RESTful API开发指南
发布时间: 2023-12-20 15:25:40 阅读量: 44 订阅数: 37 

Python语言开发RESTful API指南
# 1. 什么是RESTful API
## 1.1 了解RESTful API的基础概念
RESTful API(Representational State Transfer,表述性状态转移)是一种基于HTTP协议构建的网络应用程序接口。它遵循一系列的设计原则和约束,使得不同客户端和服务端之间可以进行有效的通信和交互。
RESTful API的核心概念包括资源(Resource)、表述(Representation)和状态转移(State Transfer)。资源是API提供的数据或服务的抽象,可以用URI(Uniform Resource Identifier)来唯一标识。表述则是资源的具体呈现形式,可以是JSON、XML等数据格式。状态转移指的是通过HTTP动词对资源进行操作,例如GET用于获取资源,POST用于创建资源,PUT用于更新资源,DELETE用于删除资源。
## 1.2 RESTful API的优点和特点
RESTful API具有以下优点和特点:
- 简单统一:RESTful API使用统一的接口设计原则,简化了开发和维护的复杂性。
- 可伸缩性:由于RESTful API的无状态性,可以方便地进行系统的横向扩展。
- 可缓存性:RESTful API支持HTTP的缓存机制,提高了响应速度和系统的性能。
- 可见性:RESTful API使用明确的URI来标识资源,提供了可见性和可访问性。
- 可移植性:由于使用标准的HTTP协议和数据格式,RESTful API可以在不同平台和语言之间互操作。
综上所述,RESTful API是一种灵活、简洁且易于扩展的API设计风格,适用于各种网络应用程序的开发和集成。在接下来的章节中,我们将深入探讨RESTful API的设计原则、认证与授权、数据传输和格式、性能优化和安全性等方面的内容。
# 2. RESTful API的设计原则
在设计RESTful API时,有一些原则和最佳实践可以帮助开发人员提供一致、易用和可扩展的API。以下是一些常见的RESTful API设计原则:
### 2.1 定义资源和URL结构
在RESTful API中,一切都是关于资源的。每个资源都应该有一个唯一的标识符,并通过URL来表示。URL结构应该简洁、直观,并且符合常规的命名约定。
**示例代码(Python):**
```python
from flask import Flask
app = Flask(__name__)
@app.route('/users', methods=['GET'])
def get_users():
# 获取所有用户的逻辑
pass
@app.route('/users/<user_id>', methods=['GET'])
def get_user(user_id):
# 获取指定用户的逻辑
pass
@app.route('/users', methods=['POST'])
def create_user():
# 创建用户的逻辑
pass
@app.route('/users/<user_id>', methods=['PUT'])
def update_user(user_id):
# 更新指定用户的逻辑
pass
@app.route('/users/<user_id>', methods=['DELETE'])
def delete_user(user_id):
# 删除指定用户的逻辑
pass
if __name__ == '__main__':
app.run()
```
**代码总结:** 上述示例展示了如何定义用户资源的URL结构,包括获取所有用户、获取指定用户、创建用户、更新用户和删除用户的操作。
### 2.2 使用HTTP动词进行操作
RESTful API借助HTTP动词来表示对资源的操作,常用的HTTP动词包括GET、POST、PUT和DELETE。对应不同的操作类型,使用相应的HTTP动词进行定义。
**示例代码(Java):**
```java
@RestController
@RequestMapping("/users")
public class UserController {
@GetMapping
public List<User> getUsers() {
// 获取所有用户的逻辑
}
@GetMapping("/{user_id}")
public User getUser(@PathVariable("user_id") String userId) {
// 获取指定用户的逻辑
}
@PostMapping
public User createUser(@RequestBody User user) {
// 创建用户的逻辑
}
@PutMapping("/{user_id}")
public User updateUser(@PathVariable("user_id") String userId, @RequestBody User user) {
// 更新指定用户的逻辑
}
@DeleteMapping("/{user_id}")
public void deleteUser(@PathVariable("user_id") String userId) {
// 删除指定用户的逻辑
}
}
```
**代码总结:** 上述示例展示了如何使用Spring MVC框架以及相应的HTTP动词定义用户资源的操作。
### 2.3 使用状态码和错误处理
RESTful API应该返回适当的状态码,以便客户端能够根据状态码进行不同的处理。常见的状态码包括200 OK(请求成功)、404 Not Found(资源不存在)、400 Bad Request(无效的请求)等。
**示例代码(Go):**
```go
package main
import (
"net/http"
"github.com/gorilla/mux"
)
func GetUsers(w http.ResponseWriter, r *http.Request) {
// 获取所有用户的逻辑
}
func GetUser(w http.ResponseWriter, r *http.Request) {
// 获取指定用户的逻辑
}
func CreateUser(w http.ResponseWriter, r *http.Request) {
// 创建用户的逻辑
}
func UpdateUser(w http.ResponseWriter, r *http.Request) {
// 更新指定用户的逻辑
}
func DeleteUser(w http.ResponseWriter, r *http.Request) {
// 删除指定用户的逻辑
}
func main() {
r := mux.NewRouter()
api := r.PathPrefix("/api/v1").Subrouter()
api.HandleFunc("/users", GetUsers).Methods("GET")
api.HandleFunc("/users/{user_id}", GetUser).Methods("GET")
api.HandleFunc("/users", CreateUser).Methods("POST")
api.HandleFunc("/users/{user_id}", UpdateUser).Methods("PUT")
api.HandleFunc("/users/{user_id}", DeleteUser).Methods("DELETE")
http.Handle("/", r)
http.ListenAndServe(":8080", nil)
}
```
**代码总结:** 上述示例展示了如何使用Gorilla Mux库以及状态码进行错误处理。
### 2.4 考虑API版本控制
随着API的演进,可能需要引入新的功能或进行不兼容的更改。为了保证对现有客户端的兼容性,可以考虑对API进行版本控制。常见的版本控制方式包括在URL中添加版本号或使用HTTP请求头部进行指定。
**示例代码(JavaScript):**
```javascript
const express = require('express');
const app = express();
// API v1
app.get('/api/v1/users', (req, res) => {
// 获取所有用户的逻辑
});
app.get('/api/v1/users/:user_id', (req, res) => {
// 获取指定用户的逻辑
});
app.post('/api/v1/users', (req, res) => {
// 创建用户的逻辑
});
app.put('/api/v1/users/:user_id', (req, res) => {
// 更新指定用户的逻辑
});
app.delete('/api/v1/users/:user_id', (req, res) => {
// 删除指定用户的逻辑
});
app.listen(3000, () => {
console.log('Server started on port 3000');
});
```
**代码总结:** 上述示例展示了如何使用Express框架以及在URL中添加版本号进行API版本控制。
### 2.5 实现数据过滤和排序
有时候,客户端可能只需要获取部分数据或按特定条件进行排序。在API设计中,可以考虑提供数据过滤和排序的功能,通过查询参数来指定过滤和排序的条件。
**示例代码(Python):**
```python
from flask import Flask, request
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
db = SQLAlchemy(app)
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(50))
age = db.Column(db.Integer)
@app.route('/users', methods=['GET'])
def get_users():
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
该专栏涵盖了广泛的.NET技术主题,从ASP.NET核心技术详解到MVC设计模式在.NET中的应用,再到使用Entity Framework进行.NET数据访问,以及RESTful API开发指南等方面详细解析。同时还介绍了ASP.NET Core中的身份验证与授权,使用Azure云平台构建.NET应用,以及在.NET中的并发编程和WebSockets的实战应用等。此外,专栏还探讨了WCF服务端与客户端开发、使用SignalR实现实时通讯应用,微服务架构与.NET Core等话题。同时,还介绍了使用LINQ进行数据查询与操作、ASP.NET中的前后端分离开发、Dapper与ADO.NET性能比较与优化,以及Windows服务开发与部署和性能优化等重要内容。无论是初学者还是有经验的开发人员,本专栏都将为大家提供有关.NET的详实信息和指导,助您在.NET开发中取得更好的成果。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【GSEA基础入门】:掌握基因集富集分析的第一步

# 摘要
基因集富集分析(GSEA)是一种广泛应用于基因组学研究的生物信息学方法,其目的是识别在不同实验条件下显著改变的生物过程或通路。本文首先介绍了GSEA的理论基础,并与传统基因富集分析方法进行比较,突显了GSEA的核心优势。接着,文章详细叙述了GSEA的操作流程,包括软件安装配置、数据准备与预处理、以及分析步骤的讲解。通过实践案例分析,展示了GSEA在疾病相关基因集和药物作用机制研究中的应用,以及结果的
【ISO 14644标准的终极指南】:彻底解码洁净室国际标准
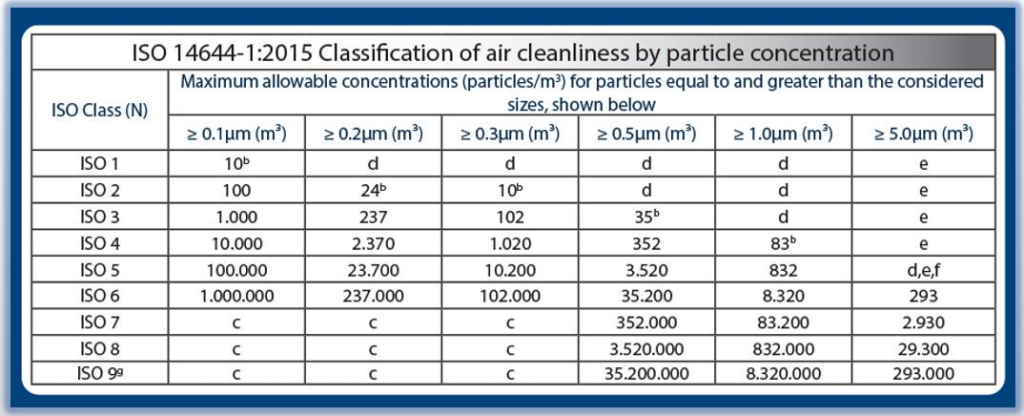
# 摘要
本文系统阐述了ISO 14644标准的各个方面,从洁净室的基础知识、分类、关键参数解析,到标准的详细解读、环境控制要求以及监测和维护。此外,文章通过实际案例探讨了ISO 14644标准在不同行业的实践应用,重点分析了洁净室设计、施工、运营和管理过程中的要点。文章还展望了洁净室技术的发展趋势,讨论了实施ISO 14644标准所
【从新手到专家】:精通测量误差统计分析的5大步骤

# 摘要
测量误差统计分析是确保数据质量的关键环节,在各行业测量领域中占有重要地位。本文首先介绍了测量误差的基本概念与理论基础,探讨了系统误差、随机误差、数据分布特性及误差来源对数据质量的影响。接着深入分析了误差统计分析方法,包括误差分布类型的确定、量化方法、假设检验以及回归分析和相关性评估。本文还探讨了使用专业软件工具进行误差分析的实践,以及自编程解决方案的实现步骤。此外,文章还介绍了测量误差统计分析的高级技巧,如误差传递、合
【C++11新特性详解】:现代C++编程的基石揭秘
# 摘要
C++11作为一种现代编程语言,引入了大量增强特性和工具库,极大提升了C++语言的表达能力及开发效率。本文对C++11的核心特性进行系统性概览,包括类型推导、模板增强、Lambda表达式、并发编程改进、内存管理和资源获取以及实用工具和库的更新。通过对这些特性的深入分析,本文旨在探讨如何将C++11的技术优势应用于现代系统编程、跨平台开发,并展望C++11在未来
【PLC网络协议揭秘】:C#与S7-200 SMART握手全过程大公开
# 摘要
本文旨在详细探讨C#与S7-200 SMART PLC之间通信协议的应用,特别是握手协议的具体实现细节。首先介绍了PLC与网络协议的基础知识,随后深入分析了S7-200 SMART PLC的特点、网络配置以及PLC通信协议的概念和常见类型。文章进一步阐述了C#中网络编程的基础知识,为理解后续握手协议的实现提供了必要的背景。在第三章,作者详细解读了握手协议的理论基础和实现细节,包括数据封装与解析的规则和方法。第四章提供了一个实践案例,详述了开发环境的搭建、握手协议的完整实现,以及在实现过程中可能遇到的问题和解决方案。第五章进一步讨论了握手协议的高级应用,包括加密、安全握手、多设备通信等
电脑微信"附近的人"功能全解析:网络通信机制与安全隐私策略
# 摘要
本文综述了电脑微信"附近的人"功能的架构和隐私安全问题。首先,概述了"附近的人"功能的基本工作原理及其网络通信机制,包括数据交互模式和安全传输协议。随后,详细分析了该功能的网络定位机制以及如何处理和保护定位数据。第三部分聚焦于隐私保护策略和安全漏洞,探讨了隐私设置、安全防护措施及用户反馈。第四章通过实际应用案例展示了"附近的人"功能在商业、社会和
Geomagic Studio逆向工程:扫描到模型的全攻略
# 摘要
本文系统地介绍了Geomagic Studio在逆向工程领域的应用。从扫描数据的获取、预处理开始,详细阐述了如何进行扫描设备的选择、数据质量控制以及预处理技巧,强调了数据分辨率优化和噪声移除的重要性。随后,文章深入讨论了在Geomagic Studio中点云数据和网格模型的编辑、优化以及曲面模型的重建与质量改进。此外,逆向工程模型在不同行业中的应用实践和案例分析被详细探讨,包括模型分析、改进方法论以及逆向工程的实际应用。最后,本文探
大数据处理:使用Apache Spark进行分布式计算

# 摘要
Apache Spark是一个为高效数据处理而设计的开源分布式计算系统。本文首先介绍了Spark的基本概念及分布式计算的基础知识,然后深入探讨了Spark的架构和关键组件,包括核心功能、SQL数据处理能力以及运行模式。接着,本文通过实践导向的方式展示了Spark编程模型、高级特性以及流处理应用的实际操作。进一步,文章阐述了Spark MLlib机器学习库和Gr
【FPGA时序管理秘籍】:时钟与延迟控制保证系统稳定运行

# 摘要
随着数字电路设计的复杂性增加,FPGA时序管理成为保证系统性能和稳定性的关键技术。本文首先介绍了FPGA时序管理的基础知识,深入探讨了时钟域交叉问题及其对系统稳定性的潜在影响,并且分析了多种时钟域交叉处理技术,包括同步器、握手协议以及双触发器和时钟门控技术。在延迟控制策略方面,本文阐述了延
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )