Hibernate中缓存机制及性能优化策略
发布时间: 2024-02-25 16:12:07 阅读量: 28 订阅数: 21 
# 1. Hibernate中的缓存概述
Hibernate中的缓存是一个重要的性能优化和提升系统响应速度的利器。在本章节中,我们将深入探讨Hibernate中的缓存概念、作用以及三级缓存结构。
## 1.1 Hibernate中的缓存基本概念
在Hibernate中,缓存是指将数据库中的数据缓存在内存中,以提高数据的访问速度和降低对数据库的频繁访问,从而提升系统的性能。
## 1.2 缓存的作用及优势
Hibernate缓存的作用主要是减少对数据库的查询操作,降低系统的IO消耗,提高系统的响应速度,同时可以降低系统的负载压力和数据库压力。
## 1.3 Hibernate中的三级缓存结构
Hibernate中的三级缓存包括一级缓存(Session缓存)、二级缓存(SessionFactory级别缓存)和查询缓存(Query Cache)。通过这三级缓存结构,可以实现不同粒度的缓存数据共享和管理。
在接下来的章节中,我们将逐步深入探讨Hibernate缓存的机制及性能优化策略。
# 2. Hibernate缓存机制详解
Hibernate中的缓存机制是提高系统性能和响应速度的重要手段之一。在这一章节中,我们将详细探讨Hibernate中的缓存机制,包括一级缓存(Session缓存)、二级缓存(SessionFactory级别缓存)和查询缓存(Query Cache)的原理和使用方式。
### 2.1 一级缓存(Session缓存)的工作原理
一级缓存是与Session对象绑定的缓存,也称为Session缓存。当从数据库中读取数据时,数据会被存储在Session的缓存中。如果再次查询相同的数据,Hibernate会首先检查Session缓存中是否存在,如果存在则直接返回缓存中的数据,而不需要再次访问数据库。这种机制可以减少数据库的访问次数,提高性能。
```java
// 示例代码
Session session = sessionFactory.openSession();
Transaction tx = session.beginTransaction();
// 第一次查询,数据存储在一级缓存中
User user1 = session.get(User.class, 1L);
System.out.println(user1.getName());
// 第二次查询,直接从缓存中获取数据,不需要访问数据库
User user2 = session.get(User.class, 1L);
System.out.println(user2.getName());
tx.commit();
session.close();
```
**代码总结:**
- 当两次查询中使用相同的Session对象并且第一次查询结果未被修改时,第二次查询会直接从一级缓存中获取数据,而不会访问数据库。
- 一级缓存是默认开启的,无法关闭,与Session的生命周期绑定。
**结果说明:**
- 输出结果会显示两次相同的用户名称,因为第二次查询直接从一级缓存中获取数据。
### 2.2 二级缓存(SessionFactory级别缓存)的实现原理
二级缓存是在SessionFactory级别的缓存,多个Session共享同一个二级缓存。当一个Session从数据库中读取数据后,数据会被存储在二级缓存中。当其他Session需要相同的数据时,会先在二级缓存中查找,如果存在则直接返回数据,避免了多次访问数据库。
```java
// 示例代码
// 配置User实体启用二级缓存
@Entity
@Cacheable
@Cache(usage = CacheConcurrencyStrategy.READ_WRITE)
public class User {
// 实体映射信息
}
// 获取SessionFactory对象
SessionFactory sessionFactory = new Configuration().configure().buildSessionFactory();
Session session1 = sessionFactory.openSession();
Transaction tx1 = session1.beginTransaction();
// 第一次查询,数据存储在二级缓存中
User user1 = session1.get(User.class, 1L);
System.out.println(user1.getName());
tx1.commit();
session1.close();
Session session2 = sessionFactory.openSession();
Transaction tx2 = session2.beginTransaction();
// 第二次查询,直接从二级缓存中获取数据,不需要访问数据库
User user2 = session2.get(User.class, 1L);
System.out.println(user2.getName());
tx2.commit();
session2.close();
```
**代码总结:**
- 通过配置实体的@Cacheable和@Cache注解启用实体级别的二级缓存。
- 多个Session可以共享二级缓存中的数据,提高了系统性能。
**结果说明:**
- 输出结果中会显示两次相同的用户名称,因为第二次查询直接从二级缓存中获取数据,而不需要访问数据库。
### 2.3 查询缓存(Query Cache)的使用方式和效果
查询缓存是针对查询结果的缓存,可以缓存查询语句的结果集。当相同的查询被多次执行时,如果启用了查询缓存,Hibernate会缓存查询结果以加快响应速度。
```java
// 示例代码
// 通过Query对象设置启用查询缓存
Query query = session.createQuery("from User u where u.id = :id");
query.setParameter("id", 1L);
query.setCacheable(true);
List<User> users = query.list();
for(User user : users) {
System.out.println(user.getName());
}
```
**代码总结:**
- 通过在Query对象上调用setCacheable(true)启用查询缓存。
- 当相同的查询多次执行时,会直接从查询缓存中获取结果,而不需要重新执行查询语句。
**结果说明:**
- 若多次执行相同的查询,只有第一次会实际执行数据库查询,后续查询会直接从查询缓存中获取结果。
通过这些示例代码和说明,我们对Hibernate中的缓存机制有了更深入的理解。在实陗项目中合理使用缓存可以有效提升系统性能,降低数据库访问压力。
# 3. Hibernate缓存配置及管理
在Hibernate中,缓存的配置和管理是非常重要的,可以通过不同的配置选项和策略来优化应用程序的性能。下面将详细介绍Hibernate中的缓存配置及管理内容:
#### 3.1 缓存配置文件的设置
在Hibernate项目中,可以通过配置文件来指定缓存的相关设置。通常需要在Hibernate配置文件(如hibernate.cfg.xml)中添加以下配置:
```xml
<property name="hibernate.cache.use_second_level_cache">true</property>
<property name="hibernate.cache.use_query_cache">true</property>
<property name="hibernate.cache.region.factory_class">org.hibernate.cache.ehcache.EhCacheRegionFactory</property>
```
通过以上配置,可以启用二级缓存和查询缓存,并指定使用的缓存实现类为EhCacheRegionFactory。
#### 3.2 各种缓存策略的选择与配置
Hibernate提供了多种缓存策略,如:
- **READ_ONLY**:只读缓存,适用于不经常更新的数据。
- **READ_WRITE**:读写缓存,适用于经常被修改的数据。
- **NONSTRICT_READ_WRITE**:非严格的读写缓存,对数据的一致性要求较低。
可以通过以下配置指定缓存策略:
```java
@Cache(usage = CacheConcurrencyStrategy.READ_WRITE)
@Entity
public class User {
// Entity fields and methods
}
```
#### 3.3 缓存区域(Region)的概念和使用
在Hibernate中,缓存区域是缓存对象的逻辑分组,每个缓存对象都属于某个特定的缓存区域。通过使用缓存区域,可以更好地管理缓存对象并控制缓存的大小。
```java
SessionFactory sessionFactory = configuration.buildSessionFactory();
Query query = sessionFactory.getCurrentSession().createQuery("from User where id = :id").setCacheable(true);
List<User> users = query.setParameter("id", 1).list();
```
在以上示例中,我们使用了SessionFactory来获取当前Session,并通过设置查询缓存的方式来缓存查询结果,以提高性能。
以上是关于Hibernate缓存配置及管理的内容,合理的配置和管理缓存可以有效提升应用程序的性能。
# 4. Hibernate缓存性能优化策略
在使用Hibernate缓存时,性能优化是至关重要的。合理地配置缓存策略、实施缓存清理与刷新机制、监控缓存性能,都是提升系统性能的关键。接下来我们将详细介绍Hibernate中缓存性能优化的策略。
#### 4.1 缓存的合理使用与避免滥用
当使用Hibernate缓存时,需要注意以下几点来避免缓存的滥用:
- **避免频繁写入**:频繁写入操作会导致缓存的频繁更新,影响性能,应该谨慎处理写入操作。
- **选择合适的缓存级别**:根据实际情况选择合适的缓存级别,避免一味地将所有数据都缓存。
- **合理设置缓存过期时间**:设置适当的缓存过期时间,避免数据过期导致错误。
#### 4.2 缓存清理策略及缓存刷新机制
为了保持缓存中数据的准确性和一致性,我们需要实施以下策略:
- **手动清理缓存**:定期清理缓存,去除过期数据,保持缓存的可用性。
- **自动刷新缓存**:当数据发生变化时,及时刷新缓存,保证缓存中数据的最新。
- **使用缓存失效监听器**:监听缓存中数据的变化,如数据更新、删除等,及时刷新相关缓存项。
#### 4.3 缓存性能监控与调优
为了不断优化Hibernate缓存的性能,我们需要进行监控与调优:
- **监控缓存命中率**:定期监控缓存的命中率,及时调整缓存策略。
- **监控缓存性能指标**:关注缓存的性能指标,如读写性能,内存占用等,及时调整参数。
- **利用缓存性能工具**:使用专业的缓存性能监控工具,如Redis Monitor、Ehcache Monitor等,帮助进行性能分析与优化。
通过以上性能优化策略,可以帮助我们更好地提升Hibernate应用的性能,提高系统的稳定性和可靠性。
# 5. 常见Hibernate缓存问题及解决方案
在Hibernate缓存的应用过程中,经常会面临一些常见的问题,需要针对这些问题制定相应的解决方案。在本章节中,我们将讨论一些常见的Hibernate缓存问题,并提供相应的解决方案。
#### 5.1 缓存并发访问引发的问题与解决方案
在实际应用中,当多个线程同时访问缓存数据时,可能会出现并发访问引发的一系列问题,如数据不一致、脏数据等。为了解决这些问题,我们可以采取以下几种解决方案:
- **使用版本控制机制**:通过版本控制机制(如乐观锁、悲观锁)来保证数据的一致性和完整性,从而避免并发访问引发的问题。
- **加锁机制**:在访问缓存数据时,采用加锁的方式来确保同一时刻只有一个线程可以对数据进行修改,以避免并发修改引发的问题。
- **使用分布式锁**:当涉及分布式环境下的缓存并发访问时,可以考虑使用分布式锁来协调对共享数据的访问,确保数据的一致性和完整性。
#### 5.2 缓存中数据一致性的处理方式
由于缓存数据可能与数据库数据存在一定的延迟,因此会带来数据一致性的问题。针对这一问题,我们可以采取以下策略来处理数据一致性:
- **定时刷新缓存**:定时刷新缓存中的数据,保持缓存数据与数据库数据的一致性。
- **基于事件驱动的缓存更新**:通过监听数据库变化的事件,及时更新对应的缓存数据,从而保持数据一致性。
- **缓存失效策略**:在数据发生变化时,及时使缓存数据失效,下次访问时重新加载最新数据,确保数据的一致性。
#### 5.3 Hibernate缓存与数据库事务的协调
在Hibernate缓存与数据库事务协调的过程中,存在一些需要注意的问题,我们需要合理处理缓存与数据库事务的关系:
- **缓存与事务的隔离级别**:在并发访问的场景下,需要合理设置缓存与数据库事务的隔离级别,以确保数据的一致性和并发访问的效率。
- **事务提交与缓存更新策略**:在事务提交时,需要合理选择缓存数据的更新策略,保证事务提交后缓存数据与数据库数据保持一致。
以上是一些常见的Hibernate缓存问题及相应的解决方案,需要根据实际场景进行合理选择和应用,以确保Hibernate缓存在实际项目中的稳定和高效运行。
# 6. 实际应用中的Hibernate缓存实践
在实际项目中,Hibernate缓存是一个非常重要的性能优化手段。通过合理地配置和管理Hibernate缓存,可以有效降低数据库访问频率,提升系统性能。本章将深入探讨在实际应用中如何使用Hibernate缓存,并通过实际案例展示最佳实践方案。
#### 6.1 在实际项目中如何应用Hibernate缓存
在实际项目中,我们通常会遇到大量的数据库查询操作,而这些查询操作往往会导致性能瓶颈。而Hibernate缓存的使用能够有效减少数据库查询次数,提高系统性能。在实际项目中,我们可以通过以下方式应用Hibernate缓存:
**示例代码:**
```java
// Hibernate实体类
@Entity
@Table(name = "product")
@Cache(usage = CacheConcurrencyStrategy.READ_WRITE)
public class Product {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private BigDecimal price;
// 省略其他字段和方法
}
```
```java
// Hibernate DAO类
@Repository
public class ProductDAO {
@Autowired
private SessionFactory sessionFactory;
public Product getProductById(Long id) {
Session session = sessionFactory.getCurrentSession();
return session.get(Product.class, id);
}
}
```
**代码总结:**
- 在Hibernate实体类上通过`@Cache`注解指定缓存策略;
- 在DAO类中通过`session.get()`方法获取实体对象,Hibernate会在一级缓存和二级缓存中查找数据;
**结果说明:**
- 当多次查询同一实体对象时,第一次会从数据库加载数据并放入缓存,后续查询会直接从缓存获取数据,减少数据库查询次数,提高性能。
#### 6.2 实际案例分析及解决方案展示
在实际项目中,我们可能会遇到缓存数据与数据库数据不一致的情况,这时需要采取相应的解决方案。一个常见的案例是缓存数据的更新操作:
**示例代码:**
```java
@Service
public class ProductService {
@Autowired
private ProductDAO productDAO;
@Transactional
public void updateProductPrice(Long id, BigDecimal newPrice) {
Product product = productDAO.getProductById(id);
product.setPrice(newPrice);
productDAO.saveOrUpdateProduct(product);
}
}
```
**代码总结:**
- 在更新操作中,先从缓存获取实体对象进行修改,再通过DAO保存更新后的实体对象;
- 通过事务管理,确保更新操作的原子性,避免缓存数据与数据库数据不一致。
**结果说明:**
- 保证了缓存数据与数据库数据的一致性,避免数据脏读的问题。
#### 6.3 Hibernate缓存优化的最佳实践建议
为了充分利用Hibernate缓存提升系统性能,在实践中需要注意以下几点最佳实践建议:
1. 避免缓存雪崩:合理设置缓存失效时间,避免大量缓存同时失效导致数据库压力剧增;
2. 缓存预热:在系统启动时预加载常用数据,提高命中率,减少冷启动时的性能损耗;
3. 合理配置缓存策略:根据业务需求选择合适的缓存策略,如READ_ONLY、READ_WRITE等;
4. 监控缓存性能:定时监控缓存命中率、缓存命中效率等指标,及时调整缓存配置。
通过以上最佳实践建议,可以更好地应用Hibernate缓存,提高系统性能,优化用户体验。
本章内容对实际项目中Hibernate缓存实践进行了详细介绍,希望能够帮助读者更好地理解和应用Hibernate缓存。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【多语言应用国际化的秘诀】:Fluent中文帮助文档策略解析
参考资源链接:[ANSYS Fluent中文帮助文档:全面指南(1-28章)](https://wenku.csdn.net/doc/6461921a543f8444889366dc?spm=1055.2635.3001.10343)
# 1. 多语言应用国际化的重要性
在全球化的数字时代,多语言应用的国际化变得至关重要。随着信息技术的迅猛发展,企业开始寻求更广阔的市场
日立电子扫描电镜的电子光学系统详解:彻底了解原理与操作

参考资源链接:[日立电子扫描电镜操作指南:V23版](https://wenku.csdn.net/doc/6412b712be7fbd1778d48fb7?spm=1055.2635.3001.10343)
# 1. 日立电子扫描电镜概述
日立电子扫描电镜(Scanning Electron Microscope, SEM)是利用聚焦的高能电子束扫描样品表面,以获得样品表面形貌和成分信息的仪器。它具有卓越的分辨率,可以达到纳米级别的成像,因此在
模块化开发:AutoHotkey构建可复用代码块的最佳实践

参考资源链接:[AutoHotkey 1.1.30.01中文版教程与更新一览](https://wenku.csdn.net/doc/6469aeb1543f844488c1a7ea?spm=1055.2635.3001.10343)
# 1. 模块化开发的基本概念
在现代软件开发领域,模块化开发已经成为提高代码质量、提升开发效率和便于维护的关键实践之一。
【Symbol LS2208无线通信优化指南】:提高无线扫描枪性能的秘诀
参考资源链接:[Symbol LS2208扫描枪设置详解与常见问题解决方案](https://wenku.csdn.net/doc/6412b67ebe7fbd1778d46ec5?spm=1055.2635.3001.10343)
# 1. 无线通信基础与无线扫描枪概述
## 1.1 无线通信的演化
无线通信技术自20世纪初开始发展以来,已经历了从简单的无线电报到当前的4G、5G网络的巨大飞跃。每一阶段的变革都是基于更高频段、更先进调
【环境科学中的fsolve应用】:模拟与预测环境变化的数学模型

参考资源链接:[MATLAB fsolve函数详解:求解非线性方程组](https://wenku.csdn.net/doc/6471b
阿里巴巴Java多线程与并发控制:规范引导下的性能优化与问题解决
参考资源链接:[阿里巴巴Java编程规范详解](https://wenku.csdn.net/doc/646dbdf9543f844488d81454?spm=1055.2635.3001.10343)
# 1. Java多线程基础和并发模型
Java多线程编程是构建高效、可伸缩应用程序的关键技术之一。在本章中,我们将探索Java多线程的基础知识和并发模型的原理,为深入理解后续章节的高级概念打下坚实的基础。
## 1.1 Java多线程基础
74LS90与可编程逻辑设备的比较分析:优势、局限及选择指南

参考资源链接:[74LS90引脚功能及真值表](https://wenku.csdn.net/doc/64706418d12cbe7ec3fa9083?spm=1055.2635.3001.10343)
# 1. 74LS90与可编程逻辑设备基础
在数字电子设计领域,理解基本组件和可编程逻辑设备的概念是至关重要的。本章旨在为读者提供74LS90这种固定功
【Vcomputer存储软件高级配置技巧】:提升存储效率的7大秘密武器
参考资源链接:[桂林电子科大计算机教学辅助软件:Vcomputer软件包](https://wenku.csdn.net/doc/7gix61gm88?spm=1055.2635.3001.10343)
# 1. Vcomputer存储软件概述
随着信息技术的不
SENT vs CAN协议:汽车通信网络中最佳选择与集成指南
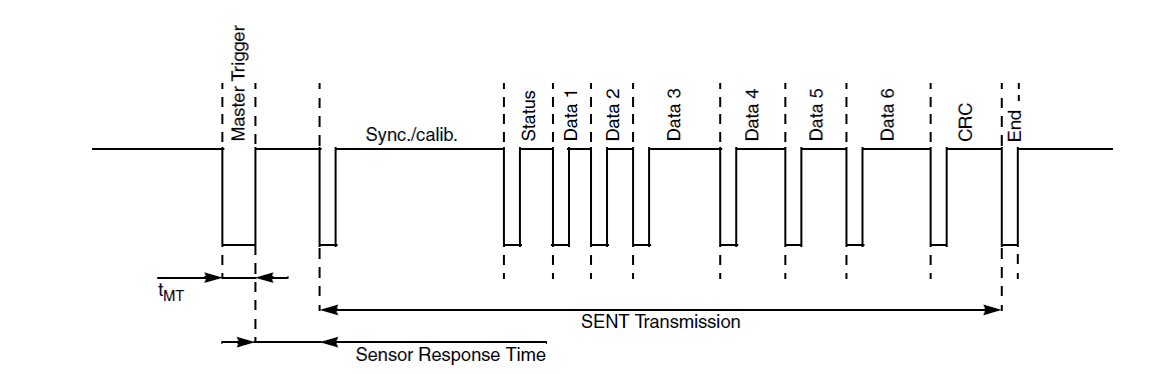
参考资源链接:[SAE J2716_201604 (SENT协议).pdf](https://wenku.csdn.net/doc/6412b704be7fbd1778d48caf?spm=1055.2635.3001.10343)
# 1. 汽车通信网络协议概述
汽车通信网络协议是现代汽车电子系统运作的基础。随着汽车技术的不断进步,各种传感器、执行器、控制单元
【外围设备集成】:ESP32最小系统外围设备集成与扩展性探讨

参考资源链接:[ESP32 最小系统原理图.pdf](https://wenku.csdn.net/doc/6401abbbcce7214c316e94cc?spm=1055.2635.3001.10343)
# 1. ESP32概述与最小系统构成
ES
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )