【wget递归下载秘籍】:深入网站架构,高效抓取数据
发布时间: 2024-12-11 18:51:56 阅读量: 17 订阅数: 13 

使用wget递归镜像网站
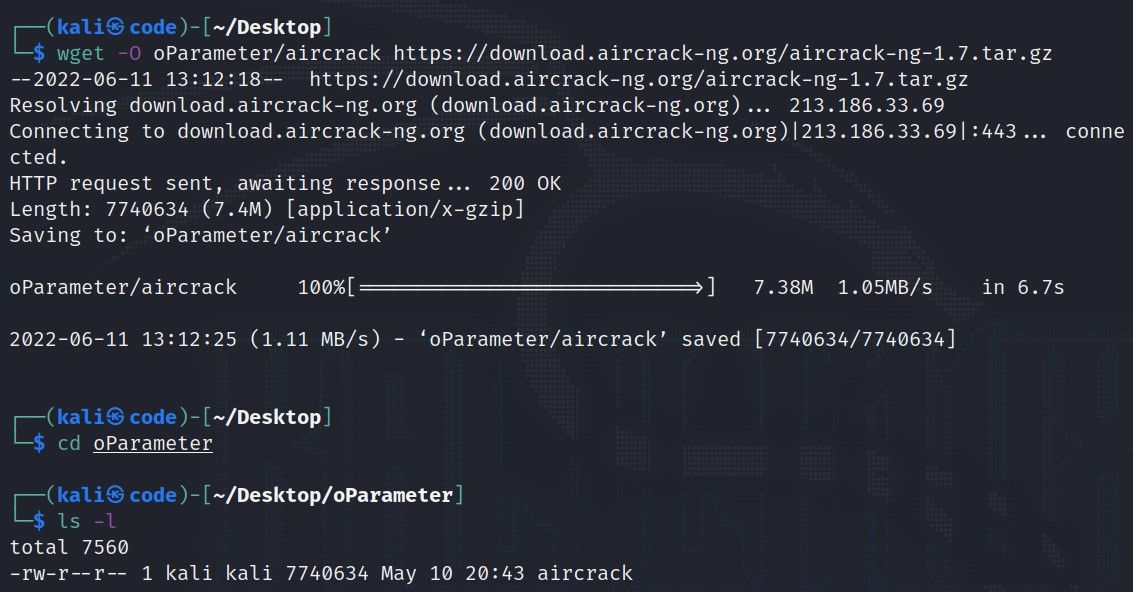
# 1. wget递归下载基础知识
在本章中,我们将从基础开始,介绍wget递归下载的概念、作用以及它的主要应用场景。wget作为一款广泛使用的开源命令行工具,不仅能够下载单个文件,还可以递归地下载整个网站。它特别适合于数据抓取、网站存档以及离线浏览等需求。
## 1.1 wget简介
wget是一个强大的网络工具,用于从网络上自动下载文件。它支持HTTP、HTTPS和FTP等协议,可以通过简单或复杂的命令控制从服务器获取数据。在递归下载中,wget可以下载一个网页的所有链接资源,非常适合于备份网站或对网页内容进行完整抓取。
## 1.2 递归下载的定义
递归下载是指wget不仅下载指定的初始URL,还会尝试下载所有在初始页面中找到的、符合特定条件的链接资源。这包括页面中的所有图片、CSS文件、JavaScript文件和其他依赖资源,从而实现对网站内容的全面备份。
## 1.3 递归下载的应用场景
递归下载在多个场景中非常有用,例如:网站更新时用于备份旧网页、学术研究时收集网页资源、在开发中对前端资源的测试等。使用wget的递归下载功能可以大大提高工作效率,但也需要注意合理的使用频率和深度,以避免对目标服务器造成不必要的负载。
通过本章的介绍,读者将对wget的递归下载功能有一个初步的理解,为后续章节深入分析和实践打下基础。在第二章,我们将分析网站架构,了解网页的基本结构和内容组织方式,为下载实践提供理论支持。
# 2. 网站架构分析
### 2.1 网页的基本结构
网页是构成网站的基础元素,每一个网页都有其特定的结构,通常由HTML、CSS和JavaScript等技术构建而成。了解这些基本结构对于IT专业人员来说是至关重要的。
#### 2.1.1 HTML标签和元素
HTML(HyperText Markup Language)是构建网页的标准标记语言。它由一系列的标签(tag)组成,这些标签被用来定义网页的内容和结构。例如,`<p>` 标签用于定义段落,`<h1>` 到 `<h6>` 标签定义标题的级别。
在HTML中,基本的结构标签如下所示:
```html
<!DOCTYPE html>
<html>
<head>
<title>网页标题</title>
</head>
<body>
<h1>标题1</h1>
<p>这是一个段落。</p>
<img src="image.jpg" alt="示例图片">
</body>
</html>
```
每个标签都有其特定的作用,如 `<img>` 标签用于引入图片,并通过 `alt` 属性为图片提供一个文本替代说明,这在网页中是非常重要的,因为它是网页内容的可访问性的一部分。
#### 2.1.2 CSS和JavaScript的作用
CSS(Cascading Style Sheets)用于控制网页的格式和布局。它描述了HTML元素如何在屏幕、纸张、声音等媒体上呈现。例如,通过CSS,可以设置字体样式、颜色、边距等。
JavaScript则是网页的动态脚本语言,它允许用户与网页进行交互。例如,当用户点击一个按钮时,JavaScript可以处理这个点击事件,并触发一些动作,如弹出一个提示框、加载新的内容或者验证表单数据。
```css
body {
background-color: #f0f0f0;
font-family: Arial, sans-serif;
}
h1 {
color: blue;
}
```
```javascript
document.addEventListener('DOMContentLoaded', function () {
var button = document.getElementById('myButton');
button.addEventListener('click', function() {
alert('按钮被点击了!');
});
});
```
### 2.2 URL解析
URL(Uniform Resource Locator)是网络资源的地址,也是网络上请求资源时需要输入的地址。了解URL的结构是分析和操作网站架构的一个重要步骤。
#### 2.2.1 URL组成部分
一个标准的URL由以下几个部分组成:协议(如http、https)、域名、端口号、路径、查询字符串和锚点。例如:
```
http://www.example.com:80/path/to/resource?query=string#anchor
```
- 协议:定义了访问资源所使用的协议类型,如http或https。
- 域名:标识了服务器的位置。
- 端口号:(可选)数字形式,用于表示特定服务的监听端口,HTTP默认端口是80,HTTPS默认端口是443。
- 路径:标识服务器上资源的路径。
- 查询字符串:以'?'开头,跟随一系列的键值对,用来传递给服务器参数。
- 锚点:以'#'开头,用于定位页面中的某个位置。
#### 2.2.2 协议、域名和路径解析
- **协议**:指出服务器处理请求所使用的方法。最常见的是HTTP和HTTPS。
- **域名**:将IP地址转换为人类可读的名称。例如,`example.com`是一个域名。
- **路径**:指向服务器上的特定资源。例如,`/path/to/resource`指明了资源的路径。
理解这些组成部分,可以帮助IT专业人员更有效地对网站进行故障排查和内容定位。
### 2.3 网站内容的组织方式
网站内容的组织方式对于用户体验和搜索引擎优化(SEO)至关重要。它决定了用户和搜索引擎如何找到和理解网站上的信息。
#### 2.3.1 静态与动态网页
- **静态网页**:直接由HTML文件构成,无需服务器进行处理即可直接向浏览器发送。它们通常用于内容不经常变动的页面,如关于页面或联系方式页面。
- **动态网页**:由服务器根据用户的请求动态生成的页面。它们通常包含数据库交互,能够根据不同的用户输入显示不同的内容。
静态网页与动态网页各有其适用场景,选择正确的类型可以帮助提高网站的性能和可维护性。
#### 2.3.2 网站目录结构和链接结构
- **目录结构**:决定了网站文件的存储和组织方式。良好的目录结构可以帮助内容管理、导航和SEO。
- **链接结构**:包括内部链接和外部链接。内部链接有助于用户在网站内导航,而外部链接则有助于提高网站的SEO排名。
了解网站结构有助于IT专业人员理解和优化网站内容的组织,从而提升网站的用户体验和搜索引擎表现。
本章节提供了网站架构的基础知识,对于深入理解如何使用wget进行递归下载以及如何高效抓取网站内容至关重要。接下来章节将继续深入探讨wget递归下载的具体实践技巧。
# 3. wget递归下载实践技巧
## 3.1 wget的基本用法
### 3.1.1 命令行参数解析
`wget` 是一款广泛使用的命令行网络下载工具,它支持 HTTP、HTTPS 和 FTP 协议。在递归下载时,`wget` 可以通过其命令行参数实现对网站内容的深度爬取,并将整个网站的结构完整地保存到本地。理解并掌握 `wget` 的基本命令行参数,对于实现有效和高效的下载操作至关重要。
`wget` 的基本语法为:
```bash
wget [选项] [URL]
```
核心选项包括:
- `-r` 或 `--recursive`:启动递归下载。
- `-l` 或 `--level=数字`:设置递归下载的深度。
- `-A` 或 `--accept=后缀列表`:指定下载文件的后缀类型。
- `-R` 或 `--reject=后缀列表`:指定不下载的文件后缀类型。
- `-nd` 或 `--no-directories`:不在本地创建远端网站的目录结构。
- `-np` 或 `--no-parent`:不追溯到父目录。
- `-k` 或 `--convert-links`:下载后将链接转换为本地链接。
- `-p` 或 `--page-requisites`:下载所有用于显示页面所需的资源。
### 3.1.2 基本下载和递归下载选项
在使用 `wget` 进行递归下载时,常用的参数组合可以是:
```bash
wget -r -l inf -A html,png,jpg -k -p http://example.com/
```
这条命令的含义是:
- `-r`:启动递归下载。
- `-l inf`:设置无限深度的递归下载,直到所有链接都被访问。
- `-A html,png,jpg`:指定只下载后缀为 `.html`, `.png`, `.jpg` 的文件。
- `-

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Linux 系统中使用 wget 命令下载网页的各种技巧和策略。从提升下载速度的选项到自动化下载任务,再到确保下载过程稳定可靠的断点续传,专栏全面涵盖了 wget 的核心功能。此外,还提供了自定义下载过程、递归下载网站数据、防范恶意内容下载以及记录和分析下载过程的实用指南。通过这些高级技巧,读者可以最大限度地利用 wget 的强大功能,高效可靠地下载网页内容。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【51单片机数字时钟案例分析】:深入理解中断管理与时间更新机制
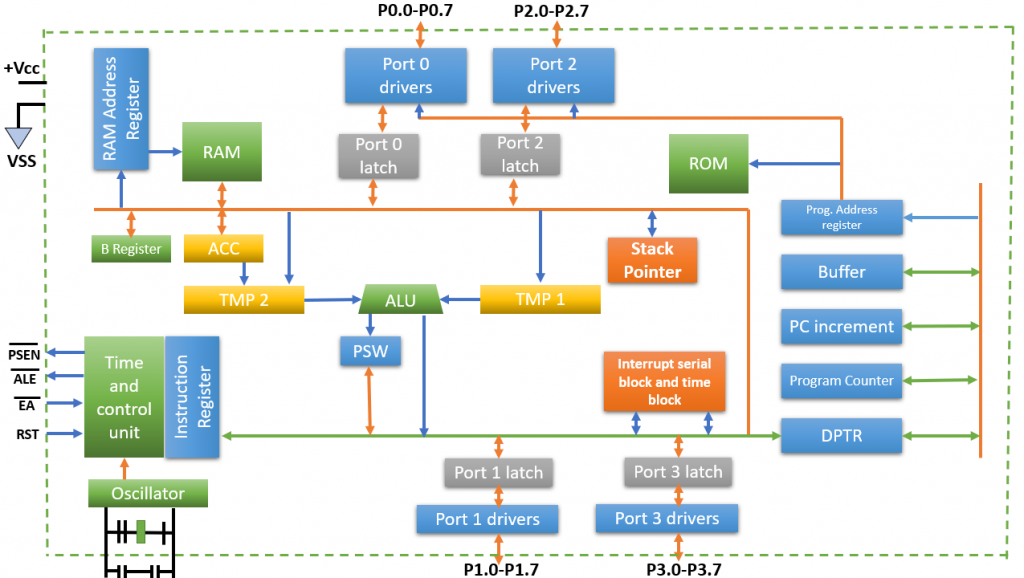
# 摘要
本文详细探讨了基于51单片机的数字时钟设计与实现。首先介绍了数字时钟的基本概念、功能以及51单片机的技术背景和应用领域。接着,深入分析了中断管理机制,包括中断系统原理、51单片机中断系统详解以及中断管理在实际应用中的实践。本文还探讨了时间更新机制的实现,阐述了基础概念、在51单片机下的具体策略以及优化实践。在数字时钟编程与调试章节中,讨论了软件设计、关键功能实现以及调试
【版本升级无忧】:宝元LNC软件平滑升级关键步骤大公开!

# 摘要
宝元LNC软件的平滑升级是确保服务连续性与高效性的关键过程,涉及对升级需求的全面分析、环境与依赖的严格检查,以及升级风险的仔细评估。本文对宝元LNC软件的升级实践进行了系统性概述,并深入探讨了软件升级的理论基础,包括升级策略
【异步处理在微信小程序支付回调中的应用】:C#技术深度剖析

# 摘要
本文首先概述了异步处理与微信小程序支付回调的基本概念,随后深入探讨了C#中异步编程的基础知识,包括其概念、关键技术以及错误处理方法。文章接着详细分析了微信小程序支付回调的机制,阐述了其安全性和数据交互细节,并讨论了异步处理在提升支付系统性能方面的必要性。重点介绍了如何在C#中实现微信支付的异步回调,包括服务构建、性能优化、异常处理和日志记录的最佳实践。最后,通过案例研究,本文分析了构建异步支付回调系统的架构设计、优化策略和未来挑战,为开
内存泄漏不再怕:手把手教你从新手到专家的内存管理技巧

# 摘要
内存泄漏是影响程序性能和稳定性的关键因素,本文旨在深入探讨内存泄漏的原理及影响,并提供检测、诊断和防御策略。首先介绍内存泄漏的基本概念、类型及其对程序性能和稳定性的影响。随后,文章详细探讨了检测内存泄漏的工具和方法,并通过案例展示了诊断过程。在防御策略方面,本文强调编写内存安全的代码,使用智能指针和内存池等技术,以及探讨了优化内存管理策略,包括内存分配和释放的优化以及内存压缩技术的应用。本文不
反激开关电源的挑战与解决方案:RCD吸收电路的重要性
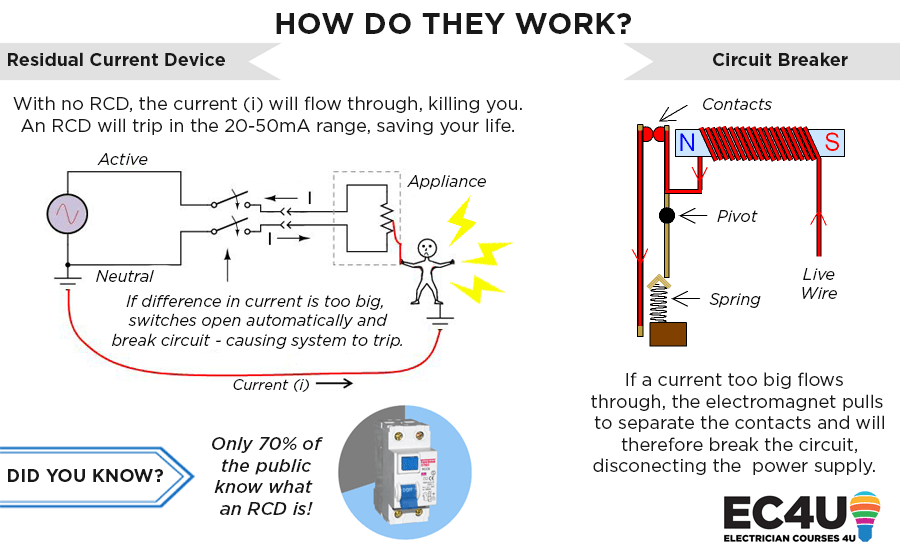
# 摘要
本文系统探讨了反激开关电源的工作原理及RCD吸收电路的重要作用和优势。通过分析RCD吸收电路的理论基础、设计要点和性能测试,深入理解其在电压尖峰抑制、效率优化以及电磁兼容性提升方面的作用。文中还对RCD吸收电路的优化策略和创新设计进行了详细讨论,并通过案例研究展示其在不同应用中的有效性和成效。最后,文章展望了RCD吸收电路在新材料应用
【Android设备标识指南】:掌握IMEI码的正确获取与隐私合规性

# 摘要
IMEI码作为Android设备的唯一标识符,不仅保证了设备的唯一性,还与设备的安全性和隐私保护密切相关。本文首先对IMEI码的概念及其重要性进行了概述,然后详细介绍了获取IMEI码的理论基础和技术原理,包括在不同Android版本下的实践指南和高级处理技巧。文中还讨论了IMEI码的隐私合规性考量和滥用防范策略,并通过案例分析展示了IMEI码在实际应用中的场景。最后,本文探讨了隐私保护技术的发展趋势以及对开发者在合规性
E5071C射频故障诊断大剖析:案例分析与排查流程(故障不再难)
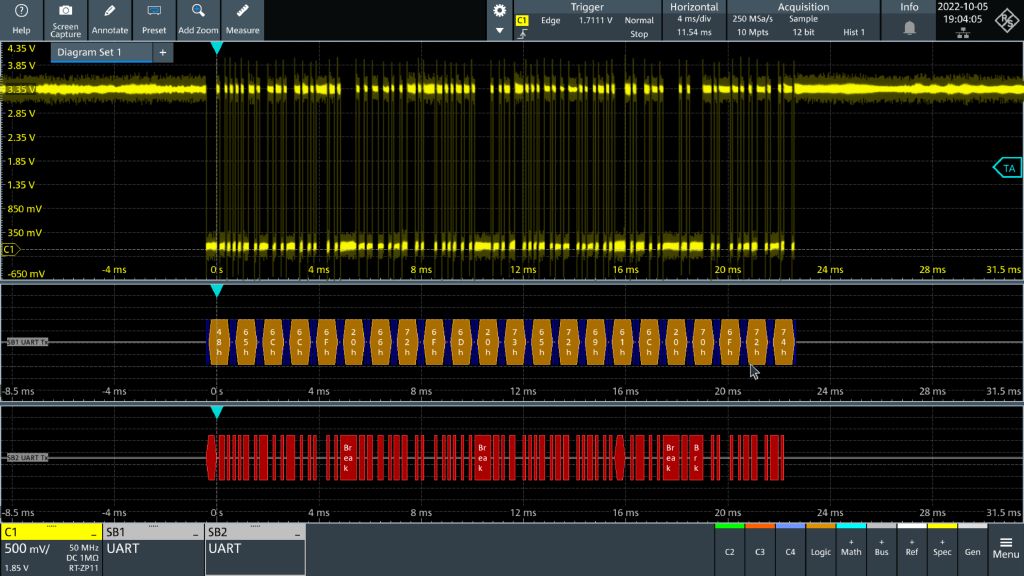
# 摘要
本文对E5071C射频故障诊断进行了全面的概述和深入的分析。首先介绍了射频技术的基础理论和故
【APK网络优化】:减少数据消耗,提升网络效率的专业建议

# 摘要
随着移动应用的普及,APK网络优化已成为提升用户体验的关键。本文综述了APK网络优化的基本概念,探讨了影响网络数据消耗的理论基础,包括数据传输机制、网络请求效率和数据压缩技术。通过实践技巧的讨论,如减少和合并网络请求、服务器端数据优化以及图片资源管理,进一步深入到高级优化策略,如数据同步、差异更新、延迟加载和智能路由选择。最后,通过案例分析展示了优化策略的实际效果,并对5G技
DirectExcel数据校验与清洗:最佳实践快速入门
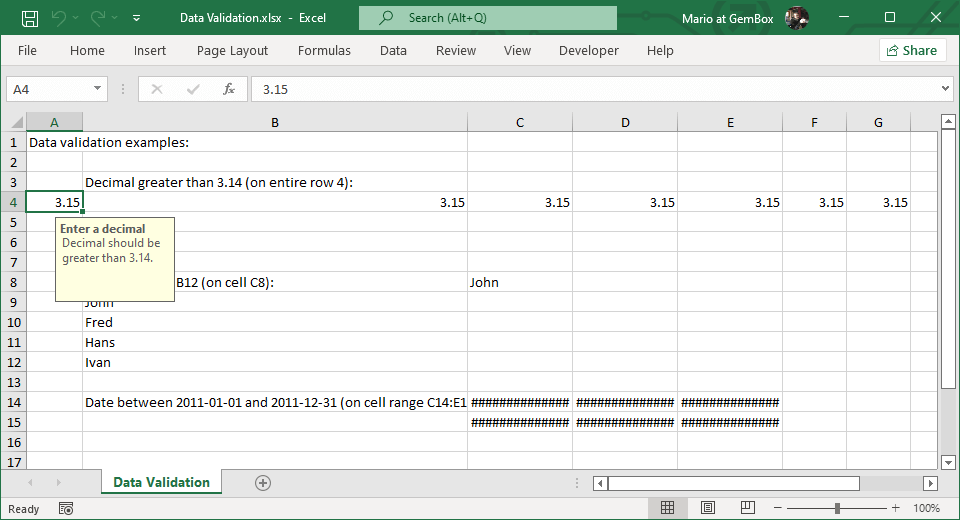
# 摘要
本文旨在介绍DirectExcel在数据校验与清洗中的应用,以及如何高效地进行数据质量管理。文章首先概述了数据校验与清洗的重要性,并分析了其在数据处理中的作用。随后,文章详细阐述了数据校验和清洗的理论基础、核心概念和方法,包括校验规则设计原则、数据校验技术与工具的选择与应用。在实践操作章节中,本文展示了DirectExcel的界面布局、功能模块以及如何创建
【模糊控制规则优化算法】:提升实时性能的关键技术
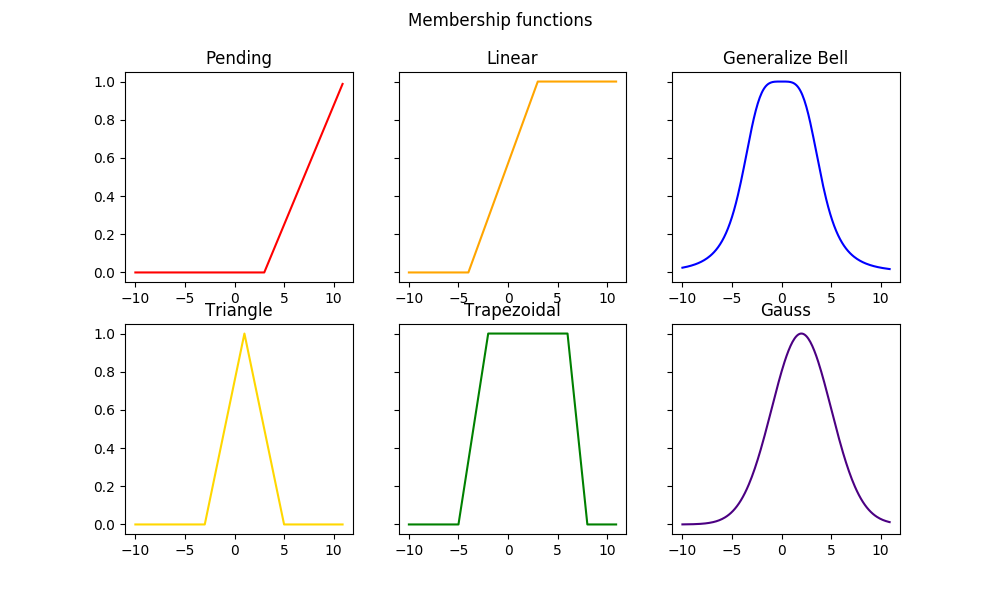
# 摘要
模糊控制规则优化算法是提升控制系统性能的重要研究方向,涵盖了理论基础、性能指标、优化方法、实时性能分析及提升策略和挑战与展望。本文首先对模糊控制及其理论基础进行了概述,随后详细介绍了基于不同算法对模糊控制规则进行优化的技术,包括自动优化方法和实时性能的改进策略。进一步,文章分析了优化对实时性能的影响,并探索了算法面临的挑战与未
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )