Sqoop与Spark之间的数据交互与计算
发布时间: 2023-12-17 10:45:46 阅读量: 15 订阅数: 17 
# 1. 引言
## 1.1 问题背景
在大数据领域,数据交互和数据计算是非常重要的环节。随着大数据技术的发展,Sqoop和Spark作为两个重要的工具,在数据交互和数据计算方面扮演着重要的角色。本文将探讨Sqoop和Spark在数据交互和数据计算方面的应用,并分析它们各自的优缺点以及未来发展方向。
## 1.2 技术背景
在大数据处理中,Hadoop被广泛应用于存储和分析海量数据。Sqoop是一种用于在Hadoop和关系型数据库之间进行数据传输的工具,可以有效地实现数据的导入和导出。而Spark则是基于内存计算的大数据计算框架,具有快速、通用、易用的特点,可以实现复杂的数据处理和分析。Sqoop和Spark的结合使用,可以充分发挥它们各自的优势,实现更加高效的大数据处理和分析。
## 2. Sqoop简介
### 2.1 Sqoop基础概念
Sqoop是一个用于在Apache Hadoop和关系型数据库之间传输大量数据的工具。它可以将结构化数据从关系型数据库导入到Hadoop中,也可以将处理过的数据从Hadoop导出到关系型数据库中。
Sqoop支持多种关系型数据库(如MySQL、Oracle、SQL Server等)和Hadoop的各种数据格式(如HDFS、Hive、HBase等),使数据的导入和导出变得非常灵活和高效。
Sqoop的核心组件包括:
- Connector:Sqoop通过连接器与目标数据库进行通信,不同的数据库需要对应不同的连接器。
- Import Tool:用于将数据从关系型数据库导入到Hadoop中。
- Export Tool:用于将数据从Hadoop导出到关系型数据库中。
- Core:提供了一些通用的功能,如配置解析、连接管理等。
### 2.2 数据交互原理
Sqoop的数据交互原理可以简单地描述为以下三个步骤:
1. 获取数据库元数据:Sqoop首先通过相关的数据库连接器获取数据库的元数据信息,包括表结构、列名、类型等。
2. 划分数据:Sqoop根据用户指定的划分方式,将数据划分为若干份,并为每份数据分配一个Map任务。
3. 执行数据传输:每个Map任务将根据划分的数据范围,分别从源数据库中读取数据,并将数据以Hadoop支持的数据格式存储在HDFS中。
总结:
### 3. Spark简介
Apache Spark 是一个快速通用的集群计算系统。它提供了简单的编程模型,基于内存中进行计算,因此在大数据处理中具有高性能。与传统的MapReduce 相比,Spark 能够在内存中保留数据集,从而提供更快的数据存取。以下将介绍Spark的基础概念和数据计算原理。
### 4. Sqoop与Spark的数据交互
#### 4.1 Sqoop将数据导入到Hadoop中
Sqoop是一个用于在Hadoop和关系型数据库之间进行数据传输的工具。它可以将关系型数据库(如MySQL、Oracle等)中的数据导入到Hadoop的分布式文件系统(HDFS)中,以供Spark等计算框架使用。
以下是使用Sqoop将数据从关系型数据库导入到Hadoop的示例代码(使用Java语言):
```java
import org.apache.sqoop.Sqoop;
import org.apache.sqoop.tool.ExportTool;
public class SqoopImportExample {
public static void main(String[] args){
String jdbcUrl = "jdbc:mysql://localhost:3306/mydb";
String username = "root";
String password = "password";
String table = "mytable";
String targetDirectory = "/user/hadoop/mydata";
String[] sqoopArgs = {
"import",
"--connect", jdbcUrl,
"--username", username,
"--password", password,
"--table", table,
"--target-dir", targetDirectory
};
Sqoop.runTool(sqoopArgs);
```
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Sqoop专栏:数据导入与导出的利器》是针对Sqoop工具的一系列文章的专栏。Sqoop是一款用于在Hadoop生态系统中进行结构化数据的传输工具,能够将关系型数据库中的数据快速导入到Hadoop中,并支持将Hadoop中的数据导出到关系型数据库中。本专栏以简介与安装指南为起点,从使用Sqoop进行数据导入和导出、数据过滤与转换技巧、与其他数据存储和计算组件的集成、数据压缩与优化、数据更新与合并操作等多个角度深入探讨Sqoop的各种应用场景和技术细节。此外,还涵盖了Sqoop在大数据场景下的实时数据同步、数据校验与容错处理、与各类数据库和NoSQL数据库的集成与数据交互、以及数据集成与数据湖构建等方面的内容。无论是初学者还是有一定经验的开发人员,都可以通过本专栏全面了解Sqoop的使用技巧,并掌握如何在大数据环境中高效地进行数据导入和导出的方法。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【实战演练】通过强化学习优化能源管理系统实战
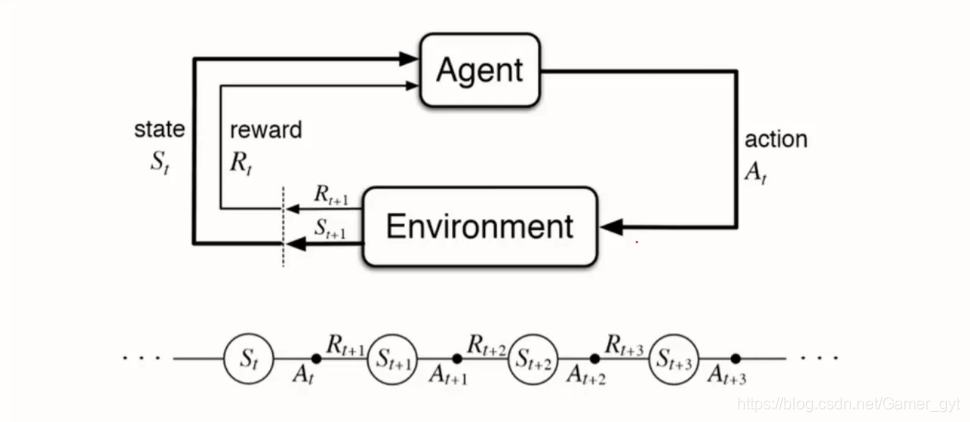
# 2.1 强化学习的基本原理
强化学习是一种机器学习方法,它允许智能体通过与环境的交互来学习最佳行为。在强化学习中,智能体通过执行动作与环境交互,并根据其行为的
Python Excel数据分析:统计建模与预测,揭示数据的未来趋势
# 1. Python Excel数据分析概述**
**1.1 Python Excel数据分析的优势**
Python是一种强大的编程语言,具有丰富的库和工具,使其成为Excel数据分析的理想选择。通过使用Python,数据分析人员可以自动化任务、处理大量数据并创建交互式可视化。
**1.2 Python Excel数据分析库**
【实战演练】构建简单的负载测试工具

# 1. 负载测试基础**
负载测试是一种性能测试,旨在模拟实际用户负载,评估系统在高并发下的表现。它通过向系统施加压力,识别瓶颈并验证系统是否能够满足预期性能需求。负载测试对于确保系统可靠性、可扩展性和用户满意度至关重要。
# 2. 构建负载测试工具
### 2.1 确定测试目标和指标
在构建负载测试工具之前,至关重要的是确定测试目标和指标。这将指导工具的设计和实现。以下是一些需要考虑的关键因素:
Python脚本调用与区块链:探索脚本调用在区块链技术中的潜力,让区块链技术更强大

# 1. Python脚本与区块链简介**
**1.1 Python脚本简介**
Python是一种高级编程语言,以其简洁、易读和广泛的库而闻名。它广泛用于各种领域,包括数据科学、机器学习和Web开发。
**1.2 区块链简介**
区块链是一种分布式账本技术,用于记录交易并防止篡改。它由一系列称为区块的数据块组成,每个区块都包含一组交易和指向前一个区块的哈希值。区块链的去中心化和不可变性使其
【实战演练】虚拟宠物:开发一个虚拟宠物游戏,重点在于状态管理和交互设计。

# 2.1 虚拟宠物的状态模型
### 2.1.1 宠物的基本属性
虚拟宠物的状态由一系列基本属性决定,这些属性描述了宠物的当前状态,包括:
- **生命值 (HP)**:宠物的健康状况,当 HP 为 0 时,宠物死亡。
- **饥饿值 (Hunger)**:宠物的饥饿程度,当 Hunger 为 0 时,宠物会饿死。
- **口渴
【实战演练】深度学习在计算机视觉中的综合应用项目

# 1. 计算机视觉概述**
计算机视觉(CV)是人工智能(AI)的一个分支,它使计算机能够“看到”和理解图像和视频。CV 旨在赋予计算机人类视觉系统的能力,包括图像识别、对象检测、场景理解和视频分析。
CV 在广泛的应用中发挥着至关重要的作用,包括医疗诊断、自动驾驶、安防监控和工业自动化。它通过从视觉数据中提取有意义的信息,为计算机提供环境感知能力,从而实现这些应用。
# 2.1 卷积
【进阶】数据库事务:概念与实践

# 1. 数据库事务基础**
数据库事务是一组原子性的数据库操作,要么全部执行成功,要么全部失败。事务的概念对于确保数据库数据的完整性和一致性至关重要。
在数据库系统中,事务
【实战演练】前沿技术应用:AutoML实战与应用

# 1. AutoML概述与原理**
AutoML(Automated Machine Learning),即自动化机器学习,是一种通过自动化机器学习生命周期
【实战演练】综合自动化测试项目:单元测试、功能测试、集成测试、性能测试的综合应用

# 2.1 单元测试框架的选择和使用
单元测试框架是用于编写、执行和报告单元测试的软件库。在选择单元测试框架时,需要考虑以下因素:
* **语言支持:**框架必须支持你正在使用的编程语言。
* **易用性:**框架应该易于学习和使用,以便团队成员可以轻松编写和维护测试用例。
* **功能性:**框架应该提供广泛的功能,包括断言、模拟和存根。
* **报告:**框架应该生成清
【实战演练】时间序列预测项目:天气预测-数据预处理、LSTM构建、模型训练与评估

# 1. 时间序列预测概述**
时间序列预测是指根据历史数据预测未来值。它广泛应用于金融、天气、交通等领域,具有重要的实际意义。时间序列数据通常具有时序性、趋势性和季节性等特点,对其进行预测需要考虑这些特性。
# 2. 数据预处理
### 2.1 数据收集和清洗
#### 2.1.1 数据源介绍
时间序列预测模型的构建需要可靠且高质量的数据作为基础。数据源的选择至关重要,它将影响模型的准确性和可靠性。常见的时序数据源包括:
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )