ASDS基础入门:快速上手指南
发布时间: 2025-01-09 18:03:59 阅读量: 7 订阅数: 7 

ASDS使用说明 pdf说明资料

# 摘要
ASDS是一种先进的数据处理系统,其基础概念和理论基础是实现高效数据处理的关键。本文首先介绍ASDS的核心原理及其在大数据处理中的重要角色,然后分析ASDS的主要组件、功能以及它们之间的通信机制。文章进一步阐述了ASDS的数据持久化解决方案,包括存储方案和数据一致性以及备份策略。在实践操作指南章节,详细介绍了环境搭建、数据处理流程以及调优与故障排除方法。进阶应用技巧部分探讨了定制化数据处理流程、高级配置和安全性与权限管理。最后,通过案例研究与技术发展趋势分析,提供了ASDS在行业中的应用实例与未来展望。本文旨在为读者提供一个关于ASDS全面的了解,以及如何有效部署和优化ASDS应用的实用指导。
# 关键字
ASDS;大数据处理;数据流;组件分析;数据持久化;故障排除;安全性管理;技术融合
参考资源链接:[ASDS配置工具:高效便捷的物联网产品管理神器](https://wenku.csdn.net/doc/7xy1tfjpd7?spm=1055.2635.3001.10343)
# 1. ASDS基础概念介绍
## 1.1 ASDS的定义与重要性
ASDS(Advanced Stream Data System)是一种高度可扩展、容错性强、适合大规模数据流处理的系统。随着大数据时代的到来,ASDS在实时数据处理、分析和反应方面变得越来越重要。在IT行业中,ASDS已经被广泛地应用于企业数据平台、互联网服务提供商和金融行业的数据分析中。
## 1.2 ASDS的主要特点
ASDS系统的设计重点在于数据处理的实时性和准确性。它支持多种数据源,并能够对流式数据进行高效处理。此外,ASDS具备模块化设计,能够很好地支持定制化需求和扩展性,适应不同行业和应用场景的特定需求。
## 1.3 ASDS的应用场景
在实际业务中,ASDS可以用于多种场景,包括但不限于实时监控、日志分析、交易处理、网络流量分析等。它为数据分析师和工程师提供了一套强大的工具集,帮助他们更快地获取洞察力,并实时作出决策。下一章我们将深入探讨ASDS的理论基础和架构设计。
# 2. ASDS理论基础与应用架构
## 2.1 ASDS核心原理
### 2.1.1 数据流与处理模型
ASDS(Abstract Stream Data System,抽象流数据系统)是一种基于数据流处理模型的系统,它的设计初衷是为了解决实时数据处理的需求。在ASDS中,数据流以连续的、快速流动的方式到达,系统需要实时地处理这些数据,并输出相应的处理结果。
ASDS的数据处理模型通常包括以下几个关键环节:
- **数据源(Data Source)**:数据流的起点,它可以是实时的传感器数据,也可以是预先存储在数据库中的数据。
- **数据处理节点(Data Processing Node)**:负责对流数据进行加工处理的单元。在ASDS中,这些节点可能执行过滤、转换、聚合等操作。
- **数据汇(Data Sink)**:处理后的数据的终点,比如数据库、文件系统或者提供给其他系统或服务的数据接口。
整个数据流处理模型的设计必须考虑到处理效率和容错性,确保即使在高速和大数据量的情况下,也能稳定运行并保持低延迟。
### 2.1.2 ASDS在大数据处理中的角色
在大数据处理的背景下,ASDS发挥着至关重要的作用。由于数据的体量巨大并且不断增长,传统的批处理模型已无法满足实时数据处理的需求。ASDS为大数据提供了以下核心能力:
- **实时性(Real-time processing)**:能够快速响应数据流事件,实时输出处理结果。
- **高吞吐量(High throughput)**:能够处理大规模的数据流,保证数据不积压。
- **可扩展性(Scalability)**:系统架构能够水平扩展,以应对数据量的增加。
- **容错能力(Fault tolerance)**:能够在节点故障的情况下保证数据流的连续性和完整性。
ASDS通过以上特性,成为了现代大数据处理架构中不可或缺的一部分。特别是在需要实时分析和决策支持的场景中,ASDS展现出了其不可替代的优势。
## 2.2 ASDS的组件分析
### 2.2.1 主要组件功能与作用
ASDS系统由多个关键组件构成,每个组件都有其独特的功能和作用:
- **事件监听器(Event Listener)**:负责监听数据源,接收数据流事件,并将事件推送给后续处理组件。
- **转换器(Transformer)**:负责对流经的数据进行必要的转换和处理工作,如格式转换、字段提取等。
- **聚合器(Aggregator)**:对数据流中的数据进行聚合操作,如计算平均值、最大值等。
- **分发器(Distributor)**:负责将处理后的数据分发到不同的输出系统或存储系统中。
这些组件之间通常通过消息队列或者流式处理框架进行通信,以保证系统的解耦和高可用性。
### 2.2.2 组件间通信机制
在ASDS中,组件间的通信机制是系统设计的关键部分。为了确保系统的鲁棒性和实时性,组件间的通信通常采用以下方式:
- **消息队列(Message Queueing)**:使用消息队列来实现组件间的消息传递,如Apache Kafka或RabbitMQ等。
- **事件驱动(Event-driven)**:组件通过发布/订阅模式进行通信,其中组件可以订阅感兴趣的数据流事件,当事件发生时,系统会触发订阅组件进行处理。
- **流处理框架(Stream Processing Framework)**:如Apache Flink或Apache Storm,提供了复杂的流数据处理能力,并支持高效的组件间通信。
这些机制保证了数据流可以在组件间可靠地传递,并且能够在发生故障时,快速恢复服务,最小化系统的停机时间。
## 2.3 ASDS的数据持久化
### 2.3.1 数据存储解决方案
尽管ASDS系统强调实时处理,但数据的持久化也是不可或缺的。为了确保数据的安全和可靠性,ASDS提供了多种数据持久化解决方案:
- **关系型数据库(RDBMS)**:用于存储需要进行复杂查询和事务处理的数据。
- **非关系型数据库(NoSQL)**:如HBase、Cassandra,适用于存储大量的键值对或文档数据。
- **分布式文件系统(DFS)**:如HDFS,用于存储大规模数据文件,适用于数据分析和处理。
为了实现数据的持久化,ASDS还需要考虑如何在保证高可用性和一致性的同时,有效地处理数据备份和故障恢复。
### 2.3.2 数据一致性和备份策略
数据一致性和备份是数据持久化过程中需要特别注意的问题。ASDS通常采用以下策略来保证数据的一致性和可靠性:
- **事务支持**:在需要严格事务保证的场景下,ASDS会与支持事务的关系型数据库配合使用。
- **数据复制**:通过数据复制技术,将数据在多个节点上进行备份,保证单点故障时数据不会丢失。
- **定期备份与快照**:利用快照技术或定期备份,可以将数据状态记录下来,便于在数据丢失或损坏时进行恢复。
通过这些策略,ASDS系统可以确保数据处理的连续性,并在面对系统故障时,最大限度地减少数据丢失的风险。
# 3. ASDS实践操作指南
## 3.1 环境搭建与配置
### 3.1.1 安装ASDS组件
ASDS(Autonomous Scalable Data Stream)是一个支持可扩展数据流处理的平台。搭建ASDS环境是进行数据流处理的第一步。以下步骤将指导您如何在标准Linux操作系统上安装ASDS组件。
```bash
# 更新系统包管理器的索引
sudo apt-get update
# 安装ASDS依赖包
sudo apt-get install -y java-openjdk wget unzip
# 下载ASDS安装包
wget https://asds-releases.s3.amazonaws.com/asds-latest.zip
# 解压下载的文件
unzip asds-latest.zip -d /opt
# 移动到解压后的目录
cd /opt/asds-*/bin
# 设置ASDS的环境变量
export ASDS_HOME=/opt/asds-*/
export PATH=$ASDS_HOME/bin:$PATH
```
上面的步骤在终端中执行,每一步都有特定的作用,如更新系统包管理器的索引,安装所需的依赖包,下载ASDS的安装包,并解压到指定目录。
### 3.1.2 配置集群与管理工具
ASDS支持集群模式,以提供高可用性和横向扩展能力。配置集群涉及编辑配置文件来指定集群中的节点信息。此外,ASDS提供了一个管理工具用于监控和操作集群。
```bash
# 配置集群节点
vi $ASDS_HOME/conf/asds-cluster.xml
<asds-cluster>
<node>
<id>1</id>
<host>localhost</host>
<port>9001</port>
<!-- 其他节点配置 -->
</node>
</asds-cluster>
```
在集群配置文件中,每个`<node>`标签代表集群中的一个节点,其中`<id>`是节点的唯一标识符,`<host>`和`<port>`指定了节点的地址和端口。
ASDS管理工具是一个图形用户界面,可以通过在浏览器中输入管理工具的服务地址来访问。
```bash
# 启动管理工具
$ASDS_HOME/bin/asds-management-tool.sh start
# 管理工具默认在端口8080上运行,可以在浏览器中访问
http://localhost:8080
```
## 3.2 数据处理流程实战
### 3.2.1 数据输入与输出操作
在ASDS中,数据的输入和输出操作是构建数据流处理流程的基础。ASDS支持从各种源读取数据,例如Kafka、Flume等,并支持多种数据存储作为输出,如HDFS、MySQL等。
```java
// 示例代码:数据输入操作
Source source = new KafkaSource()
.setZookeeperConnect("localhost:2181")
.setTopic("input-topic");
// 示例代码:数据输出操作
Sink sink = new HDFSSink()
.setPath("hdfs://localhost:8020/output-path");
```
在上述代码块中,我们创建了两个实例,一个`KafkaSource`用于从Kafka读取数据,一个`HDFSSink`用于将处理后的数据写入HDFS。每个实例通过设置相应的属性来配置数据源或数据目的地。
### 3.2.2 数据处理示例与分析
为了进一步理解ASDS的数据处理流程,我们通过一个简单的示例来分析其实际操作过程。
```java
// 示例代码:一个简单的数据处理流程
// 创建一个数据处理任务
StreamTask task = new StreamTask("example-task");
// 定义数据源和目的地
Source source = new KafkaSource()...;
Sink sink = new HDFSSink()...;
// 添加转换操作
Transformation transformation = new MapTransformation()
.setFunction((MapFunction) record -> {
// 对输入记录进行处理的逻辑
return transformedRecord;
});
// 将各组件连接到任务中
task.setSource(source)
.addTransformation(transformation)
.setSink(sink);
// 启动任务
task.start();
```
在这个示例中,数据处理任务首先创建了一个名为`example-task`的任务实例。然后,我们定义了数据源、转换逻辑和输出目的地,并将它们依次添加到任务中。最后,我们启动了任务实例,数据流开始按照定义的流程进行处理。
## 3.3 调优与故障排除
### 3.3.1 性能监控与调优技巧
为了确保数据流处理的性能,ASDS提供了性能监控工具,可以帮助用户实时监控系统状态。此外,根据监控数据,用户可以对系统进行调优。
```java
// 性能监控示例代码
PerformanceMonitor monitor = new PerformanceMonitor(task);
// 使用性能监控器来获取任务状态信息
TaskStatus status = monitor.getStatus();
// 根据监控数据调整任务参数
task.setParallelism(4); // 增加任务的并行度
```
性能监控器`PerformanceMonitor`通过调用`getStatus()`方法可以获取任务的当前状态信息,包括CPU、内存和网络的使用情况,以及任务的吞吐量。通过这些信息,用户可以作出相应的调整,例如增加任务的并行度来提升处理速度。
### 3.3.2 常见故障诊断与解决方案
在使用ASDS时,难免会遇到一些故障。ASDS提供了一套诊断工具,可以帮助用户快速定位和解决问题。
```bash
# 故障诊断示例命令
$ASDS_HOME/bin/asds-diagnose.sh --task-id <task-id> --diagnosis-type cpu-memory
# 示例输出结果
Diagnosis Result:
CPU Usage: 85%
Memory Usage: 70%
# 根据输出结果进行问题分析和解决
```
通过运行诊断命令`asds-diagnose.sh`,可以针对特定任务进行CPU和内存使用情况的检查。根据命令的输出结果,用户可以采取相应的措施来解决资源使用过高的问题,如优化任务处理逻辑或增加集群资源。
接下来的章节将继续深入介绍ASDS的进阶应用技巧。
# 4. ASDS进阶应用技巧
## 4.1 定制化数据处理流程
### 实现复杂数据流的策略
在ASDS的使用中,设计和实施复杂的数据流是提高数据处理效率和扩展性的关键。定制化数据处理流程涉及到多个方面,包括数据源的选择、数据转换操作、数据目的地的确定以及整个数据流的优化。以下是一些策略:
- **理解数据源特性**:首先必须清晰了解数据源的种类(如日志文件、数据库、消息队列等)、格式(如CSV、JSON、XML等)及数据量大小,以便设计出合理的数据接入策略。
- **采用合适的数据转换方法**:根据数据源的特性选择合适的转换手段,比如使用MapReduce编程模型进行复杂的数据清洗和转换,或者利用内置的转换工具进行简单的格式转换。
- **优化数据流向**:合理规划数据流的路径,减少不必要的数据复制和移动,使用高效的数据分区和负载均衡策略。
- **实施数据流监控和日志记录**:对数据流的状态进行实时监控,并记录详细的操作日志,以便于在数据流出现问题时能够快速定位和修复。
### 数据流的优化与重构
随着时间的推移,数据流可能会变得过于复杂或低效,这时候就需要进行优化或重构。数据流的优化和重构包括以下几个步骤:
- **性能分析**:使用ASDS提供的监控工具对现有数据流的性能进行分析,找出瓶颈。
- **代码或配置优化**:根据性能分析结果,对数据处理代码或ASDS配置进行调整,比如优化MapReduce作业中的join逻辑,或者调整资源分配参数。
- **架构重构**:在某些情况下,可能需要重构整个数据流架构。例如,将批处理转换为流处理或将一些本地化处理迁移到云平台上。
## 4.2 高级配置与扩展应用
### 配置参数深入解析
ASDS的高级配置可以显著影响系统的性能和资源使用。深入理解这些参数及其对数据流的影响是至关重要的。下面是一些核心参数的解析:
- **资源分配参数**:包括内存、CPU、网络和存储资源的分配策略。合理分配资源可以防止作业在执行时出现资源不足的情况。
- **数据分区与并行度**:适当的分区可以减少数据倾斜问题,而并行度则影响数据处理的吞吐量。
- **缓冲区大小**:调整缓冲区大小可以影响数据的延迟和吞吐量,过小的缓冲区可能导致频繁的磁盘I/O,而过大的缓冲区可能导致内存占用过高。
### 集成外部系统与工具
为了提高ASDS的灵活性和易用性,通常需要将ASDS与外部系统和工具集成。以下是一些集成策略:
- **数据集成**:将ASDS与外部数据源和数据仓库进行集成,比如使用JDBC连接数据库,或通过API与外部服务交互。
- **工作流调度**:结合工作流调度工具如Apache Airflow或Azkaban来自动化、调度和监控数据处理任务。
- **监控与告警**:集成监控工具如Grafana和告警系统如Prometheus,以实时监控ASDS集群的健康状况和性能指标。
## 4.3 安全性与权限管理
### 用户认证与授权机制
数据安全和访问控制是任何数据处理系统中不可或缺的部分。ASDS提供了多种机制来实现用户认证和授权:
- **基于角色的访问控制**(RBAC):为用户分配角色,并根据角色设定权限,实现不同级别的访问控制。
- **LDAP/Active Directory集成**:与企业的LDAP或Active Directory服务集成,实现用户身份的集中管理和认证。
- **审计日志**:开启审计日志功能,记录所有用户操作和数据访问行为,以供事后分析和审计。
### 数据加密与合规性考量
处理敏感数据时,数据加密是保障数据安全的重要手段。在ASDS中,数据加密可以从以下方面进行:
- **传输中加密**:使用TLS/SSL协议对数据传输过程中的数据进行加密。
- **存储加密**:利用存储加密技术,如AES,对静态数据进行加密。
- **合规性考量**:根据所在地区的法律法规要求,如GDPR或HIPAA,实施相应的数据处理策略。
至此,我们已经探讨了ASDS在实践中的进阶应用技巧,包括定制化数据处理流程、高级配置、以及安全性与权限管理。这些技巧不仅有助于提高数据处理的效率和安全性,也为进一步探索ASDS的潜能打下了坚实的基础。在接下来的章节中,我们将深入了解ASDS的案例研究和未来展望。
# 5. ASDS案例研究与未来展望
## 5.1 行业应用案例分析
ASDS(Advanced Stream Data System,高级流数据系统)在大数据处理领域中拥有广泛的应用,其能够实时处理大规模数据流,并对数据进行分析和决策支持。在本节中,我们将深入研究ASDS在不同行业中的应用案例,并对成功案例进行经验总结。
### 5.1.1 ASDS在不同领域的应用
ASDS技术应用横跨金融、电信、物联网、医疗保健等多个行业。例如,在金融领域,ASDS能够实时监控市场动态,并对交易数据进行分析,辅助投资者做出更好的投资决策。而在电信行业,ASDS可以实时分析网络流量数据,预测并及时处理网络拥塞,提高服务质量。
#### 5.1.1.1 金融服务
在金融服务中,ASDS可以实现高频交易(HFT)系统的低延迟处理,以及风险管理系统中的实时风险评估。此外,ASDS能够整合多种市场数据源,提供实时的数据分析服务。
#### 5.1.1.2 物联网
物联网(IoT)设备产生的数据量巨大且实时性要求高。ASDS可以用于收集和分析来自传感器的数据,对于智能家居、智慧城市、远程健康监测等场景至关重要。
### 5.1.2 成功案例的经验总结
以下是一些成功运用ASDS的案例经验总结:
- **实时数据分析**:确保系统可以快速响应并处理实时数据流,是ASDS成功应用的关键。
- **系统扩展性**:随着业务的增长,系统应具备良好的扩展性,以应对日益增长的数据量和复杂的处理需求。
- **集成化**:与现有系统及工具的无缝集成,能够充分发挥ASDS的数据处理能力,同时利用现有投资。
## 5.2 技术发展趋势与挑战
随着数据量的不断增长,ASDS也面临着技术发展和应用挑战。在本小节,我们讨论新兴技术的融合、创新,以及未来在大数据处理领域可能面临的挑战。
### 5.2.1 新兴技术的融合与创新
技术的融合发展促使ASDS实现更高级别的功能。例如,机器学习和人工智能的集成,可以增强ASDS的预测分析能力。
#### 5.2.1.1 机器学习与ASDS的融合
机器学习算法的引入使得ASDS能够在数据流处理过程中进行更智能的数据分析。这包括异常检测、趋势预测和模式识别等。
```python
from sklearn.cluster import KMeans
# 假设我们有一个实时数据流,其中包含多个维度的数据
# 使用KMeans进行实时数据聚类分析
for data_point in data_stream:
cluster = kmeans.predict(data_point.reshape(1, -1))
# 分析聚类结果,此处省略具体操作细节
```
### 5.2.2 应对大数据处理的未来挑战
未来ASDS系统将需要处理比以往更加庞大的数据集,同时保证数据处理的速度和质量。
#### 5.2.2.1 数据规模与处理速度的平衡
在保证数据处理速度的前提下,如何有效管理大规模数据是ASDS面临的一个主要挑战。需要优化算法,提高硬件性能,并可能需要探索新的数据压缩和存储技术。
- **数据压缩技术**:通过使用数据压缩算法减少存储需求和提高数据传输速度。
- **内存计算**:利用内存数据库技术加快数据访问速度,从而实现更快的处理。
```mermaid
graph LR
A[原始数据流] --> B[数据压缩]
B --> C[内存计算处理]
C --> D[实时分析结果]
D --> E[数据持久化]
```
ASDS的未来展望充满了无限可能,但同时也伴随着不少挑战。在大数据时代背景下,ASDS将扮演越来越重要的角色,成为数据驱动决策的核心技术。随着技术的不断进步和行业的不断探索,我们期待ASDS能够带来更多的创新和变革。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏提供了有关 ASDS(高级存储和数据服务)的全面指南,涵盖从基础入门到高级特性、集成应用、性能调优、故障排查、数据备份和恢复、集群管理、应用性能分析、自动化运维、与其他技术栈的集成、API 开发和使用,以及数据处理和分析高级技巧等各个方面。通过深入浅出的讲解和丰富的案例研究,本专栏旨在帮助读者快速上手 ASDS,掌握其不为人知的秘密,扩展其功能,优化其性能,解决常见问题,确保业务连续性,构建高可用环境,深入理解性能指标,实现自动化运维,打造定制化解决方案,并解锁数据潜力。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
东大认知计算:引领智能革命的关键技术与策略

# 摘要
本文探讨了认知计算的定义、理论基础、实际应用以及面临的挑战和未来发展方向。认知计算是一种模仿人类认知过程的高级计算方式,它结合了机器学习、人工智能、大数据处理等关键技术,为多个行业带来了变革性的应用,如医疗健康、金融服务和零售市场。文章分析了认知计算的核心架构、技术组成及其在不同领域中的应用案例,同时讨论了与之相关的伦理、法律问题和技术局限。本文还提出了一系列促进认知计算健康发展的策略建议
【驱动更新VS错误修复】:USB驱动更新的利与弊
# 摘要
USB驱动作为连接计算机与外部设备的桥梁,其重要性不言而喻。本文深入探讨USB驱动的更新理论基础,包括其工作原理、必要性及实践操作。同时,分析了在USB驱动更新过程中可能遇到的风险,并提出了相应的预防与控制措施。文章还介绍了错误修复的策略与技巧,并讨论了如何在USB驱动更新与系统稳定性之间找到平衡点。通过对USB驱动更新全面的分析与讨论,本文旨在为计算机用户和IT专业人士提供
【音频信号处理的核动力】:傅里叶变换的理论与应用全景解析
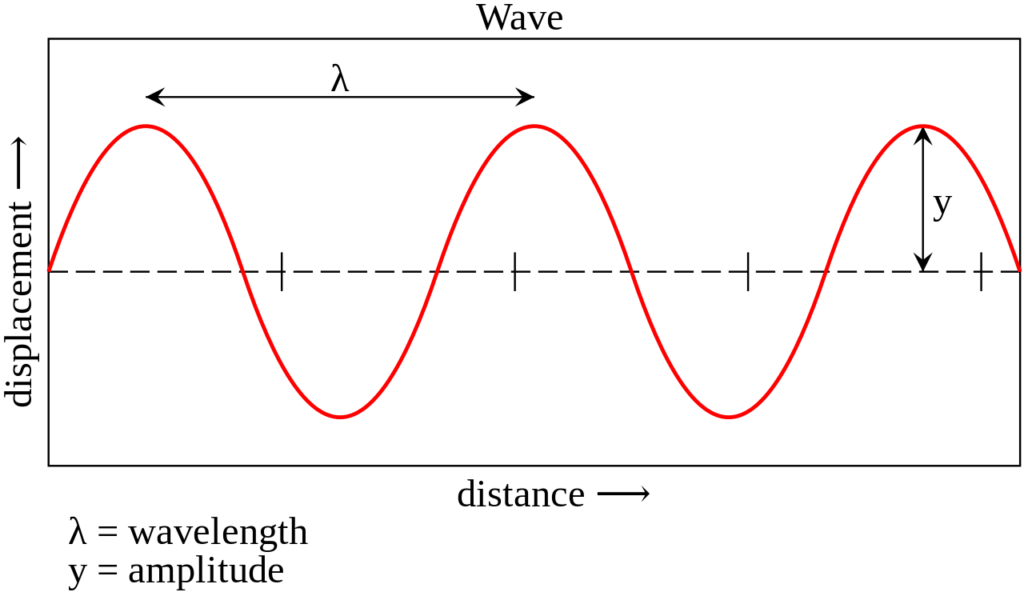
# 摘要
傅里叶变换是信号处理领域中一种基本而强大的数学工具,它允许从时域到频域的转换,以便于分析信号的频率成分。本文从傅里叶变换的数学基础和历史背景入手,详细介绍了其理论框架和数学性质,包括连续时间傅里叶变换(CTFT)、离散时间傅里叶变换(DTFT)以及快速傅里叶变换(FF
Swift项目构建与管理高效指南:runoob教程的最佳实践策略

# 摘要
本文旨在全面介绍Swift项目在构建、管理、质量控制、自动化测试、交付和维护等方面的实践策略与最佳实践。首先,文章深入探讨了Swift构建系统,包括构建工具的介绍、依赖管理以及项目配置与优化。其次,文章详细阐述了代码质量管理与自动化测试方法,涵盖了静态分析、单元测试、集成测试和性能测试。第三部分则专注于Swift项目交付过程中的版本控制选择、代码部署和版本迭代。最后,文章分享
Fel表达式引擎可扩展性深度探讨:架构优化与案例分析

# 摘要
Fel表达式引擎作为一种功能强大的编程工具,因其灵活的语法和高效的执行机制,在数据处理和业务逻辑领域得到了广泛应用。本文首先概述了Fel表达式引擎的基本概念,继而深入探讨其核心原理,包括语法分析、执行机制,并着重分析了虚拟机模型与动态编译技术。第三章着重讨论了Fel引擎的可扩展性设计,涉及模块化架构和插件系统的实现。第四章则通过实际案例展示了Fel表达式引擎在不同场景下的应用实
Visual Paradigm汉化全攻略:中文界面一步搞定
# 摘要
随着信息技术的发展,软件本地化需求日益增长,特别是对于专业设计工具而言,提供多语言支持成为其满足全球用户需求的重要一环。Visua
【项目管理技巧】:IT项目经理必须掌握的监控和控制技巧
# 摘要
项目监控和控制是确保项目成功完成的关键组成部分,涵盖从监控计划的制定到风险评估与管理,再到项目绩效评估和报告等多个方面。本文系统地介绍了项目监控和控制的基础概念、关键实践、控制策略和方法,以及高级应用。特别强调了利益相关者在项目监控中的作用、质量保证的方法论以及项目管理软件的运用。通过对成功与失败案例的分析,本文提炼了关键成功因素,并提供了
【Visual C++ 6.0 LNK1104错误:终极修复指南】:一步到位解决文件无法打开的噩梦
# 摘要
LNK1104错误是Visual C++ 6.0开发环境中常见的链接错误,其产生可能由多种因素引起,包括链接器工作原理的异常、库文件缺失、文件路径和名称长度问题以及编译器或链接器版本不匹配等。本文首先概述了LNK1104错误并分析其根本原因,然后提供了预防和解决该错误的策略和技巧,包括环境变量和路径设置的最佳
【问题全解析】:微信小程序radio单选框,常见问题及解决方案

# 摘要
微信小程序中的radio单选框是用户界面设计的基础组件之一,它允许用户从多个选项中仅选择一个。本文从概述和理论基础开始,详细探讨了radio单选框的构成、功能、数据绑定与传递。在开发实践方面,本文深入讲解了布局实现、功能逻辑、样式定制及性能优化,提供了实用的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )