Python异常处理的艺术:优雅处理函数调用异常案例!
发布时间: 2024-09-20 18:13:19 阅读量: 68 订阅数: 52 
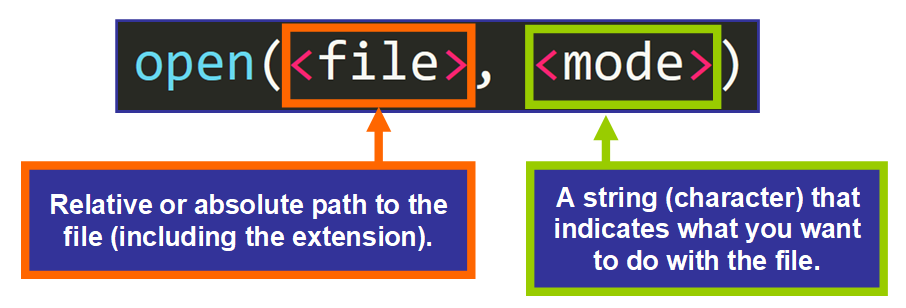
# 1. Python异常处理基础
异常处理是任何编程语言中不可或缺的一部分,而Python凭借其简洁和灵活性,在这一领域提供了多种强大的工具和结构。在编写健壮和可靠的程序时,处理潜在的错误和异常情况是至关重要的。本章我们将介绍Python异常处理的基本概念、语法结构以及一些简单的实践方法。
首先,我们将解释什么是异常以及它在Python中的作用。异常是程序运行时发生的不正常情况,它会打断程序的正常流程。Python通过一套异常处理机制来处理这些事件,这样即使出现错误,程序也不会立即崩溃,而是能够优雅地处理异常并继续执行。我们还将讨论`try-except`语句的使用,这是Python异常处理中最基本的结构,用于捕获和响应可能在程序中发生的异常。通过本章内容的学习,您将为深入理解和应用Python的异常处理打下坚实的基础。
# 2. 掌握异常处理的理论
## 2.1 异常的概念和分类
异常是程序在执行过程中发生的不正常情况,比如文件不存在、网络连接失败、算术运算错误等。它们通常分为两大类:系统异常和用户自定义异常。
### 2.1.1 理解Python中的异常机制
Python中的异常机制为程序提供了错误处理的能力。当异常发生时,程序不会立即崩溃,而是进入异常处理流程。这是通过`try`块和`except`块实现的,其中`try`块用于捕获潜在的异常,而`except`块则用于处理它们。
Python的异常是从`BaseException`派生出来的,它派生出两个主要的子类:`SystemExit`和`Exception`。`SystemExit`用于在程序收到退出请求时引发,而`Exception`是大多数标准异常的基类。开发者需要继承`Exception`来创建自定义异常。
```python
try:
# 尝试执行的代码块
pass
except Exception as e:
# 处理常规异常的代码块
print(f"An exception occurred: {e}")
```
### 2.1.2 常见异常类型详解
Python的标准库和第三方库提供了许多异常类型。例如:
- `ValueError`:当提供的参数值不合适时引发。
- `IndexError`:当索引超出序列的范围时引发。
- `KeyError`:当键值不在字典中时引发。
- `IOError`:当输入输出操作失败时引发,如文件不存在或无法打开。
理解这些异常类型对于编写健壮的代码至关重要。开发者应当根据不同的异常类型,编写不同的处理逻辑,以确保程序在发生错误时能够优雅地处理。
## 2.2 异常处理的关键语法
### 2.2.1 try-except语句的使用
在Python中,使用`try-except`语句处理异常是最基本的方法。`try`块中的代码一旦引发异常,程序将立即跳转到对应的`except`块中。
```python
try:
result = 10 / 0
except ZeroDivisionError:
print("You can't divide by zero!")
```
### 2.2.2 多个except块的处理逻辑
在处理多种类型的异常时,可以使用多个`except`块。一旦匹配到异常,相应的`except`块就会执行,后面的`except`块将被忽略。因此,通常会将更具体的异常类型放在前面,将更通用的异常类型放在后面。
```python
try:
# 执行可能引发不同类型异常的代码
pass
except (ValueError, TypeError):
# 处理ValueError和TypeError
print("One of the values or types is not correct!")
except Exception as e:
# 处理其他所有异常
print(f"An unexpected error occurred: {e}")
```
### 2.2.3 finally子句的作用
`finally`子句是`try-except`语句的可选部分,无论是否发生异常,都会执行`finally`块中的代码。这通常用于执行清理资源的操作,如关闭文件或网络连接。
```python
try:
# 尝试执行的代码块
pass
except Exception as e:
# 异常处理代码块
print(f"An error occurred: {e}")
finally:
# 无论是否发生异常都会执行的代码块
print("Clean up resources here.")
```
## 2.3 异常处理的最佳实践
### 2.3.1 异常捕获与日志记录
异常捕获是控制程序响应错误的方式,而日志记录是记录错误详情以供事后分析的过程。在实际开发中,应当合理地捕获异常并记录相关的错误信息和堆栈跟踪。
```python
import logging
logging.basicConfig(level=logging.ERROR)
try:
# 尝试执行可能出错的代码
pass
except Exception as e:
logging.error("Exception occurred", exc_info=True)
print(f"An error occurred: {e}")
```
### 2.3.2 自定义异常类的设计原则
自定义异常类用于表示程序中特定的错误情况。设计良好的自定义异常类应当继承自`Exception`类,并可能提供额外的方法或属性来描述异常情况。
```python
class CustomError(Exception):
def __init__(self, message):
super().__init__(message)
self.message = message
def __str__(self):
return self.message
try:
raise CustomError("There was a problem!")
except CustomError as e:
print(e)
```
通过设计良好的异常处理机制,可以让程序更加健壮,提高用户体验,并简化后期维护和调试的复杂度。
# 3. 异常处理实践技巧
异常处理不仅仅是一门理论,更是一项需要在实际应用中不断实践和优化的技巧。掌握实践中的技巧能够帮助我们更好地编写健壮、可靠和用户友好的代码。本章将深入探讨在函数中如何处理异常,复杂应用中如何管理异常,以及如何评估异常处理对性能的影响,并提供相关优化技巧。
## 3.1 函数中的异常处理策略
函数是编程中最重要的代码组织和复用方式之一。在编写函数时,必须考虑到如何处理可能发生的异常情况。良好的异常处理策略不仅能够保护函数的使用者免受异常的困扰,也能够给维护者提供清晰的错误信息。
### 3.1.1 处理函数参数异常
函数在被调用时,无法保证传入的参数总是符合预期。如果参数错误,函数需要能够恰当地响应。例如,在进行数学计算的函数中,传入的参数不应该是负数:
```python
def calculate_square_root(number):
if number < 0:
raise ValueError("Cannot calculate square root of negative number.")
return number ** 0.5
```
在上述代码中,如果`number`为负数,我们通过`raise`关键字抛出`ValueError`异常。这种方法可以明确地告知函数调用者犯了什么错误,也使得调试时能够快速定位到问题所在。
### 3.1.2 返回值和异常的平衡
函数可以用返回值来表示错误,而将异常作为更严重或更不可预料的错误处理。例如,在一个文件读

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 函数调用的方方面面,提供了一系列技巧和最佳实践,帮助你提升代码性能和可读性。从函数参数传递的陷阱到高阶函数的巧妙应用,再到装饰器、闭包和递归函数的进阶技巧,本专栏涵盖了广泛的主题。此外,还深入探讨了异步编程、多线程、函数式编程和可调用对象,提供全面且实用的指南。无论你是 Python 初学者还是经验丰富的开发者,本专栏都能为你提供宝贵的见解,让你掌握函数调用的精髓,编写更优雅、更有效的代码。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
解决组合分配难题:偏好单调性神经网络实战指南(专家系统协同)

# 摘要
本文旨在探讨解决组合分配难题的方法,重点关注偏好单调性理论在优化中的应用以及神经网络的实战应用。文章首先介绍了偏好单调性的定义、性质及其在组合优化中的作用,接着深入探讨了如何
WINDLX模拟器案例研究:3个真实世界的网络问题及解决方案

# 摘要
本文对WINDLX模拟器进行了全面概述,并深入探讨了网络问题的理论基础与诊断方法。通过对比OSI七层模型和TCP/IP模型,分析了网络通信中常见的问题及其分类。文中详细介绍了网络故障诊断技术,并通过案例分析方法展示了理论知识在实践中的应用。三个具体案例分别涉及跨网络性能瓶颈、虚拟网络隔离失败以及模拟器内网络服务崩溃的背景、问题诊断、解决方案实施和结果评估。最后,本文展望了W
【FREERTOS在视频处理中的力量】:角色、挑战及解决方案

# 摘要
FreeRTOS在视频处理领域的应用日益广泛,它在满足实时性能、内存和存储限制、以及并发与同步问题方面面临一系列挑战。本文探讨了FreeRTOS如何在视频处理中扮演关键角色,分析了其在高优先级任务处理和资源消耗方面的表现。文章详细讨论了任务调度优化、内存管理策略以及外设驱动与中断管理的解决方案,并通过案例分析了监控视频流处理、实时视频转码
ITIL V4 Foundation题库精讲:考试难点逐一击破(备考专家深度剖析)
# 摘要
ITIL V4 Foundation作为信息技术服务管理领域的重要认证,对从业者在理解新框架、核心理念及其在现代IT环境中的应用提出了要求。本文综合介绍了ITIL V4的考试概览、核心框架及其演进、四大支柱、服务生命周期、关键流程与功能以及考试难点,旨在帮助考生全面掌握ITIL V4的理论基础与实践应用。此外,本文提供了实战模拟
【打印机固件升级实战攻略】:从准备到应用的全过程解析

# 摘要
本文综述了打印机固件升级的全过程,从前期准备到升级步骤详解,再到升级后的优化与维护措施。文中强调了环境检查与备份的重要性,并指出获取合适固件版本和准备必要资源对于成功升级不可或缺。通过详细解析升级过程、监控升级状态并进行升级后验证,本文提供了确保固件升级顺利进行的具体指导。此外,固件升级后的优化与维护策略,包括调整配置、问题预防和持续监控,旨在保持打印机最佳性能。本文还通过案
【U9 ORPG登陆器多账号管理】:10分钟高效管理你的游戏账号

# 摘要
本文详细探讨了U9 ORPG登陆器的多账号管理功能,首先概述了其在游戏账号管理中的重要性,接着深入分析了支持多账号登录的系统架构、数据流以及安全性问题。文章进一步探讨了高效管理游戏账号的策略,包括账号的组织分类、自动化管理工具的应用和安全性隐私保护。此外,本文还详细解析了U9 ORPG登陆器的高级功能,如权限管理、自定义账号属性以及跨平台使用
【编译原理实验报告解读】:燕山大学案例分析
# 摘要
本文是关于编译原理的实验报告,首先介绍了编译器设计的基础理论,包括编译器的组成部分、词法分析与语法分析的基本概念、以及语法的形式化描述。随后,报告通过燕山大学的实验案例,深入分析了实验环境、工具以及案例目标和要求,详细探讨了代码分析的关键部分,如词法分析器的实现和语法分析器的作用。报告接着指出了实验中遇到的问题并提出解决策略,最后展望了编译原理实验的未来方向,包括最新研究动态和对
【中兴LTE网管升级与维护宝典】:确保系统平滑升级与维护的黄金法则

# 摘要
本文详细介绍了LTE网管系统的升级与维护过程,包括升级前的准备工作、平滑升级的实施步骤以及日常维护的策略。文章强调了对LTE网管系统架构深入理解的重要性,以及在升级前进行风险评估和备份的必要性。实施阶段,作者阐述了系统检查、性能优化、升级步骤、监控和日志记录的重要性。同时,对于日常维护,本文提出监控KPI、问题诊断、维护计划执行以及故障处理和灾难恢复措施。案例研究部分探讨了升级维护实践中的挑战与解决方案。最后,文章展望了LT
故障诊断与问题排除:合泰BS86D20A单片机的自我修复指南
# 摘要
本文系统地介绍了故障诊断与问题排除的基础知识,并深入探讨了合泰BS86D20A单片机的特性和应用。章节二着重阐述了单片机的基本概念、硬件架构及其软件环境。在故障诊断方面,文章提出了基本的故障诊断方法,并针对合泰BS86D20A单片机提出了具体的故障诊断流程和技巧。此外,文章还介绍了问题排除的高级技术,包括调试工具的应用和程序自我修复技术。最后,本文就如何维护和优化单片
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )