detectron2中的常用模型架构解析与比较
发布时间: 2024-04-04 07:42:35 阅读量: 175 订阅数: 34 

detectron2官方代码
# 1. 介绍detectron2
## 1.1 detectron2概述
Detectron2是Facebook AI Research (FAIR)开发的下一代目标检测和分割软件系统,建立在PyTorch框架上。它是Detectron的升级版,提供了更高的灵活性和可扩展性,具有更好的性能和效率。
## 1.2 detectron2的特性与优势
- **模块化设计**:Detectron2采用模块化设计,使用户可以灵活地组合不同的组件来构建自定义的计算机视觉任务。
- **高性能**:结合了PyTorch的强大特性,Detectron2在目标检测和分割任务中取得了令人瞩目的性能。
- **易用性**:提供了丰富的API和示例代码,方便用户快速上手和定制化开发。
- **支持多种模型架构**:Detectron2支持多种常用的模型架构,例如Faster R-CNN、Mask R-CNN、RetinaNet等。
- **社区活跃**:作为开源项目,Detectron2拥有庞大的开发者社区,保证了持续的更新和支持。
## 1.3 detectron2在计算机视觉领域的应用案例
Detectron2在计算机视觉领域广泛应用,包括但不限于:
- 目标检测
- 实例分割
- 人体姿态估计
- 图像分割
- 图像分类
- 物体跟踪等。
这些应用案例充分展示了Detectron2在各种视觉任务上的强大表现和广泛适用性。
# 2. 常用模型架构概览
在这一章中,我们将介绍detectron2中常用的模型架构,包括Faster R-CNN、Mask R-CNN、RetinaNet、Cascade R-CNN、DensePose等,让我们一起来深入了解它们的原理和特点。
# 3. 模型架构对比分析
在本章中,我们将对detectron2中常用的模型架构进行对比分析,包括性能比较、训练需求以及部署考量等方面。
#### 3.1 性能对比
首先,让我们比较一下Faster R-CNN、Mask R-CNN、RetinaNet、Cascade R-CNN和DensePose这几种常用的模型架构在精度和速度上的表现。我们可以通过在相同数据集上训练并测试这些模型来进行评估。
```python
# 代码示例:模型性能对比
import detectron2.model_zoo as model_zoo
# 加载Faster R-CNN模型
faster_rcnn_model = model_zoo.get('COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml')
# 加载Mask R-CNN模型
mask_rcnn_model = model_zoo.get('COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml')
# 加载RetinaNet模型
retinanet_model = model_zoo.get('COCO-Detection/retinanet_R_50_FPN_3x.yaml')
# 加载Cascade R-CNN模型
cascade_rcnn_model = model_zoo.get('COCO-Detection/cascade_mask_rcnn_R_50_FPN_3x.yaml')
# 加载DensePose模型
densepose_model = model_zoo.get('densepose_rcnn_R_50_FPN_s1x.yaml')
# 训练和测试模型...
```
通过比较这些模型在准确率和推理速度上的表现,我们可以选择最适合特定场景的模型进行应用。
#### 3.2 训练需求
除了性能表现,训练模型所需的时间、数据量等方面也是很重要的考量因素。不同的模型对训练数据的要求、训练时间的长短会有所不同。
```python
# 代码示例:模型训练需求对比
import time
# 训练Faster R-CNN模型并记录训练时间
start_time = time.time()
# 训练...
end_time = time.time()
training_time_faster_rcnn = end_time - start_time
# 训练Mask R-CNN模型并记录训练时间
start_time = time.time()
# 训练...
end_time = time.time()
training_time_mask_rcnn = end_time - start_time
# 训练RetinaNet模型并记录训练时间
start_time = time.time()
# 训练...
end_time = time.time()
training_time_retinanet = end_time - start_time
# 训练Cascade R-CNN模型并记录训练时间
start_time = time.time()
# 训练...
end_time = time.time()
training_time_cascade_rcnn = end_time - start_time
# 训练DensePose模型并记录训练时间
start_time = time.time()
# 训练...
end_time = time.time()
training_time_densepose = end_time - start_time
# 对比模型训练时间...
```
通过比较各模型的训练时间、数据需求等指标,可以帮助我们选择合适的模型进行训练。
#### 3.3 部署考量
最后,在部署模型时,模型的复杂度、适用场景等因素也需要考虑进去。不同的模型在部署时可能会有不同的难易程度,适用于不同的部署场景。
通过以上对比分析,我们可以更全面地评估各模型在不同方面的表现,从而选择最适合实际需求的模型进行应用。
# 4. 模型架构深入解析
在这一章中,我们将深入解析detectron2中常用的模型架构,包括Faster R-CNN、Mask R-CNN、RetinaNet、Cascade R-CNN以及DensePose。通过对每种模型架构的详细分析,了解其原理、特点以及适用场景,有助于我们更好地选择和优化模型以满足具体项目需求。
#### 4.1 Faster R-CNN详解
Faster R-CNN是一种高效的目标检测框架,通过两阶段目标检测模型实现目标检测和定位。其主要组成部分包括RPN(Region Proposal Network)和Fast R-CNN模块。RPN用于生成候选区域,Fast R-CNN用于对这些候选区域进行分类和回归。其核心思想是引入候选区域提取网络,从而提高检测速度。
以下是一个简单的Faster R-CNN示例代码:
```python
# 导入必要的库
from detectron2.engine import DefaultPredictor
from detectron2.config import get_cfg
from detectron2 import model_zoo
# 加载配置文件
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file("COCO-Detection/faster_rcnn_R_101_FPN_3x.yaml"))
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.5
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-Detection/faster_rcnn_R_101_FPN_3x.yaml")
# 创建预测器
predictor = DefaultPredictor(cfg)
# 读取测试图片
im = cv2.imread("test.jpg")
# 进行推理
outputs = predictor(im)
# 处理输出结果
# ...
```
**代码解释:**
- 首先,我们导入所需的库。
- 然后,加载Faster R-CNN的配置文件并设置阈值和权重。
- 创建预测器,并读取测试图片。
- 最后,进行推理过程并处理输出结果。
这段代码展示了如何使用Faster R-CNN进行目标检测,通过加载配置文件和权重,创建预测器并进行推理过程,最终得到检测结果。
#### 4.2 Mask R-CNN详解
Mask R-CNN在Faster R-CNN的基础上增加了实例分割的功能,可以同时实现目标检测和语义分割。其关键在于引入了分割头(Mask Head),用于预测每个实例的像素级掩模。Mask R-CNN在各种图像分割任务中表现出色,尤其适用于需要准确的实例分割结果的场景。
以下是一个简单的Mask R-CNN示例代码:
```python
# 导入必要的库
from detectron2.engine import DefaultPredictor
from detectron2.config import get_cfg
from detectron2 import model_zoo
# 加载配置文件
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml"))
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.5
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml")
# 创建预测器
predictor = DefaultPredictor(cfg)
# 读取测试图片
im = cv2.imread("test.jpg")
# 进行推理
outputs = predictor(im)
# 处理输出结果
# ...
```
**代码解释:**
- 与Faster R-CNN类似,首先导入必要的库。
- 加载Mask R-CNN的配置文件和权重。
- 创建预测器,读取测试图片,并进行推理过程。
- 最后,处理输出结果,得到实例分割的掩模信息。
通过以上代码,你可以了解如何使用Mask R-CNN进行实例分割任务,其中关键在于加载配置文件、创建预测器,并处理输出结果,以获得准确的实例分割结果。
在接下来的内容中,我们将继续深入探讨RetinaNet、Cascade R-CNN和DensePose等模型架构的原理和应用。
# 5. 模型调优与实践指南
在使用detectron2进行目标检测任务时,为了使模型达到更好的性能,通常需要进行模型调优和实践指南。下面将分享一些模型调参技巧、数据预处理与增强方法、模型优化策略以及实战经验与注意事项。
#### 5.1 模型调参技巧分享
在调优detectron2模型时,常用的调参技巧包括:
1. 学习率调整:通过学习率衰减、学习率预热等方式优化训练过程。
2. 正则化项:添加正则化项(如L1、L2正则化)来缓解过拟合问题。
3. 批量大小调整:调整训练时的批量大小,可以影响模型训练效果。
#### 5.2 数据预处理与增强方法讨论
数据预处理和增强在目标检测任务中起着至关重要的作用,常用的方法包括:
1. 图像缩放:将原始图像缩放到固定大小以适配模型输入。
2. 随机裁剪:对图像进行随机裁剪,增加模型的鲁棒性。
3. 色彩扭曲:利用颜色空间变换等方法进行数据增强,增加数据多样性。
#### 5.3 模型优化策略介绍
为了提升模型性能,可以采用以下优化策略:
1. 损失函数设计:根据具体任务设计合适的损失函数,如交叉熵损失、IoU损失等。
2. 模型融合:结合多个模型的预测结果进行融合,提升检测性能。
3. 预训练模型:使用在大规模数据集上预训练的模型,可以加快收敛速度并提升性能。
#### 5.4 实战经验分享与注意事项
在实际应用detectron2时,需要注意以下事项:
1. 数据质量:确保训练数据质量高,避免出现标注错误等问题。
2. 硬件选择:根据模型复杂度和数据规模选择合适的硬件资源,如GPU加速训练。
3. 模型解释性:定期对模型进行解释性分析,确保模型输出符合预期。
综上所述,通过合理的模型调优和实践指南,可以提升detectron2在目标检测任务中的性能和效果。
# 6. 未来发展与展望
在技术不断演进的今天,detectron2作为一个领先的计算机视觉框架,其未来发展仍将充满潜力。以下是对detectron2未来发展的一些可能方向和展望:
1. **模型性能进一步提升**:
- 随着硬件计算能力的提升和算法的不断优化,未来detectron2的模型在精度和速度上会有更多的提升空间。可以通过模型结构的改进、损失函数的优化等方式来提高性能。
2. **支持新的模型架构**:
- 随着新型神经网络架构的涌现,未来detectron2可能会支持更多的新型模型架构,如Transformers等,从而不断扩大框架的适用范围。
3. **多模态融合**:
- 随着多模态数据应用的增多,detectron2可能会加强对多模态数据的处理能力,使其可以更好地处理文本、图像、视频等多种数据源的融合。
4. **端到端的解决方案**:
- 未来detectron2可能会向着提供更完整的端到端解决方案发展,包括数据处理、模型训练、部署等环节的完整支持,为用户提供更便捷的使用体验。
5. **自动化调参与模型优化**:
- 针对用户调参和模型优化过程中的繁琐性,未来detectron2可以引入自动化调参工具或优化算法,帮助用户更快地得到理想的模型效果。
6. **与行业应用的深度融合**:
- 随着计算机视觉技术在各个行业的应用不断深化,detectron2未来可能会加强与行业的合作,推出针对不同行业需求的定制化解决方案,进一步拓展其应用范围。
7. **社区共建与开放合作**:
- detectron2作为一个开源项目,未来会倡导更多的开发者参与到项目的共建中,形成更加活跃的社区,推动框架的不断发展和完善。
综上所述,detectron2作为一款领先的计算机视觉框架,未来发展的道路上充满着机遇和挑战。随着技术的不断进步和创新,我们有理由相信,detectron2将在未来的发展中继续发挥重要的作用,为计算机视觉领域带来更多惊喜与突破。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏介绍了 Detectron2,一个用于物体检测和实例分割的领先深度学习框架。从入门介绍到高级概念,专栏深入探讨了 Detectron2 的方方面面。
读者将了解 Detectron2 的数据预处理流程、模型架构、自定义数据集构建、物体检测流程、目标实例分割指南、评估与优化策略、主干网架构、损失函数、遮罩头架构、图像金字塔、ROIAlign 和 ROIPool 技术。
此外,专栏还涵盖了训练速度优化、多任务学习、模型蒸馏、CascadeRCNN 原理、关键点头技术、模型微调最佳实践、自监督学习和预训练模型,以及学习率调度策略。通过深入的研究和详细的解释,该专栏为读者提供了全面的 Detectron2 指南,帮助他们掌握这个强大的框架。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【推荐系统架构设计】:从保险行业案例中提炼架构设计实践

# 摘要
推荐系统作为保险行业满足个性化需求的关键技术,近年来得到了快速发展。本文首先概述了推荐系统在保险领域的应用背景和需求。随后,本文探讨了推荐系统的基本理论和评价指标,包括协同过滤、基于内容的推荐技术,以及推荐系统的架构设计、算法集成和技术选型。文中还提供了保险行业的推荐系统实践案例,并分析了数据安全、隐私保护的挑战与策略。最后,本文讨论了推荐系统在伦理与社会责任方面的考量,关注其可能带来的偏见
KST_WorkVisual_40_zh高级应用:【路径规划与优化】提升机器人性能的秘诀
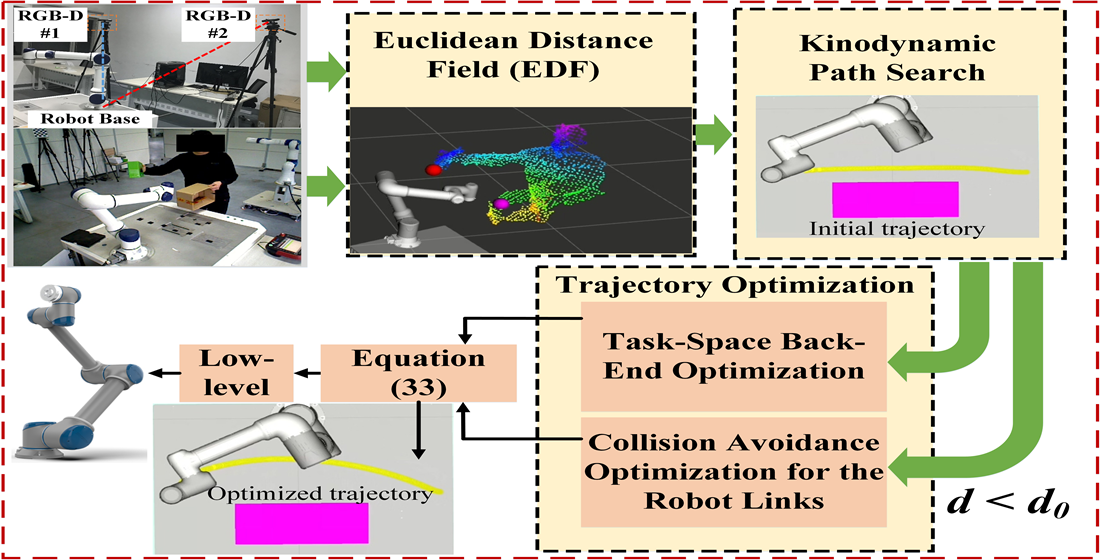
# 摘要
本文针对KST_WorkVisual_40_zh路径规划及优化进行深入探讨。首先,概述了路径规划的基本概念、重要性和算法分类,为理解路径规划提供理论基础。接着,通过KST_WorkVisual_40_zh系统进行路径生成、平滑处理以及调整与优化的实践分析,突显实际应
一步到位:PyTorch GPU支持安装实战,快速充分利用硬件资源(GPU加速安装指南)
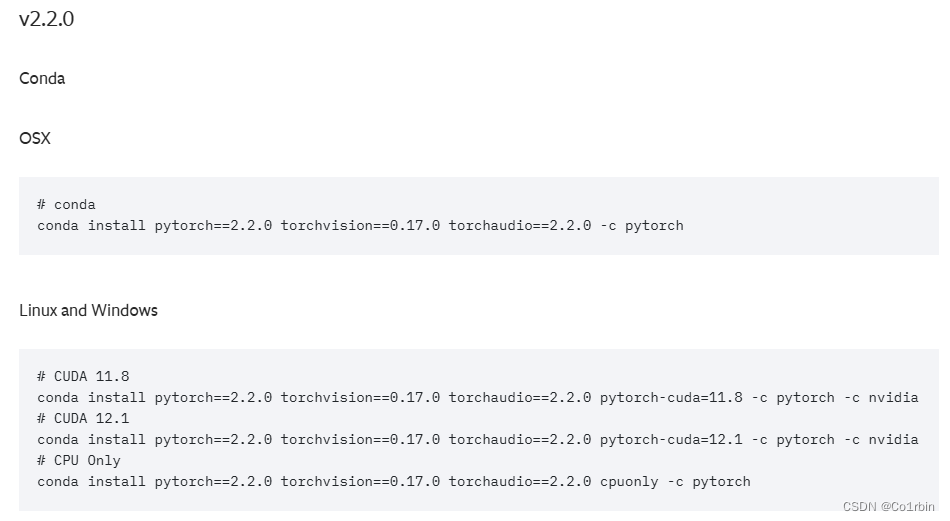
# 摘要
PyTorch作为一个流行的深度学习框架,其对GPU的支持极大地提升了模型训练和数据处理的速度。本文首先探讨了PyTorch GPU支持的背景和重要性,随后详细介绍了基础安装流程,包括环境准备、安装步骤以及GPU支持的测试与验证。文章进一步深入到PyTorch GPU加速的高级配置,阐述了针对不同GPU架构的优化、内存管理和多GPU环境配置。通
Overleaf图表美化术:图形和表格高级操作的专家指南
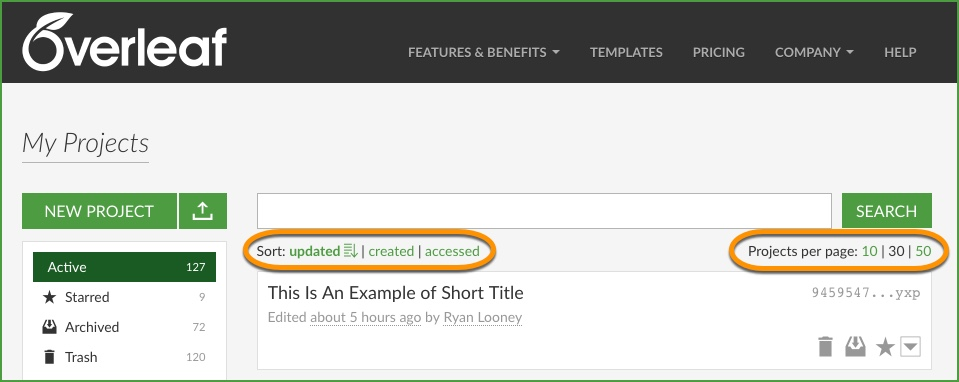
# 摘要
本文全面介绍了Overleaf平台中图表和表格的美化与高级操作技术。章节一概述了Overleaf图表美化的基本概念,随后各章节深入探讨了图形和表格的高级操作技巧,包括图形绘制、坐标变换、交互式元素和动画的实现,以及表格的构建、样式定制和数据处理。第四章通过综合应用示例,展示了如何将高级图表类型与数据可视化最佳实践相结合,处理复杂数据集,并与文档风格相融合。最后,文章探讨了利用外部工具、版本控制和团队协作来提升Overleaf图表设计的效
RDA5876 射频信号增强秘诀:提高无线性能的工程实践
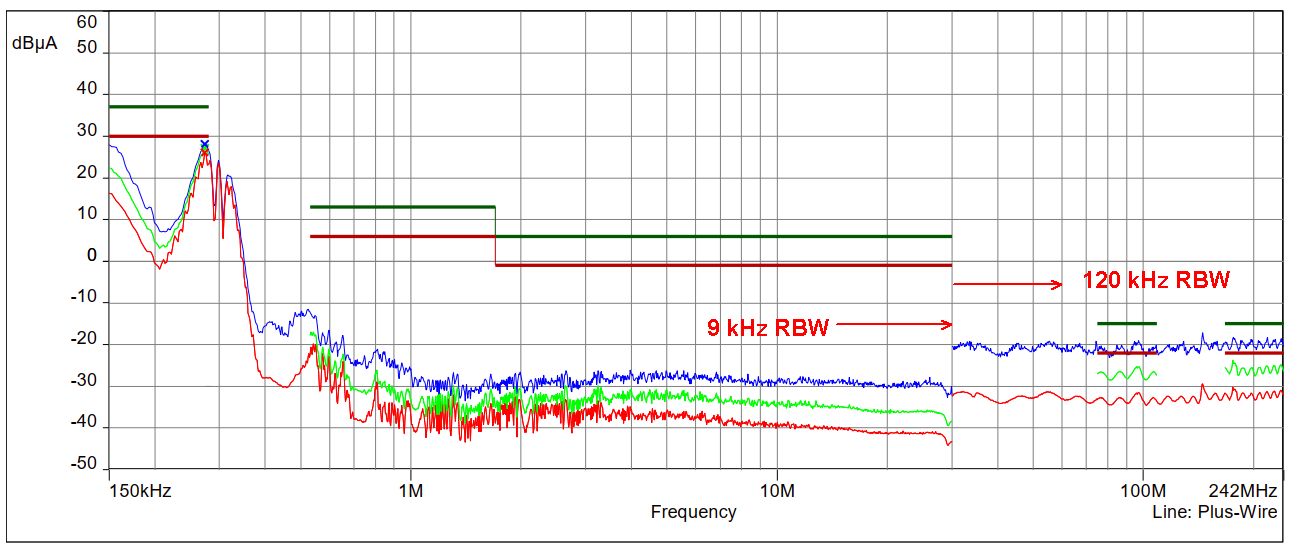
# 摘要
本文系统地介绍了RDA5876射频信号增强技术的理论与实践应用。首先,概述了射频信号的基础知识和信号增强的理论基础,包括射频信号的传播原理、信号调制解调技术、噪声分析以及射频放大器和天线的设计。接着,深入分析了RDA5876芯片的功能架构和性能参数,探讨了软件和硬件层面上的信号处理与增强方法。文章进一步通过实际应用案例,展示了RDA5876在无线通信系统优化和物联网设备中的应用效果。最后,文章展望
AVR微控制器编程进阶指南:精通avrdude 6.3手册,从新手到专家

# 摘要
本文全面介绍了AVR微控制器的基础知识、编程环境搭建、以及使用avrdude工具进行编程和固件更新的详细流程。文章首先提供了对AVR微控制器的概述,然后详述了如何搭建和
微信群聊自动化秘籍:AutoJs脚本开发与性能优化指南

# 摘要
微信群聊自动化技术近年来随着移动互联网的发展而兴起,本文首先概述了AutoJs及其在微信群聊自动化中的应用。接着,介绍了AutoJs脚本的基础知识,包括环境搭建、语言基础和核心组件的操作方法。本文深入探讨了通过AutoJs实现微信群消息监控、管理自动化以及用户体验增强的实战演练。针对脚本性能优化,本文提出了调试技巧、性
煤矿开采规划:地质保障技术如何发挥指导作用
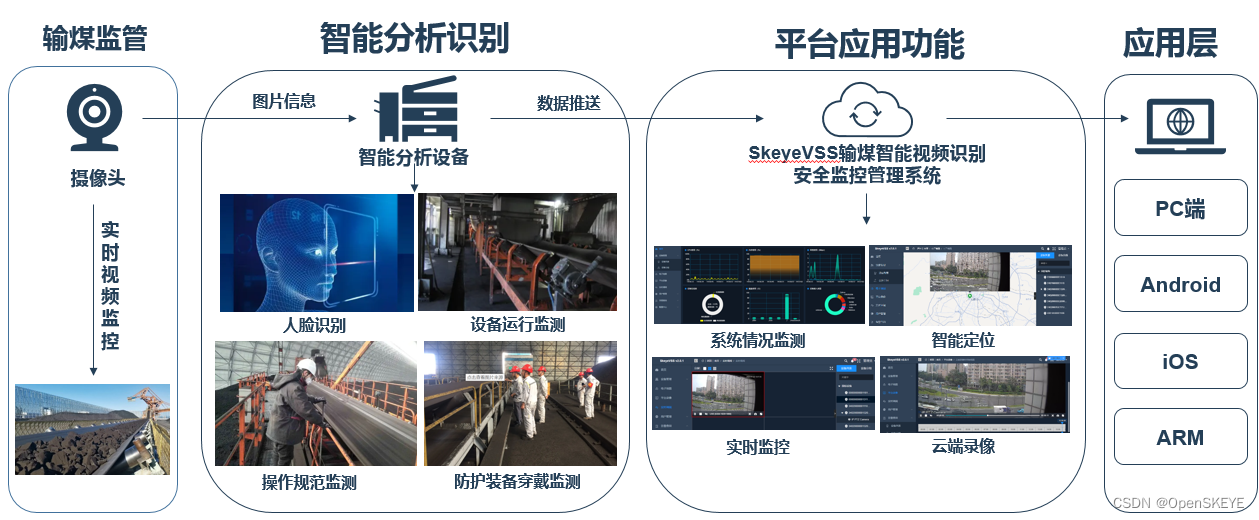
# 摘要
地质保障技术在煤矿开采规划、安全性和技术创新中扮演着至关重要的角色。本文概述了地质保障技术的基本原理,详细探讨了地质数据分析在煤矿开采规划中的应用,以及如何通过地质保障技术预防地质灾害和保障煤矿安全。文章还分析了开采技术进步对地质保障的影响,地质保障技术与开采新技术的结合点,以及未来发展趋势。案例研究部分提供了地质保障技术成功应用的实例分析和经验总结。最后,文章讨论了地质保障技术面临的挑战和未来发展方向
【SOEM同步位置模式(CSP)入门与实践】:打造高性能电机控制系统
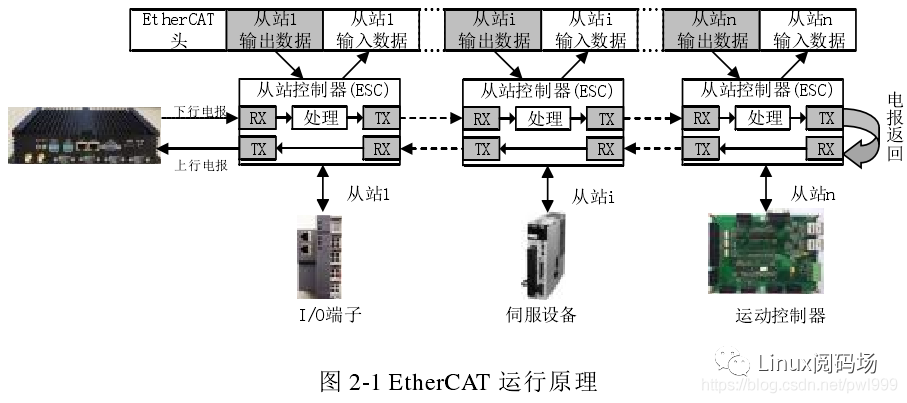
# 摘要
同步位置模式(CSP)是一种关键的同步控制技术,广泛应用于电机控制系统中,以提高运动精度和同步性能。本文首先概述了CSP的基础知识及其理论基础,包括工作原理、同步算法的数学模型以及同步机制的优化策略。接着,本文深入探讨了CSP在伺服电机、步进电机和多轴同步控制中的应用实践,分析了其在不同电机控制场景
【Python列表与数据结构】:深入理解栈、队列与列表的动态互动
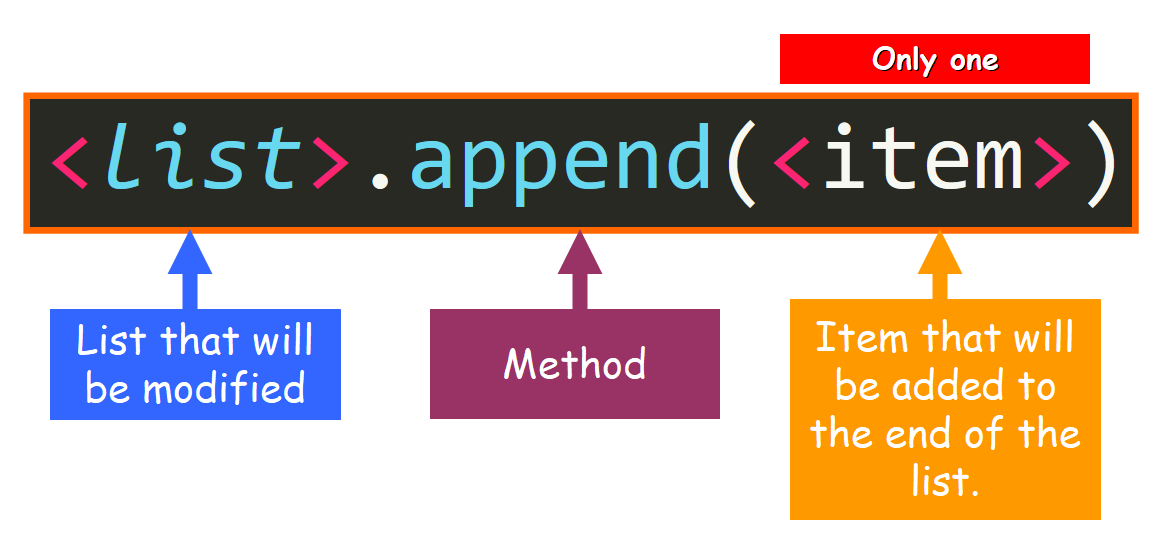
# 摘要
本文系统性地探讨了Python中列表与栈、队列等数据结构的基础知识、原理、应用和优化。章节一介绍了Python列表的基本概念和作为动态数据结构的特点。第二章和第三章深入解析了栈和队列的定义、操作原理、算法应用和内存优化策略,以及在Python中的实现。第四章探讨了列表与栈、队列的动态互动以及性能对比。第五章通过案例分析展示了这些数据结构在实际问题中的应用,如浏览器历史记
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )