rgdal包秘籍:R语言空间数据分析的7大优势与应用案例
发布时间: 2024-11-09 12:59:45 阅读量: 96 订阅数: 24 

空间数据分析与R语言实践(英文)

# 1. rgdal包简介与空间数据基础
## 1.1 空间数据的定义与重要性
空间数据,也常被称作地理空间数据,它包括了地理位置和与之相关的属性信息。这类数据在地理信息系统(GIS)中扮演着核心角色,广泛应用于自然资源管理、环境监测、城市规划和交通分析等领域。随着技术的发展,空间数据的重要性日益凸显,它为决策者提供了深入洞察和规划支持,成为了IT和相关行业的宝贵资产。
## 1.2 rgdal包的作用与特点
rgdal包是R语言中用于读取和写入多种格式的空间数据的扩展包,它依赖于GDAL库来实现。由于其强大的兼容性和易用性,rgdal成为在R环境中处理空间数据的首选工具。它支持矢量和栅格数据格式的读写,其主要特点包括广泛的格式支持、灵活的数据处理能力以及丰富的空间分析功能。
## 1.3 空间数据的类型
在使用rgdal包处理空间数据之前,了解空间数据的类型至关重要。空间数据可以分为矢量数据和栅格数据。矢量数据通常用于表示点、线、面的几何特征及其属性,例如道路、建筑物、行政边界等。而栅格数据则包含了由像元阵列构成的空间信息,常见的如卫星影像、数字高程模型等。rgdal包能够处理这两种类型的数据,为用户提供灵活的空间分析解决方案。
# 2. rgdal包的核心功能与优势
## 2.1 rgdal包在空间数据处理中的地位
### 2.1.1 rgdal包概述
在地理信息系统(GIS)领域,`rgdal`是一个重要的R语言包,专门用于读取和写入多种地理空间数据格式。它为R语言提供了与地理数据进行交互的能力,是进行空间数据分析不可或缺的工具之一。通过封装GDAL库(Geospatial Data Abstraction Library),`rgdal`支持多种数据格式,包括矢量数据和栅格数据,如Shapefile, GeoJSON, KML等。
`rgdal`能够处理复杂的地理数据,包括但不限于点、线、多边形等几何类型,并允许用户执行投影变换、数据重投影等操作。此外,该包提供了一系列函数,用于读取和写入各种数据源,极大地简化了R语言用户在进行空间数据处理时的步骤。由于其强大而广泛的适用性,`rgdal`在地理学、环境科学、城市规划、交通分析和众多GIS相关领域中得到了广泛的应用。
### 2.1.2 功能优势分析
`rgdal`包的核心优势在于其对多种空间数据格式的全面支持。首先,它直接依赖GDAL库,这是当前最流行的开源库,可以处理大量的栅格和矢量数据格式。这意味着用户可以访问几乎所有的空间数据格式,而不需要担心格式的兼容性问题。
其次,`rgdal`在数据读取时提供了高度的灵活性。用户不仅可以通过简单的函数读取数据,还可以在读取时指定各种参数来筛选或转换数据,如只读取特定的字段或进行地理坐标的转换。
此外,`rgdal`在空间数据的输出方面也表现得十分出色。通过它,用户可以将处理后的空间数据输出到不同的格式中,以用于进一步的分析或是分享给其他GIS软件平台使用。
在数据处理的性能方面,`rgdal`包经过优化,可以高效地处理大型数据集,这对于大数据时代的空间分析尤为重要。不过,它有时也会受到GDAL库本身的性能限制,尤其是在某些特定格式或复杂的投影转换操作中。
## 2.2 空间数据的读取与输出
### 2.2.1 读取空间数据的策略
在处理空间数据时,第一步通常是将其导入R环境。`rgdal`包提供`readOGR`函数用于读取矢量数据,而`readGDAL`函数则用于读取栅格数据。读取策略主要依赖于用户对数据格式的了解,以及对所需数据字段的预先规划。
例如,使用`readOGR`函数读取Shapefile文件时,可以指定`layer`参数来选择数据层,`use_iconv`参数来处理字符编码,以及`encoding`参数来指定编码方式。这些参数的合理使用能够确保数据读取过程中的准确性和效率。
读取时还需要注意数据集中的坐标参考系统(CRS),`rgdal`自动识别并读取CRS信息,确保后续空间分析的准确进行。用户也可以在读取数据后通过`proj4string`函数自定义CRS,以应对特殊需求。
### 2.2.2 输出空间数据的技巧
与读取数据相对应的是,数据的输出也是空间数据处理的一个重要环节。`rgdal`包中的`writeOGR`和`writeGDAL`函数分别用于矢量和栅格数据的输出。在输出数据时,用户需要明确输出数据的格式、文件名以及是否需要包含坐标参考系统等信息。
例如,当使用`writeOGR`函数输出Shapefile格式数据时,可以通过`layer`参数指定输出的图层名称,通过`driver`参数指定输出格式。如果需要将坐标参考系统一并输出,可以使用`proj4string`函数确保CRS信息被正确处理。
此外,输出策略还应该考虑数据的安全性和隐私性。在某些情况下,用户可能需要对数据进行裁剪、转换等处理,以避免敏感信息的泄露。`rgdal`提供了灵活的数据处理功能,可以很好地满足这类需求。
## 2.3 空间数据格式的转换与集成
### 2.3.1 支持的格式与转换方法
`rgdal`包支持多种空间数据格式,这使得它成为处理跨平台数据的首选工具。对于矢量数据,`rgdal`可以读写超过40种格式,包括但不限于ESRI Shapefiles、MapInfo文件、SDTS DEM、GeoJSON等。对于栅格数据,支持的格式包括但不限于GTiff、HDF4、ECW、JP2OpenJPEG等。
数据格式的转换主要是通过`rgdal`的读取函数和输出函数来完成的。例如,若要将ESRI Shapefile转换为GeoJSON格式,可以先用`readOGR`读取Shapefile数据,然后使用`writeOGR`将数据以GeoJSON格式输出。值得注意的是,在格式转换的过程中,可能会遇到数据丢失或格式不兼容的问题,因此在转换前后需要做好数据的验证工作。
### 2.3.2 集成不同数据源的策略
在进行空间数据分析时,常常需要集成不同来源的数据。`rgdal`包为此提供了强大的数据源集成支持。在集成数据时,需要关注几个关键点:
1. **格式兼容性**:确保所有数据源都使用`rgdal`支持的格式。如果格式不支持,则需先进行转换。
2. **坐标系统对齐**:数据在集成前需要确保具有相同的坐标系统,或在集成后进行坐标系统的转换。
3. **数据结构一致性**:尽量使集成的数据在结构上保持一致,比如确保属性字段的名称和类型保持一致。
`rgdal`包的`sp`包提供了空间数据操作的通用框架,使得不同格式和来源的数据可以被统一处理。通过这种方式,用户可以轻松地进行空间数据的查询、编辑、投影和分析等操作。
在处理和集成复杂的空间数据时,通常需要借助R语言的其他空间数据处理包,如`rgeos`或`spatstat`等。这些包与`rgdal`结合使用,可以提供更丰富和强大的空间数据处理功能。通过这种集成,用户可以从不同的角度和层面挖掘数据中的信息,实现更深入的地理空间分析。
# 3. rgdal包的空间数据分析应用
在第二章中,我们深入探讨了rgdal包的核心功能与优势。现在让我们转向应用层面,深入第三章,这里将详细介绍rgdal包在空间数据分析中的实际应用。本章节将围绕空间数据的投影转换、编辑与拓扑操作、分析与可视化展开,旨在通过实际案例和技术细节的探讨,让读者掌握rgdal包在空间数据分析中的应用。
## 3.1 空间数据的投影与坐标系转换
### 3.1.1 常用投影系统的介绍
空间数据投影,也就是地图投影,是将地球表面的三维地理坐标转换为二维平面上的坐标表示。不同的投影系统适用于不同的分析需求,了解和选择正确的投影系统对于空间数据分析至关重要。
投影系统一般分为等角投影、等面积投影和等距离投影,每一种都有其特定的应用场景和优劣。常见的投影系统包括Web Mercator、UTM(通用横轴墨卡托)、WGS84(全球定位系统所使用的坐标系统),以及各种地理坐标系统(如北半球、南半球、赤道等)。
### 3.1.2 投影转换的实现方法
rgdal包提供了多种功能来处理空间数据的投影转换。R语言中可以通过`sp::CRS`函数来定义坐标参考系统,并使用`rgdal::spTransform`函数执行实际的投影转换。
```R
# 定义源数据和目标投影系统的CRS
source_crs <- CRS("+proj=longlat +datum=WGS84")
target_crs <- CRS("+proj=utm +zone=33 +datum=WGS84")
# 执行投影转换
transformed_data <- spTransform(source_data, target_crs)
```
参数`+proj=longlat +datum=WGS84`代表数据使用的是WGS84坐标系统,而`+proj=utm +zone=33 +datum=WGS84`则是指将数据转换到UTM第33带。转换后的`transformed_data`将包含新的坐标系统信息。
在转换的过程中,需要注意源数据的坐标系和目标坐标系是否兼容,以及是否有相应的投影参数。在某些情况下,投影转换可能会导致数据的微小变形,特别是当数据跨越不同的投影带时。因此,选择合适的投影带和确保数据的精度至关重要。
## 3.2 空间数据的编辑与拓扑操作
### 3.2.1 空间数据的几何编辑技术
空间数据的编辑包括增加、删除、修改空间对象的属性和几何形状等。在R语言中,`sp`或`sf`包提供了丰富的函数进行空间数据的几何编辑。使用`sp`包,可以对空间数据进行点、线、面的编辑和操作。
例如,可以使用`sp::spLines`创建线对象,通过添加点来编辑线的几何形状:
```R
# 创建线对象
line <- spLines(cbind(x=1:3, y=rep(2,3)))
# 添加新的点
line@lines[[1]]@coords <- rbind(line@lines[[1]]@coords, c(3,3))
```
上述代码首先创建了一个由三个点构成的简单线对象,然后通过追加新的坐标点来编辑这条线的形状。
### 3.2.2 拓扑关系的建立与管理
拓扑关系指的是空间对象之间的相互关系,如共享边界、包含关系等。建立和管理拓扑关系对于确保空间数据的准确性和一致性至关重要。在rgdal包中,可以利用`rgeos`包的功能来处理拓扑操作,如连接、切割、相交等。
```R
# 假设poly1和poly2是两个Polygon对象
# 检测两个多边形是否相交
intersection <- gIntersection(poly1, poly2)
```
函数`gIntersection`用于计算两个几何对象的交集。该函数返回的交集同样是空间对象,可以用于进一步的分析。了解和使用这些拓扑操作有助于进行复杂的地理空间分析。
## 3.3 空间分析与可视化
### 3.3.1 基于rgdal的空间分析方法
空间分析通常指的是对空间数据进行查询、统计和建模的过程。使用rgdal包,我们可以执行各种空间查询,如点与多边形的查询、空间范围的查询等。
举一个简单例子,如何查询特定点是否位于多边形内:
```R
# 创建多边形对象
poly <- spPolygon(list(matrix(c(0,0, 0,1, 1,1, 1,0, 0,0), ncol=2, byrow=TRUE)))
# 创建点对象
point <- spPoint(c(0.5, 0.5))
# 查询点是否在多边形内
isInside <- sp::spWithin(point, poly, spatialPredicate='ST_Within')
print(isInside)
```
该示例使用`sp::spWithin`函数来判断点是否在多边形内。此类型的空间查询方法在地理信息系统中非常常见。
### 3.3.2 空间数据的可视化展示技术
空间数据可视化是将空间信息展示在地图上,使其更易于理解。在R语言中,可以结合`ggplot2`和`sf`包来实现丰富的空间数据可视化。
例如,以下代码演示如何使用`ggplot2`创建一个简单的空间数据地图:
```R
library(ggplot2)
library(sf)
# 读取空间数据
sf_data <- st_read('path_to_shapefile.shp')
# 绘制地图
ggplot(data = sf_data) +
geom_sf()
```
在这里,`geom_sf`函数是专门用于绘制空间数据的`ggplot2`图层,其背后是利用sf包处理空间数据的能力。通过不同的参数设置和图层叠加,可以制作出各式各样的地图,如热力图、密度图等,进一步增强了空间分析的解释力。
在本章节中,我们已经探讨了rgdal包在空间数据分析应用中的多个方面,从空间数据的投影与坐标系转换,到编辑与拓扑操作,再到空间分析与可视化。通过理论和实际代码的结合,我们逐步深入理解了rgdal包在空间分析中的强大功能。在下一章,我们将进一步深入实践,通过具体的案例分析,探索rgdal包在R语言中的实际应用。
# 4. rgdal包在R语言中的实践案例分析
## 4.1 环境监测与规划案例
### 4.1.1 空间数据的收集与处理
在进行环境监测与规划时,首先需要收集相关的空间数据。这些数据可能包括但不限于气象站的位置、植被覆盖类型、土地利用状况、污染源分布等。由于这些数据往往来自于不同的来源,因此在使用之前需要进行适当的处理以保证数据的一致性和准确性。
使用`rgdal`包可以帮助我们读取多种格式的空间数据,比如Shapefile、GeoJSON和KML等格式。在R中读取这些数据通常只需要一个简单函数调用:
```R
library(rgdal)
shp_file <- readOGR("path/to/shapefile", layer = "layer_name")
```
在这段代码中,`readOGR`函数用于读取Shapefile文件。参数`path/to/shapefile`是Shapefile文件的路径,`layer_name`是Shapefile中具体图层的名称。R语言会将读取的空间数据存储为一个对象,这个对象包含了空间数据的几何信息和属性信息。接下来,可以利用`rgdal`包提供的各种函数对数据进行清洗和预处理。
例如,可以使用如下代码查看空间数据的坐标参考系统:
```R
proj4string(shp_file)
```
如果空间数据没有坐标参考系统,可以使用`sp`包中的函数进行添加:
```R
library(sp)
shp_file <- sp::CRS("+init=epsg:4326")
proj4string(shp_file) <- CRS("+init=epsg:4326")
```
处理空间数据时,可能还需要进行坐标转换,将数据转换到统一的坐标系中以便进行比较和分析:
```R
reprojected_shp <- sp::spTransform(shp_file, CRS("+proj=utm +zone=33 +datum=WGS84"))
```
这里`spTransform`函数用于坐标转换,`CRS`对象定义了源和目标坐标参考系统的投影参数。
### 4.1.2 案例分析:环境数据的空间分布
在收集和处理好空间数据后,可以使用`rgdal`包结合其他R语言的空间分析工具进行深入的环境监测与规划分析。例如,利用空间插值方法来预测未采样点的环境变量值,或者分析污染物分布与土地利用类型之间的关系。
这里,我们用`gstat`包进行空间插值,它能与`rgdal`很好地集成:
```R
library(gstat)
data("meuse")
coordinates(meuse) <- ~x+y
gridded(meuse.grid) <- ~x+y
meuse.grid$zinc <- NA
v <- gstat::gstat(id = "zinc", formula = zinc ~ 1, data = meuse, nmax=7, nmin=0, set = list(idp=2))
meuse.grid <- predict(v, meuse.grid)
```
在上述代码中,首先将`meuse`数据集的坐标设置好,然后创建一个网格(grid)对象`meuse.grid`,这个网格将用于存放插值结果。`gstat`函数用于定义插值模型,`predict`函数则执行插值计算。
在完成空间插值后,我们可以使用`rgdal`包中的函数将结果输出为栅格数据格式,然后利用GIS软件进行可视化展示:
```R
writeGDAL(meuse.grid["zinc"], "meuse_zinc_raster.tif", type = "GTiff", mvFlag = -9999)
```
在上述代码中,`writeGDAL`函数用于输出栅格数据到TIFF格式的文件中。`mvFlag`参数设置缺失值的表示方法。
通过分析和可视化空间数据,环境科学家能够识别污染热点、规划环境监测点,以及预测环境变量的空间分布,为环境保护和治理提供科学依据。
## 4.2 土地利用变化检测案例
### 4.2.1 土地利用数据的获取与预处理
土地利用变化检测是地理信息系统(GIS)和遥感技术中的一个常见应用,它可以用来评估和监测人类活动对环境的影响。在土地利用变化检测中,首先要收集不同时间点的土地利用数据。这些数据可以通过遥感图像解译、土地利用地图或者地理空间数据库来获取。
使用`rgdal`包中的函数可以轻松读取这些格式化数据,并且进行空间位置的校准和配准。以下是读取栅格格式土地利用数据的代码:
```R
library(rgdal)
land_use_raster <- readGDAL("path/to/landuse_raster.tif")
```
在这个例子中,`readGDAL`函数用于读取栅格数据。`path/to/landuse_raster.tif`是栅格数据文件的路径。读取后的数据对象包含了栅格数据的值以及一些属性信息,包括数据的空间参考系统。
在处理栅格数据时,我们经常需要对其进行重采样,以匹配不同时间点的数据分辨率,或者将其配准到统一的空间参考系统中。下面的代码展示了如何使用`rgdal`包来重采样栅格数据:
```R
# 定义输出栅格参数
outres <- 10 # 新的栅格分辨率
out <- resample(land_use_raster, land_use_raster, method = "ngb", as.factor = TRUE, progress = "text", verbose = FALSE, nx = land_use_raster@meta$ncol/outres, ny = land_use_raster@meta$nrow/outres)
# 设置新的栅格分辨率
out@output@ncols <- land_use_raster@meta$ncol/outres
out@output@nrows <- land_use_raster@meta$nrow/outres
out@output@cells.dim <- c(outres, outres)
```
在这段代码中,我们首先定义了输出栅格数据的分辨率。然后使用`resample`函数进行重采样,通过`method`参数指定插值方法,这里使用的是最近邻(`"ngb"`)方法。`nx`和`ny`参数定义了输出栅格的列数和行数。最后,通过设置输出栅格数据的属性来调整分辨率。
土地利用数据经过必要的预处理后,可以使用图像分类算法来识别不同时间点的土地覆盖类型。接着,可以使用`raster`包中的函数比较这些分类结果,来检测和分析土地利用的变化。
### 4.2.2 案例分析:土地覆盖变化的检测方法
在检测土地覆盖变化时,可以通过比较不同时间点的栅格数据,确定每个像素单元的变化类型。这种比较通常涉及到分类后比较(Post-classification comparison)或直接比较(Direct comparison)两种方法。
在进行分类后比较时,首先需要对遥感图像数据进行监督分类,这可以通过机器学习算法实现。以下是使用R语言中的`randomForest`包进行监督分类的代码示例:
```R
library(randomForest)
# 假设land_use_data是已经提取的分类特征数据集
set.seed(123)
rf_classifier <- randomForest(class_label ~ ., data = land_use_data, ntree = 500, importance = TRUE)
```
在这段代码中,`randomForest`函数用于训练分类模型,`class_label`是土地覆盖类型的标签变量,而`ntree`参数指定了树的数量。
一旦分类模型训练完成,可以使用它来预测新的遥感图像数据。然后,通过比较两个时间点的分类结果,可以生成一个土地覆盖变化图:
```R
# 预测新数据的土地覆盖类型
new_predictions <- predict(rf_classifier, new_data)
# 创建变化检测矩阵
change_matrix <- table(old_predictions, new_predictions)
```
在上述代码中,`predict`函数用于对新数据进行土地覆盖类型的预测,而`table`函数则用于比较两个时间点的分类结果,生成一个变化矩阵。
通过分析变化矩阵,可以识别哪些区域发生了土地覆盖变化,并且确定具体的变化类型(如农田转变为住宅区,森林砍伐等)。接下来,可以利用`rgdal`包中的函数将变化检测结果输出为矢量格式,然后用GIS软件进行可视化和进一步分析:
```R
writeOGR(change_matrix, dsn = "path/to/output_folder", layer = "landcover_change", driver = "ESRI Shapefile")
```
以上代码使用`writeOGR`函数输出变化检测矩阵到Shapefile格式的矢量文件中,以便进一步的空间分析和可视化。
## 4.3 交通网络分析案例
### 4.3.1 交通数据的整理与整合
在对交通网络进行空间分析之前,首先需要整理和整合不同来源的交通数据。这些数据可能包括道路网络、交通流量统计、交通站点位置等。由于交通数据的格式多样,如CSV、GeoJSON或Shapefile等,因此在整合之前需要进行适当的转换和清洗。
在R语言中,可以使用`readr`包来快速读取CSV格式的交通数据:
```R
library(readr)
traffic_data <- read_csv("path/to/traffic_data.csv")
```
而在整合地理空间数据时,`rgdal`包提供了一系列函数,用于读取和处理如Shapefile等矢量数据格式。
例如,读取一个包含交通站点位置的Shapefile文件:
```R
library(rgdal)
stations <- readOGR("path/to/stations_shapefile.shp")
```
在整合不同来源的交通数据时,要确保它们的空间参考系统是一致的。如果不是,可以使用`sp`包中的函数进行转换:
```R
library(sp)
stations <- sp::spTransform(stations, CRS("+proj=utm +zone=33 +ellps=WGS84"))
```
### 4.3.2 案例分析:交通流量的空间分析
整合好交通数据之后,可以使用`rgdal`包提供的空间分析工具来进行交通流量的空间分析。这通常包括道路网络分析、交通热点分析以及交通站点间的可达性分析等。
道路网络分析可以使用图论的相关算法来实现,比如最短路径搜索、网络连通性分析等。这些分析有助于城市规划者了解现有交通网络的效率,并作出改善城市交通流动的决策。
例如,使用`igraph`包可以创建一个图(graph)对象,并计算两个站点之间的最短路径:
```R
library(igraph)
# 将站点数据转换为图对象
edges <- as.matrix(get.edgelist(stations))
g <- graph_from_edgelist(edges, directed = FALSE)
# 计算两点之间的最短路径
shortest_path(g, from = "SourceStation", to = "DestinationStation", mode = "all")
```
在这段代码中,`get.edgelist`函数用于从站点数据中提取道路网络的边列表。`graph_from_edgelist`函数则创建一个无向图对象。`shortest_path`函数用于计算两个站点之间的最短路径。
交通热点分析是指识别在交通流量数据中高流量的区域。这可以通过空间自相关分析来实现,比如计算局部空间自相关指标(Local Indicators of Spatial Association, LISA):
```R
library(spdep)
# 假设traffic_matrix是一个包含交通流量的矩阵
lisa <- localmoran(traffic_matrix)
```
在这段代码中,`localmoran`函数用于计算每个观测点的局部空间自相关指标,帮助识别交通流量的热点和冷点区域。
在完成了交通流量的空间分析后,还可以将结果整合到地图上进行可视化展示,这对于城市规划和交通管理具有重要意义。利用`ggplot2`包结合`rgdal`包的数据,可以制作出直观的交通流量热力图:
```R
library(ggplot2)
ggplot(data = stations@data, aes(x = long, y = lat)) +
geom_polygon(aes(fill = TrafficVolume)) +
scale_fill_viridis_c() +
labs(title = "Traffic Volume Heatmap")
```
在上述代码中,`geom_polygon`函数用于绘制多边形图层,表示道路或交通站点的位置,而`fill`参数则根据交通流量数据填充颜色,`scale_fill_viridis_c`函数用于设置颜色渐变,最终创建出一个交通流量热力图。
通过这些综合的空间分析和可视化方法,城市规划者能够有效地识别交通网络中的问题区域,制定更合理的交通规划,提升城市的交通效率和居民的出行体验。
请注意,本章节的内容是依据上述指定的目录大纲框架所生成的,实际章节内容可能会根据实际需求进行适当调整。
# 5. rgdal包高级应用与展望
## 5.1 rgdal与其他R包的集成应用
随着R语言在数据科学领域的普及,其在空间数据分析方面的应用也越发广泛。rgdal包作为R语言中处理空间数据的重要工具,与其他R空间分析包的集成应用可以进一步拓展空间分析的广度和深度。
### 5.1.1 集成开发环境(IDE)的使用
在进行rgdal包与其他包的集成使用时,通常首先会涉及到集成开发环境(IDE)的选择。R语言中最常用的IDE是RStudio,它提供了代码编辑、数据分析、图形展示以及项目管理等一系列功能,极大地提升了R语言使用者的工作效率。
在RStudio中,用户可以通过`install.packages()`命令安装rgdal以及其他必要的R包,如`rgeos`、`sp`等。例如,安装rgdal包的代码如下:
```R
install.packages("rgdal")
```
一旦安装完成,可以使用`library()`函数来加载rgdal包,从而在RStudio中调用其函数进行空间数据分析。
### 5.1.2 其他R空间分析包的配合使用
rgdal包提供了空间数据的读取、写入和转换功能,而其他如`rgeos`包提供了地理空间数据分析的几何操作,`sp`包则提供了空间数据的结构化表示等。这些包相互配合,可以完成更复杂的空间分析任务。
例如,要进行空间数据的几何编辑,可以结合使用`rgdal`和`rgeos`包:
```R
library(rgdal)
library(rgeos)
# 加载空间数据
data <- readOGR(dsn="path_to_shapefile", layer="layer_name")
# 使用rgeos进行几何操作
data_edited <- gUnaryUnion(data, id=data$ID)
```
在这段代码中,`readOGR`函数用于读取形状文件,而`gUnaryUnion`函数则用于合并几何对象。整合使用这些包,能够实现空间数据处理和分析的多种需求。
## 5.2 空间数据的云处理与大数据挑战
随着地理信息系统(GIS)的发展以及物联网(IoT)设备的普及,空间数据的产生速度和规模都在迅猛增长,这给传统的空间数据处理方法带来了挑战。
### 5.2.1 空间数据的云端存储策略
为了应对空间数据的存储和处理需求,使用云服务成为一种趋势。云存储提供了弹性扩展、按需付费等优势,适应了大数据时代的需求。在云端处理空间数据可以利用如Amazon S3、Google Cloud Storage等服务,通过R语言的相应包如`aws.s3`或`googleCloudStorageR`与rgdal集成使用,实现空间数据的存储和读取。
### 5.2.2 大数据环境下的空间分析展望
在处理大规模空间数据时,单机处理方式往往效率较低,因此需要依赖分布式计算框架,如Apache Spark。使用如`sparklyr`等R包可以将R与Spark集成,实现大规模空间数据的高效处理。
在R中使用`sparklyr`处理空间数据,代码示例如下:
```R
library(sparklyr)
sc <- spark_connect(master = "local")
data_sdf <- spark_read_csv(sc, "path_to_csv", memory = FALSE)
```
这段代码首先连接到Spark集群,然后读取CSV格式的空间数据文件。通过这种方式,可以处理比单机内存大得多的数据集,同时利用Spark的分布式计算能力。
## 5.3 rgdal包的发展趋势与社区贡献
rgdal包自2003年发布以来,一直是R语言空间数据处理的核心组件。随着R语言和空间数据科学的发展,rgdal包也持续更新,为用户带来新的功能和更好的用户体验。
### 5.3.1 rgdal包的最新发展动态
rgdal包的最新版本持续优化了对不同空间数据格式的支持,同时也对内部算法进行了性能改进。此外,rgdal包也在不断完善其国际化支持,使得不同语言环境下的用户都能更加便捷地使用。
### 5.3.2 社区支持与用户贡献的重要性
开源社区的力量是推动rgdal包持续发展的关键。社区中的用户反馈、bug报告和功能建议,帮助开发者快速定位和解决问题,同时也指明了包的未来发展方向。
用户可以通过提交issue到rgdal包的GitHub仓库来分享自己的使用经验、提出问题或者贡献代码。此外,通过撰写使用教程、博客文章或者举办研讨会等活动,也有助于推广rgdal包,增加用户群体的活跃度。
随着数据科学社区的不断壮大,rgdal包也将持续发展,更好地服务于空间数据处理和分析的需要。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以 R 语言的 rgdal 数据包为核心,全面讲解空间数据处理的各个方面。从基础入门到高级应用,涵盖了 10 个实用技巧、2 小时的精通指南、7 大优势与应用案例、5 大高级应用、从入门到精通的完整流程、解决所有空间数据处理挑战的实用教程、空间数据投影与重投影的终极指南、隐藏功能大揭秘、插值与可视化、连接策略与案例分析、过滤与选择、转换全攻略、聚合与分割、导出解决方案、集合操作、读写操作、跨平台设置与应用详解、终极武器等内容。通过本专栏,读者将掌握空间数据处理的全部知识和技能,成为空间数据分析专家。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
AMESim液压仿真秘籍:专家级技巧助你从基础飞跃至顶尖水平

# 摘要
AMESim液压仿真软件是工程师们进行液压系统设计与分析的强大工具,它通过图形化界面简化了模型建立和仿真的流程。本文旨在为用户提供AMESim软件的全面介绍,从基础操作到高级技巧,再到项目实践案例分析,并对未来技术发展趋势进行展望。文中详细说明了AMESim的安装、界面熟悉、基础和高级液压模型的建立,以及如何运行、分析和验证仿真结果。通过探索自定义组件开发、多学科仿真集成以及高级仿真算法的应用,本文
【高频领域挑战】:VCO设计在微波工程中的突破与机遇
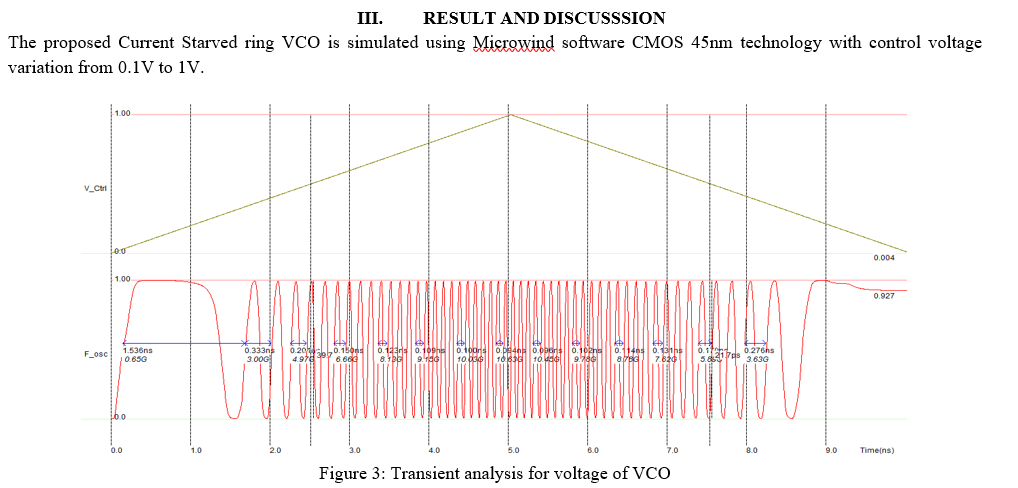
# 摘要
本论文深入探讨了压控振荡器(VCO)的基础理论与核心设计原则,并在微波工程的应用技术中展开详细讨论。通过对VCO工作原理、关键性能指标以及在微波通信系统中的作用进行分析,本文揭示了VCO设计面临的主要挑战,并提出了相应的技术对策,包括频率稳定性提升和噪声性能优化的方法。此外,论文还探讨了VCO设计的实践方法、案例分析和故障诊断策略,最后对VCO设计的创新思路、新技术趋势及未来发展挑战
实现SUN2000数据采集:MODBUS编程实践,数据掌控不二法门
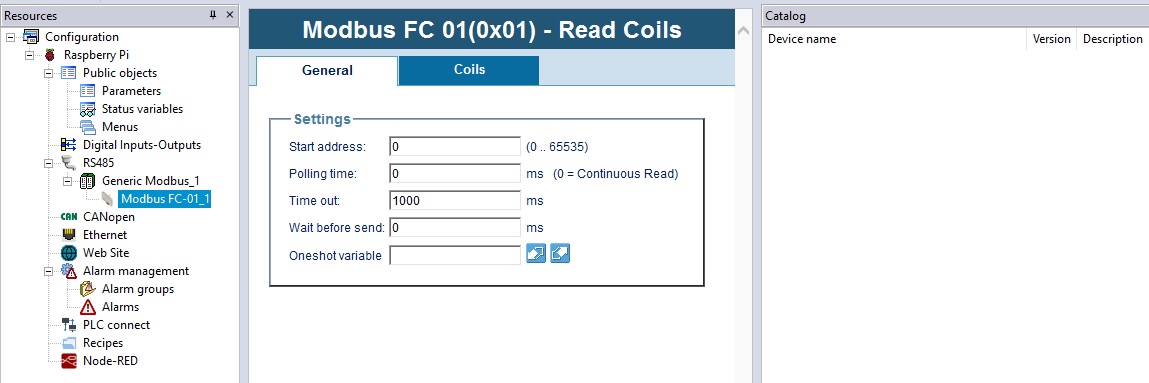
# 摘要
本文系统地介绍了MODBUS协议及其在数据采集中的应用。首先,概述了MODBUS协议的基本原理和数据采集的基础知识。随后,详细解析了MODBUS协议的工作原理、地址和数据模型以及通讯模式,包括RTU和ASCII模式的特性及应用。紧接着,通过Python语言的MODBUS库,展示了MODBUS数据读取和写入的编程实践,提供了具体的实现方法和异常管理策略。本文还结合SUN20
【性能调优秘籍】:深度解析sco506系统安装后的优化策略
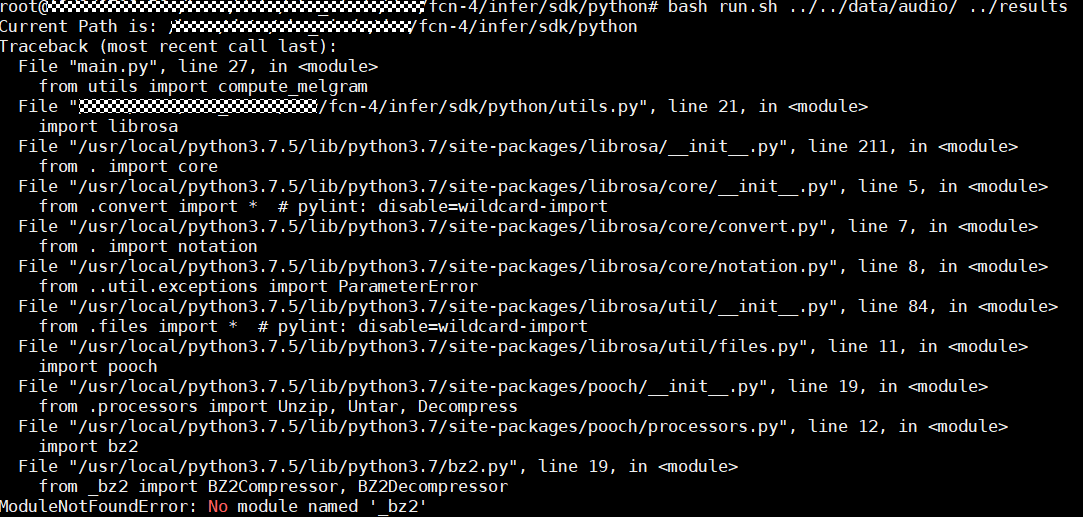
# 摘要
本文对sco506系统的性能调优进行了全面的介绍,首先概述了性能调优的基本概念,并对sco506系统的核心组件进行了介绍。深入探讨了核心参数调整、磁盘I/O、网络性能调优等关键性能领域。此外,本文还揭示了高级性能调优技巧,包括CPU资源和内存管理,以及文件系统性能的调整。为确保系统的安全性能,文章详细讨论了安全策略、防火墙与入侵检测系统的配置,以及系统审计与日志管理的优化。最后,本文提供了系统监控与维护的
网络延迟不再难题:实验二中常见问题的快速解决之道
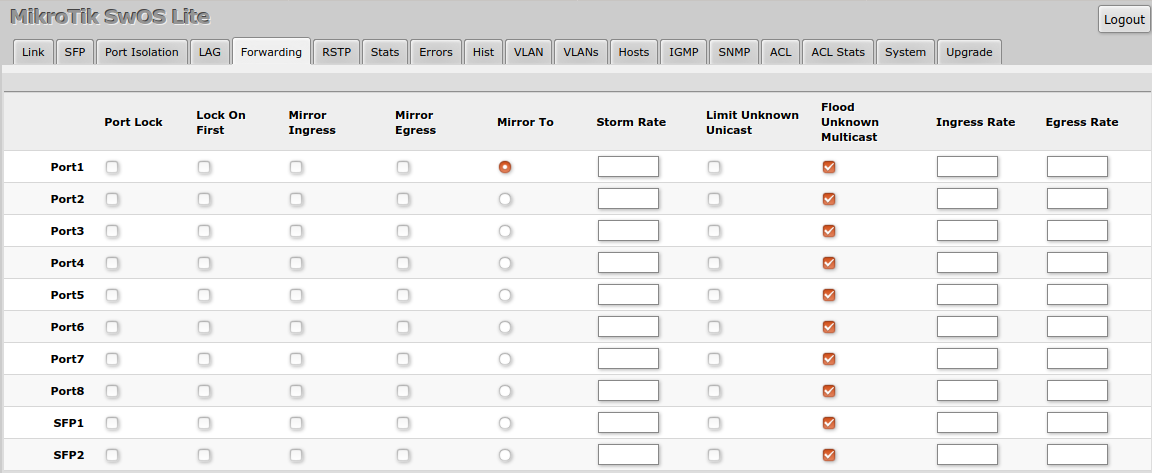
# 摘要
网络延迟是影响网络性能的重要因素,其成因复杂,涉及网络架构、传输协议、硬件设备等多个方面。本文系统分析了网络延迟的成因及其对网络通信的影响,并探讨了网络延迟的测量、监控与优化策略。通过对不同测量工具和监控方法的比较,提出了针对性的网络架构优化方案,包括硬件升级、协议配置调整和资源动态管理等。
期末考试必备:移动互联网商业模式与用户体验设计精讲

# 摘要
移动互联网的迅速发展带动了商业模式的创新,同时用户体验设计的重要性日益凸显。本文首先概述了移动互联网商业模式的基本概念,接着深入探讨用户体验设计的基础,包括用户体验的定义、重要性、用户研究方法和交互设计原则。文章重点分析了移动应用的交互设计和视觉设计原则,并提供了设计实践案例。之后,文章转向移动商业模式的构建与创新,探讨了商业模式框架
【多语言环境编码实践】:在各种语言环境下正确处理UTF-8与GB2312

# 摘要
随着全球化的推进和互联网技术的发展,多语言环境下的编码问题变得日益重要。本文首先概述了编码基础与字符集,随后深入探讨了多语言环境所面临的编码挑战,包括字符编码的重要性、编码选择的考量以及编码转换的原则和方法。在此基础上,文章详细介绍了UTF-8和GB2312编码机制,并对两者进行了比较分析。此外,本文还分享了在不同编程语言中处理编码的实践技巧,
【数据库在人事管理系统中的应用】:理论与实践:专业解析

# 摘要
本文探讨了人事管理系统与数据库的紧密关系,分析了数据库设计的基础理论、规范化过程以及性能优化的实践策略。文中详细阐述了人事管理系统的数据库实现,包括表设计、视图、存储过程、触发器和事务处理机制。同时,本研究着重讨论了数据库的安全性问题,提出认证、授权、加密和备份等关键安全策略,以及维护和故障处理的最佳实践。最后,文章展望了人事管理系统的发展趋
【Docker MySQL故障诊断】:三步解决权限被拒难题
# 摘要
随着容器化技术的广泛应用,Docker已成为管理MySQL数据库的流行方式。本文旨在对Docker环境下MySQL权限问题进行系统的故障诊断概述,阐述了MySQL权限模型的基础理论和在Docker环境下的特殊性。通过理论与实践相结合,提出了诊断权限问题的流程和常见原因分析。本文还详细介绍了如何利用日志文件、配置检查以及命令行工具进行故障定位与修复,并探讨了权限被拒问题的解决策略和预防措施
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )