Python版本维护必杀技:自动化版本更新和维护流程
发布时间: 2024-09-18 19:24:40 阅读量: 205 订阅数: 42 

Python与GitHub Actions:自动化你的开发流程
# 1. 版本控制的基础概念
在软件开发的历史长河中,版本控制始终扮演着至关重要的角色。它不仅确保了代码变更的追踪和管理,还为团队协作提供了基石。理解版本控制的基础概念是每一位软件工程师所必须的。本章将从最简单的版本控制系统开始,逐步深入到现代分布式版本控制系统如Git,并介绍它们如何帮助我们更有效地管理项目。
## 1.1 版本控制的含义
版本控制是一种记录一个或多个文件内容变化,以便将来查阅特定版本修订情况的系统。通过版本控制,开发者能够回溯到文件的历史状态,比较不同版本间的差异,以及同步多人之间的代码改动。
## 1.2 版本控制的类型
简单来说,版本控制分为两大类:集中式版本控制系统和分布式版本控制系统。
- **集中式版本控制系统**(CVCS)例如SVN,所有文件的变更历史都存储在服务器上。开发者通过检出(Checkout)和提交(Commit)来与中心仓库交互。
- **分布式版本控制系统**(DVCS)如Git,每个开发者的本地仓库都拥有完整的代码历史和版本记录。开发者之间的协作通过推送(Push)和拉取(Pull)来进行。
## 1.3 版本控制的实践意义
版本控制不仅提供了项目变更的历史视图,它还极大地提高了开发效率和代码质量。在现代开发实践中,良好的版本控制流程是持续集成和持续部署的基础,也是团队协作不可或缺的工具。
通过本章的学习,读者将获得对版本控制基本知识的深刻理解,并为进一步学习自动化版本更新打下坚实的基础。
# 2. 自动化版本更新的理论与实践
## 2.1 版本号的管理策略
### 2.1.1 语义化版本控制(SemVer)
语义化版本控制(SemVer)是一种流行的版本命名约定,它基于项目版本号的三个数字组成:主版本号、次版本号和修订号,格式通常表示为 X.Y.Z。这种版本号管理策略对用户明确传达了版本变更的性质,帮助用户决定是否升级他们的软件。
主版本号(X):当做了不兼容的 API 修改时,主版本号增加。这种变更一般会需要用户重新编写部分代码,因为接口发生了变化。
次版本号(Y):当做了向下兼容的功能性新增时,次版本号增加。这意味着添加了新的功能,但是没有破坏已有功能。
修订号(Z):当做了向下兼容的问题修正时,修订号增加。通常用于小错误修复,不影响功能的变更。
语义化版本控制的好处是显而易见的。它简化了版本更新的决策过程,对于依赖管理尤其重要。当一个项目遵循SemVer规范时,用户可以根据版本号中的变化了解到变更的性质,决定是否需要升级他们的应用以获得新的功能或者修复问题。
### 2.1.2 版本号在项目中的意义和影响
版本号对于项目有着深远的意义,它不仅标记了项目发展的阶段,而且对于项目的可持续性管理至关重要。一个项目的版本号是用户选择是否升级的重要依据,它帮助用户理解更新内容的性质和影响。
版本号还影响着项目维护者管理依赖关系和处理版本冲突。如果两个依赖库的版本不兼容,可能会导致项目构建失败或者运行时错误。因此,项目维护者需要有策略地管理依赖库的版本,以确保项目的稳定运行。
在自动化版本更新的实践中,版本号的管理需要被集成到构建和部署的流程中。例如,自动化构建系统可以配置为在每次构建时自动增加版本号,而部署系统则可以根据版本号来决定部署哪个版本的应用。
在本节中,我们将更深入地探讨如何使用Git这种现代版本控制系统来管理和自动化版本号的更新。
## 2.2 使用Git进行版本控制
### 2.2.1 Git的安装与配置
Git是一个开源的分布式版本控制系统,由Linus Torvalds于2005年开发。它能够跟踪源代码的变更,并且提供了很多特性,如分支管理、合并、版本比较和变更回退等。
安装Git通常是一个简单的过程。在大多数Linux发行版中,Git可以通过包管理器安装。在Windows系统上,可以从Git官方网站下载安装程序进行安装。对于macOS用户,Xcode的命令行工具包含了Git。
安装Git后,用户可以进行基本的配置。配置信息可以存储在用户目录下的`.gitconfig`文件中。最基本的配置项包括用户名称和邮箱地址:
```bash
git config --global user.name "Your Name"
git config --global user.email "***"
```
这样的配置是推荐的,因为Git在提交变更时会记录这些信息。
### 2.2.2 Git工作流与分支管理
使用Git进行版本控制时,开发者通常遵循一定的工作流。一个典型的工作流包括创建分支、提交更改、合并分支和处理合并冲突。
Git分支是指向提交记录的指针。创建新分支非常简单:
```bash
git checkout -b new-branch-name
```
这个命令创建了一个名为`new-branch-name`的新分支,并自动切换到这个分支上。在分支上进行更改后,可以通过以下命令提交到本地仓库:
```bash
git commit -am "Meaningful commit message"
```
将更改合并回主分支之前,需要确保更改与主分支保持同步,这可以通过拉取远程分支的最新更改来完成:
```bash
git pull origin main
```
如果在合并时出现了冲突,Git会停止合并过程,并允许开发者解决冲突。解决冲突后,合并过程可以继续。
分支管理是维护项目代码健康的重要部分。良好的分支管理策略,比如使用特性分支(feature branching)或Gitflow工作流,可以帮助团队成员有效地协作,同时减少错误和冲突。
## 2.3 自动化脚本的编写
### 2.3.1 编写脚本更新版本号
自动化版本更新的一个关键步骤是在构建过程中更新版本号。可以通过编写简单的脚本来实现这一点。
以下是一个Bash脚本示例,它自动读取当前的版本号,增加主版本号,并将新版本号写回到源代码文件中:
```bash
#!/bin/bash
VERSION=$(grep 'VERSION' config.py | cut -d '=' -f2 | tr -d '[:space:]')
NEW_VERSION=$(echo "$VERSION" | awk -F. -v OFS=. '{$NF += 1; print}')
sed -i "s/$VERSION/$NEW_VERSION/" config.py
echo "Version updated from $VERSION to $NEW_VERSION"
```
这个脚本首先从`config.py`文件中提取当前版本号,然后通过`awk`命令计算新版本号,最后使用`sed`命令更新版本号。
### 2.3.2 脚本测试与错误处理
编写自动化脚本时,测试和错误处理是不可或缺的。测试确保脚本按照预期工作,而错误处理确保脚本在遇到意外情况时能够优雅地处理。
测试脚本可以通过编写单元测试或者使用模拟数据来完成。对于上述脚本,可以模拟`config.py`文件,然后检查脚本是否正确更新了版本号。
错误处理可以通过检查环境变量、输入参数、文件权限等来实现。脚本应当在无法获取版本号、版本号格式不正确或文件写入失败时,给出清晰的错误信息。
```bash
if ! grep -q 'VERSION' config.py; then
echo "Error: VERSION variable not found in config.py"
exit 1
fi
```
这段代码检查`config.py`文件中是否存在`VERSION`变量。如果不存在,脚本将输出错误信息并退出。
在本节中,我们学习了如何使用Git进行有效的版本控制,以及如何编写自动化脚本进行版本号的管理。接下来的章节将深入探讨版本发布的自动化流程。
# 3. 版本发布的自动化流程
自动化流程的构建是现代软件开发中的关键环节,它涉及构建、测试和部署的自动化。本章节将深入探讨如何通过自动化工具和脚本实现一个高效、可靠且可重复的发布流程。
## 3.1 构建自动化工具
构建自动化工具是确保每次代码变更都能顺利通过编译,并将代码打包成可分发格式的关键。它不仅加速了开发周期,还确保了每次构建的一致性和可追溯性。
### 3.1.1 选择适合的构建工具
选择合适的构建自动化工具对于项目的成功至关重要。构建工具需要支持项目的构建脚本、依赖管理和环境配置。常见构建工具如Maven、Gradle、Ant等,它们各有特点:
- Maven以其约定优于配置的理念,拥有成熟的插件系统和广泛的社区支持。
- Gradle提供了更灵活的构建脚本编写能力,支持Groovy或Kotlin DSL,使得构建脚本更加简洁和强大。
- Ant是较为传统的构建工具,其XML构建文件配置灵活,但配置相对繁琐。
```gradle
// Gradle示例构建脚本片段
apply plugin: 'java'
apply plugin: 'maven-publish'
repositories {
mavenCentral()
}
dependencies {
implementation 'org.example:library:1.0.0'
}
publishing {
publications {
mavenJava(MavenPublication) {
from components.java
}
}
}
```
上面的Gradle脚本配置了一个简单的项目构建过程,其中包含了项目的依赖配置和发布配置。
### 3.1.2 构建过程中版本信息的嵌入
在构建过程中,自动化地更新版本号是避免发布混淆的重要步骤。这可以通过在构建脚本中使用特定的变量或标记来实现。
```gradle
version = "${versionMajor}.${versionMinor}.${versionPatch}-SNAPSHOT"
// 在构建时,可以使用以下命令更新版本号
def releaseVersion = "1.0.0"
version = releaseVersion
```
在上述代码中,我们可以看到如何在Gradle构建脚本中配置和更新项目版本。每次构建时,版本号都会根据需要进行修改,从而避免重复和混淆。
## 3.2 测试自动化
测试自动化是确保软件质量的关键环节。它涵盖

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏聚焦于 Python 版本管理和优化,提供了一系列深入指南和实用技巧。从平滑迁移到 Python 3 的秘籍到精通 pyenv 和 virtualenvwrapper 的实战手册,再到分析和解决版本冲突的专家级方案,专栏涵盖了 Python 版本管理的各个方面。此外,还提供了自动化版本更新和维护流程的必杀技,以及选择合适版本以优化性能的关键因素。通过阅读本专栏,Python 开发人员可以掌握管理和优化 Python 版本的全面知识,从而提升开发效率和应用程序性能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【MATLAB中MSK调制的艺术】:差分编码技术的优化与应用

# 摘要
MSK调制技术作为现代通信系统中的一种关键调制方式,与差分编码相结合能够提升信号传输的效率和抗干扰能力。本文首先介绍了MSK调制技术和差分编码的基础理论,然后详细探讨了差分编码在MSK调制中的应用,包括MSK调制器设计与差分编码
从零开始学习RLE-8:一文读懂BMP图像解码的技术细节

# 摘要
本文从编码基础与图像格式出发,深入探讨了RLE-8编码技术在图像处理领域的应用。首先介绍了RLE-8编码机制及其在BMP图像格式中的应用,然后详细阐述了RLE-8的编码原理、解码算法,包括其基本概念、规则、算法实现及性能优化策略。接着,本文提供了BMP图像的解码实践指南,解析了文件结构,并指导了RLE-8解码器的开发流程。文章进一步分析了RLE-8在图像压缩中的优势和适用场景,以及其在高级图像处
Linux系统管理新手入门:0基础快速掌握RoseMirrorHA部署
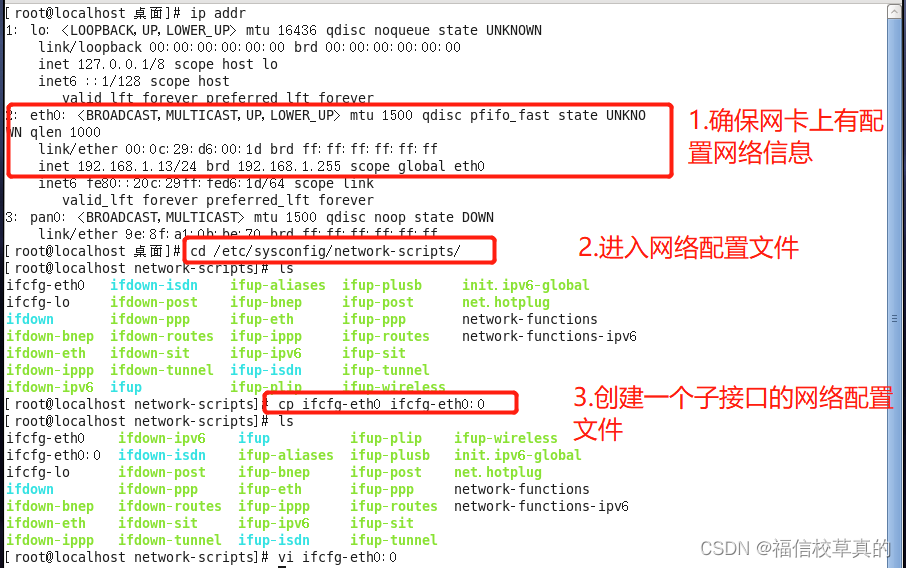
# 摘要
本文首先介绍了Linux系统管理的基础知识,随后详细阐述了RoseMirrorHA的理论基础及其关键功能。通过逐步讲解Linux环境下RoseMirrorHA的部署流程,包括系统要求、安装、配置和启动,本文为系统管理员提供了一套完整的实施指南。此外,本文还探讨了监控、日常管理和故障排查等关键维护任务,以及高可用场景下的实践和性能优化策略。最后,文章展望了Linux系统管理和R
用户体验:华为以用户为中心的设计思考方式与实践
# 摘要
用户体验在当今产品的设计和开发中占据核心地位,对产品成功有着决定性影响。本文首先探讨了用户体验的重要性及其基本理念,强调以用户为中心的设计流程,涵盖用户研究、设计原则、原型设计与用户测试。接着,通过华为的设计实践案例分析,揭示了用户研究的实施、用户体验的改进措施以及界面设计创新的重要性。此外,本文还探讨了在组织内部如何通过
【虚拟化技术】:smartRack资源利用效率提升秘籍
# 摘要
本文全面介绍了虚拟化技术,特别是smartRack平台在资源管理方面的关键特性和实施技巧。从基础的资源调度理论到存储和网络资源的优化,再到资源利用效率的实践技巧,本文系统阐述了如何在smartRack环境下实现高效的资源分配和管理。此外,本文还探讨了高级资源管理技巧,如资源隔离、服务质量(QoS)保障以及性能分析与瓶颈诊
【聚类算法选型指南】:K-means与ISODATA对比分析
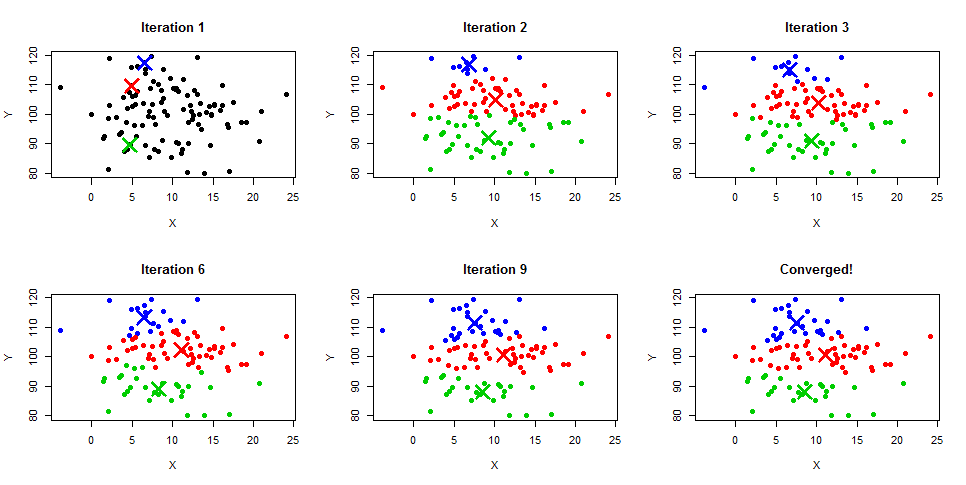
# 摘要
本文系统地介绍了聚类算法的基础知识,着重分析了K-means算法和ISODATA算法的原理、实现过程以及各自的优缺点。通过对两种算法的对比分析,本文详细探讨了它们在聚类效率、稳定性和适用场景方面的差异,并展示了它们在市场细分和图像分割中的实际应用案例。最后,本文展望了聚类算法的未来发展方向,包括高维数据聚类、与机器学习技术的结合以及在新兴领域的应用前景。
# 关
小米mini路由器序列号恢复:专家教你解决常见问题

# 摘要
本文对小米mini路由器序列号恢复问题进行了全面概述。首先介绍了小米mini路由器的硬件基础,包括CPU、内存、存储设备及网络接口,并探讨了固件的作用和与硬件的交互。随后,文章转向序列号恢复的理论基础,阐述了序列号的重要性及恢复过程中的可行途径。实践中,文章详细描述了通过Web界面和命令行工具进行序列号恢复的方法。此外,本文还涉及了小米mini路由器的常见问题解决,包括
深入探讨自然辩证法与软件工程的15种实践策略

# 摘要
自然辩证法作为哲学原理,为软件工程提供了深刻的洞见和指导原则。本文探讨了自然辩证法的基本原理及其在软件开发、设计、测试和管理中的应用。通过辩证法的视角,文章分析了对立统一规律、质量互变规律和否定之否定原则在软件生命周期、迭代优化及软件架构设计中的体现。此外,还讨论了如何将自然辩证法应用于面向对象设计、设计模式选择以及测试策略的制定。本文强调了自然辩证法在促进软
【自动化控制】:PRODAVE在系统中的关键角色分析

# 摘要
本文对自动化控制与PRODAVE进行了全面的介绍和分析,阐述了PRODAVE的基础理论、应用架构以及在自动化系统中的实现。文章首先概述了PRODAVE的通信协议和数据交换模型,随后深入探讨了其在生产线自动化、能源管理和质量控制中的具体应用。通过对智能工厂、智能交通系统和智慧楼宇等实际案例的分析,本文进一步揭示了PR
【VoIP中的ITU-T G.704应用】:语音传输最佳实践的深度剖析

# 摘要
本文系统地分析了ITU-T G.704协议及其在VoIP技术中的应用。文章首先概述了G.704协议的基础知识,重点阐述了其关键特性,如帧结构、时间槽、信道编码和信号传输。随后,探讨了G.704在保证语音质量方面的作用,包括误差检测控制机制及其对延迟和抖动的管理。此外,文章还分析了G.704
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )