MySQL数据库备份与恢复指南:全面解析备份与恢复方案
发布时间: 2024-07-23 00:11:43 阅读量: 40 订阅数: 49 

基于springboot的酒店管理系统源码(java毕业设计完整源码+LW).zip
# 1. MySQL数据库备份原理与策略**
MySQL数据库备份是创建数据库副本的过程,以保护数据免遭丢失或损坏。备份策略定义了备份的类型、频率和保留策略。
**备份类型:**
- **物理备份:**复制数据库文件,包括数据文件、日志文件和配置。
- **逻辑备份:**导出数据库架构和数据,生成可用于恢复数据库的脚本。
**备份频率:**
- **全量备份:**定期创建整个数据库的备份,通常在非高峰时段进行。
- **增量备份:**仅备份自上次全量备份以来更改的数据,减少备份时间和存储空间。
# 2. MySQL数据库备份实践
MySQL数据库备份是数据库管理中至关重要的任务,它可以保护数据免受意外丢失、硬件故障或人为错误的影响。本章将介绍MySQL数据库的两种主要备份类型:物理备份和逻辑备份,并详细探讨每种类型的工具和方法。
### 2.1 物理备份
物理备份直接复制数据库文件,从而创建数据库的完整副本。物理备份通常用于快速恢复整个数据库或其一部分。
#### 2.1.1 mysqldump工具备份
mysqldump是MySQL自带的命令行工具,用于创建数据库的逻辑备份。它将数据库结构和数据转储为文本文件,可以轻松地导入其他MySQL服务器。
```bash
mysqldump -u root -p --all-databases > backup.sql
```
**参数说明:**
* `-u root`: 使用root用户连接数据库
* `-p`: 提示输入root用户的密码
* `--all-databases`: 备份所有数据库
* `> backup.sql`: 将备份输出到backup.sql文件中
**逻辑分析:**
mysqldump命令连接到MySQL服务器,并使用指定的用户名和密码进行身份验证。然后,它遍历所有数据库,转储数据库结构和数据,并将其写入指定的文件中。
#### 2.1.2 xtrabackup工具备份
xtrabackup是Percona开发的开源工具,用于创建MySQL数据库的物理备份。它通过复制数据文件和二进制日志来创建一致的备份,即使数据库正在运行。
```bash
xtrabackup --backup --target-dir=/backup
```
**参数说明:**
* `--backup`: 指定备份操作
* `--target-dir=/backup`: 指定备份目录
**逻辑分析:**
xtrabackup工具连接到MySQL服务器,并创建一个临时目录来存储备份文件。然后,它复制数据文件和二进制日志,并将其写入临时目录。最后,它将临时目录移动到指定的备份目录。
### 2.2 逻辑备份
逻辑备份只备份数据库中的数据,而不包括数据库结构。逻辑备份通常用于增量备份或恢复特定数据子集。
#### 2.2.1 binlog备份
binlog备份将数据库中的所有写入操作记录到二进制日志文件中。binlog备份可以用于恢复数据库到特定时间点,或者用于复制数据到其他服务器。
```bash
mysqlbinlog --start-datetime="2023-03-08 12:00:00" --stop-datetime="2023-03-08 14:00:00" > binlog.log
```
**参数说明:**
* `--start-datetime`: 指定备份的开始时间
* `--stop-datetime`: 指定备份的结束时间
* `> binlog.log`: 将备份输出到binlog.log文件中
**逻辑分析:**
mysqlbinlog命令连接到MySQL服务器,并从指定的开始时间到结束时间读取二进制日志。然后,它将读取到的二进制日志记录写入指定的文件中。
#### 2.2.2 row-based备份
row-based备份只备份数据库中的特定行或表。row-based备份通常用于恢复特定数据子集,或者用于将数据从一个数据库迁移到另一个数据库。
```sql
SELECT * INTO OUTFILE '/tmp/table.csv'
FROM table_name
WHERE id > 100;
```
**参数说明:**
* `INTO OUTFILE`: 指定将查询结果输出到文件中
* `/tmp/table.csv`: 指定输出文件路径
* `FROM table_name`: 指定要备份的表
* `WHERE id > 100`: 指定要备份的行的条件
**逻辑分析:**
该查询从table_name表中选择id大于100的行,并将结果输出到/tmp/table.csv文件中。
# 3.1 物理恢复
物理恢复是指从物理备份中恢复数据库。物理备份直接将数据库文件复制到另一个位置,因此恢复速度快,但灵活性较差。
#### 3.1.1 从物理备份恢复
从物理备份恢复数据库的步骤如下:
1. 停止数据库服务。
2. 将备份文件复制到要恢复的服务器。
3. 覆盖现有数据库文件。
4. 启动数据库服务。
**代码块:**
```
# 停止数据库服务
systemctl stop mysql
# 复制备份文件
cp /path/to/backup.sql /var/lib/mysql
# 覆盖现有数据库文件
rm -rf /var/lib/mysql/*
cp -r /path/to/backup/* /var/lib/mysql
# 启动数据库服务
systemctl start mysql
```
**逻辑分析:**
* `systemctl stop mysql`:停止 MySQL 服务。
* `cp /path/to/backup.sql /var/lib/mysql`:将备份文件复制到 MySQL 数据目录。
* `rm -rf /var/lib/mysql/*`:删除现有数据库文件。
* `cp -r /path/to/backup/* /var/lib/mysql`:将备份文件中的内容复制到 MySQL 数据目录。
* `systemctl start mysql`:启动 MySQL 服务。
#### 3.1.2 从快照恢复
快照是数据库在某个时间点的完整副本。从快照恢复数据库的步骤如下:
1. 创建快照。
2. 停止数据库服务。
3. 将快照还原到要恢复的服务器。
4. 启动数据库服务。
**代码块:**
```
# 创建快照
aws ec2 create-snapshot --volume-id vol-12345678
# 停止数据库服务
systemctl stop mysql
# 还原快照
aws ec2 restore-snapshot-to-volume --snapshot-id snap-12345678 --volume-id vol-87654321
# 启动数据库服务
systemctl start mysql
```
**逻辑分析:**
* `aws ec2 create-snapshot --volume-id vol-12345678`:创建快照。
* `systemctl stop mysql`:停止 MySQL 服务。
* `aws ec2 restore-snapshot-to-volume --snapshot-id snap-12345678 --volume-id vol-87654321`:将快照还原到要恢复的服务器。
* `systemctl start mysql`:启动 MySQL 服务。
# 4. MySQL数据库备份与恢复方案
### 4.1 备份方案设计
**4.1.1 备份类型选择**
根据业务需求和数据重要性,选择合适的备份类型。主要有以下几种备份类型:
| 备份类型 | 特点 | 适用场景 |
|---|---|---|
| **全量备份** | 备份数据库所有数据 | 数据完整性要求高,重要数据定期备份 |
| **增量备份** | 备份上次备份后的数据变更 | 备份频率高,恢复速度快 |
| **差异备份** | 备份上次全量备份后的所有数据变更 | 介于全量备份和增量备份之间,恢复速度较快 |
**4.1.2 备份频率和保留策略**
确定备份频率和保留策略,以满足业务连续性和数据恢复需求。
| 备份频率 | 保留策略 | 适用场景 |
|---|---|---|
| **每天备份** | 保留最近7天备份 | 数据变更频繁,恢复时间要求短 |
| **每周备份** | 保留最近4周备份 | 数据变更较少,恢复时间要求中等 |
| **每月备份** | 保留最近12个月备份 | 数据变更极少,恢复时间要求长 |
### 4.2 恢复方案设计
**4.2.1 恢复目标设定**
明确恢复目标,包括恢复时间目标 (RTO) 和恢复点目标 (RPO)。
- **RTO:**数据库恢复到可用的时间间隔。
- **RPO:**数据丢失的最大可接受时间间隔。
**4.2.2 恢复步骤和流程**
制定详细的恢复步骤和流程,包括:
1. **故障识别:**识别数据库故障类型和原因。
2. **备份选择:**根据故障类型和RPO选择合适的备份。
3. **恢复操作:**执行备份恢复操作,恢复数据库数据。
4. **验证恢复:**验证恢复后的数据库数据是否完整和一致。
5. **故障分析:**分析故障原因,采取措施防止类似故障再次发生。
**示例恢复流程图:**
```mermaid
graph LR
subgraph 故障识别
A[故障识别]
end
subgraph 备份选择
B[备份选择]
end
subgraph 恢复操作
C[恢复操作]
end
subgraph 验证恢复
D[验证恢复]
end
subgraph 故障分析
E[故障分析]
end
A --> B
B --> C
C --> D
D --> E
```
**恢复操作代码示例:**
```bash
# 从全量备份恢复
mysql -u root -p < full_backup.sql
# 从增量备份恢复
mysqlbinlog incremental_backup.log | mysql -u root -p
# 从差异备份恢复
mysql -u root -p < differential_backup.sql
```
**代码逻辑分析:**
- `mysql -u root -p`:使用指定用户和密码连接到MySQL数据库。
- `< full_backup.sql`:从全量备份文件中读取SQL语句并执行。
- `mysqlbinlog incremental_backup.log`:读取增量备份日志文件并解析SQL语句。
- `| mysql -u root -p`:将解析后的SQL语句管道到MySQL数据库执行。
- `< differential_backup.sql`:从差异备份文件中读取SQL语句并执行。
# 5.1 备份和恢复工具的选择
在选择备份和恢复工具时,需要考虑以下因素:
- **功能特性:**工具是否支持所需的备份和恢复类型,如物理备份、逻辑备份、增量备份、并行备份等。
- **性能效率:**工具的备份和恢复速度是否满足业务需求,尤其是对于大规模数据库。
- **兼容性:**工具是否与使用的MySQL版本兼容,以及是否支持跨平台恢复。
- **易用性:**工具的界面是否友好,操作是否简单,是否提供自动化功能。
- **成本:**工具的许可费用、维护成本和支持服务是否在预算范围内。
常用的MySQL备份和恢复工具包括:
- **物理备份工具:**
- mysqldump:MySQL官方提供的命令行工具,用于导出数据库结构和数据。
- xtrabackup:Percona开发的工具,用于创建一致性备份,支持在线备份。
- **逻辑备份工具:**
- binlog:MySQL的二进制日志,记录了数据库的所有修改操作。
- row-based备份工具:如MySQL Enterprise Backup、MariaDB MaxScale等,用于备份数据库中的行级数据。
## 5.2 备份和恢复性能优化
优化备份和恢复性能可以提高数据库的可用性和效率。以下是一些优化技巧:
- **选择合适的备份类型:**对于大规模数据库,增量备份或并行备份可以显著提高备份速度。
- **优化备份参数:**调整备份工具的参数,如压缩级别、并行线程数等,以提高备份效率。
- **选择合适的恢复方法:**对于逻辑恢复,可以考虑使用并行恢复或基于时间点的恢复,以缩短恢复时间。
- **使用高速存储设备:**使用SSD或NVMe等高速存储设备可以加快备份和恢复速度。
- **定期清理备份:**删除过期的或不必要的备份,以节省存储空间和提高恢复效率。
## 5.3 备份和恢复安全保障
确保备份和恢复的安全至关重要,以防止数据泄露或篡改。以下是一些安全保障措施:
- **加密备份:**使用加密算法对备份进行加密,以防止未经授权的访问。
- **限制访问权限:**只授予必要的人员访问备份和恢复工具的权限。
- **定期测试恢复:**定期进行恢复测试,以验证备份的完整性和恢复流程的有效性。
- **异地备份:**将备份存储在异地数据中心或云端,以防止本地灾难导致数据丢失。
- **监控备份和恢复活动:**使用监控工具监控备份和恢复活动,及时发现异常情况并采取措施。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏标题:“SQL数据库备份方法”
本专栏深入探讨了SQL数据库备份的各个方面,从基础知识到高级策略和实践。它涵盖了各种数据库管理系统,包括MySQL、PostgreSQL、Oracle、SQL Server、MongoDB、Redis、Elasticsearch和Cassandra。专栏提供了详细的指南、实战演练和最佳实践,帮助读者掌握数据库备份与恢复的各个方面。此外,它还探讨了备份性能优化、安全策略、监控与管理、自动化以及故障排除,确保读者能够有效地保护和恢复其关键数据。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
EIA-481-D标准:10大实施指南,确保供应链追踪效率与合规性

# 摘要
EIA-481-D标准是一种广泛应用于多个行业的条码标签和数据交换标准,旨在提升供应链的追踪效率和合规性。本文首先概述了EIA-481-D标准的理论基础,包括其起源、发展和核心要求,特别是关键数据格式与编码解析。其次,详细阐述了该标准在实践中的应用指南,包括标签的应用、数据管理和电子交换的最
R420读写器GPIO安全实操:保障数据传输安全的终极指南

# 摘要
R420读写器是一种广泛应用于数据传输的设备,其安全性和效率很大程度上取决于通用输入输出(GPIO)接口的安全管理。本文首先概述了R420读写器与GPIO的基础知识,接着深入探讨了GPIO在数据传输中的安全机制,并分析了数据传输的安全威胁及其理论基础。第三章提供了R420读写器GPIO的安全实操技巧,包括配置、初始化、数据加密操作及防范攻击方法。进阶应用章节详述了GPIO在高级加密算法中的应用、构建安全数据传输链
硬件仿真中的Microblaze调试:24小时内掌握实战案例分析
# 摘要
本文首先概述了硬件仿真与Microblaze处理器的基础知识,接着详细介绍了Microblaze的调试技术,包括处理器架构理解、仿真环境的搭建、基本调试工具和命令的使用。文章的后半部分着重探讨了Microblaze调试的进阶技巧,如性能分析、中断和异常处理,以及多处理器仿真调试技术。通过实战案例分析,本文具体说明了调试流
美观实用两不误:ECharts地图自定义数值样式完全手册
# 摘要
随着数据可视化在现代信息系统中变得越来越重要,ECharts作为一款流行的JavaScript图表库,其地图功能尤其受到关注。本文全面介绍了ECharts地图的基础知识、自定义样式理论基础、数值样式自定义技巧和进阶应用。文章深入探讨了样式自定义在数据可视化中的作用、性能优化、兼
TRACE32时间戳与性能分析:程序执行时间的精确测量

# 摘要
本文全面探讨了TRACE32在程序性能分析中的应用,强调了时间戳功能在准确记录和优化程序性能方面的重要性。章节首先介绍了TRACE32的基础知识和时间戳功能的生成机制及记录方式,进而详细阐述
信息系统项目风险评估与应对策略:从理论到实操
# 摘要
信息系统项目风险评估是确保项目成功的关键环节,涉及到风险的识别、分类、评估及管理。本文首先介绍了信息系统项目风险评估的基础知识,包括风险的来源分析与指标建立,接着详细阐述了风险的分类方法,探讨了定性和定量风险评估技术,以及风险评估工具的应用实践。此外,文章还讨论了项目风险管理计划的制定,涵盖风险应对策
【MySQL复制与故障转移】:数据库高可用性的关键掌握
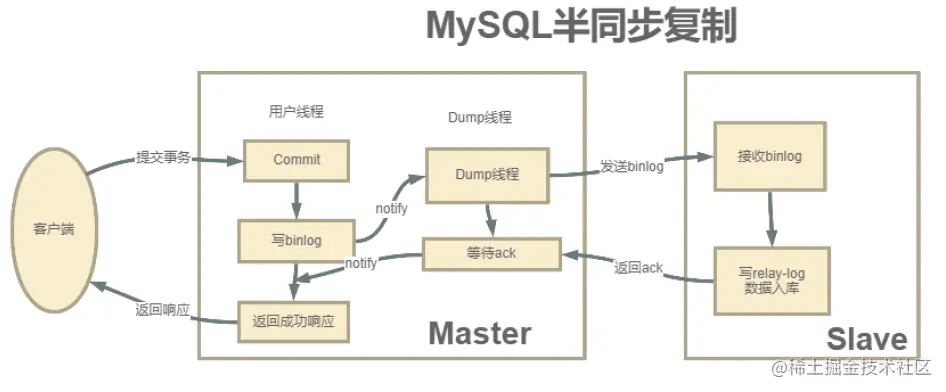
# 摘要
本文系统地探讨了MySQL复制技术的基础知识、配置管理、故障转移策略以及高可用性架构设计的理论与实践。首先,介绍了MySQL复制的基本原理,随后详细阐述了如何配置和管理复制环境,包括主从复制的搭建和日志管理。接着,文章深入分析了故障转移的概念、策略及其在实际场景中的应用。此外,本文还讨论了高可
【WZl客户端补丁编辑器:快速入门到专家】:一步步构建并应用补丁

# 摘要
本文系统性地介绍了WZl客户端补丁编辑器的各个方面,从基础操作到高级技巧,再到未来的趋势和扩展。首先概述了补丁编辑器的基本功能与界面布局,随后深入解析了补丁文件结构和编辑流程。文章接着探讨了补丁逻辑与算法的原理和实现,强调了高级逻辑处理和脚本编写的重要性。通过实践操作章节,详细指导了如何构建和优化自定义补丁。在编辑器的高级技巧与优化部分,本文介绍了高级功能的使用以及版本
【数据库故障无处遁形】:工厂管理系统问题诊断到解决全攻略
# 摘要
本文全面探讨了数据库故障的识别、分类、诊断、排查技术,以及维护、优化和恢复策略。首先,对数据库故障进行识别与分类,为接下来的故障诊断提供了理论基础。随后深入讨论了故障诊断技术,包括日志分析技术、性能监控工具的使用和自动化检测,并分析了故障模式与影响分析(FMEA)在实际案例中的应用。在实践排查技术方面,文章详细介绍了事务、锁机制、索引与查询性能及系统资源和硬件故障的排查方法
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )