pyparsing多文件处理技巧:批量解析和数据整合,提升工作效率
发布时间: 2024-10-16 16:47:53 阅读量: 29 订阅数: 32 

SMILES:使用pyparsing的简单SMILES验证器和解析器-.zip

# 1. pyparsing库简介与环境配置
## 简介
pyparsing是一个Python模块,提供了一种简单而强大的方式来解析文本数据。它允许开发者构建解析表达式,并对输入数据进行解析和提取。与正则表达式相比,pyparsing提供了更加直观和灵活的方式来处理复杂的文本解析任务。
## 环境配置
要开始使用pyparsing,首先需要确保你的Python环境中已经安装了该库。可以通过pip安装:
```bash
pip install pyparsing
```
安装完成后,你可以在Python脚本中导入并使用它:
```python
import pyparsing as pp
```
## 安装验证
安装完成后,可以通过运行简单的示例代码来验证pyparsing库是否安装成功:
```python
# 示例:解析一个简单的数学表达式
expr = pp.Word(pp.alphas) + "=" + pp.Word(pp.nums)
result = expr.parseString("x=5")
print(result)
```
如果一切正常,上述代码将输出:
```
['x', '=', '5']
```
这样,你就成功安装并验证了pyparsing库,可以开始进行更复杂的文本解析任务了。
# 2. pyparsing基础语法和解析技巧
## 2.1 pyparsing的核心组件
### 2.1.1 基本元素解析
在本章节中,我们将深入探讨pyparsing库的基本元素,这是构建任何解析器的基础。pyparsing库提供了一系列的解析器对象,用于识别和处理文本中的基本元素。基本元素包括字符串、数字、文本模式等。
基本元素的解析通常是通过创建一个`ParseElement`类的实例来完成的。例如,要解析一个字符串"Hello World",可以使用以下代码:
```python
from pyparsing import Word, alphas
greeting = Word(alphas)
result = greeting.parseString("Hello World")
print(result[0]) # 输出: Hello
```
在这个例子中,`Word(alphas)`创建了一个解析器,它可以匹配任何由字母组成的字符串。`parseString`方法用于在指定的文本中搜索匹配项,并返回一个`ParseResults`对象,其中包含了匹配的内容。
### 2.1.2 表达式和语法规则
pyparsing不仅支持基本元素的解析,还能够构建复杂的语法规则,以解析更复杂的字符串模式。这些规则是通过组合基本元素和运算符(如`+`、`|`、`*`等)来实现的。
例如,要解析一个简单的算术表达式,比如"1 + 2",可以使用以下代码:
```python
from pyparsing import nums, alphanums, Literal, Group, Combine, oneOf
expr = Combine(Group(nums) + Literal('+') + Group(nums))
result = expr.parseString("1 + 2")
print(result[0]) # 输出: 12+
```
在这个例子中,`Group(nums)`创建了一个解析器,它可以匹配一个数字。`Literal('+')`用于匹配加号。`Combine`用于将匹配的元素组合成一个单一的字符串。`Group`用于将多个元素组合成一个组,这样就可以使用`result[0]`来访问匹配的整个表达式。
## 2.2 pyparsing的解析流程
### 2.2.1 解析单个文件
解析单个文件是pyparsing库的一个常见用途。通过定义适当的语法规则,可以从文件中提取所需的信息。
例如,假设我们有一个文本文件`data.txt`,内容如下:
```
Name: John Doe
Age: 30
Location: New York
```
我们可以使用以下代码来解析这个文件:
```python
from pyparsing import *
# 定义语法规则
name = Word(alphas) + Literal(':') + Word(alphas)
age = Word(nums) + Literal(':') + Word(nums)
location = Word(alphas) + Literal(':') + Word(alphas)
# 解析文件
with open('data.txt', 'r') as ***
***
***
***
***
```
在这个例子中,我们定义了三个语法规则来匹配姓名、年龄和位置。然后,我们打开文件并读取内容,使用`searchString`方法来搜索匹配项。
### 2.2.2 解析字符串
除了解析文件,pyparsing还可以直接解析字符串。这对于处理动态生成的文本或进行单元测试非常有用。
例如,我们可以解析一个JSON格式的字符串:
```python
from pyparsing import *
# 定义JSON语法规则
js_string = Literal('"') + ZeroOrMore(chrange(sys.maxunicode)) + Literal('"')
js_number = Word(nums)
js_object = Forward()
js_pair = Group(js_string + Literal(':') + (js_string | js_number))
js_object <<= Group(Literal('{') + ZeroOrMore(js_pair + (Literal(',') + js_pair)) + Literal('}'))
# 解析JSON字符串
json_data = '{ "name": "John Doe", "age": 30, "location": "New York" }'
result = js_object.parseString(json_data)
print(result.dump())
```
在这个例子中,我们定义了一个简单的JSON语法规则,然后解析了一个JSON格式的字符串。
### 2.2.3 错误处理与异常管理
在解析过程中,可能会遇到格式不正确的数据,导致解析失败。pyparsing提供了强大的错误处理机制来管理和处理这些异常情况。
例如,我们可以定义一个错误处理函数来捕获解析错误:
```python
from pyparsing import *
# 定义语法规则
name = Word(alphas) + Literal(':') + Word(alphas)
age = Word(nums) + Literal(':') + Word(nums)
location = Word(alphas) + Literal(':') + Word(alphas)
# 错误处理函数
def handleParseException(l, s, t):
print("Parse error at '%s'" % t[0][0])
# 解析字符串并处理异常
try:
result = name.searchString("Invalid Data")
except ParseException as pe:
handleParseException(*pe)
```
在这个例子中,我们定义了一个错误处理函数`handleParseException`,当解析失败时,会打印出错误位置。然后,我们尝试解析一个格式不正确的字符串,并捕获并处理`ParseException`异常。
## 2.3 pyparsing的高级特性
### 2.3.1 可选元素与重复元素
在构建复杂的解析规则时,我们经常需要定义可选元素和重复元素。pyparsing提供了灵活的方式来处理这些情况。
例如,我们可以定义一个解析规则来匹配可选的电子邮件地址:
```python
from pyparsing import *
# 定义可选元素和重复元素
email = Word(alphanums) + Literal('@') + Word(alphanums) + Optional(Literal('.')) + Word(alphas)
email.ignore(Literal('[').suppress() + ZeroOrMore(charsNotIn(']')) + Literal(']'))
# 解析字符串
result = email.searchString("john.***")
print(result.dump())
```
在这个例子中,`Optional`用于定义可选的元素,即电子邮件地址中的点和顶级域名是可选的。
### 2.3.2 动态解析与数据驱动解析
pyparsing还支持动态解析,这意味着解析规则可以根据数据动态生成。这对于处理不规则或变化的文本格式非常有用。
例如,我们可以根据提供的模式动态构建解析规则:
```python
from pyparsing import *
# 定义动态解析规则
def createParserField(field):
return Word(alphas) + Literal(':') + field
# 创建解析器
parser = createParserField(Word(nums) | Word(alphanums))
# 解析字符串
result = parser.searchString("Name: John Doe")
print(result.dump())
```
在这个例子中,我们定义了一个函数`createParserField`,它根据提供的字段类型动态创建解析规则。然后,我们创建了一个解析器来解析姓名和年龄。
通过以上章节内容,我们已经对pyparsing的基础语法和解析技巧有了一个全面的了解。接下来,我们将进入更高级的主题,包括pyparsing的高级特性、多文件处理实践以及进阶应用。
# 3. 多文件处理实践
## 3.1 文件定位与筛选
### 3.1.1 文件路径和模式匹配
在处理多文件时,定位文件是一个基本而关键的步骤。使用文件路径和模式匹配可以有效地定位到指定的文件或文件集。在Python中,`os`和`glob`模块可以帮助我们实现这一点。
#### 代码示例
```python
import os
import glob
# 获取当前目录
current_directory = os.getcwd()
# 使用glob模块进行模式匹配
pattern = '*.txt'
matched_files = glob.glob(pattern, root_dir=current_directory)
# 打印匹配到的文件
for file in matched_files:
print(file)
```
#### 参数说明
- `os.getcwd()`: 获取当前工作目录的路径。
- `glob.glob()`: 在指定目录下根据模式匹配文件路径。
#### 逻辑分析
上述代码首先获取了当前工作目录,然后使用`glob.glob()`函数搜索所有扩展名为`.txt`的文件。这是一种简单而强大的方法来处理多文件场景。
### 3.1.2 文件属性筛选
文件属性筛选是指根据文件的属性(如大小、修改时间等)来筛选文件。Python的`os`模块提供了多种方法来获取文件属性。
#### 代码示例
```python
import os
# 获取文件属性
file_path = 'example.txt'
file_attrs = os.stat(file_path)
# 判断文件大小是否大于1024字节
if file_attrs.st_size > 1024:
print('文件大于1024字节')
else:
print('文件小于1024字节')
```
#### 参数说明
- `os.stat()`: 获取文件的状态信息,包括文件大小、修改时间等。
#### 逻辑分析
通过`os.stat()`函数,我们可以获取到文件的状态信息。在这个例子中,我们检查文件大小是否大于1024字节。这是筛选出特定大小文件的有效方法。
### 3.1.3 文件内容解析
一旦我们定位并筛选出了需要处理的文件,下一步就是解析文件内容。pyparsing库提供了强大的文本解析功能。
#### 代码示例
```python
from pyparsing import Word, alphas, nums, ParseException
# 定义一个简单的文本解析器
parser = Word(alphas + nums)
# 解析字符串
try:
result = parser.parseString('abc123')
print(result)
except ParseException as pe:
print(f'解析错误: {pe}')
```
#### 参数说明
- `Word()`: 定义一个词(一个或多个字符)作为解析的基本元素。
#### 逻辑分析
在这个例子中,我们定义了一个简单的解析器,它可以解析包含字母和数字的字符串。使用`parseString()`方法来尝试解析一个字符串。如果解析失败,将捕获`ParseException`异常。
### 3.1.4 文件解析结果处理
解析后的数据通常需要进行进一步的处理,如存储、比较或合并。
#### 代码示例
```python
# 假设我们已经有了一个解析结果列表
parse_results = ['abc123', 'def456', 'ghi789']
# 将解析结果存储到列表中
parsed_data = []
for result in parse_results:
try:
parsed_data.append(parser.parseString(result))
except ParseException as pe:
print(f'解析错误: {pe}')
# 比较和合并解析结果
# 这里只是一个简单的比较示例
if parsed_data[0] == parsed_data[1]:
print('前两个结果相同')
else:
print('前两个结果不同')
```
#### 逻辑分析
在这个代码段中,我们首先解析了一系列字符串,并将成功的解析结果存储到`parsed_data`列表中。然后,我们进行了一个简单的比较操作,比较前两个解析结果是否相同。这是处理解析结果的

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 pyparsing 库,这是一款功能强大的 Python 文本解析工具。从初学者入门指南到高级技术,本专栏涵盖了文本解析的所有方面。通过一系列循序渐进的教程和实际案例,您将掌握使用 pyparsing 高效解析文本、提取数据和构建自定义解析器所需的技能。此外,本专栏还探讨了 pyparsing 在自然语言处理、数据清洗、数据迁移和数据可视化等领域的应用。无论您是初学者还是经验丰富的开发者,本专栏都能为您提供全面的指导,帮助您充分利用 pyparsing 的强大功能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
台达触摸屏宏编程:入门到精通的21天速成指南

# 摘要
本文系统地介绍了台达触摸屏宏编程的全面知识体系,从基础环境设置到高级应用实践,为触摸屏编程提供了详尽的指导。首先概述了宏编程的概念和触摸屏环境的搭建,然后深入探讨了宏编程语言的基础知识、宏指令和控制逻辑的实现。接下来,文章介绍了宏编程实践中的输入输出操作、数据处理以及与外部设备的交互技巧。进阶应用部分覆盖了高级功能开发、与PLC的通信以及故障诊断与调试。最后,通过项目案例实战,展现了如何将理论知识应用
信号完整性不再难:FET1.1设计实践揭秘如何在QFP48 MTT中实现

# 摘要
本文综合探讨了信号完整性在高速电路设计中的基础理论及应用。首先介绍信号完整性核心概念和关键影响因素,然后着重分析QFP48封装对信号完整性的作用及其在MTT技术中的应用。文中进一步探讨了FET1.1设计方法论及其在QFP48封装设计中的实践和优化策略。通过案例研究,本文展示了FET1.1在实际工程应用中的效果,并总结了相关设计经验。最后,文章展望了FET
【MATLAB M_map地图投影选择】:理论与实践的完美结合
:no_upscale()/cdn.vox-cdn.com/uploads/chorus_asset/file/3470884/1024px-Robinson_projection_SW.0.jpg)
# 摘要
M_map工具包是一种在MATLAB环境下使用的地图投影软件,提供了丰富的地图投影方法与定制选项,用
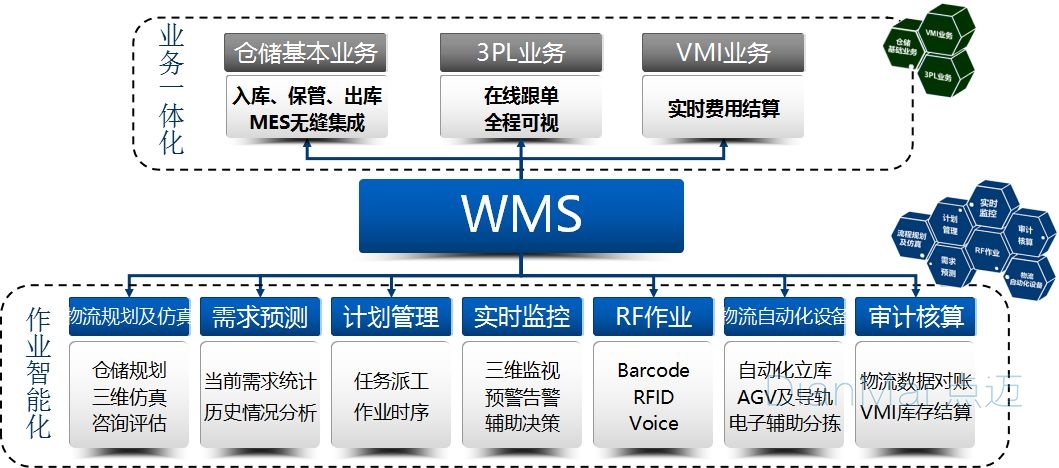
打造数据驱动决策:Proton-WMS报表自定义与分析教程
# 摘要
本文旨在全面介绍Proton-WMS报表系统的设计、自定义、实践操作、深入应用以及优化与系统集成。首先概述了报表系统的基本概念和架构,随后详细探讨了报表自定义的理论基础与实际操作,包括报表的设计理论、结构解析、参数与过滤器的配置。第三章深入到报表的实践操作,包括创建过程中的模板选择、字段格式设置、样式与交互设计,以及数据钻取与切片分析的技术。第四章讨论了报表分析的高级方法,如何进行大数据分析,以及报表的自动化
【DELPHI图像旋转技术深度解析】:从理论到实践的12个关键点

# 摘要
图像旋转是数字图像处理领域的一项关键技术,它在图像分析和编辑中扮演着重要角色。本文详细介绍了图像旋转技术的基本概念、数学原理、算法实现,以及在特定软件环境(如DELPHI)中的应用。通过对二维图像变换、旋转角度和中心以及插值方法的分析
RM69330 vs 竞争对手:深度对比分析与最佳应用场景揭秘

# 摘要
本文全面比较了RM69330与市场上其它竞争产品,深入分析了RM69330的技术规格和功能特性。通过核心性能参数对比、功能特性分析以及兼容性和生态系统支持的探讨,本文揭示了RM69330在多个行业中的应用潜力,包括消费电子、工业自动化和医疗健康设备。行业案例与应用场景分析部分着重探讨了RM69330在实际使用中的表现和效益。文章还对RM69330的市场表现进行了评估,并提供了应
无线信号信噪比(SNR)测试:揭示信号质量的秘密武器!
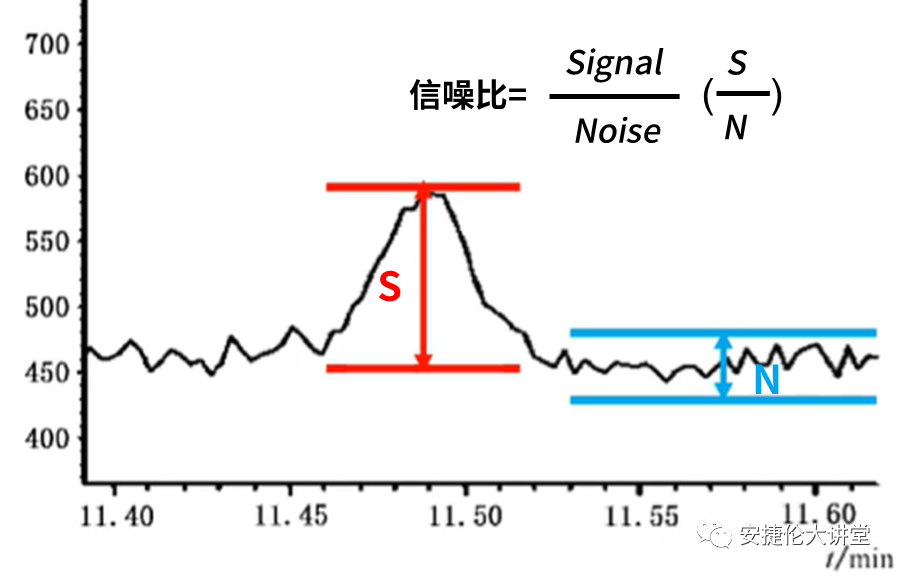
# 摘要
无线信号信噪比(SNR)是衡量无线通信系统性能的关键参数,直接影响信号质量和系统容量。本文系统地介绍了SNR的基础理论、测量技术和测试实践,探讨了SNR与无线通信系统性能的关联,特别是在天线设计和5G技术中的应用。通过分析实际测试案例,本文阐述了信噪比测试在无线网络优化中的重要作用,并对信噪比测试未来的技术发展趋势和挑战进行
【UML图表深度应用】:Rose工具拓展与现代UML工具的兼容性探索
# 摘要
本文系统地介绍了统一建模语言(UML)图表的理论基础及其在软件工程中的重要性,并对经典的Rose工具与现代UML工具进行了深入探讨和比较。文章首先回顾了UML图表的理论基础,强调了其在软件设计中的核心作用。接着,重点分析了Rose工具的安装、配置、操作以及在UML图表设计中的应用。随后,本文转向现代UML工具,阐释其在设计和配置方面的
台达PLC与HMI整合之道:WPLSoft界面设计与数据交互秘笈
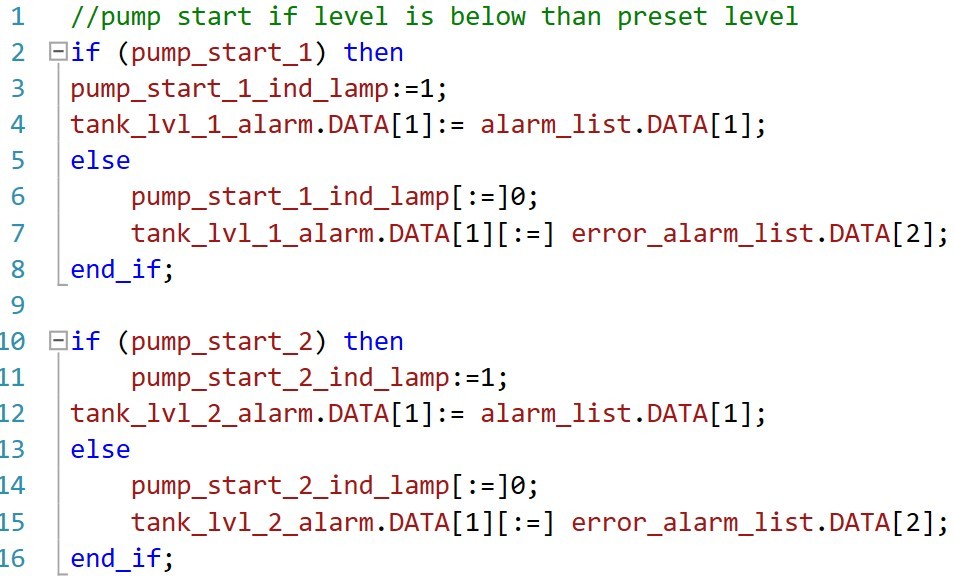
# 摘要
本文旨在提供台达PLC与HMI交互的深入指南,涵盖了从基础界面设计到高级功能实现的全面内容。首先介绍了WPLSoft界面设计的基础知识,包括界面元素的创建与布局以及动态数据的绑定和显示。随后深入探讨了WPLSoft的高级界面功能,如人机交互元素的应用、数据库与HMI的数据交互以及脚本与事件驱动编程。第四章重点介绍了PLC与HMI之间的数据交互进阶知识,包括PLC程序设计基础、
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )