RocksDB简介与基本原理解析
发布时间: 2024-02-24 20:57:14 阅读量: 124 订阅数: 26 

Python库 | rocksdb3-0.1.0-cp39-none-win32.whl
# 1. RocksDB概述
RocksDB是一个由Facebook开发的开源持久化键值存储引擎,它基于LevelDB进行了优化和拓展。RocksDB具有高性能、低延迟、可靠性强等特点,因此在大数据领域得到了广泛的应用。
## 1.1 RocksDB的历史和背景
RocksDB最早于2013年由Facebook开源,其初衷是为了提供一个高性能的存储引擎,以满足Facebook内部大规模数据处理的需求。随着RocksDB逐渐成熟和稳定,越来越多的公司和开发者开始关注和使用RocksDB,其社区也越来越活跃。
## 1.2 RocksDB的基本特性
RocksDB的基本特性包括:
- **高性能**:RocksDB采用了LSM树(Log-Structured Merge Tree)的存储结构,使得其在写入、读取等方面都具有非常高的性能。
- **低延迟**:RocksDB能够在毫秒级别内完成读写操作,适用于对延迟要求较高的场景。
- **可靠性强**:RocksDB支持数据的持久化存储,并具有良好的数据一致性和可靠性。
- **灵活性**:RocksDB支持强大的配置选项,能够适应不同的存储需求。
## 1.3 RocksDB在大数据领域的应用
RocksDB在大数据领域广泛应用于数据存储、日志采集、实时数据处理等场景,例如被用于Hadoop、Cassandra、Kafka等大数据系统的存储引擎,以及在互联网领域的实时数据处理系统中具有重要地位。
在接下来的章节中,我们将深入解析RocksDB的基本原理、性能优化、与其他存储引擎的对比以及具体的应用案例分析。
# 2. RocksDB基本原理解析
RocksDB作为一个高性能的开源存储引擎,在实际应用中具有广泛的价值。本章节将深入探讨RocksDB的基本原理,包括LSM树存储结构、缓存和压缩技术的应用,以及数据存储与读写流程的分析。
### 2.1 LSM树存储结构介绍
LSM树(Log-Structured Merge Tree)是RocksDB的核心存储结构之一,其优势在于写入性能高、数据追加顺序存储、读取效率较高等特点。LSM树由多个层级组成,包括内存中的MemTable和磁盘中的SSTable,通过后台合并操作将数据不断从MemTable导入到SSTable,实现数据的持久化存储和快速检索。
```java
// Java示例代码:LSM树的写入操作
RocksDB db = RocksDB.open("/path/to/database", new Options());
try (WriteBatch batch = new WriteBatch()) {
batch.put("key1", "value1");
batch.put("key2", "value2");
db.write(new WriteOptions(), batch);
}
// 写入成功后数据会被存入MemTable,在后台周期性地将MemTable中的数据写入磁盘的SSTable中
```
### 2.2 缓存和压缩技术在RocksDB中的应用
RocksDB在内存读写性能方面的优化,主要依赖于缓存和数据压缩技术。通过合理配置缓存大小、使用LRU算法等,可以提高数据的命中率,降低磁盘I/O操作。同时,RocksDB还支持多种数据压缩算法,如Snappy、Zlib等,可以有效减少数据在磁盘上的存储空间,提升存储效率。
```python
# Python示例代码:配置RocksDB的缓存参数
options = {
'write_buffer_size': 64 * 1024 * 1024,
'max_write_buffer_number': 3,
'target_file_size_base': 64 * 1024 * 1024
}
db = rocksdb.DB("/path/to/database", rocksdb.Options(**options))
# 数据写入时会根据配置的缓存大小和文件大小进行管理,提升数据读写效率
```
### 2.3 数据存储与读写流程分析
RocksDB的数据存储与读写流程主要包括数据写入、数据读取和数据删除等操作。在数据写入时,会先将数据写入MemTable,然后根据条件触发MemTable到磁盘的写入操作。数据读取时,先在MemTable中查找,如果未找到再去磁盘中的SSTable中查找。数据删除会标记为删除操作,而实际数据并不会立即从磁盘中删除,只是在后续的合并操作中才会真正删除过期数据。
综上所述,RocksDB通过LSM树的存储结构、缓存及压缩技术的应用,以及高效的数据存储与读写流程,实现了较高的性能和可靠性,适用于大数据场景下的存储需求。
# 3. RocksDB的性能优化
在第三章中,我们将深入探讨RocksDB的性能优化策略,包括数据压缩与存储优化策略、查询性能优化技巧以及写入性能优化策略。通过这些优化手段,我们可以更好地发挥RocksDB在大数据存储领域的优势,提升系统性能和效率。接下来,让我们逐一进行剖析。
#### 3.1 数据压缩与存储优化策略
在RocksDB中,数据的压缩是一项非常重要的性能优化策略。通过对数据进行压缩,可以减小数据存储空间的占用,降低I/O操作的负担,提升读写性能。RocksDB提供了多种压缩算法可供选择,用户可以根据实际场景和需求进行配置。在使用数据压缩时,需要注意在压缩和解压缩过程中可能带来的计算开销,需要权衡空间和时间开销。
```python
# 数据压缩配置示例
opts = rocksdb.Options()
opts.compression = rocksdb.SnappyCompression() # 选择Snappy压缩算法
db = rocksdb.DB("example.db", opts)
```
数据的存储优化策略也是影响RocksDB性能的重要因素之一。在存储数据时,可以通过设置合适的存储选项和参数来提升性能。例如,可以配置内存使用策略、文件存储规则、数据结构布局等方面的参数,以实现更高效的数据存储和访问。
#### 3.2 查询性能优化技巧
对于查询操作,RocksDB也提供了一些优化技巧。例如,在执行查询时可以利用缓存机制减少磁盘读取,提升查询速度。RocksDB支持设置缓存大小、缓存策略和缓存淘汰机制等参数,用户可以根据实际情况进行调整。此外,合理设计数据库键的结构和索引也是提升查询性能的有效手段。
```java
// 查询性能优化示例
ReadOptions options = new ReadOptions()
.setFillCache(false); // 不使用缓存
byte[] value = db.get(options, key);
```
#### 3.3 写入性能优化策略
写入性能是另一个需要重点关注的方面。RocksDB通过批量写入、异步写入、写缓冲等技术来优化写入性能。通过合理配置写入选项和参数,可以提升写入速度,减少写放大现象,降低写入时的性能开销。此外,合理管理内存和磁盘空间,避免频繁的写入和删除操作也可以提升写入性能。
```go
// 写入性能优化示例
batch := new(rocksdb.WriteBatch)
batch.Put([]byte("key1"), []byte("value1"))
batch.Put([]byte("key2"), []byte("value2"))
db.Write(wo, batch)
```
通过以上性能优化策略,可以有效提升RocksDB在大数据存储领域的性能表现,使系统更加高效稳定地运行。在实际应用中,可以根据具体需求和场景选择合适的优化策略,不断调优和改进系统性能。
# 4. RocksDB与其他存储引擎的比较
RocksDB作为一种高性能的嵌入式键值存储引擎,在与其他存储引擎进行比较时,具有其独特的优势和特点。接下来将对RocksDB与LevelDB进行比较分析,以及与其他主流数据库的性能比较。
#### 4.1 与LevelDB的比较
RocksDB是由Facebook开发的,是在LevelDB基础上进行了优化和改进的存储引擎。相较于LevelDB,RocksDB在以下几个方面有明显的优势:
- **性能优化:** RocksDB针对SSD硬盘进行了优化,包括使用更加高效的压缩算法和更有效的读写操作,因此在大规模数据存储和高并发读写场景下性能更加出色。
- **可扩展性:** RocksDB对并发和多线程读写的支持更强,能够更好地适应高并发访问的场景,具有更好的可扩展性。
- **持久化:** RocksDB支持更多的持久化配置选项,包括更细粒度的数据持久化控制和更灵活的数据持久化策略,因此在数据可靠性和一致性上更有优势。
#### 4.2 与RocksDB的对比分析
在与自身版本的比较中,RocksDB具有更多的新特性和优化,例如:
- **压缩算法:** RocksDB引入了更多高效的压缩算法,能够更好地节省存储空间。
- **并发控制:** RocksDB在并发控制方面进行了进一步的优化,能够更好地应对高并发读写场景。
#### 4.3 与其他主流数据库的性能比较
除了与LevelDB的比较之外,RocksDB还可以与其他主流数据库进行性能比较,例如与Redis、Cassandra等进行读写性能对比,以及与HBase、MySQL等进行存储空间利用率对比。这些比较可以帮助我们更好地了解RocksDB在不同场景下的优势和劣势,从而更好地选择合适的存储引擎来满足业务需求。
以上是RocksDB与其他存储引擎的比较分析,不同的存储引擎在不同的场景下可能有不同的优势,因此在选择存储引擎时需要充分考虑实际业务需求和场景。
# 5. RocksDB的应用案例分析
RocksDB作为一个高性能、可靠的嵌入式存储引擎,在各个领域都有广泛的应用。下面我们将分析一些RocksDB在实际场景中的应用案例,从而更好地理解其实际运用价值。
### 5.1 RocksDB在大数据存储中的应用案例
#### 场景描述:
一家互联网公司拥有海量用户数据,需要一种高效的数据存储方案来满足快速增长的需求,同时要求存储引擎具备高性能和可靠性。
#### 代码示例(Python):
```python
import rocksdb
# 打开数据库
db = rocksdb.DB("path_to_db", rocksdb.Options(create_if_missing=True))
# 写入数据
db.put(b"key1", b"value1")
db.put(b"key2", b"value2")
# 读取数据
print(db.get(b"key1"))
print(db.get(b"key2"))
# 关闭数据库
del db
```
#### 代码说明:
- 通过RocksDB提供的Python接口,我们可以轻松地打开、写入和读取数据。
- RocksDB支持多种数据类型的存储,可以满足大数据场景下的各种需求。
#### 结果说明:
通过RocksDB的高性能和可靠性,可以有效地处理海量的用户数据,确保数据的安全性和高速访问。
### 5.2 RocksDB在分布式系统中的应用案例
#### 场景描述:
一个分布式系统需要一个可靠、易扩展的存储引擎来支持系统的数据存储和访问需求,同时要求能够很好地处理各节点之间的数据同步和一致性问题。
#### 代码示例(Java):
```java
import org.rocksdb.*;
// 打开数据库
final Options options = new Options().setCreateIfMissing(true);
final RocksDB db = RocksDB.open(options, "path_to_db");
// 写入数据
db.put("key1".getBytes(), "value1".getBytes());
db.put("key2".getBytes(), "value2".getBytes());
// 读取数据
System.out.println(new String(db.get("key1".getBytes())));
System.out.println(new String(db.get("key2".getBytes())));
// 关闭数据库
db.close();
```
#### 代码说明:
- 使用RocksDB的Java接口,可以轻松地在分布式系统中实现数据的存储和读取,并支持数据的一致性和同步。
- RocksDB的高性能和可扩展性使得其在分布式系统中表现出色。
#### 结果说明:
RocksDB在分布式系统中的应用,能够有效地支撑系统的数据存储和读取需求,并保证数据的一致性和可靠性。
### 5.3 RocksDB在互联网行业的典型应用
#### 场景描述:
一家互联网公司需要构建一个高性能、可靠的数据存储系统,以支持用户行为数据的收集、存储和分析,为业务决策提供数据支撑。
#### 代码示例(Go):
```go
package main
import (
"github.com/tecbot/gorocksdb"
"log"
)
func main() {
// 打开数据库
opts := gorocksdb.NewDefaultOptions()
defer opts.Destroy()
db, err := gorocksdb.OpenDb(opts, "path_to_db")
if err != nil {
log.Fatalf("Open DB failed: %v", err)
}
defer db.Close()
// 写入数据
wo := gorocksdb.NewDefaultWriteOptions()
defer wo.Destroy()
db.Put(wo, []byte("key1"), []byte("value1"))
db.Put(wo, []byte("key2"), []byte("value2"))
// 读取数据
ro := gorocksdb.NewDefaultReadOptions()
defer ro.Destroy()
data1, err := db.Get(ro, []byte("key1"))
log.Println(string(data1.Data()))
data2, err := db.Get(ro, []byte("key2"))
log.Println(string(data2.Data()))
}
```
#### 代码说明:
- 在Go语言中使用gorocksdb库实现对RocksDB的操作,支持高性能的数据存储和读取。
- RocksDB在互联网行业的应用可以提升系统的数据处理效率和响应速度。
#### 结果说明:
通过RocksDB的稳定性和高效性,互联网公司可以构建出高性能、可靠的数据存储系统,为业务发展提供有力支持。
# 6. RocksDB发展趋势与展望
RocksDB作为一个高性能、可嵌入式的持久化键值存储引擎,在大数据领域有着广泛的应用前景。未来,随着大数据和分布式系统的不断发展,RocksDB也将在以下方面有更多发展空间和机遇。
#### 6.1 RocksDB在未来的应用前景
RocksDB在未来将更加深度地融合在大数据存储、分布式系统、云计算等领域。随着存储技术和硬件技术的不断升级,RocksDB在数据处理和存储方面将有更广阔的应用前景,包括但不限于:
- 更快速的数据处理和读写性能
- 更高效的数据压缩和存储优化策略
- 更广泛的分布式存储和计算场景
#### 6.2 RocksDB可能的技术发展方向
未来,RocksDB在技术上可能会朝着以下方向进行发展:
- 支持更多的存储介质,如闪存、NVM等
- 改进数据压缩算法,提升存储效率
- 更好地融合在容器、虚拟化等场景中,提供更灵活的部署方式
- 更丰富的监控和管理功能,更好地适应大规模分布式系统的管理需求
#### 6.3 RocksDB在大数据时代的发展机遇
在当前大数据时代,RocksDB将面临以下发展机遇:
- 大数据场景下对高性能、低延迟存储的持续需求
- 云原生应用和分布式存储系统的普及,为RocksDB的应用提供更广泛的场景
- 大规模应用场景下的不断优化和改进需求,推动RocksDB技术的不断进步和发展
总之,RocksDB作为一款性能和稳定性表现优秀的存储引擎,在未来将继续发挥重要作用,并有望在大数据时代中迎来更广阔的发展空间。
以上就是关于RocksDB发展趋势与展望的内容,希望能够为您提供一些参考和启发。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
这个专栏深入探讨了RocksDB这一高性能开源存储引擎的各个方面。从RocksDB的简介与基本原理解析开始,逐步展开对其数据存储结构、读取流程、写入前日志机制等方面的深入分析。通过与LevelDB的对比与区别,帮助读者更好地理解RocksDB的特点。此外,专栏还详细解析了RocksDB中的事务处理与ACID原则,以及数据压缩与解压缩策略。这些内容帮助读者全面了解RocksDB的运行机制,为使用该存储引擎提供了深入的理论支持与实践指导。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
电子组件可靠性快速入门:IEC 61709标准的10个关键点解析
# 摘要
电子组件可靠性是电子系统稳定运行的基石。本文系统地介绍了电子组件可靠性的基础概念,并详细探讨了IEC 61709标准的重要性和关键内容。文章从多个关键点深入分析了电子组件的可靠性定义、使用环境、寿命预测等方面,以及它们对于电子组件可靠性的具体影响。此外,本文还研究了IEC 61709标准在实际应用中的执行情况,包括可靠性测试、电子组件选型指导和故障诊断管理策略。最后,文章展望了IEC 61709标准面临的挑战及未来趋势,特别是新技术对可靠性研究的推动作用以及标准的适应性更新。
# 关键字
电子组件可靠性;IEC 61709标准;寿命预测;故障诊断;可靠性测试;新技术应用
参考资源
KEPServerEX扩展插件应用:增强功能与定制解决方案的终极指南
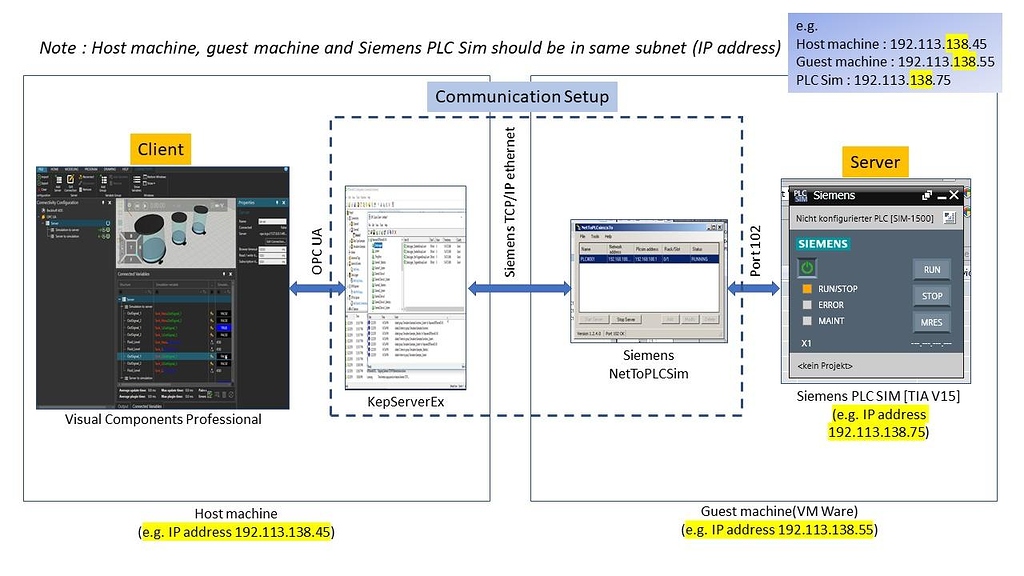
# 摘要
本文全面介绍了KEPServerEX扩展插件的概况、核心功能、实践案例、定制解决方案以及未来的展望和社区资源。首先概述了KEPServerEX扩展插件的基础知识,随后详细解析了其核心功能,包括对多种通信协议的支持、数据采集处理流程以及实时监控与报警机制。第三章通过
【Simulink与HDL协同仿真】:打造电路设计无缝流程

# 摘要
本文全面介绍了Simulink与HDL协同仿真技术的概念、优势、搭建与应用过程,并详细探讨了各自仿真环境的配置、模型创建与仿真、以及与外部代码和FPGA的集成方法。文章进一步阐述了协同仿真中的策略、案例分析、面临的挑战及解决方案,提出了参数化模型与自定义模块的高级应用方法,并对实时仿真和硬件实现进行了深入探讨。最
高级数值方法:如何将哈工大考题应用于实际工程问题
# 摘要
数值方法作为工程计算中不可或缺的工具,在理论研究和实际应用中均显示出其重要价值。本文首先概述了数值方法的基本理论,包括数值分析的概念、误差分类、稳定性和收敛性原则,以及插值和拟合技术。随后,文章通过分析哈工大的考题案例,探讨了数值方法在理论应用和实际问
深度解析XD01:掌握客户主数据界面,优化企业数据管理

# 摘要
客户主数据界面作为企业信息系统的核心组件,对于确保数据的准确性和一致性至关重要。本文旨在探讨客户主数据界面的概念、理论基础以及优化实践,并分析技术实现的不同方法。通过分析客户数据的定义、分类、以及标准化与一致性的重要性,本文为设计出高效的主数据界面提供了理论支撑。进一步地,文章通过讨论数据清洗、整合技巧及用户体验优化,指出了实践中的优化路径。本文还详细阐述了技术栈选择、开发实践和安
Java中的并发编程:优化天气预报应用资源利用的高级技巧
# 摘要
本论文针对Java并发编程技术进行了深入探讨,涵盖了并发基础、线程管理、内存模型、锁优化、并发集合及设计模式等关键内容。首先介绍了并发编程的基本概念和Java并发工具,然后详细讨论了线程的创建与管理、线程间的协作与通信以及线程安全与性能优化的策略。接着,研究了Java内存模型的基础知识和锁的分类与优化技术。此外,探讨了并发集合框架的设计原理和
计算机组成原理:并行计算模型的原理与实践
# 摘要
随着计算需求的增长,尤其是在大数据、科学计算和机器学习领域,对并行计算模型和相关技术的研究变得日益重要。本文首先概述了并行计算模型,并对其基础理论进行了探讨,包括并行算法设计原则、时间与空间复杂度分析,以及并行计算机体系结构。随后,文章深入分析了不同的并行编程技术,包括编程模型、语言和框架,以及
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )