理解Node.js的核心概念与工作原理
发布时间: 2024-04-08 17:15:49 阅读量: 36 订阅数: 24 

学习node.js核心原理
# 1. Node.js简介
Node.js是一个基于Chrome V8引擎的JavaScript运行时环境,它采用事件驱动、非阻塞I/O模型,使其非常适合构建高性能的网络应用程序。在现代Web开发中,Node.js已经成为一个备受关注和广泛应用的技术。
## 1.1 Node.js的定义与背景
Node.js最初由Ryan Dahl在2009年创建,旨在实现高效的服务器端JavaScript运行环境。它借助V8引擎快速执行JavaScript代码,同时利用事件驱动、非阻塞I/O的特性,使得处理大量并发请求成为可能。
## 1.2 Node.js的特点与优势
Node.js具有以下几个显著的特点与优势:
- 单线程处理请求,无需创建新的线程,减少了内存消耗和线程切换开销。
- 采用事件驱动模型,通过事件循环处理请求,提高了处理能力。
- 非阻塞I/O操作,能够高效处理大量I/O密集型任务。
- 丰富的模块生态系统,可以方便地引入第三方模块。
## 1.3 Node.js在现代Web开发中的应用
Node.js在现代Web开发中有着广泛的应用,包括但不限于:
- 构建RESTful API服务
- 开发实时应用程序,如聊天室、在线游戏等
- 构建单页面应用程序(SPA)
- 实现服务器端渲染(SSR)
- 开发工具、构建工具等等
总的来说,Node.js的强大特性和优势使其成为了现代Web开发不可或缺的一部分。
现在让我们进入第二章,深入理解Node.js的核心概念。
# 2. Node.js的核心概念
### 2.1 事件驱动模型
事件驱动模型是Node.js的核心之一,它使用事件循环和触发器来处理异步操作。下面我们来演示一个简单的事件驱动示例代码:
```javascript
// 引入events模块
const EventEmitter = require('events');
// 创建一个事件发射器实例
const myEmitter = new EventEmitter();
// 监听事件
myEmitter.on('event', () => {
console.log('触发了一个事件!');
});
// 触发事件
myEmitter.emit('event');
```
**代码场景解释:**
- 首先,我们引入Node.js的events模块,该模块提供了EventEmitter类,用于处理事件的触发和监听。
- 然后,我们创建了一个事件发射器实例myEmitter。
- 接着,使用`on`方法监听名为`event`的事件,并在事件发生时打印出一条消息。
- 最后,通过`emit`方法手动触发事件。
**代码总结:**
- 通过事件驱动模型,Node.js可以实现异步、非阻塞的I/O操作,提高程序的并发处理能力。
**结果说明:**
运行该示例代码将会输出:`触发了一个事件!`
### 2.2 非阻塞I/O
在 Node.js 中,使用非阻塞 I/O 操作可以避免因为等待 I/O 操作完成而导致线程被阻塞的情况,提高程序的性能和并发处理能力。下面是一个简单的非阻塞 I/O 示例:
```javascript
// 引入fs模块
const fs = require('fs');
// 读取文件内容(非阻塞)
fs.readFile('example.txt', 'utf8', (err, data) => {
if (err) throw err;
console.log(data);
});
console.log('文件读取中...');
```
**代码场景解释:**
- 首先,我们引入Node.js的fs模块,该模块提供了文件系统相关的操作函数。
- 然后,使用`readFile`方法异步地读取`example.txt`文件的内容,并在读取完成后执行回调函数打印文件内容。
- 最后,由于是非阻塞操作,所以会立即输出`文件读取中...`,而不会等待文件读取完成。
**代码总结:**
- 非阻塞 I/O 使得程序能够在等待 I/O 操作完成的同时执行其他任务,提高了程序的效率和性能。
**结果说明:**
运行该示例代码将会先输出`文件读取中...`,随后再输出文件的内容。
# 3. Node.js的工作原理
Node.js的工作原理涉及到其核心机制和模块,包括V8引擎、libuv库、事件循环机制和异步I/O操作。本章将深入介绍Node.js的工作原理。
#### 3.1 V8引擎解析JavaScript代码
V8引擎是由Google开发的JavaScript引擎,用于解析和执行JavaScript代码。Node.js利用V8引擎来运行JavaScript代码,实现高性能的执行环境。下面是一个简单的Node.js脚本示例:
```javascript
// hello.js
function greet() {
return 'Hello, World!';
}
console.log(greet());
```
在命令行中执行`node hello.js`,V8引擎会解析并执行`hello.js`中的代码,最后输出`Hello, World!`。
总结:V8引擎负责解析和执行JavaScript代码,是Node.js的核心之一。
#### 3.2 libuv库实现事件驱动
libuv是一个跨平台的异步I/O库,是Node.js的重要组成部分,用于处理事件驱动的编程。通过libuv库,Node.js可以实现异步操作,包括文件I/O、网络I/O等。以下是一个简单的使用libuv进行文件读取的示例:
```javascript
// file.js
const fs = require('fs');
fs.readFile('example.txt', 'utf8', (err, data) => {
if (err) {
console.error(err);
return;
}
console.log(data);
});
```
在上述示例中,`fs.readFile`方法是异步的,当文件读取完成后会触发回调函数并输出文件内容。
总结:libuv库实现了事件驱动和异步I/O,使Node.js能够高效处理I/O操作。
#### 3.3 Node.js的事件循环机制
Node.js基于事件驱动的模型,通过事件循环机制来处理异步操作和事件触发。事件循环不断监听事件队列,当有事件发生时就会调用相应的回调函数进行处理。以下是一个简单的事件循环示例:
```javascript
// event.js
const EventEmitter = require('events');
const emitter = new EventEmitter();
emitter.on('hello', () => {
console.log('Hello, Event!');
});
emitter.emit('hello');
```
在上述示例中,通过`emitter.emit`方法触发`hello`事件,事件循环监听到该事件后会执行对应的回调函数并输出`Hello, Event!`。
总结:Node.js通过事件循环机制实现异步操作的调度和执行,提高了系统的性能和响应速度。
#### 3.4 Node.js的异步I/O操作
Node.js采用异步非阻塞的I/O模型,通过回调函数实现异步操作的处理。异步I/O操作可以提高系统的并发能力和性能。以下是一个简单的异步读取文件的示例:
```javascript
// async_io.js
const fs = require('fs');
fs.readFile('example.txt', 'utf8', (err, data) => {
if (err) {
console.error(err);
return;
}
console.log(data);
});
```
在上述示例中,通过`fs.readFile`方法进行文件读取操作,当读取完成后会调用回调函数输出文件内容。
总结:Node.js的异步I/O操作模型可以提高系统的性能和吞吐量,适用于处理大量并发请求的场景。
本章详细介绍了Node.js的工作原理,包括V8引擎解析JavaScript代码、libuv库实现事件驱动、事件循环机制和异步I/O操作。深入理解这些核心概念可以帮助开发者更好地利用Node.js构建高性能的应用程序。
# 4. Node.js的模块系统
在Node.js中,模块系统起着至关重要的作用,它使得我们可以将代码分割成小块,提高代码的可维护性和复用性。本章将深入探讨Node.js的模块系统相关内容。
### 4.1 CommonJS规范
CommonJS是一种模块化规范,Node.js遵循这一规范来组织代码。根据CommonJS规范,一个文件就是一个模块,模块内部的变量和方法默认是私有的,需要通过`module.exports`来导出需要暴露的内容,通过`require()`函数来引入其他模块。
```javascript
// math.js
function add(a, b) {
return a + b;
}
function subtract(a, b) {
return a - b;
}
module.exports = {
add,
subtract
};
```
```javascript
// app.js
const { add, subtract } = require('./math.js');
console.log(add(5, 3)); // 输出:8
console.log(subtract(5, 3)); // 输出:2
```
### 4.2 npm包管理器
npm是Node.js的包管理器,拥有丰富的第三方包可以供开发者使用。通过npm,我们可以轻松地安装、管理、发布自己的包。
安装包示例:
```bash
npm install packageName
```
### 4.3 内置模块与第三方模块
Node.js提供了一些核心模块,如`fs`、`http`等,可以直接引入和使用。同时,也可以通过npm安装第三方模块,丰富了Node.js的功能。
```javascript
// 使用内置模块 http
const http = require('http');
// 使用第三方模块 lodash
const _ = require('lodash');
```
### 4.4 模块加载机制分析
Node.js采用了CommonJS的模块加载机制,每个模块都有自己的模块对象、模块作用域等特性。在模块加载时会进行缓存,避免重复加载,提高性能。
总结:模块化是Node.js的核心特性之一,通过CommonJS规范和npm包管理器,使得Node.js在代码组织和模块复用方面非常强大。通过模块加载机制,能够高效地管理模块间的依赖关系,带来更好的开发体验。
# 5. Node.js的网络编程
在 Node.js 中,网络编程是一项非常重要的任务,它可以帮助我们构建各种类型的网络应用程序。本章将介绍 Node.js 中网络编程的相关内容,包括创建 HTTP 服务器、处理 HTTP 请求与响应、WebSocket 通信以及 TCP/UDP 套接字编程。
### 5.1 创建HTTP服务器
在 Node.js 中创建一个简单的 HTTP 服务器非常简单,可以通过以下代码实现:
```javascript
const http = require('http');
// 创建服务器
const server = http.createServer((req, res) => {
res.statusCode = 200;
res.setHeader('Content-Type', 'text/plain');
res.end('Hello, World!\n');
});
// 监听端口
server.listen(3000, '127.0.0.1', () => {
console.log('Server running at http://127.0.0.1:3000/');
});
```
**场景说明:** 以上代码创建了一个简单的 HTTP 服务器,当收到请求时,服务器会返回一个 "Hello, World!" 的响应。
**代码总结:**
- 使用 `http` 模块创建 HTTP 服务器。
- 通过 `createServer` 方法创建服务器实例,并传入一个回调函数处理请求和响应。
- 使用 `listen` 方法指定服务器监听的端口和主机地址。
- 在回调函数中设置响应状态码、头部信息以及返回内容。
**结果说明:** 当访问 `http://127.0.0.1:3000/` 时,浏览器将显示 "Hello, World!"。
### 5.2 处理HTTP请求与响应
在 Node.js 中,可以通过请求对象 `req` 和响应对象 `res` 来处理 HTTP 请求和生成 HTTP 响应。下面是一个简单的例子:
```javascript
const http = require('http');
const server = http.createServer((req, res) => {
if (req.url === '/') {
res.statusCode = 200;
res.setHeader('Content-Type', 'text/plain');
res.end('Welcome to the homepage!\n');
} else if (req.url === '/about') {
res.statusCode = 200;
res.setHeader('Content-Type', 'text/plain');
res.end('About us page\n');
} else {
res.statusCode = 404;
res.end('Page not found\n');
}
});
server.listen(3000, '127.0.0.1', () => {
console.log('Server running at http://127.0.0.1:3000/');
});
```
**场景说明:** 以上代码根据不同的 URL 路径返回不同的内容,包括首页和关于页面。
**代码总结:**
- 通过请求对象 `req.url` 来获取请求的 URL 路径。
- 根据 URL 路径的不同,设置不同的响应内容和状态码。
- 在回调函数中以 `res.end` 方法结束响应。
**结果说明:**
- 访问 `http://127.0.0.1:3000/` 将显示 "Welcome to the homepage!"。
- 访问 `http://127.0.0.1:3000/about` 将显示 "About us page"。
- 访问其他路径将返回 "Page not found"。
(文章内容仅为示例,实际完整文章将包含更多详细信息和示例代码)
# 6. Node.js的性能优化与安全性
Node.js作为一种高性能的服务器端JavaScript运行环境,性能优化和安全性是开发过程中需要重点关注的方面。本章将介绍Node.js的性能优化和安全性相关内容,包括异步编程技巧、内存管理与垃圾回收、压缩与缓存优化以及防止常见攻击与漏洞。
#### 6.1 异步编程技巧
在Node.js中,异步编程是非常重要的,通过回调函数、Promise、async/await等方式可以有效避免阻塞,提高程序的并发处理能力。下面是一个使用Promise进行异步编程的示例代码:
```javascript
function asyncFunction() {
return new Promise((resolve, reject) => {
setTimeout(() => {
resolve('Async operation completed');
}, 2000);
});
}
async function main() {
console.log('Start');
try {
const result = await asyncFunction();
console.log(result);
} catch (error) {
console.error(error);
}
console.log('End');
}
main();
```
**代码总结:**
- 使用Promise对象包装异步操作,通过resolve()和reject()方法处理操作结果。
- 使用async/await语法糖可以让异步代码看起来像同步代码,提高可读性和维护性。
**结果说明:**
- 执行main()函数时,会先输出"Start"。
- 等待2秒后,输出"Async operation completed"。
- 最后输出"End"。
#### 6.2 内存管理与垃圾回收
Node.js采用V8引擎进行JavaScript代码的解析和执行,V8引擎中包含了自动内存管理和垃圾回收机制。开发者需要注意内存泄漏和性能优化问题,避免不必要的内存消耗。可以通过Heap Snapshot和CPU Profile工具进行性能分析和内存泄漏检测。
#### 6.3 压缩与缓存优化
对于大型Web应用,压缩和缓存是提高性能的重要手段。可以使用gzip压缩响应数据,减少传输时间和带宽消耗;同时,合理设置HTTP头中的缓存控制字段,使浏览器能够有效地缓存静态资源,减少重复请求。
#### 6.4 防止常见攻击与漏洞
在Node.js应用中,需要考虑到常见的安全攻击和漏洞,如跨站脚本攻击(XSS)、SQL注入、拒绝服务攻击(DDoS)等。开发者需要通过输入验证、数据加密、安全头设置等方式,增强应用的安全性,防范潜在的风险。
通过对Node.js的性能优化和安全性方面的理解,开发者可以更好地构建高效、安全的应用程序,提升用户体验并保护数据安全。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨 Node.js,涵盖从入门基础到高级概念的方方面面。它提供了一系列循序渐进的指南,帮助初学者了解 Node.js 的核心概念、模块化编程、异步编程和事件驱动架构。此外,它还介绍了 Express 框架、中间件、RESTful API 设计、数据库操作、性能优化和安全性等高级主题。通过深入理解 Node.js 的特性和最佳实践,本专栏旨在帮助开发者构建健壮、可扩展和高效的 Node.js 应用程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【零基础到精通】:3D渲染技术速成指南,掌握关键技巧

# 摘要
本文系统地介绍了3D渲染技术,从理论基础到实际应用进行了全面阐述。首先介绍了3D渲染的基本概念、光线追踪与光栅化的原理、材质与纹理贴图的应用,以及照明与阴影技术。接着,文章深入探讨了当前流行的3D渲染软件和工具,包括软件功能和渲染引擎的选择。实践案例分析章节通过具体实例展示了产品、角色与动画以及虚拟现实和3D打印的渲染技巧。最后,文章聚焦于渲染速度提升方法、高级渲
压力感应器校准精度提升:5步揭秘高级技术
# 摘要
提升压力感应器校准精度对于确保测量准确性具有重要意义,特别是在医疗和工业制造领域。本文首先介绍了压力感应器的工作原理及其校准的基础知识,然后探讨了提高校准精度的实践技巧,包括精确度校准方法和数据分析处理技术。文章还探讨了高级技术,如自动化校准和校准软件的应用,以及误差补偿策略的优化。通过对典型行业应用案例的分析,本文最后提出了校准技术的创新趋势,指出了新兴技术在校准领域的潜在应用和未来发展方向。本文旨在为专业技术人员提供系统性的理论指导和实践经验,以提升压力感应器的校准精度和可靠性。
# 关键字
压力感应器;校准精度;自动化校准;数据分析;误差补偿;校准技术
参考资源链接:[鑫精
【24小时精通TI-LMK04832.pdf】:揭秘技术手册背后的技术细节,快速掌握关键信息
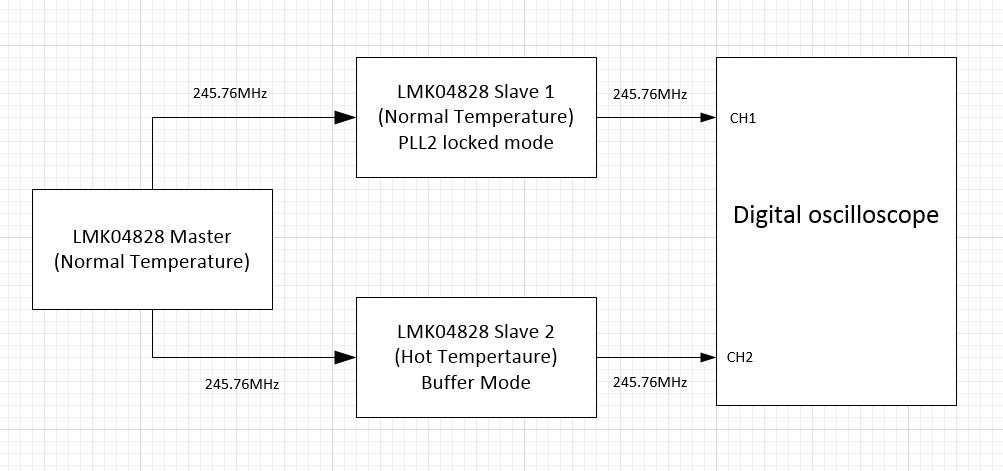
# 摘要
LMK04832是高性能的时钟发生器与分配设备,本文全面介绍其技术手册、工作原理、性能参数、应用电路设计、编程与配置,以及故障排除与维护。本手册首先为读者提供了关于LMK04832的概览,接着详细分析了其内部架构和关键性能参数,阐述了信号路径和时钟分配机制,并指
STM32电源问题诊断:系统稳定性的关键策略

# 摘要
STM32系统作为广泛应用于嵌入式领域的一个重要平台,其电源稳定性对整个系统的性能和可靠性至关重要。本文系统地分析了电源问题对STM32系统稳定性的影响
深入揭秘VB.NET全局钩子:从原理到高效应用的全攻略
# 摘要
全局钩子在软件开发中常用于监控和响应系统级事件,例如键盘输入或鼠标活动。本文首先概述了VB.NET中的全局钩子,随后深入探讨了其内部工作机制,包括Windows消息系统原理和钩子的分类及其作用。文章详细介绍了在VB.NET环境下设置和实现全局钩子的具体步骤,并通过键盘和鼠标钩子的使用案例,展示了全局钩子的实际应用。进一步,本文探讨了全局钩子在多线程环境下的交互和性能优化策略,以及安全性考量。最后,文章提供了
前端性能优化实战秘籍:10个策略让你的页面飞起来

# 摘要
随着互联网技术的快速发展,前端性能优化成为提升用户体验的关键因素。本文对前端性能优化进行了全面的概述,深入探讨了页面渲染优化技术,包括关键渲染路径、代码分割与懒加载,以及CSS优化。在资源加载与管理方面,文章分析了资源压缩与合并、异步加载及CDN加速的有效策略。进一步地,本文还讨论了交互与动画性能提升的方法,如GPU加速、动画优化技巧及交互性能调优。此外,文章还介绍了前端监控与分析工
CMW500信令测试故障排除:20个常见问题与应对策略

# 摘要
本文
CPCI标准2.0中文版数据隐私保护指南

# 摘要
本文全面介绍了CPCI标准2.0在数据隐私保护方面的应用和实践。首先概述了CPCI标准2.0的基本内容,并详细讨论了数据隐私保护的基础理论,包括其定义、重要性以及与数据保护原则的关系。随后,文章对比了CPCI标准2.0与国际数据隐私保护标准,如GDPR,并探讨了其具体要求与实践,特别是在数据主体权利保护、数据处理活动合规性及跨境数据传输规则方面。此外,本文着重阐述了CPCI标准2.0在实施过程中所依赖的技术保障措施,如数据加密、匿名
【TOAS流程优化】:OSA测试流程详解与操作步骤优化建议

# 摘要
本文针对TOAS流程的全貌进行了深入探讨,涵盖了OSA测试流程的理论与实践操作。通过对测试流程中的关键活动、要素以及测试前后的重要步骤进行分析,本文揭示了TOAS流程中常见的问题与挑战,并提供了优化建议和理论支撑。具体操作步骤包括流程映射与诊断、重构与标准化,以及监控与持续改进。文章通过案例分享,展示了TOAS流程优化的成功与失败经验,旨在为相关流程管理和优化提供
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )