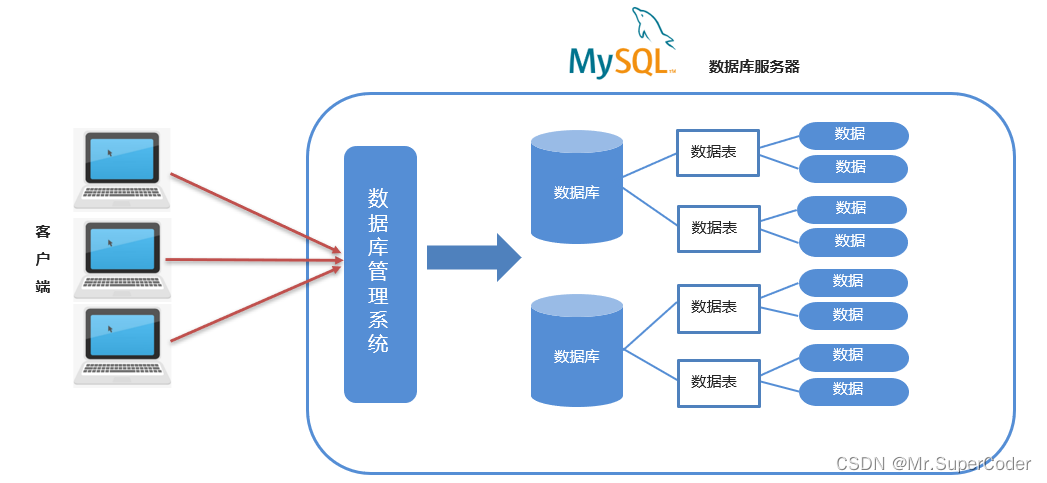
# 摘要
MySQL作为广泛使用的数据库管理系统,其性能调优对保持系统稳定运行至关重要。本文综述了MySQL性能调优的各个方面,从索引优化深入探讨了基础知识点,提供了创建与维护高效索引的策略,并通过案例展示了索引优化的实际效果。查询语句调优技巧章节深入分析了性能问题,并探讨了实践中的优化方法和案例研究。系统配置与硬件优化章节讨论了服务器参数调优与硬件资源的影响,以及高可用架构对性能的提升。综合性能调优实战章节强调了优化前的准备工作、综
【光模块发射电路效率与稳定性双提升】:全面优化策略

# 摘要
本文针对光模块发射电路进行了深入研究,概述了其基本工作原理及效率提升的策略。文章首先探讨了光发射过程的物理机制和影响电路效率的因素,随后提出了一系列提升效率的方法,包括材料选择、电路设计创新和功率管理策略改进。在稳定性提升方面,分析了评价指标、关键影响因素,并探索了硬件和软件层面的技术措施。此外,
IBM Rational DOORS最佳实践秘籍:提升需求管理的10大策略
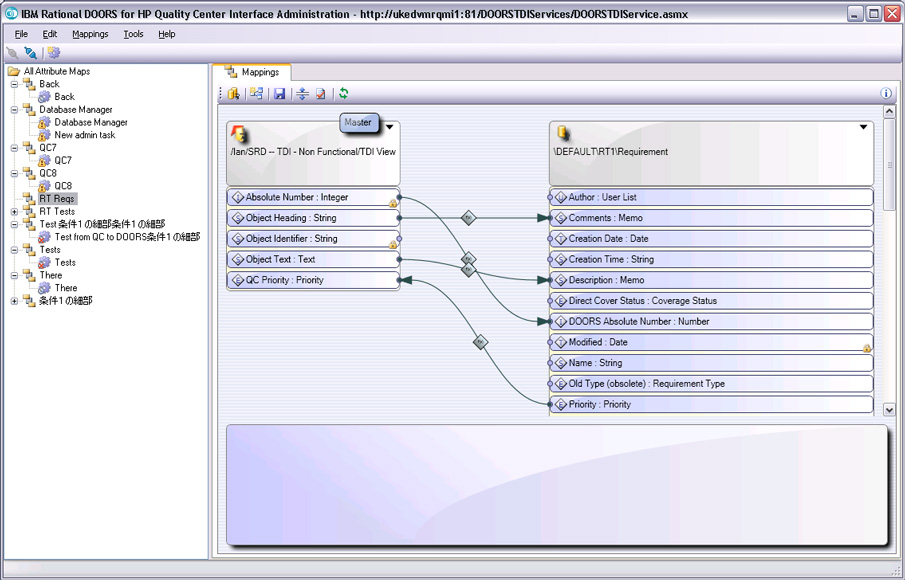
# 摘要
本文旨在全面介绍IBM Rational DOORS软件在需求管理领域中的应用及其核心价值。首先概述了需求管理的理论基础,包括关键概念、管理流程以及质量评估方法。接着,文章深入解析了DOORS工具的基本操作、高级特性和配置管理策略。实战演练章节通过具体的案例和技巧,指导读者如何在敏捷环境中管理和自动化需求过程,以及如何优化组织内部的需求管理。最后,
数据标准化的力量:提升国际贸易效率的关键步骤
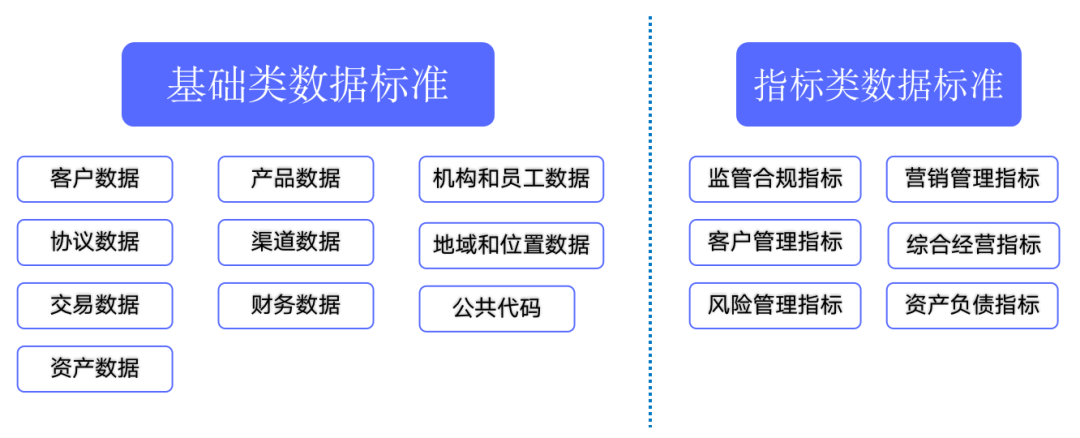
# 摘要
数据标准化是国际贸易领域提高效率和准确性的关键。本文首先介绍了数据标准化的基本概念,并阐述了其在国际贸易中的重要性,包括提升数据交换效率、促进贸易流程自动化以及增强国际市场的互联互通。随后,文章通过案例分析了国际贸易数据标准化的实践,并探讨了数据模型与结构
InnoDB故障恢复高级教程:多表空间恢复与大型数据库案例研究

# 摘要
InnoDB存储引擎在数据库管理中扮演着重要角色,其故障恢复技术对于保证数据完整性与业务连续性至关重要。本文首先概述了InnoDB存储引擎的基本架构及其故障恢复机制,接着深入分析了故障类型与诊断方法,并探讨了单表空间与多表空间的恢复技术。此外,本文还提供了实践案例分析,以及故障预防和性能调优的有效策略。通过对InnoDB故障恢复的全面审视,本文旨在为数据
系统速度提升秘诀:XJC-CF3600-F性能优化实战技巧
# 摘要
本文对XJC-CF3600-F性能优化进行了全面的概述,并详细探讨了硬件升级、系统配置调整、应用软件优化、负载均衡与集群技术以及持续监控与自动化优化等多个方面。通过对硬件性能瓶颈的识别、系统参数的优化调整、应用软件的性能分析与调优、集群技术的运用和性能数据的实时监控,本文旨在为读者提供一套系统性、实用性的性能优化方案。文章还涉及了自动化优化工具的使用和性能优
【SIM卡无法识别系统兼容性】:深度解析与专业解决方案
# 摘要
本文针对SIM卡无法识别的现象进行研究,分析其背景、影响及技术与系统兼容性。文章首先概述SIM卡技术,并强调系统兼容性在SIM卡识别中的作用。之后,通过理论框架对常见问题进行了剖析,进而讨论了故障诊断方法和系统日志的应用。针对兼容性问题,提供了实际的解决方案,包括软件更新、硬件维护及综合策略。最后,展望了SIM卡技术的发展前景,以及标准化和创新技
Kafka监控与告警必备:关键指标监控与故障排查的5大技巧
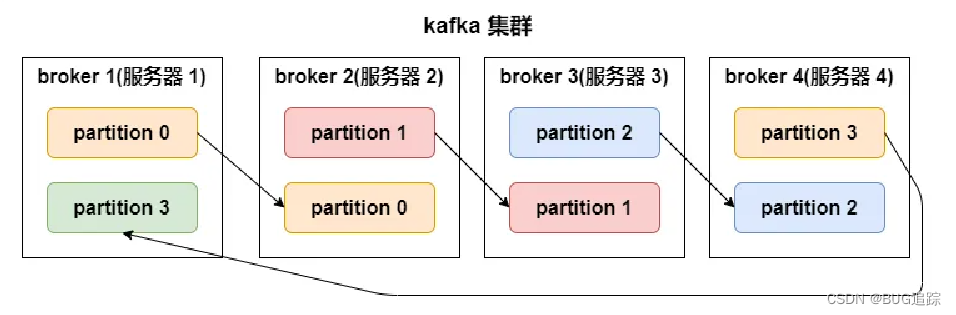
# 摘要
本文综述了Kafka监控与告警的关键要素和实用技巧,重点介绍了Kafka的关键性能指标、故障排查方法以及监控和告警系统的构建与优化。通过详细解析消息吞吐量、延迟、分区与副本状态、磁盘空间和I/O性能等关键指标,本文揭示了如何通过监控这些指标来评估Kafka集群的健康状况。同时,文中还探讨了常见的故障模式,提供了使用日志进行问题诊断的技巧,并介绍了多种故障排查工具和自动化脚本的应用。为了应
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )