初识Gitee代码托管平台:注册与项目创建
发布时间: 2024-02-21 04:47:48 阅读量: 39 订阅数: 38 

06、初识SAS分析之二:制表与画图 sas06c.flv
# 1. 什么是Gitee代码托管平台?
### 1.1 Gitee简介
Gitee(原码云)是一家基于Git的代码托管平台,旨在为开发者提供稳定、高效的代码托管服务。除了代码托管功能外,Gitee还提供了问题跟踪、Wiki、代码贡献分析等功能,是一个全方位的协作开发平台。
### 1.2 Gitee与GitHub的区别
Gitee与GitHub类似,但也有一些区别。其中之一是Gitee在中国大陆地区拥有更快的访问速度,另外Gitee还提供了更多针对中国开发者的本地化服务,使得国内开发者能够更方便地使用。
### 1.3 Gitee的优势
- 中国大陆地区访问速度快
- 提供免费的私有仓库
- 支持企业级应用部署
- 融合了代码托管、协作开发与项目管理功能
通过这些内容的介绍,读者可以对Gitee代码托管平台有一个初步的认识,接下来我们将深入探讨如何在Gitee上注册账号并进行项目管理和代码托管。
# 2. 注册Gitee账号
在使用Gitee之前,您需要先注册一个Gitee账号。下面将详细介绍注册Gitee账号的步骤以及安全设置建议。
### 2.1 访问Gitee官网
首先,打开您的浏览器,访问[Gitee官网](https://gitee.com/)。
### 2.2 注册步骤详解
1. 点击网页右上角的 "注册" 按钮。
2. 在弹出的注册页面中,输入您的邮箱地址或手机号码,设置登录密码,进行人机验证。
3. 点击 "立即注册" 完成基本注册。
4. 根据页面提示,完善个人信息,包括昵称、头像等。
### 2.3 安全设置建议
- 使用强密码并定期更换。
- 启用双因素认证(2FA)提升账号安全性。
- 不要泄露个人信息,警惕钓鱼网站。
注册完毕后,您就可以登录您的Gitee账号开始使用这个功能强大的代码托管平台了。
# 3. 创建新的项目
在Gitee上创建新的项目非常简单,只需几个简单的步骤即可完成。
1. **登录Gitee账号**
首先,在浏览器中访问Gitee的官方网站(https://gitee.com/),然后使用您的账号信息登录。
2. **点击新建项目**
登录成功后,您会看到页面右上角有一个“加号”图标,点击它会弹出一个下拉菜单,选择“新建仓库”选项。
3. **填写项目信息**
在新建项目的页面中,您需要填写项目的基本信息,包括项目名称、描述、可见性(公开或私有)、初始化仓库等。
4. **选择项目权限设置**
在填写完项目信息后,您可以选择是否设置项目的访问权限。您可以选择公开项目供所有人查看,也可以将项目设置为私有仅限特定成员访问。
通过以上步骤,您就成功创建了一个新的项目,并可以开始在Gitee上管理您的代码了。
# 4. 项目管理与设置
在Gitee上创建新项目后,您将需要对项目进行管理和设置。这包括项目概览、描述、成员管理、分支管理以及合并请求等功能。
#### 4.1 项目主页概览
项目主页是您项目的信息总览页面。您可以在此页面查看项目的基本信息,如项目名称、描述、许可证、星标数、关注者数等。同时,您还可以快速查看项目的代码、问题、合并请求等。
#### 4.2 设置项目描述与标签
在项目设置中,您可以编辑项目描述,介绍项目的背景、功能、特点等。此外,您还可以为项目添加标签,帮助其他用户更好地了解和搜索您的项目。
```markdown
# 项目描述示例
这是一个用于演示如何设置项目描述和标签的示例项目。
```
#### 4.3 添加项目成员
在多人协作开发中,您可能需要邀请其他成员加入您的项目。在项目设置的成员管理页面,您可以通过邮箱或用户名邀请他人加入项目,并设置其权限级别。
```markdown
# 示例代码:邀请成员加入项目
git clone https://gitee.com/your-username/your-project.git
git remote add colleague https://gitee.com/colleague-username/your-project.git
git push colleague master
```
#### 4.4 分支管理与合并请求
分支管理是代码管理中的重要环节。您可以在项目中创建新的分支,开发新功能或修复bug,然后通过合并请求将更改合并到主分支中。
```markdown
# 示例代码:创建新分支
git checkout -b new-feature
# 开发新功能,并提交更改
git add .
git commit -m "Add new feature"
# 将新功能合并到主分支
git checkout master
git merge new-feature
git push origin master
```
通过以上步骤,您可以轻松管理和设置您在Gitee上创建的项目。希望这些内容能帮助您更好地利用Gitee进行项目管理与协作开发。
# 5. 代码上传与版本控制
在使用Gitee进行代码托管时,代码上传与版本控制是非常重要的部分。接下来,我们将详细介绍如何在Gitee上进行代码上传和版本控制。
#### 5.1 上传代码文件
在项目创建完成后,我们需要将本地的代码上传到Gitee上。首先,我们需要在本地安装Git,并在项目根目录打开命令行窗口。然后按照以下步骤操作:
1. 初始化本地仓库:在命令行中使用 `git init` 命令初始化本地仓库。
2. 添加文件到暂存区:使用 `git add <file>` 命令将需要上传的文件添加到暂存区。
3. 提交文件到版本库:通过 `git commit -m "提交说明"` 命令将暂存区的文件提交到本地版本库。
4. 关联远程仓库:执行 `git remote add origin <远程仓库地址>` 命令,将本地仓库与Gitee上的远程仓库进行关联。
5. 推送代码:最后使用 `git push -u origin master` 命令将本地代码推送到Gitee上。
这样,我们就成功地将本地的代码上传到了Gitee上。接下来,我们将学习如何使用Git进行版本控制。
#### 5.2 使用Git进行版本控制
在日常开发中,我们经常需要对代码进行版本控制,以便随时回滚到历史版本或者进行代码比对等操作。Git是一款非常强大的版本控制工具,也是Gitee所使用的版本控制系统。
通过以下几个常用命令,我们可以进行基本的版本控制操作:
- `git pull`:从远程仓库拉取最新代码到本地。
- `git branch`:查看分支信息,包括本地分支和远程分支。
- `git checkout -b <branch_name>`:创建并切换到新的分支。
- `git merge <branch_name>`:将指定分支的代码合并到当前分支。
- `git log`:查看提交历史记录。
通过以上命令,我们可以轻松地进行版本控制操作,并且保证代码的稳定性和可追溯性。
#### 5.3 查看代码提交记录
在Gitee上,我们可以方便地查看代码的提交记录。在项目页面中,选择“代码”选项卡,即可看到代码文件的修改记录以及每次提交的作者、提交时间等信息。这为团队协作开发和代码审查提供了便利。
以上就是在Gitee上进行代码上传和版本控制的基本操作,通过这些操作,我们可以高效地管理和维护项目代码。
# 6. 共享与合作开发
在软件开发过程中, 共享与合作至关重要。Gitee作为一个优秀的代码托管平台, 提供了许多功能来促进团队合作开发。本章将介绍如何在Gitee上进行共享与合作开发。
### 6.1 设置Webhook实现自动化集成
Webhook是一种用户定义的HTTP回调,可触发事件。通过设置Webhook,可以实现代码提交后触发自动化构建、部署等操作。
```python
# 以Python为例,设置Webhook实现自动化集成
import requests
url = "https://gitee.com/webhook"
data = {
"repository": "my_repo",
"action": "push",
"branch": "main"
}
response = requests.post(url, json=data)
if response.status_code == 200:
print("Webhook set successfully!")
else:
print("Failed to set Webhook.")
```
**代码总结:** 以上代码演示了如何使用Python设置Webhook来实现自动化集成。当触发条件满足时,Webhook将向指定的URL发送一个JSON数据,触发相应的操作。
### 6.2 讨论问题与合并请求评论
在项目开发过程中,经常会遇到问题或需要进行代码合并。Gitee 提供了问题追踪工具和合并请求功能,方便团队成员之间的沟通和代码审核。
```java
// 使用Java示例,讨论问题与合并请求评论
public class Issue {
private String title;
private String description;
public Issue(String title, String description) {
this.title = title;
this.description = description;
}
// 添加评论
public void addComment(String comment) {
System.out.println("Comment added: " + comment);
}
public static void main(String[] args) {
Issue myIssue = new Issue("Bug fix", "Fix the login issue");
myIssue.addComment("Reviewed and approved!");
}
}
```
**代码总结:** 以上Java示例展示了如何在Gitee上讨论问题和进行合并请求评论。通过添加评论,团队成员可以就问题进行讨论并审核合并请求。
### 6.3 开源项目与协作开发
开源项目是许多开发者喜爱的形式,通过开源项目可以互相学习、贡献代码和共同推进项目进展。Gitee提供了丰富的开源项目支持和协作开发功能,让开源变得更加简单。
```javascript
// 使用JavaScript示例,开源项目与协作开发
const welcomeMessage = "Welcome to contribute to our open source project!";
function contributeToProject() {
console.log(welcomeMessage);
}
contributeToProject();
```
**代码总结:** 以上JavaScript示例展示了开源项目与协作开发的简单示例。每个人都可以贡献自己的代码与想法,共同推动项目的发展。
通过以上内容,可以看到在Gitee上共享与合作开发是多么简单而且有效。团队成员可以通过各种功能快速高效地进行沟通、合作,提高开发效率,推动项目进展。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探究Gitee代码托管平台的各种功能与应用,从初识到高级应用,一步步引领读者掌握Gitee的使用技巧。文章内容包括注册与项目创建、代码仓库的创建与管理、团队协作开发、Pull Requests功能与代码审查流程、CI_CD功能与持续集成部署、代码审核功能与规范管理、插件市场应用、Gitee Pages静态网站部署实践、API二次开发与集成、社区交流与分享平台,以及DevOps实践与最佳实践分享。无论初学者还是有经验者都能在本专栏中找到所需的资讯与指导,加深对Gitee平台的了解,提升开发效率,促进团队协作与项目成功。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
TSPL语言效能革命:全面优化代码效率与性能的秘诀

# 摘要
TSPL语言是一种专门设计用于解决特定类型问题的编程语言,它具有独特的核心语法元素和模块化编程能力。本文第一章介绍了TSPL语言的基本概念和用途,第二章深入探讨了其核心语法元素,包括数据类型、操作符、控制结构和函数定义。性能优化是TSPL语言实践中的重点,第三章通过代码分析、算法选择、内存管理和效率提升等技术,
【Midas+GTS NX起步指南】:3步骤构建首个模型
# 摘要
Midas+GTS NX是一款先进的土木工程模拟软件,集成了丰富的建模、分析和结果处理功能。本文首先对Midas+GTS NX软件的基本操作进行了概述,包括软件界面布局、工程设置、模型范围确定以及材料属性定义等。接着,详细介绍了模型建立的流程,包括创建几何模型、网格划分和边界条件施加等步骤。在模型求解与结果分析方面,本文讨论了求解参数
KEPServerEX6数据日志记录进阶教程:中文版深度解读
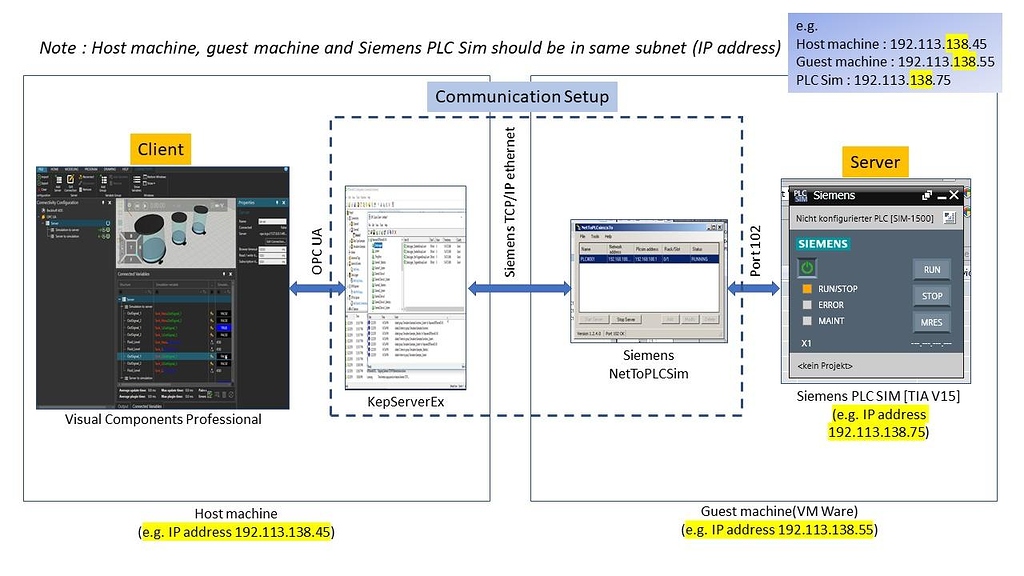
# 摘要
本论文全面介绍了KEPServerEX6数据日志记录的基础知识、配置管理、深入实践应用、与外部系统的集成方法、性能优化与安全保护措施以及未来发展趋势和挑战。首先,阐述了KEPServerEX6的基本配置和日志记录设置,接着深入探讨了数据过滤、事件触发和日志分析在故障排查中的具体应用。文章进一步分析了KEPS
【头盔检测误检与漏检解决方案】:专家分析与优化秘籍

# 摘要
本文对头盔检测系统进行了全面的概述和挑战分析,探讨了深度学习与计算机视觉技术在头盔检测中的应用,并详细介绍了相关理论基础,包括卷积神经网络(CNN)和目标检测算法。文章还讨论了头盔检测系统的关键技术指标,如精确度、召回率和模型泛化能力,以及常见误检类型的原因和应对措施。此外,本文分享
CATIA断面图高级教程:打造完美截面的10个步骤
# 摘要
本文系统地介绍了CATIA软件中断面图的设计和应用,从基础知识到进阶技巧,再到高级应用实例和理论基础。首先阐述了断面图的基本概念、创建过程及其重要性,然后深入探讨了优化断面图精度、处理复杂模型、与装配体交互等进阶技能。通过案例研究,本文展示了如何在零件设计和工程项目中运用断
伦茨变频器:从安装到高效运行
# 摘要
伦茨变频器是一种广泛应用于工业控制领域的电力调节装置,它能有效提高电机运行的灵活性和效率。本文从概述与安装基础开始,详细介绍了伦茨变频器的操作与配置,包括基本操作、参数设置及网络功能配置等。同时,本论文也探讨了伦茨变频器的维护与故障排除方法,重点在于日常维护实践、故障诊断处理以及性能优化建议。此外,还分析了伦茨变频器在节能、自动化系统应用以及特殊环境下的应用案例。最后,论文展望了伦茨变频器未来的发展趋势,包括技术创新、产品升级以及在新兴行业中的应用前景。
# 关键字
伦茨变频器;操作配置;维护故障排除;性能优化;节能应用;自动化系统集成
参考资源链接:[Lenze 8400 Hi
【编译器构建必备】:精通C语言词法分析器的10大关键步骤
# 摘要
本文对词法分析器的原理、设计、实现及其优化与扩展进行了系统性的探讨。首先概述了词法分析器的基本概念,然后详细解析了C语言中的词法元素,包括标识符、关键字、常量、字符串字面量、操作符和分隔符,以及注释和宏的处理方式。接着,文章深入讨论了词法分析器的设计架构,包括状态机理论基础和有限自动机的应用,以及关键代码的实现细节。此外,本文还涉及
【Maxwell仿真必备秘籍】:一文看透瞬态场分析的精髓

# 摘要
Maxwell仿真是电磁学领域的重要工具,用于模拟和分析电磁场的瞬态行为。本文从基础概念讲起,介绍了瞬态场分析的理论基础,包括物理原理和数学模型,并详细探讨了Maxwell软件中瞬态场求解器的类型与特点,网格划分对求解精度的影响。实践中,建立仿真模型、设置分析参数及解读结果验证是关键步骤,本文为这些技巧提供了深入的指导。此外,文章还探讨了瞬态场分析在工程中的具体应用,如
Qt数据库编程:一步到位连接与操作数据库
# 摘要
本论文为读者提供了一套全面的Qt数据库编程指南,涵盖了从基础入门到高级技巧,再到实际应用案例的完整知识体系。首先介绍了Qt数据库编程的基础知识,然后深入分析了数据库连接机制,包括驱动使用、连接字符串构建、QDatabase类的应用,以及异常处理。在数据操作与管理章节,重点讲解了SQL语句的应用、模型-视图结构的数据展示以及数据的增删改查操作。高级数据库编程技巧章节讨论了事务处理、并
【ZXA10网络性能优化】:容量规划的10大黄金法则
# 摘要
随着网络技术的快速发展,ZXA10网络性能优化成为了提升用户体验与系统效率的关键。本文从容量规划的理论基础出发,详细探讨了容量规划的重要性、目标、网络流量分析及模型构建。进而,结合ZXA10的实际情况,对网络性能优化策略进行了深入分析,包括QoS配置优化、缓冲区与队列管理以及网络设备与软件更新。为了保障网络稳定运行,本文还介绍了性能监控与故障排除的有效方法,并通过案例研究分享了成功与失败的经验教训。本文旨在为网络性能优化提供一套全面的解决方案,对相关从业人员和技术发展具有重要的指导意义。
# 关键字
网络性能优化;容量规划;流量分析;QoS配置;缓冲区管理;故障排除
参考资源链接
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )