Kubernetes部署:从本地搭建到云端上手指南
发布时间: 2024-02-23 22:16:43 阅读量: 41 订阅数: 24 
# 1. 简介
Kubernetes(简称K8s)是一个开源的容器编排引擎,用于自动化部署、扩展和管理容器化应用程序。由Google开发并捐赠给Cloud Native Computing Foundation(CNCF)管理。
## 什么是Kubernetes
Kubernetes允许用户快速高效地构建、扩展和管理容器化应用程序。它提供了强大的自动化容器编排、管理和操作功能,可以让开发者更专注于应用程序的开发,而不是运维工作。
## 为什么要使用Kubernetes
Kubernetes可以帮助用户轻松管理上千个容器化应用实例,提供高可用性、强大的故障恢复能力和自动伸缩等功能。通过Kubernetes,用户可以更好地利用资源,提高应用程序的稳定性和可靠性。
## Kubernetes在现代应用开发中的角色
在当前的云原生时代,Kubernetes已成为重要的基础设施组件。它为容器化应用提供了一致的部署和管理平台,在云端和本地环境都具备良好的适用性。使用Kubernetes可以帮助开发团队更高效地开发、测试和部署应用程序。
# 2. 本地环境准备
在本地搭建Kubernetes环境之前,我们需要进行一些准备工作,包括安装必要的软件和配置基本环境。接下来,将详细介绍如何在本地环境下准备好Kubernetes的部署环境。
### 2.1 安装Docker
Docker是一款开源的容器化引擎,Kubernetes一般使用Docker来构建和运行应用程序。以下是在Linux环境下安装Docker的步骤:
```bash
# 更新apt包列表
sudo apt update
# 安装所需软件包以允许apt通过HTTPS使用存储库
sudo apt install apt-transport-https ca-certificates curl software-properties-common
# 添加Docker的官方GPG密钥
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
# 添加Docker的稳定存储库
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
# 再次更新apt包列表
sudo apt update
# 安装Docker CE
sudo apt install docker-ce
```
安装完成后,可以通过以下命令验证Docker是否成功安装:
```bash
docker --version
```
### 2.2 安装Minikube
Minikube是一个用于在本地机器上运行单节点Kubernetes集群的工具,通过Minikube,您可以方便地在本地进行Kubernetes的开发和测试。
要安装Minikube,可以使用以下命令(以Linux为例):
```bash
curl -Lo minikube https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64 \
&& chmod +x minikube
sudo cp minikube /usr/local/bin && rm minikube
```
### 2.3 Minikube基本配置
安装完成后,可以使用以下命令启动Minikube:
```bash
minikube start
```
启动后,可以使用以下命令检查集群状态:
```bash
minikube status
```
### 2.4 创建第一个Kubernetes集群
通过以上步骤,您已成功在本地环境搭建了第一个Kubernetes集群。接下来,您可以开始学习Kubernetes的基本概念并在集群中创建和部署应用程序。
# 3. 基本概念介绍
Kubernetes作为一个容器编排平台,有一些核心概念需要我们了解和掌握,下面将逐一介绍这些基本概念。
#### 3.1 Pod、Deployment、Service是什么
在Kubernetes中,Pod 是最小的部署单元,它可以包含一个或多个容器,这些容器共享网络和存储资源。Deployment 是用来管理 Pod 的控制器,它定义了应用的部署方式,可以确保指定数量的 Pod 始终在运行。Service 提供了一个抽象层,用于将一组具有相同标签的 Pod 组合在一起,外部应用可以通过 Service 访问这些 Pod,而不需要了解 Pod 的具体 IP 地址和端口。Pod、Deployment、Service三者是Kubernetes中非常重要的概念,理解它们的关系和作用将有助于更好地管理和部署应用程序。
#### 3.2 Namespace的作用和用法
Namespace 是一种用来在集群内部划分资源的机制,可以将集群划分为多个虚拟集群,每个 Namespace 都拥有自己的资源范围,不同 Namespace 之间的资源相互隔离,从而帮助管理和组织集群中的资源。通常可以通过 Namespace 来划分不同环境(如开发、测试、生产),不同团队或不同项目的资源,以便更好地管理和使用 Kubernetes 集群中的资源。
#### 3.3 Ingress Controller的配置
Ingress 是Kubernetes中管理外部访问的 API 对象,它允许对集群中的 Service 进行路由和暴露,通过定义不同的 Ingress 规则,可以实现基于域名和路径的流量分发。而 Ingress Controller 则是实现 Ingress 的关键组件,它负责监视集群中的 Ingress 资源变化,并根据配置更新负载均衡器等组件,将外部流量路由到对应的 Service。配置 Ingress Controller 是部署应用到 Kubernetes 集群中的重要步骤,通过合理的配置可以实现灵活的流量控制和负载均衡。
#### 3.4 基于Label的Pod管理
Kubernetes 中的 Label 是一种用来标识 Pod 或其他资源的键值对,通过 Label 可以给 Pod 添加元数据,以便更好地组织和管理 Pod。使用 Label 可以实现对 Pod 的分组、筛选和关联,同时也是很多控制器(如 Deployment、Service)实现功能的重要手段。合理使用 Label 可以提高 Pod 的管理效率,简化对资源的操作和控制,是 Kubernetes 中重要的管理机制。
# 4. 在本地部署应用
在这一节中,我们将详细介绍如何在本地环境中部署一个简单的应用程序到Kubernetes集群中。
#### 4.1 编写一个简单的应用程序
首先,我们需要编写一个简单的应用程序作为示例。我们以Python为例,编写一个简单的flask应用。
```python
# 文件名: app.py
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello, Kubernetes! This is my first app.'
if __name__ == '__main__':
app.run(debug=True, host='0.0.0.0')
```
在该应用中,我们创建了一个简单的Flask应用,当访问根路径时返回"Hello, Kubernetes! This is my first app."。
#### 4.2 创建Deployment和Service文件
接下来,我们需要创建Deployment和Service文件来定义如何部署和暴露我们的应用。
Deployment文件 `app-deployment.yaml`:
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-first-app
spec:
replicas: 1
selector:
matchLabels:
app: my-first-app
template:
metadata:
labels:
app: my-first-app
spec:
containers:
- name: my-first-app
image: my-first-app:latest
ports:
- containerPort: 5000
```
Service文件 `app-service.yaml`:
```yaml
apiVersion: v1
kind: Service
metadata:
name: my-first-app
spec:
selector:
app: my-first-app
ports:
- protocol: TCP
port: 80
targetPort: 5000
type: NodePort
```
#### 4.3 使用Kubectl部署应用到集群
现在我们可以使用`kubectl apply -f <file>`命令将Deployment和Service文件部署到我们的Kubernetes集群中:
```bash
$ kubectl apply -f app-deployment.yaml
$ kubectl apply -f app-service.yaml
```
#### 4.4 监控和调试应用
部署完成后,我们可以通过以下命令查看应用的运行状态:
```bash
$ kubectl get pods
$ kubectl get services
```
如果一切正常,我们可以通过浏览器或curl访问暴露的NodePort地址,查看应用是否成功部署和运行。
通过以上步骤,我们成功在本地搭建了一个简单的应用程序,并将其部署到Kubernetes集群中。
# 5. 在云端部署Kubernetes集群
随着Kubernetes在本地环境中的部署和应用的实践,我们可以将Kubernetes集群部署到云端。在云端部署Kubernetes集群有助于提高可靠性、可扩展性和安全性,同时也可以更好地支持持续集成/持续部署(CI/CD)的流程。以下是从本地搭建到云端部署Kubernetes集群的步骤:
#### 5.1 选择云服务商
在选择云服务商之前,需要考虑几个关键因素,包括成本、性能、地域覆盖范围、安全和可用性。目前市面上主要的云服务商包括AWS、Azure、Google Cloud和阿里云等。在选择云服务商时需要根据实际需求和预算做出合理的选择。
#### 5.2 在云端设置Kubernetes集群
大多数云服务商提供了简单易用的界面和命令行工具来设置Kubernetes集群。以AWS为例,可以使用Amazon EKS来快速建立高可用的Kubernetes集群。在Google Cloud平台上,可以使用Google Kubernetes Engine(GKE)来搭建Kubernetes集群。另外,阿里云的容器服务(ACK)和华为云的云容器引擎(CCE)也为用户提供了简单快捷的Kubernetes集群搭建方案。
#### 5.3 部署应用到云端Kubernetes
一旦在云端搭建好了Kubernetes集群,就可以将之前开发好的应用程序部署到云端的集群中。可以通过Kubectl命令行工具或者其他可视化管理工具,将本地应用程序的Deployment和Service文件部署到云端的Kubernetes集群中。
#### 5.4 水平扩展和自动伸缩
在云端部署的Kubernetes集群中,可以通过Kubernetes的水平扩展与自动伸缩功能,根据实时的负载情况来自动调整应用程序的副本数量,从而满足不同负载下的性能需求。这样的自动伸缩机制可以大大提高系统的稳定性和可用性。
通过本章的指南,读者可以快速了解如何将Kubernetes集群部署到云端,并成功在云端环境中部署和运行自己的应用程序。
# 6. 进阶主题
Kubernetes的进阶主题涉及到一些高级功能和最佳实践,包括使用Helm进行应用程序的打包和发布,对Kubernetes集群进行监控和日志管理,实现持续集成/持续部署(CI/CD)流程,以及安全最佳实践及漏洞管理。
#### 6.1 使用Helm进行应用程序的打包和发布
Helm是Kubernetes的包管理工具,可以帮助我们创建、分享和管理Kubernetes应用的打包文件(Charts),并且通过简单的命令部署到集群中。下面是一个简单的示例,假设我们有一个基于Node.js的应用程序需要部署到Kubernetes集群。
首先,我们需要安装Helm,并初始化一个Helm仓库:
```bash
# 安装Helm
helm install <release_name> <chart_name>
```
然后,创建一个简单的Helm Chart,例如我们的Node.js应用程序:
```yaml
# File: my-nodejs-chart/values.yaml
replicaCount: 3
image:
repository: my-nodejs-app
tag: latest
pullPolicy: IfNotPresent
service:
name: my-nodejs-service
type: LoadBalancer
externalPort: 80
internalPort: 3000
```
接着,通过Helm将Chart部署到集群中:
```bash
# 通过Helm部署Chart
helm install my-nodejs-release ./my-nodejs-chart
```
这样,我们就可以使用Helm轻松地管理应用程序的打包和发布。
#### 6.2 对Kubernetes集群进行监控和日志管理
在生产环境中,对Kubernetes集群进行监控和日志管理是非常重要的。我们可以使用一些开源工具如Prometheus和Grafana来实现集群的监控,同时采用EFK(Elasticsearch、Fluentd、Kibana)等技术栈来进行日志管理。
#### 6.3 实现持续集成/持续部署(CI/CD)流程
持续集成/持续部署是现代化软件开发的必备流程,Kubernetes可以很好地支持CI/CD流程。我们可以利用Jenkins、GitLab等工具实现持续集成,同时通过Kubernetes的API和Helm实现持续部署,从而实现自动化地构建、测试和部署应用程序。
#### 6.4 安全最佳实践及漏洞管理
最后,对于Kubernetes集群的安全性和漏洞管理也是至关重要的。我们需要定期更新和维护Kubernetes集群的组件和依赖,同时配置网络策略、访问控制和证书管理等,从而保障集群的安全性。
通过掌握这些进阶主题,可以让我们更深入地理解和使用Kubernetes,以及将其应用于生产环境中的实际项目中。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Kubernetes/K8s企业级运维实战指南》专栏深入探讨了Kubernetes在企业级环境下的实际应用和运维技术,涵盖从基础部署到高级操作的全面指南。其中的文章包括《Kubernetes部署:从本地搭建到云端上手指南》、《Kubernetes基本操作指南:Pods、Services、Deployments》、《Kubernetes网络概念与实践:Service Discovery、Ingress、NetworkPolicies》、《Kubernetes多集群管理实战指南》等,涵盖了Kubernetes的各个关键方面。此外,专栏还就Kubernetes自动化扩展、持续集成与持续部署、故障排除与调优、监控与告警集成等议题提供了深入的解析与实践指南。对于Kubernetes中的调度器、控制器、存储、自定义资源与Operator等特性也进行了深入解析。这个专栏旨在帮助读者全面掌握Kubernetes的企业级运维技术,提高系统稳定性和运维效率。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
KeeLoq算法与物联网安全:打造坚不可摧的连接(实用型、紧迫型)

# 摘要
KeeLoq算法作为物联网设备广泛采用的加密技术,其在安全性、性能和应用便捷性方面具有独特优势。本文首先概述了KeeLoq算法的历史、发展以及在物联网领域中的应用,进而深入分析了其加密机制、数学基础和实现配置。文章第三章探讨了物联网安全面临的挑战,包括设备安全隐患和攻击向量,特别强调了KeeLoq算法在安全防护中的作
彻底分析Unity性能: Mathf.Abs() 函数的优化潜力与实战案例

# 摘要
本文对Unity环境下性能分析的基础知识进行了概述,并深入研究了 Mathf.Abs() 函数的理论与实践,探讨了其在性能优化中的应用。通过基准测试和场景分析,阐述了 Mathf.A
PCI Geomatica新手入门:一步步带你走向安装成功
# 摘要
本文详细介绍了PCI Geomatica的安装和基本使用方法。首先,概述了PCI Geomatica的基本概念、系统需求以及安装前的准备工作,包括检查硬件和软件环境以及获取必要的安装材料。随后,详细阐述了安装流程,从安装步骤、环境配置到故障排除和验证。此外,本文还提供了关于如何使用PCI Geomatica进行基本操作的实践指导,包括界面概览、数据导入导出以及高级功能的探索。深入学习章节进一步探讨了高级
【FANUC机器人集成自动化生产线】:案例研究,一步到位

# 摘要
本文综述了FANUC机器人集成自动化生产线的各个方面,包括基础理论、集成实践和效率提升策略。首先,概述了自动化生产线的发展、FANUC机器人技术特点及其在自动化生产线中的应用。其次,详细介绍了FANUC机器人的安装、调试以及系统集成的工程实践。在此基础上,提出了提升生产线效率的策略,包括效率评估、自动化技术应用实例以及持续改进的方法论。最后,
深入DEWESoftV7.0高级技巧
# 摘要
本文全面介绍了DEWESoftV7.0软件的各个方面,从基础理论知识到实践应用技巧,再到进阶定制和问题诊断解决。DEWESoftV7.0作为一款先进的数据采集和分析软件,本文详细探讨了其界面布局、数据处理、同步触发机制以及信号处理理论,提供了多通道数据采集和复杂信号分析的高级应用示例。此外,本文还涉及到插件开发、特定行业应用优化、人工智能与机器学习集成等未来发展趋势。通过综合案例分析,本文分享了在实际项目中应用DEW
【OS单站监控要点】:确保服务质量与客户满意度的铁律
# 摘要
随着信息技术的快速发展,操作系统单站监控(OS单站监控)已成为保障系统稳定运行的关键技术。本文首先概述了OS单站监控的重要性和基本组成,然后深入探讨了其理论基础,包括监控原理、策略与方法论,以及监控工具与技术的选择。在实践操作部分,文章详细介绍了监控系统的部署、配置以及实时数据分析和故障响应机制。通过对企业级监控案例的分析,本文揭示了监控系统的优化实践和性能调优策略,并讨论了监
【MTK工程模式进阶指南】:专家教你如何进行系统调试与性能监控

# 摘要
本文综述了MTK工程模式的基本概念、系统调试的基础知识以及深入应用中的内存管理、CPU性能优化和系统稳定性测试。针对MTK工程模式的高级技巧,详细探讨了自定义设置、调试脚本与自动化测试以及性能监控与预警系统的建立。通过案例分析章节,本文分享了优化案例的实施步骤和效果评估,并针对遇到的常见问题提出了具体的解决方案。整体而言,本文为MTK工程模式的使用提供了一套全面的实践指南,
【上位机网络通信】:精通TCP_IP与串口通信,确保数据传输无懈可击
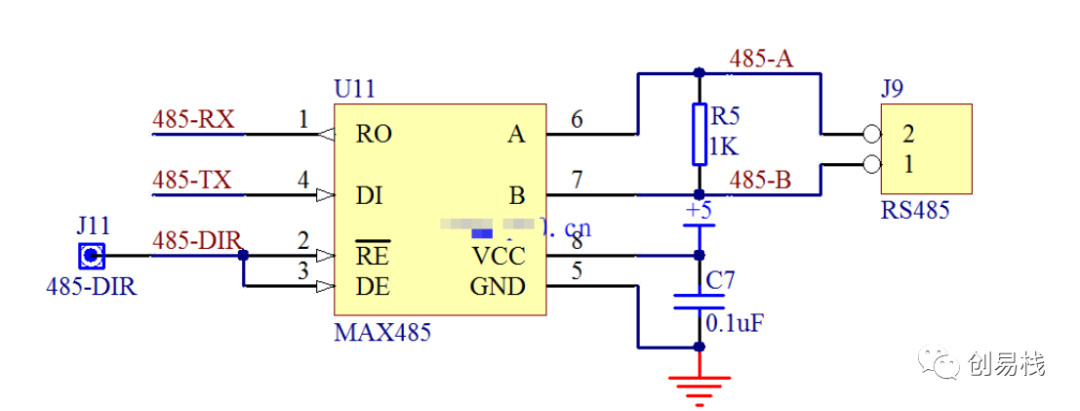
# 摘要
本文全面探讨了上位机网络通信的关键技术与实践操作,涵盖了TCP/IP协议的深入分析,串口通信的基础和高级技巧,以及两者的结合应用。文章首先概述了上位机网络通信的基本概念,接着深入分析了TCP/IP协议族的结构和功能,包括网络通信的层次模型、协议栈和数据封装。通过对比TCP和UDP协议,文章阐述了它们的特点和应用场景。此外,还探讨了IP地址的分类、分配以及ARP协议的作用。在实践操作章节,文章详细描述了构建TCP/IP通信模型、
i386环境下的内存管理:高效与安全的内存操作,让你的程序更稳定
# 摘要
本文系统性地探讨了i386环境下内存管理的各个方面,从基础理论到实践技巧,再到优化及安全实现,最后展望内存管理的未来。首先概述了i386内存管理的基本概念,随后深入分析内存寻址机制、分配策略和保护机制,接着介绍了内存泄漏检测、缓冲区溢出防御以及内存映射技术。在优化章节中,讨论了高效内存分配算法、编译器优化以及虚拟内存的应用。文章还探讨了安全内存操作,包括内存隔离技术和内存损坏的检测与恢复。最后,预
【芯片封装与信号传输】:封装技术影响的深度解析

# 摘要
芯片封装技术是现代微电子学的关键部分,对信号完整性有着至关重要的影响。本文首先概述了芯片封装技术的基础知识,然后深入探讨了不同封装类型、材料选择以及布局设计对信号传输性能的具体影响。接着,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )