探索Selenium Grid实现分布式自动化测试
发布时间: 2024-03-07 08:27:43 阅读量: 34 订阅数: 24 

selenium 自动化测试
# 1. 介绍Selenium Grid
## 1.1 什么是Selenium Grid
Selenium Grid是Selenium Suite中的一个组件,用于支持分布式自动化测试。它允许同时在多台计算机上执行测试脚本,将测试工作分发到不同的系统上,从而加快测试的执行速度。
## 1.2 分布式自动化测试的意义
分布式自动化测试利用多台计算机同时执行测试脚本,将测试工作分散到不同的机器上,可以显著减少测试的执行时间,提高测试效率。
## 1.3 使用Selenium Grid的好处
- 提高测试的执行速度:通过并行执行测试,节省时间
- 实现多平台、多浏览器测试:可以在不同环境下同时执行测试
- 节约资源成本:利用已有的机器资源进行测试
- 提高可靠性:通过分布式测试减少单点故障的风险
通过Selenium Grid,我们可以很好地实现分布式自动化测试,提高测试效率和可靠性。
# 2. 构建Selenium Grid环境
分布式自动化测试需要一个稳定、可靠的Selenium Grid环境来支持。在本章节中,我们将介绍如何构建Selenium Grid环境,包括准备依赖环境、配置Selenium Hub和配置Selenium Node。让我们一步步来进行。
### 2.1 准备Selenium Grid的依赖环境
在开始配置Selenium Grid之前,我们需要准备好相应的依赖环境,包括安装JDK、Selenium Server、浏览器驱动等。
#### 安装JDK
首先,确保你的机器上已经安装了Java Development Kit(JDK)。Selenium Grid需要JDK来运行。你可以在Oracle官网下载并安装最新版本的JDK。
#### 安装Selenium Server
接下来,需要下载Selenium Server,你可以在Selenium官网下载最新的Selenium Server版本。下载完成后,解压文件到一个适当的目录。在命令行中运行Selenium Server:
```shell
java -jar selenium-server-standalone-3.141.59.jar -role hub
```
这将启动Selenium Hub。现在,我们已经准备好了Selenium Server和Selenium Hub。
### 2.2 配置Selenium Hub
Selenium Hub是Selenium Grid的管理中心,它用于管理和分发测试请求给各个Selenium Node。
#### 创建Hub配置文件
创建一个`hubConfig.json`文件来配置Selenium Hub。示例配置如下:
```json
{
"port": 4444,
"newSessionWaitTimeout": -1,
"servlets" : [],
"prioritizer": null
}
```
#### 启动Selenium Hub
在命令行中通过以下命令启动Selenium Hub:
```shell
java -jar selenium-server-standalone-3.141.59.jar -role hub -hubConfig hubConfig.json
```
现在,Selenium Hub已经成功配置和启动了。
### 2.3 配置Selenium Node
Selenium Node是实际执行测试的节点,需要连接到Selenium Hub。
#### 创建Node配置文件
创建一个`nodeConfig.json`文件来配置Selenium Node。示例配置如下:
```json
{
"capabilities": [
{
"browserName": "chrome",
"maxInstances": 5,
"seleniumProtocol": "WebDriver"
}
],
"maxSession": 5,
"port": 5555,
"register": true,
"registerCycle": 5000,
"hub": "http://localhost:4444"
}
```
#### 启动Selenium Node
在命令行中通过以下命令启动Selenium Node:
```shell
java -jar selenium-server-standalone-3.141.59.jar -role node -nodeConfig nodeConfig.json
```
现在,Selenium Node已经成功配置和启动了。你可以根据需要创建多个Node,并配置不同的浏览器和版本。
完成以上步骤后,你的Selenium Grid环境就搭建好了,可以开始进行分布式自动化测试了。
# 3. 实现分布式自动化测试
分布式自动化测试是指在多个计算机上同时执行自动化测试,可以加快测试执行速度,提高测试效率。使用Selenium Grid可以实现分布式自动化测试,下面将介绍如何实现分布式自动化测试以及配置测试用例运行环境。
#### 3.1 编写测试脚本
首先,我们需要编写测试脚本,在本例中我们使用Python语言,通过Selenium WebDriver编写一个简单的测试脚本来演示分布式自动化测试。
```python
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
# 启动远程浏览器
driver = webdriver.Remote(
command_executor='http://selenium_hub_ip:4444/wd/hub',
desired_capabilities={
"browserName": "chrome",
}
)
# 打开网页
driver.get("https://www.example.com")
# 执行测试操作
search_box = driver.find_element_by_name("q")
search_box.send_keys("Selenium Grid")
search_box.send_keys(Keys.RETURN)
time.sleep(5)
# 结束测试
driver.quit()
```
这个脚本会启动一个远程的浏览器,打开网页,输入关键词并进行搜索,然后退出浏览器。我们需要将这个脚本保存为 `test_script.py`。
#### 3.2 配置测试用例运行环境
接下来,我们需要在多台机器上配置测试用例的运行环境。假设我们有两台机器作为节点,它们的IP地址分别是 `node1_ip` 和 `node2_ip`,我们需要在每台机器上安装Selenium和浏览器驱动,并启动Selenium Node。
我们可以使用以下命令启动Selenium Node:
```bash
java -Dwebdriver.chrome.driver=/path/to/chromedriver -jar selenium-server-standalone.jar -role node -hub http://selenium_hub_ip:4444/grid/register
```
#### 3.3 运行分布式测试
在所有节点都配置好测试环境后,我们可以通过运行 `test_script.py` 来执行分布式测试。运行测试脚本的命令如下:
```bash
python test_script.py
```
此时,Selenium Grid会在可用的节点上启动浏览器,执行测试脚本,并返回执行结果。这样就实现了分布式自动化测试。
通过以上步骤,我们成功实现了分布式自动化测试,并且演示了如何配置测试用例的运行环境和运行分布式测试。
# 4. 管理Selenium Grid
在使用Selenium Grid进行分布式自动化测试时,我们需要对Grid进行管理和监控,以确保测试环境的稳定性和高效性。本章将介绍如何监控和调试Selenium Grid,如何动态调整节点数量以及如何进行多浏览器测试管理。
#### 4.1 监控和调试Selenium Grid
监控Selenium Grid是确保测试环境正常运行的重要手段。我们可以通过Selenium Grid提供的API接口或者第三方监控工具,如Grafana和Prometheus,来监控Grid的运行状态、节点的健康状况以及测试的执行情况。
另外,在调试Selenium Grid时,我们可以通过查看节点和浏览器的日志,以及利用Grid的调试模式来定位问题,比如网络通信问题、节点断连等等。
#### 4.2 动态调整节点数量
当测试需求发生变化时,我们可能需要动态调整Selenium Grid的节点数量,以应对不同规模和复杂度的测试。可以通过编写脚本或者使用自动化部署工具,如Docker和Kubernetes,来实现动态调整节点数量,从而在保证测试质量的前提下提高测试效率。
#### 4.3 多浏览器测试管理
Selenium Grid支持在不同节点上同时执行多浏览器测试,但在实际操作中可能会遇到不同浏览器版本、驱动版本的兼容性问题。因此,需要建立良好的多浏览器测试管理机制,包括浏览器版本的统一管理、驱动的动态加载更新等,以确保测试结果的准确性和稳定性。
在管理多浏览器测试时,还需要考虑如何最大程度地利用节点资源,合理分配不同浏览器的执行任务,以提高测试效率和降低成本。
以上就是管理Selenium Grid的关键内容,通过有效的管理和调整,能够更好地利用Selenium Grid的优势,提高测试效率和质量。
# 5. 解决常见问题
在使用Selenium Grid进行分布式自动化测试的过程中,可能会遇到一些常见问题。本章将介绍一些常见问题的解决方法,帮助您更顺利地使用Selenium Grid进行测试。
#### 5.1 网络通信问题解决
在搭建和运行Selenium Grid的过程中,由于网络环境的复杂性,可能会遇到节点之间通信不畅或者超时的问题。这些问题通常可以通过以下方法解决:
```python
# 代码示例:设置节点之间的通信超时时间
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
# 设置节点之间的通信超时时间为30秒
desired_capabilities = DesiredCapabilities.CHROME.copy()
desired_capabilities['max_duration'] = 1800
driver = webdriver.Remote(
command_executor='http://<node-ip>:4444/wd/hub',
desired_capabilities=desired_capabilities
)
```
在上面的代码示例中,我们使用`max_duration`参数设置了节点之间通信的超时时间为1800秒,这可以帮助解决节点通信超时的问题。
#### 5.2 浏览器驱动管理
在Selenium Grid中使用不同的浏览器进行测试时,需要管理各种浏览器的驱动版本和路径。为了简化这一过程,可以使用WebDriverManager等工具来自动管理浏览器驱动的下载和配置。
```java
// 代码示例:使用 WebDriverManager 自动管理浏览器驱动
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import io.github.bonigarcia.wdm.WebDriverManager;
WebDriverManager.chromedriver().setup();
WebDriver driver = new ChromeDriver();
```
上面的代码示例展示了在Java中使用WebDriverManager来自动管理Chrome浏览器驱动的下载和配置。这样可以避免手动管理浏览器驱动版本和路径的繁琐工作。
#### 5.3 其他常见问题解决方法
除了上述列举的问题解决方法外,还可能会遇到其他一些常见问题,如节点注册失败、浏览器版本兼容性等。针对这些问题,可以通过查看Selenium Grid的官方文档、查找相关的社区讨论或者咨询专业人士来获取解决方法。
总之,在使用Selenium Grid进行分布式自动化测试时,遇到问题时不要气馁,要善于查找解决方法,通过持续学习和实践来提升技能。
以上是关于常见问题的解决方法,希望能帮助您更好地使用Selenium Grid进行测试。
接下来,让我们一起看看最佳实践与注意事项。
# 6. 最佳实践与注意事项
在使用Selenium Grid进行分布式自动化测试时,以下是一些最佳实践和需要注意的事项:
#### 6.1 最佳实践分享
- **合理规划节点数量**:根据实际需求和测试场景,合理规划Selenium Node的数量,避免资源浪费或性能瓶颈。
- **统一浏览器版本**:确保Selenium Node上的浏览器版本与测试用例中指定的版本一致,以避免兼容性问题。
- **灵活配置Hub和Node**:根据需要,灵活配置Selenium Hub和Node的参数,如超时时间、同时运行的测试实例数量等。
- **持续集成结合**:将Selenium Grid与持续集成工具(如Jenkins)结合使用,实现自动化测试流程。
- **定期清理环境**:定期清理测试环境,包括日志文件、临时文件和浏览器缓存等,保持环境整洁。
#### 6.2 分布式测试的注意事项
- **网络稳定性**:保证Selenium Hub和Node之间的网络连接稳定,避免测试中断或超时。
- **并发测试处理**:合理处理并发测试时的资源竞争和同步问题,确保测试结果的准确性。
- **日志记录**:及时记录测试执行日志,便于排查问题和分析测试结果。
- **异常处理**:合理处理测试中的异常情况,如断网、节点宕机等,保证测试的稳定性。
#### 6.3 总结和展望
通过遵循最佳实践和注意事项,可以更高效地利用Selenium Grid进行分布式自动化测试,提升测试效率和质量。随着技术的不断发展,Selenium Grid在分布式测试领域仍有很大的潜力,未来可以进一步优化性能、提升稳定性,为软件测试带来更多创新。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
空间统计学新手必看:Geoda与Moran'I指数的绝配应用
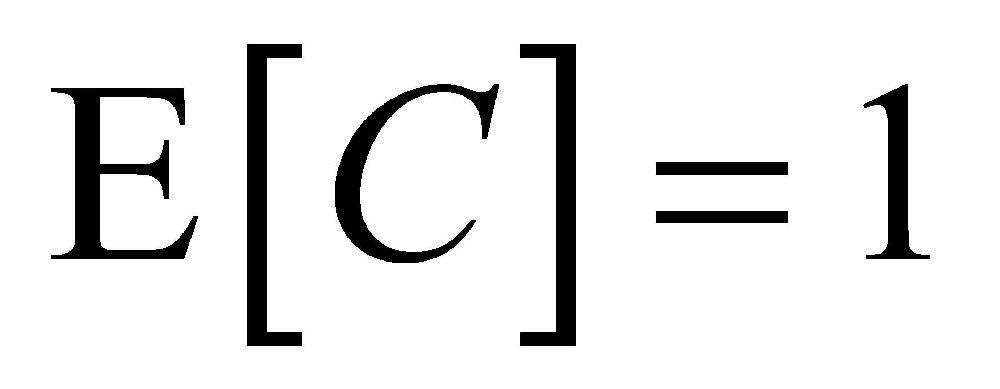
# 摘要
本论文深入探讨了空间统计学在地理数据分析中的应用,特别是运用Geoda软件进行空间数据分析的入门指导和Moran'I指数的理论与实践操作。通过详细阐述Geoda界面布局、数据操作、空间权重矩阵构建以及Moran'I指数的计算和应用,本文旨在为读者提供一个系统的学习路径和实操指南。此外,本文还探讨了如何利用Moran'I指数进行有效的空间数据分析和可视化,包括城市热岛效应的空间分析案例研究。最终,论文展望了空间统计学的未来
【Python数据处理秘籍】:专家教你如何高效清洗和预处理数据

# 摘要
随着数据科学的快速发展,Python作为一门强大的编程语言,在数据处理领域显示出了其独特的便捷性和高效性。本文首先概述了Python在数据处理中的应用,随后深入探讨了数据清洗的理论基础和实践,包括数据质量问题的认识、数据清洗的目标与策略,以及缺失值、异常值和噪声数据的处理方法。接着,文章介绍了Pandas和NumPy等常用Python数据处理库,并具体演示了这些库在实际数
【多物理场仿真:BH曲线的新角色】:探索其在多物理场中的应用
# 摘要
本文系统介绍了多物理场仿真的理论基础,并深入探讨了BH曲线的定义、特性及其在多种材料中的表现。文章详细阐述了BH曲线的数学模型、测量技术以及在电磁场和热力学仿真中的应用。通过对BH曲线在电机、变压器和磁性存储器设计中的应用实例分析,本文揭示了其在工程实践中的重要性。最后,文章展望了BH曲线研究的未来方向,包括多物理场仿真中BH曲线的局限性
【CAM350 Gerber文件导入秘籍】:彻底告别文件不兼容问题
# 摘要
本文全面介绍了CAM350软件中Gerber文件的导入、校验、编辑和集成过程。首先概述了CAM350与Gerber文件导入的基本概念和软件环境设置,随后深入探讨了Gerber文件格式的结构、扩展格式以及版本差异。文章详细阐述了在CAM350中导入Gerber文件的步骤,包括前期
【秒杀时间转换难题】:掌握INT、S5Time、Time转换的终极技巧
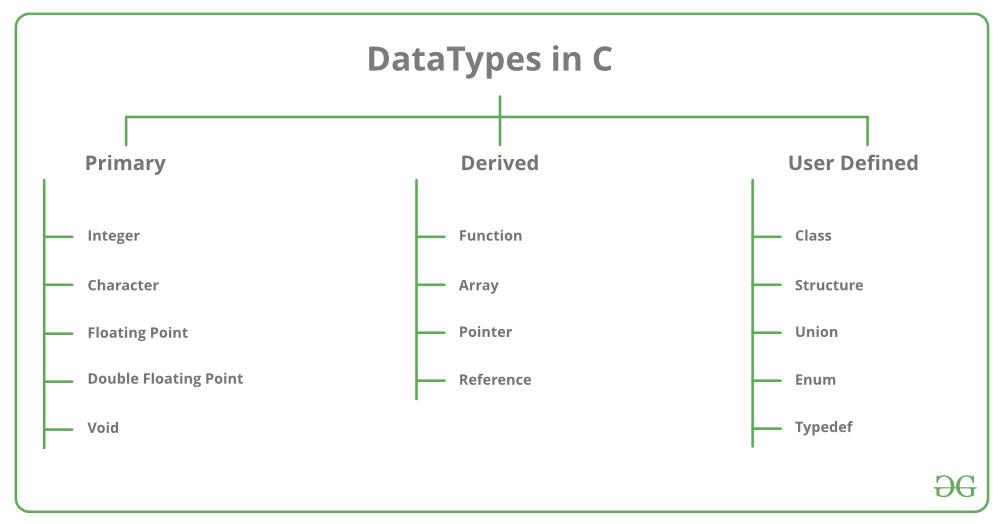
# 摘要
时间表示与转换在软件开发、系统工程和日志分析等多个领域中起着至关重要的作用。本文系统地梳理了时间表示的概念框架,深入探讨了INT、S5Time和Time数据类型及其转换方法。通过分析这些数据类型的基本知识、特点、以及它们在不同应用场景中的表现,本文揭示了时间转换在跨系统时间同步、日志分析等实际问题中的应用,并提供了优化时间转换效率的策略和最
【传感器网络搭建实战】:51单片机协同多个MLX90614的挑战

# 摘要
本论文首先介绍了传感器网络的基础知识以及MLX90614红外温度传感器的特点。接着,详细分析了51单片机与MLX90614之间的通信原理,包括51单片机的工作原理、编程环境的搭建,以及传感器的数据输出格式和I2C通信协议。在传感器网络的搭建与编程章节中,探讨了网络架构设计、硬件连接、控制程序编写以及软件实现和调试技巧。进一步
Python 3.9新特性深度解析:2023年必知的编程更新
# 摘要
随着编程语言的不断进化,Python 3.9作为最新版本,引入了多项新特性和改进,旨在提升编程效率和代码的可读性。本文首先概述了Python 3.
金蝶K3凭证接口安全机制详解:保障数据传输安全无忧
# 摘要
金蝶K3凭证接口作为企业资源规划系统中数据交换的关键组件,其安全性能直接影响到整个系统的数据安全和业务连续性。本文系统阐述了金蝶K3凭证接口的安全理论基础,包括安全需求分析、加密技术原理及其在金蝶K3中的应用。通过实战配置和安全验证的实践介绍,本文进一步阐释了接口安全配置的步骤、用户身份验证和审计日志的实施方法。案例分析突出了在安全加固中的具体威胁识别和解决策略,以及安全优化对业务性能的影响。最后
【C++ Builder 6.0 多线程编程】:性能提升的黄金法则
# 摘要
随着计算机技术的进步,多线程编程已成为软件开发中的重要组成部分,尤其是在提高应用程序性能和响应能力方面。C++ Builder 6.0作为开发工具,提供了丰富的多线程编程支持。本文首先概述了多线程编程的基础知识以及C++ Builder 6.0的相关特性,然后深入探讨了该环境下线程的创建、管理、同步机制和异常处理。接着,文章提供了多线程实战技巧,包括数据共享
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )