【邮件处理提速30%】:掌握Python email库高级技巧,优化你的工作流
发布时间: 2024-09-30 07:51:47 阅读量: 34 订阅数: 23 
# 1. 邮件处理与Python的交集
在数字化时代的今天,邮件作为沟通和业务往来的主要手段之一,仍然扮演着重要角色。Python,作为一种广泛应用于IT领域的编程语言,其在邮件处理领域的作用不容忽视。本章旨在探讨Python语言与邮件处理之间的交集,为读者提供一个全面的视角了解如何使用Python来处理邮件,从而提升工作效率。
本章将通过分析邮件处理的基本概念入手,逐步深入到Python email库的核心功能,最终引导读者理解Python在邮件处理自动化方面的巨大潜力。无论你是邮件服务提供商、企业IT管理员,还是希望提高个人邮件管理效率的开发者,本章的内容都值得你深入了解和掌握。
## 1.1 邮件处理的基本概念
邮件处理通常包括创建、发送、接收、解析和存储邮件等多个环节。随着信息技术的发展,邮件处理方式也在不断演变,逐步从传统的手动处理向自动化、智能化方向发展。邮件处理的自动化可以大大提高效率,减少重复性劳动,并帮助人们从繁琐的邮件管理任务中解放出来。
## 1.2 Python在邮件处理中的应用
Python凭借其简洁易读的语法和强大的标准库,在邮件处理领域大放异彩。特别是Python的email库,提供了丰富的邮件处理功能,使得开发者能够方便地创建和解析邮件内容、处理附件以及自动化邮件发送任务。此外,通过与其他库(如smtplib, poplib等)的结合,Python可以构建出完整的邮件处理解决方案,包括邮件发送、接收、分发等。
在接下来的章节中,我们将深入探讨Python email库的具体使用方法和最佳实践,展示如何将这些工具应用到实际的邮件处理流程中,从而实现邮件处理工作的自动化和优化。
# 2. 深入Python email库核心功能
## 2.1 Python email库基础
### 2.1.1 安装和配置Python email库
Python的`email`库是标准库的一部分,不需要额外安装。它提供了创建、操作和解析邮件消息的完整功能。然而,若需发送邮件,你可能需要依赖外部库如`smtplib`(发送邮件)和`imaplib`(接收邮件)。
为确保你的Python环境已经配置好email库,你可以在Python交互式解释器中运行以下命令:
```python
import email
```
如果你没有遇到任何错误,那么你的email库已经准备就绪。若需要发送邮件,你还得安装`smtplib`和`ssl`库:
```python
import smtplib
import ssl
```
通常,这些库在安装Python时会被自动安装,所以大多数情况下你不需要额外安装它们。
### 2.1.2 创建和发送基础邮件
创建和发送基础邮件是了解`email`库的第一步。下面是一个如何使用Python email库创建一个简单的文本邮件并通过SMTP协议发送邮件的示例:
```python
import smtplib
from email.mime.text import MIMEText
# 配置发送邮件信息
sender_email = "your_***"
receiver_email = "receiver_***"
password = input("Enter your password and press enter: ")
smtp_server = "***"
# 创建邮件对象
message = MIMEText("This is the body of the email.", "plain", "utf-8")
message['Subject'] = "Python email test"
message['From'] = sender_email
message['To'] = receiver_email
# 发送邮件
try:
with smtplib.SMTP_SSL(smtp_server, 465) as server:
server.login(sender_email, password)
server.sendmail(sender_email, receiver_email, message.as_string())
print("Email sent successfully!")
except Exception as e:
print(f"Error sending email: {e}")
```
在此示例中,我们创建了一个`MIMEText`对象来代表邮件的主体。邮件头部信息,如主题、发件人和收件人,通过直接设置邮件对象的属性来定义。邮件通过SSL连接到SMTP服务器并进行发送。
这段代码演示了Python email库中创建和发送基础邮件的基本流程,是邮件处理入门的核心知识点。
## 2.2 高级邮件解析技巧
### 2.2.1 解析邮件头部信息
邮件头部信息包含了邮件的元数据,如发件人、接收者、主题、日期等。解析邮件头部信息可以通过访问邮件对象的特定属性来完成。
下面的代码展示如何提取和打印邮件头部信息:
```python
import email
from email.parser import BytesParser
from email.policy import default
# 假设我们有一个邮件文件的字节流
with open('email_message.eml', 'rb') as f:
raw_email = f.read()
# 使用email的BytesParser解析邮件
email_message = BytesParser(policy=default).parsebytes(raw_email)
# 解析头部信息
for header, value in email_message.items():
print(f"{header}: {value}")
```
这里,`BytesParser`用于处理原始邮件数据。邮件的每个头部字段都通过调用`items()`方法进行遍历和打印。这让我们能够理解邮件的结构和传递的信息。
### 2.2.2 解析邮件正文内容
邮件正文内容可能是纯文本、HTML或其他MIME类型。解析邮件正文时,需要根据邮件内容类型选择正确的方法。下面的代码演示如何提取邮件正文内容:
```python
import email
from email.parser import BytesParser
from email.policy import default
# 假设我们有一个邮件文件的字节流
with open('email_message.eml', 'rb') as f:
raw_email = f.read()
# 解析邮件
email_message = BytesParser(policy=default).parsebytes(raw_email)
# 获取邮件内容类型
content_type = email_message.get_content_type()
content_disposition = email_message.get_content_disposition()
# 根据MIME类型决定如何处理邮件正文
if content_type == "text/html":
body = email_message.get_payload(decode=True).decode(content_type)
print("HTML content: ", body)
elif content_type == "text/plain":
body = email_message.get_payload(decode=True).decode()
print("Text content: ", body)
else:
print("Multipart message.")
```
在这个例子中,`get_content_type()`方法告诉我们邮件正文的MIME类型。`get_payload()`方法用于获取邮件的主体内容,并进行必要的解码。需要注意的是,邮件正文可能包含多个部分(例如文本和HTML),并且可能以多种方式混合显示。
### 2.2.3 邮件附件的处理与下载
邮件附件是邮件中常见的组成部分。解析邮件附件需要遍历邮件的各个部分并检查哪些是附件。下面是一个处理附件的基本代码示例:
```python
import email
from email.parser import BytesParser
from email.policy import default
# 假设我们有一个邮件文件的字节流
with open('email_message.eml', 'rb') as f:
raw_email = f.read()
# 解析邮件
email_message = BytesParser(policy=default).parsebytes(raw_email)
# 检查邮件内容是否有附件
if email_message.is_multipart():
for part in email_message.walk():
# 获取内容类型
content_type = part.get_content_type()
# 获取文件名
filename = part.get_filename()
# 检查是否是附件
if content_type == "application/octet-stream" or filename is not None:
# 将附件保存到文件系统中
with open(filename, 'wb') as f:
f.write(part.get_payload(decode=True))
```
此代码段会遍历邮件的每一个部分,并检查其内容类型和文件名。如果部分是附件(通常是二进制数据),则将其保存到文件系统中。
处理邮件附件时需要考虑到安全性。附件可能包含病毒或其他恶意代码。在处理之前,应当对其进行安全扫描。
## 2.3 邮件发送的高级配置
### 2.3.1 设置邮件优先级和MIME类型
邮件优先级是一个可选字段,它指示邮件客户端对邮件的处理方式。邮件优先级可以设置为"high"、"normal"(默认)或"low"。MIME类型定义了邮件内容的类型。
以下是如何设置邮件优先级和MIME类型的代码示例:
```python
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
# 创建多部分邮件对象
msg = MIMEMultipart()
msg['From'] = 'your_***'
msg['To'] = 'receiver_***'
msg['Subject'] = 'Python email example with high priority'
# 设置邮件优先级为高
msg['X-Priority'] = '1' # 1 表示高优先级
# 创建邮件正文,并添加到邮件中
body = MIMEText('This is the body of the email.')
msg.attach(body)
# 发送邮件
# ... 与前面类似,需要配置SMTP服务器和登录信息
```
在该代码中,使用`MIMEMultipart`来创建一个包含多种内容类型的邮件对象。邮件优先级通过`X-Priority`头部字段设置,值为1表示高优先级。
### 2.3.2 使用HTML格式发送邮件
在许多情况下,发件人希望邮件内容能够有格式化,比如使用粗体或斜体文本,或者包含图片。HTML格式能够更好地表现邮件内容。
```python
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
from email.mime.image import MIMEImage
# 创建多部分邮件对象
msg = MIMEMultipart()
msg['From'] = 'your_***'
msg['To'] = 'receiver_***'
msg['Subject'] = 'Python email example with HTML'
# 创建HTML格式的邮件正文
html = '<html><body><p><strong>Hi,</strong> this is a test email.</p></body></html>'
body = MIMEText(html, 'html')
msg.attach(body)
# 添加图片附件
image = MIMEImage(open('image.png', 'rb').read())
msg.attach(image)
image.add_header('Content-Disposition', 'attachment', filename='image.png')
# 发送邮件
# ... 与前面类似,需要配置SMTP服务器和登录信息
```
在这个例子中,我们创建了一个HTML格式的邮件正文,并将其作为`MIMEText`对象添加到邮件中。同时,我们还演示了如何将图片作为附件添加到邮件中,并通过`Content-Disposition`头部指定图片的处理方式。
### 2.3.3 邮件安全性和加密发送
邮件安全性和加密是当今电子邮件通信中重要的考量。通过Python的email库,你可以发送带有S/MIME签名和加密的邮件。
以下是一个示例,展示如何使用email库发送S/MIME签名的邮件:
```python
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from email import encoders
from email.mime.base import MIMEBase
from smtplib import SMTP
import ssl
# ... 此处省略了邮件内容的创建代码 ...
# 使用SSL进行加密连接
context = ssl.create_default_context()
with SMTP('***', 465) as server:
server.ehlo()
server.starttls(context=context)
server.login('your_***', 'your_password')
server.sendmail('your_***', ['receiver_***'], msg.as_string())
```
在这个例子中,我们使用`context.create_default_context()`创建了SSL上下文,并使用它来建立加密的SMTP连接。这种方法可以保护在发送邮件过程中的数据不被窃听。
请注意,对于S/MIME签名和加密,你还需要有相应的证书和私钥。Python本身并不提供证书或私钥的管理功能,这些通常由外部证书颁发机构提供。
到此,我们已经详细介绍了Python email库的基础知识,包括如何安装配置,创建和发送基础邮件,以及高级邮件解析技巧和邮件发送的高级配置。在下一章节,我们将进一步探讨Python email库在实践应用中的案例。
# 3. Python email库实践应用案例
在邮件处理和自动化领域,Python的email库不仅是一个强大的工具,而且在实际应用中也展现出了其灵活性和实用性。本章我们将深入探讨如何将Python email库应用于现实世界中的具体案例,包括自动化邮件分类和过滤、邮件自动化回复与通知、以及邮件数据分析与报告生成等。
## 3.1 自动化邮件分类和过滤
在日常工作中,人们每天都会收到大量的邮件,手动分类和过滤这些邮件不仅耗时而且效率低下。通过编程实现自动化邮件分类和过滤,可以极大地提高工作效率并减少不必要的信息干扰。
### 3.1.1 设计邮件规则引擎
设计邮件规则引擎是实现邮件自动分类和过滤的关键。首先需要定义规则的构成,一般包括邮件头部信息、邮件正文内容和特定关键词等。规则引擎可以通过解析邮件信息,匹配预定义的规则集,并执行相应的分类操作。
```python
import email
from email.policy import default
def filter_emails(emails, rules):
classified_emails = {'spam': [], 'not_spam': []}
for email_message in emails:
msg = email_message.as_bytes().decode(default)
msg = email.message_from_string(msg)
for rule in rules:
if rule['field'] == 'subject' and rule['keyword'] in msg['subject']:
classified_emails[rule['category']].append(email_message)
elif rule['field'] == 'body' and rule['keyword'] in msg.get_body(preferencelist=('plain',)):
classified_emails[rule['category']].append(email_message)
# 更多的规则匹配逻辑...
return classified_emails
```
在上述代码中,我们定义了一个简单的函数`filter_emails`来分类邮件。函数接受一个邮件列表和规则集合作为输入,返回一个分类后的邮件字典。每个规则定义了要匹配的字段(如主题或正文)和关键词。根据这些规则,函数会将邮件归类为垃圾邮件或非垃圾邮件。
### 3.1.2 实现邮件自动分类
接下来,我们需要实现邮件自动分类的功能。首先,我们需要收集和预定义一系列邮件规则。然后,利用邮件规则引擎对新邮件进行分类处理。
```python
rules = [
{'field': 'subject', 'keyword': '促销', 'category': 'spam'},
{'field': 'body', 'keyword': '获奖通知', 'category': 'spam'},
# 其他垃圾邮件规则...
]
# 假设我们已经获取了新邮件的列表
new_emails = get_new_emails()
# 使用filter_emails函数进行邮件分类
classified_emails = filter_emails(new_emails, rules)
# 处理分类后的邮件
for category, mails in classified_emails.items():
process_emails(mails, category)
```
在实际应用中,我们可能需要从外部获取新邮件列表(例如通过IMAP协议),并定期调用分类函数。`process_emails`函数将根据邮件的分类,执行相应的存档、删除或其他操作。
## 3.2 邮件自动化回复与通知
自动化邮件回复与通知能够提高工作效率,特别是在客户支持、预订系统和论坛管理等场景中。使用Python email库可以轻松实现邮件模板的构建和动态内容的填充,进而自动化邮件回复的流程。
### 3.2.1 构建邮件模板和动态内容填充
首先,我们需要构建一个邮件模板。邮件模板是预先设计好的邮件格式,它包含一些可以动态替换的部分,以便针对不同的接收者和上下文发送个性化的邮件。
```markdown
Subject: 您的订单已经确认
尊敬的 [客户姓名],
感谢您在 [网站名] 下单。您的订单 [订单编号] 已经成功确认。
您的订单将按照以下详情进行处理:
产品名称: [产品名称]
产品数量: [产品数量]
预计发货日期: [发货日期]
请在收到商品后检查是否有任何损坏。如果有任何问题,请随时联系我们的客户支持团队。
祝好,
[您的姓名]
[您的职位]
[您的联系方式]
```
接下来,我们可以编写一个函数来填充模板中的动态字段:
```python
def fill_template(template, context):
for key, value in context.items():
template = template.replace('[' + key + ']', value)
return template
```
这个`fill_template`函数接受模板字符串和一个上下文字典作为输入,然后将模板中的占位符替换为实际的值,生成最终的邮件内容。
### 3.2.2 邮件自动回复的实现
一旦有了填充后的邮件内容,我们就可以编写函数来发送自动回复邮件了。
```python
import smtplib
from email.mime.text import MIMEText
def send_auto_reply(to, template_context):
# 邮件服务器设置
mail_server = smtplib.SMTP('***')
mail_server.starttls()
mail_server.login('yourusername', 'yourpassword')
# 构建邮件消息
template = get_email_template() # 从文件或数据库中获取模板
filled_template = fill_template(template, template_context)
msg = MIMEText(filled_template)
msg['Subject'] = '您的订单已经确认'
msg['From'] = '***'
msg['To'] = to
# 发送邮件
mail_server.sendmail(msg['From'], [to], msg.as_string())
mail_server.quit()
```
在上述代码中,我们定义了`send_auto_reply`函数来发送自动回复邮件。函数接受接收者的电子邮件地址和填充邮件上下文作为输入,通过连接到SMTP服务器来发送邮件。
## 3.3 邮件数据分析与报告生成
邮件数据是公司的重要资产之一,分析邮件数据可以为市场策略、客户关系管理等提供有价值的信息。同时,将分析结果以报告的形式展现,可以帮助决策者快速理解情况并做出决策。
### 3.3.1 邮件数据的统计分析
为了进行有效的邮件数据分析,首先需要收集相关的邮件数据,包括邮件数量、发送时间、收件人信息等。然后使用数据分析工具(例如Python的Pandas库)对数据进行统计分析。
```python
import pandas as pd
# 假设我们已经从邮件服务器导出了邮件数据到CSV文件
mails_df = pd.read_csv('mails_data.csv')
# 对邮件进行基本的统计分析
mails_df.groupby('category').size() # 根据邮件类别统计数量
mails_df['date'].value_counts() # 根据发送日期统计数量
# 其他数据分析操作...
```
使用Pandas进行数据统计分析,可以帮助我们快速获取有关邮件活动的洞察,比如哪种类型的邮件最受欢迎,或者邮件发送高峰时段等信息。
### 3.3.2 生成邮件报告的自动化流程
分析完邮件数据后,生成报告的自动化流程就显得尤为重要了。可以使用Python的reportlab库或Pandas的内置功能来生成PDF格式的报告。
```python
from reportlab.pdfgen import canvas
def create_pdf_report(data_frame, output_file):
c = canvas.Canvas(output_file)
c.drawString(100, 750, "邮件数据分析报告")
# 添加报表的其他内容,例如图表和数据汇总
# ...
c.save()
# 调用函数生成报告
create_pdf_report(mails_df, 'mails_report.pdf')
```
在这个例子中,我们创建了一个PDF报告的框架,并添加了标题。实际报告的内容应该包括邮件数据的统计分析结果,如图表、数据表格等。这个报告可以定期自动生成,并通过邮件或在线系统分享给相关人员。
通过以上章节所述的自动化邮件分类和过滤、邮件自动化回复与通知、以及邮件数据分析与报告生成等实践应用案例,我们可以看到Python email库在实际工作中的强大应用潜力。接下来的章节,我们将探讨如何优化邮件处理工作流,提升邮件处理的效率和质量。
# 4. 优化邮件处理工作流
## 4.1 理解邮件工作流瓶颈
### 4.1.1 识别邮件处理中的痛点
在现代企业中,邮件处理可能因通信量巨大、规则复杂、安全性要求高等因素导致效率低下。邮件工作流的痛点通常包括但不限于:
1. **手动处理耗时**:大量的邮件需要人工筛选、分类和回应,这不仅消耗人力资源,而且容易出错。
2. **缺乏自动化**:对于重复性的邮件任务,缺乏自动化处理机制,导致工作效率低下。
3. **数据管理不善**:邮件中的数据未能得到有效利用,信息散乱,难以进行数据分析和挖掘。
这些痛点往往在邮件量大的团队中尤为显著,进而影响整个组织的生产力和决策能力。
### 4.1.2 分析邮件处理流程
为了优化邮件处理工作流,第一步是分析现有的邮件处理流程。我们可以借助流程图来表示邮件从接收到处理的整个流程,从而发现效率低下的环节。
```mermaid
graph LR
A[接收邮件] --> B{是否重要?}
B -- 是 --> C[手动处理]
B -- 否 --> D{是否垃圾邮件?}
C --> E[归档]
D -- 是 --> F[删除]
D -- 否 --> G[自动回复]
G --> H[任务分配]
H --> I[处理]
I --> J[归档]
```
使用如上的流程图,我们可以清晰地看到邮件处理的各个环节。流程的分析可以揭示一些环节是否过于复杂或是否可以实现自动化。例如,一个可能的瓶颈是在手动处理和自动回复环节之间的判定,这可以通过设置更加智能的邮件规则来改善。
## 4.2 Python email库在工作流中的应用
### 4.2.1 设计高效的邮件工作流
要设计高效的邮件工作流,关键在于减少手动介入,增加自动化程度。利用Python email库,可以对邮件处理工作流中的各个部分进行编程自动化。
下面是一个Python脚本示例,演示如何根据发件人地址自动分类邮件:
```python
import email
from email.policy import default
def filter_emails_by_sender(emails, sender_address):
filtered_emails = []
for msg in emails:
sender = email.utils.parseaddr(msg['from'])[1]
if sender == sender_address:
filtered_emails.append(msg)
return filtered_emails
# 示例使用
emails = # 从邮件服务器获取邮件
filtered_emails = filter_emails_by_sender(emails, '***')
```
在这个例子中,我们定义了一个`filter_emails_by_sender`函数,它接受一个邮件列表和一个发件人地址作为参数,然后返回所有来自该地址的邮件。这样,我们可以针对特定的发件人自动执行特定的任务。
### 4.2.2 集成Python email库优化流程
集成Python email库可以进一步提升邮件处理效率。通过自定义函数和类,我们可以构建出灵活的工作流,实现更加复杂和智能的任务处理。
例如,可以创建一个邮件处理器类,它包含自动分发邮件和执行特定任务的方法:
```python
class EmailProcessor:
def __init__(self):
# 初始化处理器
pass
def process_emails(self, emails):
for msg in emails:
if msg['subject'] == "Urgent":
self.handle_urgent_email(msg)
elif "monthly report" in msg['subject']:
self.generate_report(msg)
else:
self.default_email_action(msg)
def handle_urgent_email(self, msg):
# 处理紧急邮件的逻辑
pass
def generate_report(self, msg):
# 生成报告的逻辑
pass
def default_email_action(self, msg):
# 默认邮件处理逻辑
pass
```
在这个类中,我们定义了`process_emails`方法来处理邮件列表,它基于邮件主题调用不同的处理函数。这种方式可以简化邮件处理逻辑,使维护和扩展变得更加容易。
## 4.3 测试与性能评估
### 4.3.1 构建邮件处理性能测试案例
为了确保工作流优化后的邮件处理系统能够有效工作,需要进行性能测试。在测试过程中,我们可以模拟不同的邮件场景来测试系统的响应时间和准确性。
测试案例可能包括:
- **大量邮件测试**:发送成百上千的邮件来测试系统的处理能力。
- **边缘案例测试**:发送格式错误、异常内容等邮件,以测试系统的健壮性。
- **并发处理测试**:模拟多用户同时发送邮件的情况,测试系统的并发处理能力。
下面是一个简单的性能测试脚本示例:
```python
import time
import email_processor # 假设已经实现了EmailProcessor类
def test_email_processing性能(邮件数量):
start_time = time.time()
emails = # 生成或获取大量邮件
processor = email_processor.EmailProcessor()
processor.process_emails(emails)
end_time = time.time()
print(f"处理 {邮件数量} 封邮件耗时: {end_time - start_time} 秒")
test_email_processing性能(1000)
```
通过这样的测试案例,我们可以量化邮件处理的效率,找到潜在的性能瓶颈。
### 4.3.2 评估邮件处理提速效果
性能评估是优化邮件工作流的关键步骤。评估结果可以告诉我们优化工作是否成功,并指导我们进一步的优化方向。
评估指标可以包括:
- **处理速度**:单位时间内处理的邮件数量。
- **准确性**:处理结果的正确率。
- **资源消耗**:处理过程中CPU和内存的使用情况。
通过上述指标的综合评估,我们可以得出优化的效果,并根据评估结果继续调整邮件处理策略和代码,以达到进一步的优化。
在下一章节中,我们将探索如何通过Python email库与其他库的集成,拓展邮件处理的应用边界,以及如何实现邮件处理工作的面向对象编程。
# 5. 扩展Python email库的应用边界
## 5.1 Python email库与其他库的集成
### 5.1.1 集成爬虫库获取邮件地址
为了在自动化处理邮件时拥有更多的收件人地址,我们往往需要利用网络爬虫技术从互联网上抓取潜在的邮件地址。Python作为一个拥有丰富库支持的语言,爬虫库如`requests`用于发送网络请求,`BeautifulSoup`用于解析HTML页面,都是集成邮件库获取邮件地址时的得力工具。
首先,使用`requests`库发起请求以获取网页内容:
```python
import requests
from bs4 import BeautifulSoup
# 目标网页URL
url = '***'
# 发起GET请求获取网页内容
response = requests.get(url)
# 检查请求是否成功
if response.status_code == 200:
# 使用BeautifulSoup解析网页
soup = BeautifulSoup(response.text, 'html.parser')
# 针对特定标签提取信息,例如此处提取所有邮件地址
email_addresses = soup.find_all('a', class_='email')
# 过滤并清洗提取到的邮件地址
cleaned_emails = [email.get_text().strip() for email in email_addresses if email.get_text().endswith('@***')]
else:
cleaned_emails = []
```
在上面的代码中,我们通过`requests.get`方法获取网页内容,然后使用`BeautifulSoup`解析提取的HTML文档。我们寻找所有含有`email`类的`<a>`标签,并从中提取邮件地址。需要注意的是,这只是一个示例,实际情况中邮件地址的提取可能会涉及到更复杂的逻辑。
### 5.1.2 集成数据库进行邮件存储管理
在处理大量邮件时,使用数据库系统来存储和管理邮件数据是一种常见的做法。数据库系统如SQLite、MySQL或PostgreSQL都是不错的选择,而Python的`sqlite3`、`pymysql`或`psycopg2`库可以用来与这些数据库进行交互。
这里我们以SQLite为例,展示如何集成Python email库和SQLite数据库进行邮件存储管理:
```python
import sqlite3
from email.message import EmailMessage
# 连接到SQLite数据库
# 数据库文件是test.db,如果文件不存在,会自动在当前目录创建:
conn = sqlite3.connect('test.db')
cursor = conn.cursor()
# 创建一个表:
cursor.execute('CREATE TABLE IF NOT EXISTS emails (id INTEGER PRIMARY KEY AUTOINCREMENT, subject TEXT, from TEXT, to TEXT, content TEXT)')
# 邮件数据提取示例
message = EmailMessage()
message['Subject'] = 'Sample Email'
message['From'] = '***'
message['To'] = '***'
message.set_content('This is a sample email content.')
# 将邮件数据存入数据库
cursor.execute('INSERT INTO emails(subject, from, to, content) VALUES (?, ?, ?, ?)',
(message['Subject'], message['From'], message['To'], message.get_content()))
# 提交事务:
***mit()
# 关闭Cursor和Connection:
cursor.close()
conn.close()
```
在上述代码中,我们首先创建了一个SQLite数据库,然后创建了一个包含邮件信息的表。接着,我们解析一封邮件,从中提取出邮件的主题、发件人、收件人和内容,最后将这些信息存储到数据库中。在实际应用中,邮件数据的获取和解析可以是自动化的,例如通过监听邮箱触发事件或者周期性地查询邮件服务器。
## 5.2 面向对象编程在邮件处理中的应用
### 5.2.1 设计邮件处理的类和对象
在进行大规模的邮件处理时,使用面向对象的编程范式可以提高代码的可读性、可维护性和可扩展性。我们可以设计`Email`类来封装邮件数据,同时使用邮件处理逻辑的`EmailHandler`类来管理邮件的发送、接收和存储等行为。
下面是一个简单的`Email`类示例:
```python
class Email:
def __init__(self, subject, from_addr, to_addr, content):
self.subject = subject
self.from_addr = from_addr
self.to_addr = to_addr
self.content = content
def send(self, connection):
# 在这里实现发送邮件的逻辑
pass
def __repr__(self):
return f"Email: {self.subject} from {self.from_addr} to {self.to_addr}"
```
同时,我们可以定义一个`EmailHandler`类来处理`Email`对象:
```python
class EmailHandler:
def __init__(self):
self.sent_emails = []
def handle_email(self, email):
# 在这里可以加入邮件发送逻辑
self.sent_emails.append(email)
# 如果需要,还可以加入邮件存储逻辑
print(f"Email {email.subject} has been handled.")
def get_handled_emails(self):
return self.sent_emails
# 使用示例
email = Email("Hello", "***", "***", "This is a test email.")
handler = EmailHandler()
handler.handle_email(email)
```
### 5.2.2 实现邮件工作流的OOP编程
以面向对象的方式实现邮件工作流可以有效地管理复杂的邮件处理逻辑。这涉及到将不同类型的邮件处理任务抽象为类的方法,并利用类的实例来执行这些任务。
例如,一个邮件工作流可能包含以下步骤:
1. 从邮箱检索新邮件
2. 解析邮件内容
3. 根据内容执行特定操作(如发送回复、存储数据等)
4. 更新邮件状态(已处理、已存档等)
每个步骤都可以在`EmailHandler`类中以方法的形式实现:
```python
class EmailWorkflow:
def __init__(self):
self.handler = EmailHandler()
def process_inbox(self):
# 模拟获取新邮件
new_emails = self.get_new_emails()
for email in new_emails:
self.handle_email(email)
def get_new_emails(self):
# 在这里实现从邮箱获取新邮件的逻辑
pass
def handle_email(self, email):
self.handler.handle_email(email)
self.update_email_status(email)
def update_email_status(self, email):
# 更新邮件状态的逻辑
pass
# 使用示例
workflow = EmailWorkflow()
workflow.process_inbox()
```
通过这样的设计,我们可以轻松扩展邮件工作流以包含更多步骤,例如通过额外的过滤或规则引擎来处理特定类型的邮件。面向对象的方法也让我们能够更容易地维护和测试邮件处理代码。
## 5.3 利用Python email库进行云服务整合
### 5.3.1 使用云服务提供商的API发送邮件
许多云服务提供商如Amazon SES(Simple Email Service)、SendGrid和Mailgun等提供API服务,允许用户通过编程方式发送邮件。这些API通常是通过HTTP请求来实现的,因此可以通过Python的`requests`库来调用。
以下是如何使用`requests`库调用Amazon SES API发送邮件的一个简化示例:
```python
import requests
from requests_aws4auth import AWS4Auth
# AWS区域
aws_region = 'us-east-1'
# SES服务的API端点
service = 'ses'
# AWS访问密钥和密钥ID
access_key = 'YOUR_AWS_ACCESS_KEY'
secret_key = 'YOUR_AWS_SECRET_KEY'
# 创建AWS4Auth对象
aws_auth = AWS4Auth(access_key, secret_key, aws_region, service, session_token='')
# 创建请求的URL和负载
url = "***" % aws_region
headers = {'X-Amz-Target': 'SendRawEmail'}
payload = {
'Source': '***',
'Destinations': ['***'],
'RawMessage': {
'Data': 'From: ***\r\nTo: ***\r\nSubject: Test Email\r\n\r\nThis is a test email sent from Amazon SES.'
}
}
# 发送邮件
response = requests.post(url, headers=headers, data=payload, auth=aws_auth)
print(response.text)
```
在这个示例中,我们首先设置了与Amazon SES服务交互所需的认证信息,然后创建了发送邮件的HTTP请求负载,最后通过`requests.post`方法将邮件发送出去。
### 5.3.2 邮件通知与第三方服务的整合
邮件通知可以与第三方服务整合,以便实现更丰富的功能,例如:提供订单确认通知、系统运行状态报告、用户注册验证等。通过使用邮件库,可以简单地集成这些服务,将邮件发送功能嵌入到工作流中。
例如,结合云服务API,我们可以在一个订单管理系统中集成邮件通知功能:
```python
def send_order_confirmation(order):
# 创建邮件内容
subject = f'Order Confirmation for {order.id}'
message = f'''
Thank you for your order. Your order details are as follows:
ID: {order.id}
Product: {order.product}
Quantity: {order.quantity}
Price: {order.price}
Total: {order.price * order.quantity}
'''
email = EmailMessage()
email['Subject'] = subject
email['From'] = '***'
email['To'] = order.user.email
email.set_content(message)
# 使用邮件库发送邮件
send_email(email)
```
在上面的代码示例中,`send_order_confirmation`函数负责创建一个订单确认邮件,并使用之前定义的`send_email`函数发送。该函数可以集成到订单处理系统中,以便在订单创建或支付完成后自动发送。
通过这样的集成,邮件通知成为了一个强大的工具,可以及时地向用户或管理员提供关键信息,增强用户体验并提高系统的反应速度。
# 6. Python email库的未来展望与最佳实践
随着信息技术的不断发展,邮件处理作为企业沟通和个人交流的重要手段,其处理技术也在不断演变。Python的email库作为邮件处理的重要工具之一,也在随着邮件处理技术的发展而不断更新和完善。本章将探讨新一代邮件处理技术趋势,构建可扩展的邮件处理框架,并分享邮件处理经验与社区贡献的最佳实践。
## 6.1 新一代邮件处理技术趋势
随着人工智能和机器学习技术的兴起,邮件处理的自动化和智能化水平正在提升。新技术的应用使得邮件处理更加高效和精确。
### 6.1.1 探索基于AI的邮件自动处理
人工智能技术在邮件自动处理方面的应用,可以帮助用户自动分类邮件、识别重要邮件以及提供邮件内容摘要。例如,使用自然语言处理(Natural Language Processing, NLP)技术对邮件正文进行分析,提取关键信息,判断邮件紧急程度,甚至自动回复非重要邮件。
```python
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
# 示例代码:使用TF-IDF和KMeans进行邮件主题聚类分析
vectorizer = TfidfVectorizer(stop_words='english')
X = vectorizer.fit_transform(emails)
# 对邮件内容进行聚类分析
kmeans = KMeans(n_clusters=3, random_state=0).fit(X)
email_clusters = vectorizer.inverse_transform(kmeans.cluster_centers_)
```
上例展示了如何使用TF-IDF向量化邮件文本,然后利用K-Means算法将邮件分为不同的主题类别。这只是AI邮件处理的一个简单的例子,实际应用会更加复杂和深入。
### 6.1.2 分析新兴邮件标准和协议
随着邮件格式的多样化和个性化需求的提升,新的邮件标准和协议也在不断出现。例如,邮件内容使用的Markdown格式、跨平台的邮件同步协议如CardDAV等。了解和掌握这些新兴邮件标准和协议,对提高邮件处理软件的兼容性和用户体验至关重要。
## 6.2 构建可扩展的邮件处理框架
邮件处理框架的设计需要具有高可扩展性和灵活性,以适应不同的业务需求和技术更新。
### 6.2.1 设计可扩展的邮件处理架构
可扩展的邮件处理架构意味着系统能够根据需求的变化进行调整,如支持新的邮件服务提供商、新的邮件格式以及新的邮件协议。设计时可以采用模块化方法,将邮件处理流程分解为独立的组件,例如邮件接收、邮件解析、邮件发送等模块。每个模块可以独立升级和替换,而不影响整体系统。
```mermaid
flowchart LR
A[邮件接收模块] -->|解析邮件头| B[邮件解析模块]
B -->|邮件内容| C[邮件内容处理模块]
C -->|生成响应| D[邮件响应生成模块]
D -->|发送邮件| E[邮件发送模块]
```
上图展示了邮件处理架构的模块化设计,每一个模块都执行特定的功能,便于维护和扩展。
### 6.2.2 面向未来的邮件处理最佳实践
面向未来的邮件处理最佳实践需要考虑代码的可读性、系统的可维护性和业务的可持续性。代码应当遵循DRY(Don't Repeat Yourself)原则,减少重复代码。同时,利用单元测试和持续集成确保代码质量。另外,对于邮件处理系统的设计,需要考虑到系统扩展性和安全性,为未来的业务扩展和升级打下坚实基础。
## 6.3 分享与社区贡献
邮件处理是一个涉及广泛技术领域和业务场景的领域。在不断的学习和实践中,积累的经验和案例是宝贵的资源。
### 6.3.1 分享邮件处理经验与案例
分享邮件处理经验与案例,可以帮助同行避免不必要的弯路,提升整个社区的技术水平。通过博客、技术论坛、开源项目等方式,将个人或团队在邮件处理方面的成功经验分享出来,让更多的人受益。
### 6.3.2 为Python email库做出贡献
Python的email库作为邮件处理的重要工具,它的发展离不开社区成员的共同努力。为Python email库做出贡献,可以是提交补丁、完善文档或撰写使用教程。这种贡献不仅能够帮助他人,同时也是提升自身技能和影响力的过程。
通过本章内容的介绍,我们可以看到Python email库不仅仅是邮件发送和接收的基础工具,它还蕴含着丰富的技术潜力和广泛的应用场景。从AI邮件自动处理的探索,到邮件处理架构的可扩展设计,再到社区经验分享和贡献,Python email库都在不断发展和深化。掌握这些最佳实践,将帮助我们在未来邮件处理技术的演进中保持领先地位。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨 Python email 库,为邮件处理提供全面的指南。从优化工作流的高级技巧到避免常见错误,再到实现高效情感分析和加密邮件内容,专栏涵盖了邮件处理的各个方面。此外,还介绍了动态模板和自定义邮件头等高级应用,以及机器学习与 email 库的结合,帮助您提升邮件处理速度和自动化程度。通过掌握这些技巧,您可以显著提高邮件处理效率,确保邮件安全,并充分利用 email 库的强大功能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
网格搜索:多目标优化的实战技巧

# 1. 网格搜索技术概述
## 1.1 网格搜索的基本概念
网格搜索(Grid Search)是一种系统化、高效地遍历多维空间参数的优化方法。它通过在每个参数维度上定义一系列候选值,并
机器学习调试实战:分析并优化模型性能的偏差与方差
# 1. 机器学习调试的概念和重要性
## 什么是机器学习调试
机器学习调试是指在开发机器学习模型的过程中,通过识别和解决模型性能不佳的问题来改善模型预测准确性的过程。它是模型训练不可或缺的环节,涵盖了从数据预处理到最终模型部署的每一个步骤。
## 调试的重要性
有效的调试能够显著提高模型的泛化能力,即在未见过的数据上也能作出准确预测的能力。没有经过适当调试的模型可能无法应对实
跨过随机搜索的门槛

# 1. 随机搜索方法简介
随机搜索方法是一种利用随机性指导搜索过程的优化技术,它在多变量和复杂参数空间的问题求解中显示出其独特的优势。与确定性算法相比,随机搜索不依赖于梯度或其他局部信息,而是通过随机抽样和评价候选解来逼近全局最优解。这种方法对于处理离散、连续或组合优化问题都具有广泛的适用性。随机搜索的简单性和灵活性使其成为优化算法领域的一个活跃研究方向,尤其是当问题的结构复杂或信息有限时,随机搜索往往能提供一种有效的求解策略。在接下来
VR_AR技术学习与应用:学习曲线在虚拟现实领域的探索

# 1. 虚拟现实技术概览
虚拟现实(VR)技术,又称为虚拟环境(VE)技术,是一种使用计算机模拟生成的能与用户交互的三维虚拟环境。这种环境可以通过用户的视觉、听觉、触觉甚至嗅觉感受到,给人一种身临其境的感觉。VR技术是通过一系列的硬件和软件来实现的,包括头戴显示器、数据手套、跟踪系统、三维声音系统、高性能计算机等。
VR技术的应用
特征贡献的Shapley分析:深入理解模型复杂度的实用方法
# 1. 特征贡献的Shapley分析概述
在数据科学领域,模型解释性(Model Explainability)是确保人工智能(AI)应用负责任和可信赖的关键因素。机器学习模型,尤其是复杂的非线性模型如深度学习,往往被认为是“黑箱”,因为它们的内部工作机制并不透明。然而,随着机器学习越来越多地应用于关键决策领域,如金融风控、医疗诊断和交通管理,理解模型的决策过程变得至关重要
测试集在兼容性测试中的应用:确保软件在各种环境下的表现

# 1. 兼容性测试的概念和重要性
## 1.1 兼容性测试概述
兼容性测试确保软件产品能够在不同环境、平台和设备中正常运行。这一过程涉及验证软件在不同操作系统、浏览器、硬件配置和移动设备上的表现。
## 1.2 兼容性测试的重要性
在多样的IT环境中,兼容性测试是提高用户体验的关键。它减少了因环境差异导致的问题,有助于维护软件的稳定性和可靠性,降低后
【统计学意义的验证集】:理解验证集在机器学习模型选择与评估中的重要性
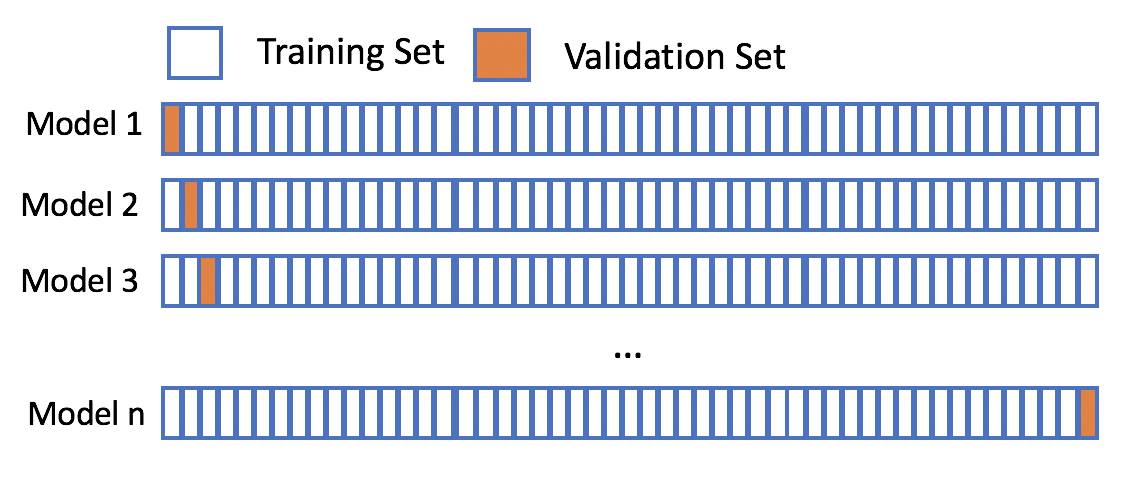
# 1. 验证集的概念与作用
在机器学习和统计学中,验证集是用来评估模型性能和选择超参数的重要工具。**验证集**是在训练集之外的一个独立数据集,通过对这个数据集的预测结果来估计模型在未见数据上的表现,从而避免了过拟合问题。验证集的作用不仅仅在于选择最佳模型,还能帮助我们理解模型在实际应用中的泛化能力,是开发高质量预测模型不可或缺的一部分。
```markdown
## 1.1 验证集与训练集、测试集的区
过拟合的统计检验:如何量化模型的泛化能力

# 1. 过拟合的概念与影响
## 1.1 过拟合的定义
过拟合(overfitting)是机器学习领域中一个关键问题,当模型对训练数据的拟合程度过高,以至于捕捉到了数据中的噪声和异常值,导致模型泛化能力下降,无法很好地预测新的、未见过的数据。这种情况下的模型性能在训练数据上表现优异,但在新的数据集上却表现不佳。
## 1.2 过拟合产生的原因
过拟合的产生通常与模
激活函数在深度学习中的应用:欠拟合克星
# 1. 深度学习中的激活函数基础
在深度学习领域,激活函数扮演着至关重要的角色。激活函数的主要作用是在神经网络中引入非线性,从而使网络有能力捕捉复杂的数据模式。它是连接层与层之间的关键,能够影响模型的性能和复杂度。深度学习模型的计算过程往往是一个线性操作,如果没有激活函数,无论网络有多少层,其表达能力都受限于一个线性模型,这无疑极大地限制了模型在现实问题中的应用潜力。
激活函数的基本
探索性数据分析:训练集构建中的可视化工具和技巧
# 1. 探索性数据分析简介
在数据分析的世界中,探索性数据分析(Exploratory Dat
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )