【Java基础篇】:核心概念的深度解读与实践技巧
发布时间: 2024-09-22 05:01:20 阅读量: 106 订阅数: 41 

Java面试核心知识点精讲-原理篇

# 1. Java语言概述与核心思想
Java语言自1995年诞生以来,以其“一次编写,到处运行”的跨平台能力迅速风靡全球,成为众多开发者首选的编程语言。它的核心思想是“Write Once, Run Anywhere”(WORA),这一理念通过Java虚拟机(JVM)来实现。JVM在不同的操作系统上提供了一个抽象层,使得Java程序在不同的平台上无需修改即可运行。
在Java的发展过程中,它的核心设计哲学逐渐扩展为面向对象编程(OOP)。Java语言完全支持OOP的四大基本原则:封装、继承、多态和抽象。这不仅让代码更加模块化,易于维护,而且还提高了代码的可重用性。随着Java不断更新,其生态系统中新增了lambda表达式、流API等现代编程范式,为开发者提供了更多的编程模式和工具。
Java的开发者,Sun Microsystems(现为甲骨文公司所有),在设计之初就赋予了Java语言强大的库支持和安全性,这些特点至今仍被看作是Java的亮点之一。通过本章的深入学习,我们将对Java的这些核心概念有一个全面的了解,为进一步学习Java面向对象编程、异常处理、并发编程以及性能优化奠定坚实的基础。
# 2. Java面向对象编程深入探讨
## 2.1 类与对象的基本概念
### 2.1.1 类的定义和对象的创建
在Java中,类是构造对象的蓝图或模板。类中封装了状态(属性)和行为(方法)。创建对象的过程称为实例化,它涉及调用类的构造器。构造器是一种特殊的方法,用于在创建对象时初始化对象的状态。
```java
// 定义一个名为Person的类
public class Person {
// 类的属性
String name;
int age;
// 类的构造器
public Person(String name, int age) {
this.name = name;
this.age = age;
}
// 类的方法
public void introduce() {
System.out.println("Hello, my name is " + name + " and I am " + age + " years old.");
}
}
// 创建Person类的对象实例
public class Main {
public static void main(String[] args) {
Person person = new Person("Alice", 30);
person.introduce();
}
}
```
在上面的示例代码中,`Person`类定义了两个属性`name`和`age`,以及一个构造器用于初始化这两个属性。`introduce`方法用于打印人的名字和年龄。在`main`方法中,我们实例化了一个`Person`对象,并调用了`introduce`方法来展示信息。
### 2.1.2 类与对象的关系及实例化过程
类与对象的关系可以理解为“类型”与“实例”的关系。类定义了对象将要拥有的属性和方法,而对象是具体存在的个体,拥有类中定义的属性值和可执行的行为。
实例化过程涉及以下步骤:
1. **内存分配**:Java虚拟机(JVM)为新对象分配内存。
2. **属性初始化**:使用构造器初始化对象的属性。
3. **构造器执行**:构造器中的代码被执行,可以是属性的进一步配置或其他对象的初始化。
4. **引用返回**:对象的引用被返回给创建者,创建者可以使用这个引用来访问对象。
```java
// 定义一个名为Car的类
class Car {
String make;
String model;
int year;
public Car(String make, String model, int year) {
this.make = make;
this.model = model;
this.year = year;
}
public void displayInfo() {
System.out.println("Car Info: " + make + " " + model + " " + year);
}
}
// 使用Car类来创建对象实例
public class Main {
public static void main(String[] args) {
Car car1 = new Car("Toyota", "Corolla", 2020);
car1.displayInfo();
Car car2 = new Car("Ford", "Mustang", 2018);
car2.displayInfo();
}
}
```
在上面的代码中,我们定义了一个`Car`类,并使用它的构造器来创建两个`Car`对象实例。每个对象都拥有不同的属性值,代表不同的汽车实例。
## 2.2 封装、继承与多态的实现机制
### 2.2.1 封装的原理和实践技巧
封装是面向对象编程中的一个核心原则,它的基本思想是将对象的状态隐藏在内部,只通过提供的公共方法来访问这些状态。这样做可以隐藏对象的内部实现细节,防止外部代码随意修改对象状态,确保数据的完整性和安全性。
```java
// 封装的Person类实例
public class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public void introduce() {
System.out.println("Hello, my name is " + name + " and I am " + age + " years old.");
}
}
```
在上面的`Person`类中,`name`和`age`属性被设置为`private`,这意味着它们不能从类的外部直接访问。相反,我们提供了公共的方法`getName()`, `setName()`, `getAge()`, 和`setAge()`来间接访问和修改这些属性。
### 2.2.2 继承的深度剖析
继承是面向对象编程中用于表示类之间“is-a”关系的概念。子类继承父类的属性和方法,并且可以添加新的属性和方法或者重写父类的方法。
```java
// 继承关系的基类Person
class Person {
private String name;
private int age;
// 构造器、方法省略...
}
// 继承Person类的Employee类
class Employee extends Person {
private String department;
private double salary;
public Employee(String name, int age, String department, double salary) {
super(name, age); // 调用父类的构造器
this.department = department;
this.salary = salary;
}
// 方法重写和其他新增方法省略...
}
```
在上面的代码中,`Employee`类继承自`Person`类。`Employee`类的构造器使用`super(name, age)`来调用父类的构造器。这样可以确保在创建`Employee`对象时,父类`Person`的状态也被正确初始化。
### 2.2.3 多态的条件与应用
多态是允许我们将不同的对象以统一的方式进行处理的能力。在Java中,多态主要通过方法重载和重写来实现,以及接口的使用。
```java
// 定义一个接口Shape
interface Shape {
double calculateArea();
}
// 一个实现了Shape接口的类Rectangle
class Rectangle implements Shape {
private double width;
private double height;
public Rectangle(double width, double height) {
this.width = width;
this.height = height;
}
@Override
public double calculateArea() {
return width * height;
}
}
// 定义一个接口Vehicle
interface Vehicle {
void startEngine();
}
// 一个实现了Vehicle接口的类Car
class Car implements Vehicle {
public void startEngine() {
System.out.println("Car engine started.");
}
}
// 使用多态
public class Main {
public static void main(String[] args) {
Shape rectangle = new Rectangle(10, 5);
Vehicle car = new Car();
displayArea(rectangle);
startEngine(car);
}
public static void displayArea(Shape shape) {
System.out.println("Area: " + shape.calculateArea());
}
public static void startEngine(Vehicle vehicle) {
vehicle.startEngine();
}
}
```
在这个例子中,我们定义了两个接口`Shape`和`Vehicle`,以及分别实现了它们的类`Rectangle`和`Car`。在`main`方法中,我们通过接口类型的引用来实现多态操作,这意味着我们可以在不关心对象具体类型的情况下调用它们的方法。
## 2.3 面向对象设计原则
### 2.3.1 SOLID原则解析
SOLID是一个缩写,代表了五个面向对象设计原则,旨在使软件更加灵活和可维护:
- **单一职责原则 (Single Responsibility Principle, SRP)**:一个类应该只有一个改变的理由。
- **开闭原则 (Open/Closed Principle, OCP)**:软件实体应当对扩展开放,对修改关闭。
- **里氏替换原则 (Liskov Substitution Principle, LSP)**:子类型必须能够替换掉它们的父类型。
- **接口隔离原则 (Interface Segregation Principle, ISP)**:不应强迫客户依赖于它们不用的方法。
- **依赖倒置原则 (Dependency Inversion Principle, DIP)**:高层模块不应依赖于低层模块,两者都应依赖于抽象。
```java
// 依赖倒置原则的应用示例
public class ReportGenerationService {
private ReportFormatter formatter;
public ReportGenerationService(ReportFormatter formatter) {
this.formatter = formatter;
}
public void generateReport() {
formatter.format("Report content goes here.");
}
}
// 报告格式化的接口
interface ReportFormatter {
void format(String content);
}
// 具体实现的报告格式化类
class HtmlReportFormatter implements ReportFormatter {
@Override
public void format(String content) {
System.out.println("HTML formatted report: " + content);
}
}
class PdfReportFormatter implements ReportFormatter {
@Override
public void format(String content) {
System.out.println("PDF formatted report: " + content);
}
}
```
在这个例子中,`ReportGenerationService`依赖于`ReportFormatter`接口而不是具体的实现。这样,我们可以为不同的报告格式化需求提供不同的实现,而不需要修改`ReportGenerationService`类。
### 2.3.2 面向对象设计的实际案例
设计模式是面向对象设计中常用解决方案的模板。它们可以帮助我们解决软件设计中重复出现的问题,并提供了经过验证的最佳实践。
例如,工厂方法模式是一种创建型设计模式,它定义了一个创建对象的接口,但让子类决定实例化哪一个类。工厂方法让类的实例化推迟到子类中进行。
```java
// 工厂方法模式的应用示例
interface Product {
void use();
}
class ConcreteProductA implements Product {
@Override
public void use() {
System.out.println("Using ConcreteProductA.");
}
}
class ConcreteProductB implements Product {
@Override
public void use() {
System.out.println("Using ConcreteProductB.");
}
}
abstract class Creator {
public abstract Product factoryMethod();
}
class ConcreteCreatorA extends Creator {
@Override
public Product factoryMethod() {
return new ConcreteProductA();
}
}
class ConcreteCreatorB extends Creator {
@Override
public Product factoryMethod() {
return new ConcreteProductB();
}
}
// 客户端代码
public class Client {
public static void main(String[] args) {
Creator creatorA = new ConcreteCreatorA();
Product productA = creatorA.factoryMethod();
productA.use();
Creator creatorB = new ConcreteCreatorB();
Product productB = creatorB.factoryMethod();
productB.use();
}
}
```
在这个例子中,`Creator`类定义了一个`factoryMethod`方法,`ConcreteCreatorA`和`ConcreteCreatorB`类分别实现了该方法以创建特定的`Product`实例。客户端代码使用这些工厂类来获取产品对象,而不需要知道具体的产品类。这样,如果将来需要增加新的产品类型,只需要添加新的具体工厂类和产品类即可,无需修改现有的代码。
# 3. Java异常处理与集合框架
## 3.1 异常处理机制的细节
### 3.1.1 异常类的层次结构
在Java中,异常处理是通过异常类的层次结构来实现的,它提供了一种机制来处理运行时发生的错误。在Java的类层次结构中,所有的异常类都派生自`Throwable`类,它是所有异常和错误的超类。`Throwable`有两个直接子类:`Error`和`Exception`。
`Error`表示严重的错误,是程序无法处理的,例如`OutOfMemoryError`或`VirtualMachineError`,它们通常与JVM内部错误或资源耗尽有关。
而`Exception`类是程序能够处理的异常情况,它又分为两种类型:检查型异常(checked exceptions)和非检查型异常(unchecked exceptions)。检查型异常必须被捕获或抛出,而非检查型异常包括`RuntimeException`及其子类,这类异常通常是因为编程错误引起的,比如`NullPointerException`或`IndexOutOfBoundsException`。
### 3.1.2 try-catch-finally的使用和最佳实践
在Java中,`try-catch-finally`语句用于捕获和处理异常。`try`块包含了可能出现异常的代码,而`catch`块用于捕获并处理特定类型的异常。如果`try`块中的代码抛出了异常,它就会被相应的`catch`块捕获。
`finally`块是可选的,无论是否捕获到异常都会执行,通常用于执行清理资源的工作,如关闭文件或网络连接。
最佳实践:
- 只捕获你能够处理的异常。
- 不要捕获`Throwable`类,因为`Error`类型错误是不应该被捕获的。
- 尽量避免空的`catch`块,至少要打印出异常信息或者记录日志。
- 如果使用`finally`来释放资源,考虑使用Java 7引入的try-with-resources语句,它能自动关闭实现了AutoCloseable接口的资源。
## 3.2 集合框架的架构与实现
### 3.2.1 集合类的层次结构和特性
Java集合框架为程序员提供了用于存储和操作对象集合的工具。框架主要分为两大类:Collection和Map。
- Collection类包括List、Set和Queue接口,它们的共同点是存储一组元素。
- List接口提供了一个有序集合,允许重复元素,主要实现类有`ArrayList`和`LinkedList`。
- Set接口不允许多个相同的元素,主要实现类有`HashSet`和`LinkedHashSet`。
- Queue接口是操作一组元素的集合,并提供了先进先出(FIFO)的处理方式,实现类如`PriorityQueue`。
- Map接口存储键值对映射,允许使用一个键来查找一个值,主要实现类有`HashMap`、`LinkedHashMap`和`TreeMap`。
集合类的层次结构使程序员能够根据不同的需求选择合适的实现。例如,如果需要快速随机访问元素,可以使用`ArrayList`;如果需要保持插入顺序,则可以使用`LinkedHashMap`。
### 3.2.2 迭代器和比较器的使用
迭代器是Java集合框架的核心组件之一,它提供了一种遍历集合的方法。`Iterator`接口包含三个主要方法:`hasNext()`、`next()`和`remove()`。
使用示例:
```java
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()) {
String element = iterator.next();
// 处理元素...
}
```
比较器(`Comparator`)是一个接口,它允许在集合的元素上定义排序规则。例如,`TreeSet`和`TreeMap`就是使用`Comparator`来维持有序状态的集合实现。
```java
Comparator<String> comparator = new Comparator<String>() {
@Override
public int compare(String s1, String s2) {
***pareToIgnoreCase(s2);
}
};
TreeSet<String> set = new TreeSet<>(comparator);
```
### 3.2.3 高级集合应用:Map与Set的深入分析
`HashMap`和`HashSet`是Java集合框架中最常用的集合类型,它们基于哈希表的实现。`HashMap`通过键值对来存储数据,而`HashSet`则存储无序的唯一对象。
`HashMap`的性能高度依赖于哈希函数的质量,它通过键的`hashCode()`方法得到一个哈希值,并基于该值来快速定位元素。在Java 8中,当哈希冲突发生时,`HashMap`会使用平衡树(红黑树)来提高性能,减少冲突导致的链表长度。
```java
Map<String, Integer> map = new HashMap<>();
map.put("Java", 1995);
map.put("Python", 1991);
```
在使用`HashSet`时,需要确保对象的`hashCode()`和`equals()`方法被正确重写,这样才能保证对象的唯一性。
```java
Set<CustomObject> set = new HashSet<>();
set.add(new CustomObject("value1"));
set.add(new CustomObject("value2"));
```
## 3.3 泛型编程的应用与限制
### 3.3.1 泛型的原理和定义方法
泛型是Java集合框架不可或缺的一部分,它允许在不指定具体类型的情况下定义集合,提供了编译时的类型安全检查,并允许集合存储任何类型的对象。泛型在集合框架中的应用,使得集合操作更加灵活和通用。
定义泛型的语法是在类名或方法名后面加上尖括号`<>`,并在其中指定类型参数,例如`List<T>`。
```java
List<String> stringList = new ArrayList<>();
stringList.add("Hello");
stringList.add("World");
```
### 3.3.2 泛型在集合框架中的应用
泛型广泛应用于集合框架中的各个类。例如,`ArrayList`、`HashMap`、`HashSet`等集合类都提供了泛型版本,使得它们可以存储特定类型的对象。
使用泛型集合的好处是可以在编译时捕获类型错误,并通过编译器的自动类型转换减少类型转换异常。泛型还可以增强代码的可读性和可维护性。
### 3.3.3 泛型的类型擦除和限制
尽管泛型提供了许多优点,但它也有一个重要的限制,那就是类型擦除。在运行时,泛型类型信息将被擦除,因此不能在运行时创建泛型数组,也不能进行泛型类型的实例化。
```java
List<Integer> list = new ArrayList<>();
list.getClass(); // 返回ArrayList.class,泛型信息已擦除
```
泛型的类型擦除导致了类型安全的限制,因为所有泛型类型在运行时都会被处理成原始类型。此外,泛型类不能直接继承自`Throwable`类,因为`Throwable`需要能够被序列化,而类型擦除会引起序列化问题。
# 4. Java并发编程的原理与实践
在当今的软件开发领域,多线程和并发编程已经成为Java应用程序设计的重要组成部分。并发不仅能够提升程序的执行效率,还能让系统更好地利用多核处理器的计算能力。然而,随着并发水平的提升,开发者也面临着诸多挑战,比如线程安全、死锁、性能瓶颈等问题。本章节将深入探讨Java并发编程的原理,并分享实用的实践技巧。
## 4.1 多线程基础知识
多线程是并发编程的基础。在Java中,线程的生命周期和状态管理是构建并发应用程序的关键。
### 4.1.1 线程的生命周期和状态
Java线程的生命周期有以下几种状态:NEW(新建)、RUNNABLE(可运行)、BLOCKED(阻塞)、WAITING(等待)、TIMED_WAITING(计时等待)和TERMINATED(终止)。线程状态的转换主要通过调用线程对象的start()、run()、sleep()、wait()、notify()、notifyAll()和join()等方法实现。
**代码示例:**
```java
Thread thread = new Thread(() -> {
System.out.println("New thread running");
});
thread.start(); // 将线程状态置为RUNNABLE
thread.join(); // 等待线程终止
```
**逻辑分析:**
当调用start()方法时,线程进入了RUNNABLE状态,并且由JVM调度器来决定何时运行线程。使用join()方法会阻塞当前线程,直到指定的线程终止。
### 4.1.2 线程同步与协作的机制
为了确保共享资源的安全访问,Java提供了一系列同步机制,如synchronized关键字、volatile关键字、显示锁(Lock)、条件变量(Condition)等。
**代码示例:**
```java
class Counter {
private int count = 0;
// 同步方法
public synchronized void increment() {
count++;
}
}
```
**逻辑分析:**
synchronized关键字确保了方法在同一时刻只能被一个线程执行,从而保证了线程安全。通过这种方式可以避免多个线程同时修改count变量时发生的冲突。
## 4.2 并发工具类的应用
Java并发包(java.util.concurrent)提供了大量的并发工具类,这些类极大地方便了并发编程。
### 4.2.1 线程池的配置与管理
线程池是一种基于池化思想管理线程的工具,它可以有效避免频繁创建和销毁线程带来的性能开销。
**代码示例:**
```java
ExecutorService executorService = Executors.newFixedThreadPool(4);
executorService.execute(() -> {
// 任务逻辑
});
executorService.shutdown(); // 关闭线程池
```
**逻辑分析:**
通过Executors工厂类可以快速配置不同类型的线程池。使用线程池可以有效控制并发数,避免创建过多线程导致系统资源耗尽。shutdown()方法用于关闭线程池,但不会立即停止正在运行的任务。
### 4.2.2 同步辅助类的使用
同步辅助类提供了实现线程之间协作的便利方法。CountDownLatch和CyclicBarrier是两种常用的同步辅助类。
**代码示例:**
```java
CountDownLatch latch = new CountDownLatch(3);
for (int i = 0; i < 3; i++) {
new Thread(() -> {
// 模拟耗时操作
latch.countDown();
}).start();
}
latch.await(); // 等待所有线程完成操作
```
**逻辑分析:**
CountDownLatch可以用于使一个或多个线程等待直到在其他线程中执行的一组操作完成。在此示例中,latch.await()方法使得主线程在所有子线程完成操作前处于等待状态。
## 4.3 并发编程的高级主题
对于更复杂的并发场景,Java提供了更高级的并发工具和机制。
### 4.3.1 锁的深入理解
Java的并发包中包含高级的锁实现,如ReentrantLock,它提供了比synchronized更灵活的锁定机制。
**代码示例:**
```java
ReentrantLock lock = new ReentrantLock();
lock.lock(); // 获取锁
try {
// 临界区代码
} finally {
lock.unlock(); // 确保锁被释放
}
```
**逻辑分析:**
ReentrantLock提供了可中断的锁获取方式,以及尝试获取锁但不会永远等待的特性。try/finally结构保证了即使在临界区发生异常锁也能被释放。
### 4.3.2 并发集合和原子变量
Java并发包中的并发集合(如ConcurrentHashMap)和原子变量(如AtomicInteger)提供了线程安全的集合操作和原子操作。
**代码示例:**
```java
ConcurrentHashMap<String, AtomicInteger> map = new ConcurrentHashMap<>();
map.put("counter", new AtomicInteger(0));
map.get("counter").incrementAndGet(); // 原子增加操作
```
**逻辑分析:**
ConcurrentHashMap通过分段锁技术提供了高效的线程安全访问。AtomicInteger保证了递增操作的原子性,适用于高并发场景下的计数器实现。
### 4.3.3 高级并发控制策略
Java 7引入了Fork/Join框架,用于解决并行处理任务的需求。它基于"分而治之"的思想,将大任务分解成小任务,并并行执行。
**代码示例:**
```java
ForkJoinPool pool = new ForkJoinPool();
ForkJoinTask<String> task = new RecursiveTask<String>() {
@Override
protected String compute() {
// 递归分解任务逻辑
return "Result";
}
};
String result = pool.invoke(task);
```
**逻辑分析:**
Fork/Join框架特别适合处理可以递归分割的大量任务。它通过工作窃取算法,使得线程池中的空闲线程能够帮助其他线程执行任务,从而提高CPU的利用率。
通过上述介绍,我们可以看出Java并发编程涉及了多个层面的深入知识和实践技巧。理解线程的生命周期、掌握线程同步与协作机制、熟悉并发工具类的使用,以及了解高级并发控制策略,对于构建高效、可靠的Java并发应用程序至关重要。
本章节深入探讨了Java并发编程的核心概念和实用技术。接下来的章节将剖析Java内存管理与性能优化的技巧,为读者提供系统性能调优的实战经验。
# 5. Java内存管理与性能优化
## 5.1 垃圾回收机制的原理与算法
垃圾回收是Java内存管理的一个重要部分,它负责回收不再被使用的对象占用的内存空间。理解垃圾回收的原理和算法是优化Java应用性能的关键。
### 5.1.1 垃圾回收的种类和时机
Java的垃圾回收机制主要分为以下几种:
- **Minor GC(年轻代回收)**:针对年轻代进行的垃圾回收,对象首先在Eden区创建,当Eden区满后,会触发一次Minor GC,存活的对象会被拷贝到Survivor区。
- **Major GC(老年代回收)**:针对老年代进行的垃圾回收。当老年代空间不足时,会触发Major GC,它通常伴随着一次Minor GC。
- **Full GC(全局垃圾回收)**:对整个堆内存进行清理,包括年轻代和老年代。Full GC会比Minor GC和Major GC消耗更多资源。
垃圾回收的时机通常由JVM根据内存使用情况自动触发,但也可以通过调用System.gc()方法建议JVM进行垃圾回收。
### 5.1.2 常见垃圾回收算法的比较和选择
不同的垃圾回收算法适用于不同的场景:
- **标记-清除算法(Mark-Sweep)**:分为标记和清除两个阶段。首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象。这种方式简单,但会造成大量内存碎片。
- **复制算法(Copying)**:将内存分为两个相等大小的区域,每次只使用其中的一个。当一个区域满了,就将存活的对象复制到另一个区域,并清除原来的区域。复制算法适合年轻代,因为它存活的对象通常较少。
- **标记-整理算法(Mark-Compact)**:是标记-清除算法的改进版本,它在标记完成后将存活对象向一端移动,然后直接清理掉端边界以外的内存。这种算法可以减少内存碎片,适用于老年代。
- **分代收集算法(Generational Collection)**:结合了以上几种算法,将堆内存划分为不同的代(如年轻代和老年代),不同代采用不同的垃圾回收算法。
开发者应根据应用的特点和需求选择合适的垃圾回收算法,以达到最优的性能表现。
## 5.2 性能调优的基本策略
性能调优是持续的过程,需要不断监测、分析、调整和验证。
### 5.2.1 JVM参数调整和性能监控
JVM参数的调整对于性能优化至关重要。一些关键参数包括堆内存大小、垃圾回收器选择、线程栈大小等。例如,设置-Xms和-Xmx来定义堆内存的最小和最大大小。
监控工具如jstat可以用来监控JVM的性能指标,如垃圾回收次数和时间,帮助开发者了解应用的运行情况。
### 5.2.2 线上问题的诊断和解决方法
线上问题诊断通常涉及到多个层面,包括但不限于:
- CPU使用率过高:使用top和htop命令查看CPU占用情况,使用jstack分析线程堆栈信息。
- 内存泄漏:利用MAT(Memory Analyzer Tool)等内存分析工具进行内存泄漏检测。
- 响应缓慢:通过分析GC日志,使用GC日志分析工具如GCViewer来诊断性能问题。
- 应用崩溃:通过分析堆转储文件(heap dump),使用jmap和jhat等工具进行分析。
找到问题后,需要根据具体的分析结果采取相应的解决方法,比如优化代码、调整JVM参数、更新依赖库或升级硬件等。
## 5.3 Java代码优化实践
性能优化不仅仅局限于JVM层面,代码层面的优化同样重要。
### 5.3.1 代码层面的性能优化技巧
代码优化技巧包括但不限于:
- **循环优化**:减少循环内部的计算,移除循环中不变的计算。
- **减少对象创建**:避免频繁地创建对象,尤其是在循环和热点代码路径中。
- **利用缓存**:合理使用缓存来存储重复计算或频繁访问的数据。
- **使用高效的数据结构**:根据需要选择合适的数据结构可以大幅提高性能。
### 5.3.2 利用Java性能分析工具进行优化
性能分析工具是性能优化的利器,可以帮助开发者精确地找出性能瓶颈所在。
- **JProfiler**:提供CPU和内存的实时监控,支持多线程分析,易于查找瓶颈。
- **YourKit**:同样提供强大的性能分析功能,包括热点分析、内存泄漏检测等。
- **VisualVM**:一个免费工具,可以监控本地和远程应用的运行情况。
这些工具不仅可以帮助开发者找出代码中的热点,还可以分析内存泄漏和线程竞争等问题,是性能优化不可或缺的辅助工具。
性能优化是一个复杂的过程,需要结合应用程序的特定场景,持续地分析和调整。开发者应不断积累经验,掌握相关工具的使用,从而在实际工作中有效地提升应用的性能表现。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Java 专栏,一个深入探索 Java 编程语言各个方面的知识库。本专栏涵盖了从核心概念到高级技术的广泛主题,旨在为 Java 开发人员提供全面的指南。
专栏内容包括:
* Java 基础知识的深入解读和实践技巧
* Java 虚拟机 (JVM) 的优化机制和工作原理
* Java 内存模型的管理和性能优化策略
* Java 并发编程的锁使用和性能提升技巧
* 面向对象设计原则在 Java 中的实际应用
* Java I/O 系统的流演进和 NIO 优化策略
* Java 集合框架的原理和性能优化法则
* Java 垃圾回收和内存管理的最佳实践和调优方法
* Java 泛型的深入解析和安全、可复用代码的秘诀
* Spring 框架的核心原理,包括 IoC 和 AOP
* MyBatis 框架的配置、优化和高级扩展策略
* Java 网络编程从 Socket 到 Netty 的进阶指南
* Java 多线程编程的高级技巧和案例分析
* Java 性能调优的代码层面优化策略
* Java 8 新特性的详解,包括 Lambda 和 Stream API 的应用技巧
* Java 中的设计模式,包括实现和应用案例的权威解析
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
供应链革新:EPC C1G2协议在管理中的实际应用案例
# 摘要
EPC C1G2协议作为一项在射频识别技术中广泛采用的标准,在供应链管理和物联网领域发挥着关键作用。本文首先介绍了EPC C1G2协议的基础知识,包括其结构、工作原理及关键技术。接着,通过分析制造业、物流和零售业中的应用案例,展示了该协议如何提升效率、优化操作和增强用户体验。文章还探讨了实施EPC C1G2协议时面临的技术挑战,并提出了一系列解决方案及优化策略。最后,本文提供了一份最佳实践指南,旨在指导读者顺利完成EPC C1G2协议的实施,并评估其效果。本文为EPC C1G2协议的深入理解和有效应用提供了全面的视角。
# 关键字
EPC C1G2协议;射频识别技术;物联网;供应链管
【数据结构与算法实战】

# 摘要
数据结构与算法是计算机科学的基础,对于软件开发和系统设计至关重要。本文详细探讨了数据结构与算法的核心概念,对常见数据结构如数组、链表、栈、队列和树等进行了深入分析,同
【Ansys参数设置实操教程】:7个案例带你精通模拟分析
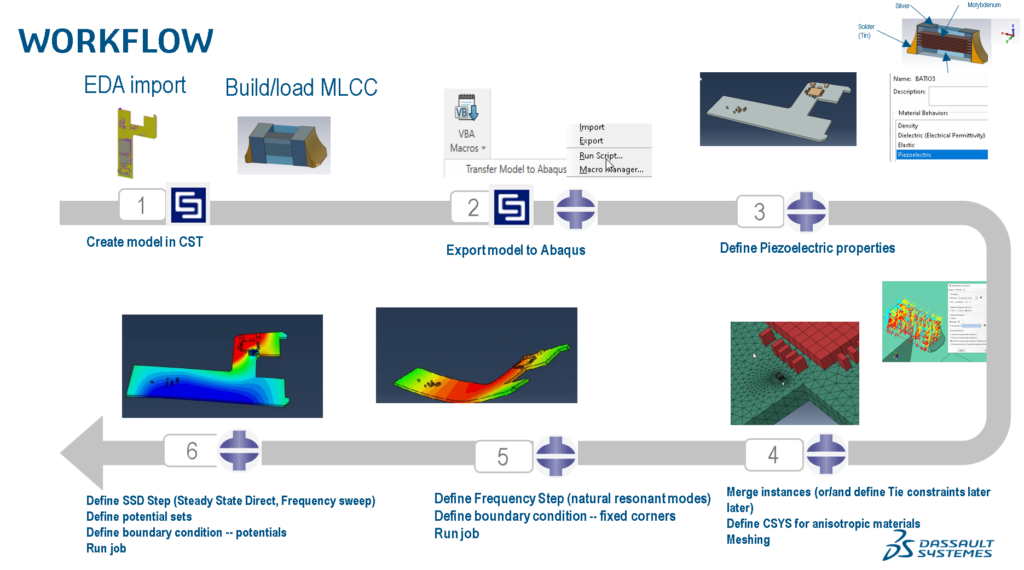
# 摘要
本文系统地介绍了Ansys软件中参数设置的基础知识与高级技巧,涵盖了结构分析、热分析和流体动力学等多方面应用。通过理论与实际案例的结合,文章首先强调了Ansys参数设置的重要性,并详细阐述了各种参数类型、数据结构和设置方法。进一步地,本文展示了如何在不同类型的工程分析中应用这些参数,并通过实例分析,提供了参数设置的实战经验,包括参数化建模、耦合分析以及参数优化等方面。最后,文章展望
【离散时间信号与系统】:第三版习题解密,实用技巧大公开

# 摘要
离散时间信号与系统的分析和处理是数字信号处理领域中的核心内容。本文全面系统地介绍了离散时间信号的基本概念、离散时间系统的分类及特性、Z变换的理论与实践应用、以及离散时间信号处理的高级主题。通过对Z变换定义、性质和在信号处理中的具体应用进行深入探讨,本文不仅涵盖了系统函数的Z域表示和稳定性分析,还包括了Z变换的计算方法,如部分分式展开法、留数法及逆Z变换的数值计算方法。同时,本文还对离散时间系
立体声分离度:测试重要性与提升收音机性能的技巧

# 摘要
立体声分离度是评估音质和声场表现的重要参数,它直接关联到用户的听觉体验和音频设备的性能。本文全面探讨了立体声分离度的基础概念、测试重要性、影响因素以及硬件和软件层面的提升措施。文章不仅分析了麦克风布局、信号处理技术、音频电路设计等硬件因素,还探讨了音频编辑软件、编码传输优化以及后期处理等软件策略对分离度的正面影响。通过实战应用案例分析,本文展示了在收音机和音频产品开
【热分析高级技巧】:活化能数据解读的专家指南
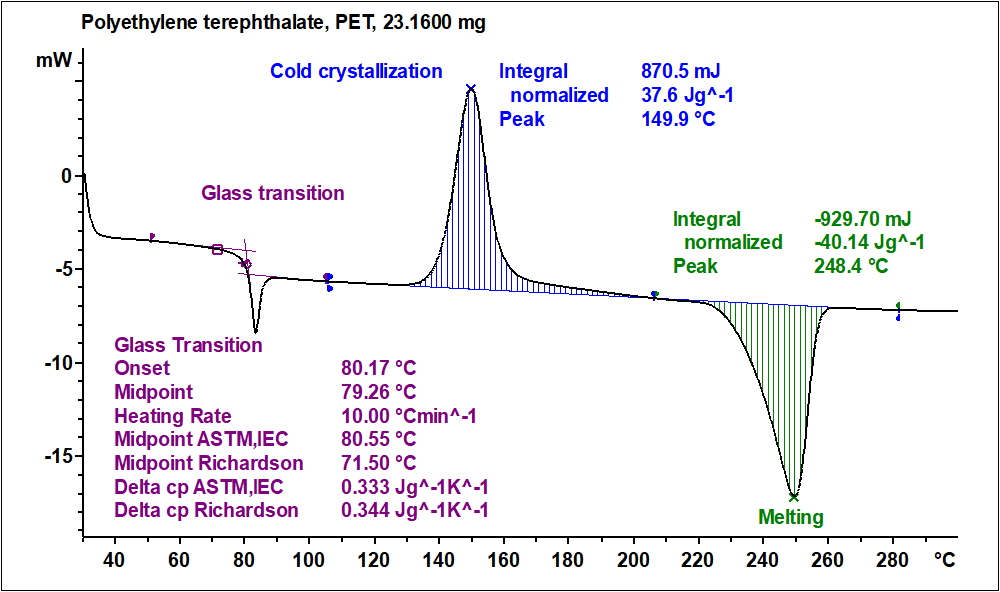
# 摘要
热分析技术作为物质特性研究的重要方法,涉及到对材料在温度变化下的物理和化学行为进行监测。本论文全面概述了热分析技术的基础知识,重点阐述了活化能理论,探讨了活化能的定义、重要性以及其与化学反应速率的关系。文章详细介绍了活化能的多种计算方法,包括阿伦尼乌斯方程及其他模型,并讨论了活化能数据分析技术,如热动力学分析法和微分扫描量热法(DSC)。同时,本文还提供了活化能实验操作技巧,包括实验设计、样品准备、仪器使用
ETA6884移动电源温度管理:如何实现最佳冷却效果

# 摘要
本论文旨在探讨ETA6884移动电源的温度管理问题。首先,文章概述了温度管理在移动电源中的重要性,并介绍了相关的热力学基础理论。接着,详细分析了移动电源内部温度分布特性及其对充放电过程的影响。第三章阐述了温度管理系统的设计原则和传感器技术,以及主动与被动冷却系统的具体实施。第四章通过实验设计和测试方法评估了冷却系统的性能,并提出了改进策略。最后,
【PCM测试高级解读】:精通参数调整与测试结果分析
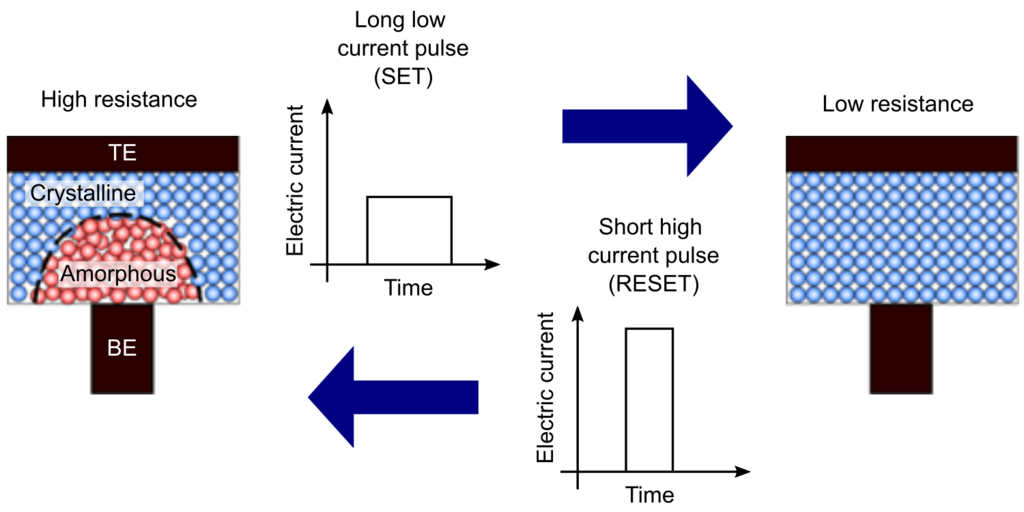
# 摘要
PCM测试作为衡量系统性能的重要手段,在硬件配置、软件环境搭建以及参数调整等多个方面起着关键作用。本文首先介绍PCM测试的基础概念和关键参数,包括它们的定义、作用及其相互影响。随后,文章深入分析了测试结果的数据分析、可视化处理和性能评估方法。在应用实践方面,本文探讨了PCM测试在系统优化、故障排除和性能监控中的实际应用案例。此外,文章还分享了PCM测试的高级技巧与最佳实践,并对测试技术未来
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )