SIMCA 14.1多维数据整合:跨学科分析的3D火山图利器
发布时间: 2024-12-15 10:32:58 阅读量: 2 订阅数: 4 

(10)SIMCA14.1操作教程--3D火山图.pdf

参考资源链接:[SIMCA 14.1教程:3D火山图制作与解析](https://wenku.csdn.net/doc/6401ad16cce7214c316ee3f4?spm=1055.2635.3001.10343)
# 1. SIMCA 14.1概览与多维数据整合简介
## 简介
SIMCA(Soft Independent Modeling of Class Analogy)是市场领先的多变量数据分析软件,它广泛应用于化学、制药、生物技术和过程工程等领域。SIMCA 14.1作为最新版本,提供了更为先进和直观的数据分析工具,特别是在处理和整合多维数据方面表现出色。
## 多维数据整合的重要性
多维数据整合指的是将来自不同来源和格式的数据,整合到一个统一的分析框架中。这项技术对于研究人员、工程师和数据分析师来说至关重要,因为它可以揭示数据之间的隐藏关系,为决策提供支持。SIMCA 14.1利用其强大的数据预处理和转换能力,为用户提供了从复杂数据集中提取有价值信息的能力。
## SIMCA 14.1的核心优势
- **直观的用户界面**:SIMCA 14.1的操作界面被设计得直观易用,即便是数据整合的新手也能快速上手。
- **多维数据处理**:集成了多种先进的算法用于数据降维、分类和回归分析。
- **跨学科应用**:适用于多领域的复杂数据集分析,如生物信息学、药物开发、化学工程等。
在接下来的章节中,我们将深入探讨SIMCA 14.1在多维数据分析方面的理论基础、操作方法和实际应用案例,帮助读者获得深入理解,并掌握其应用技巧。
# 2. 理论基础与多维数据分析方法
多维数据分析作为一门综合性强、应用广泛的学科,其背后深藏着丰富的理论基础和数据分析方法。它不仅为我们提供了一种分析和理解复杂数据集的新视角,而且还借助于强大的统计学和机器学习技术,实现了对数据内在结构的深入挖掘。在本章节中,我们将深入探讨多维数据的概念、特点以及在数据分析中的应用,同时也会对SIMCA软件在数据处理方面的技术进行详细介绍。
## 2.1 多维数据的概念和特点
### 2.1.1 多维数据的定义和应用场景
多维数据(Multidimensional data)指的是在多个维度或属性上具有特征的数据集。每个数据点包含多个度量值,这些度量值反映了不同维度上的信息。多维数据常见于各种科学研究、商业分析和工业监控等领域。
在实际应用中,多维数据可以用于表示如下的情况:
- 在经济学中,企业运营数据可能包括时间序列、产品种类、区域分布等多个维度。
- 在生物信息学中,基因表达数据集可能包括样本、基因以及表达水平等维度。
- 在零售分析中,销售数据可能涉及产品类别、时间、地理位置等多个维度。
多维数据处理的关键在于如何从高维空间中提取出有价值的信息,这通常是通过数据降维技术来实现的。降维可以简化数据结构,消除冗余信息,并且能够揭示数据中的潜在模式和关系。
### 2.1.2 多维数据的可视化原理
可视化是理解多维数据的关键手段,能够帮助分析师快速捕获数据的本质和趋势。多维数据的可视化原理基于人类对图形的感知能力,通过图像编码将高维数据映射到二维或三维空间上,以便直观展示。
常见的多维数据可视化方法有:
- 散点图矩阵(Scatter plot matrix)
- 平行坐标图(Parallel coordinates)
- 火山图(Volcano plot)
- 星形图(Star plot)
- 箱线图(Box plot)
通过这些方法,我们可以观察数据在不同维度上的分布、聚类特性、离群点等。例如,火山图能够有效地展示变量间的差异性,并通过图表中的特定点来表示差异显著的变量。
## 2.2 多维数据分析的数学理论
### 2.2.1 统计学在多维数据分析中的应用
统计学为多维数据分析提供了理论基础和计算方法。在多维数据中,单变量统计分析往往不能完全满足需求,因此需要扩展到多变量统计分析。多变量统计分析包括聚类分析、主成分分析(PCA)、因子分析等,这些方法可以探索数据的结构、模式和关系。
- **聚类分析**:将相似的观测值分组在一起。
- **主成分分析(PCA)**:将数据降维,提取主要信息,同时尽可能保留数据变异。
- **因子分析**:识别背后的隐含变量,减少观测变量的数量。
### 2.2.2 机器学习算法与多维数据挖掘
机器学习为多维数据挖掘提供了强大的工具,尤其是无监督学习算法,它们不需要事先指定标签,就能够从数据中发现有用的模式。常用的无监督学习算法包括K-means聚类、层次聚类、DBSCAN等。
- **K-means聚类**:通过迭代优化,将数据分为K个聚类,以最小化聚类内差异。
- **层次聚类**:通过构建层次的聚类树,逐步聚合或分裂数据点。
- **DBSCAN**:基于密度的空间聚类,能发现任意形状的聚类,并且能够识别噪声点。
这些算法帮助我们从大量的、看似杂乱无章的数据中提取出有价值的信息,并对数据进行分类和特征提取,为进一步的数据分析和决策提供支持。
## 2.3 SIMCA软件的数据处理技术
### 2.3.1 SIMCA的数据预处理工具
数据预处理是数据分析前的关键步骤,目的在于提高数据质量,为后续分析打下坚实的基础。SIMCA提供了多种数据预处理工具,包括数据标准化、中心化、去趋势、缺失值处理等。
数据标准化通常用于处理不同测量尺度的数据,而中心化则可以帮助消除数据的平均水平,使得数据分布围绕0变化,便于进行比较和后续分析。去趋势用于移除数据中的非相关性变化,以突出数据的内在变异,而缺失值处理则涉及如何对缺失数据进行合理估算。
### 2.3.2 SIMCA的数据转换与降维策略
为了更有效地分析多维数据,SIMCA采用了多种数据转换和降维方法,比如主成分分析(PCA)、偏最小二乘法(PLS)、正交偏最小二乘法(OPLS)等。
- **主成分分析(PCA)**:通过识别数据中的主要成分,将高维数据投影到新的空间中,降低数据维度,同时尽可能保留数据的信息。
- **偏最小二乘法(PLS)**:在预测模型中,PLS可以用于寻找X变量(解释变量)和Y变量(响应变量)之间的关系。
- **正交偏最小二乘法(OPLS)**:OPLS是PLS的一种改进形式,它将数据分解为与Y变量相关的部分和与Y变量无关但与X变量相关的部分,有助于提高模型的解释能力。
通过这些策略,SIMCA能够帮助用户有效地从复杂的多维数据中提取关键信息,实现数据的降维和可视化,进而进行更深入的数据分析和解释。
通过本章节的内容介绍,我们对多维数据的定义、特点、可视化原理有了基本的了解,同时也认识到了统计学和机器学习在多维数据分析中的重要性。SIMCA作为一个专业级的多维数据分析工具,它提供的数据预处理和降维策略为用户提供了强大的数据处理能力。在后续的章节中,我们将进一步探讨3D火山图的构建与应用,以

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【数据存储新篇章:凝思安全操作系统V6.0.80存储管理优化策略】
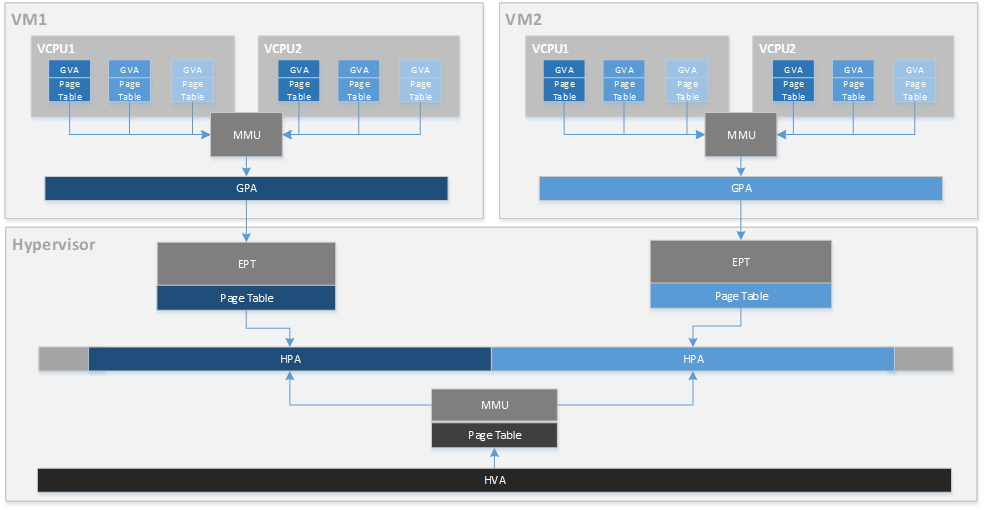
参考资源链接:[凝思安全操作系统V6.0.80安装教程与常见问题详解](https://wenku.csdn.net/doc/1wk3bc6maw?spm=1055.2635.3001.10343)
# 1. 安全操作系统存储管理概述
## 1.1 存储管理的重要性
在信息安全越来越受到重视的今天,安全操作系统的存储管理不仅关系到数据的完整性和安全性,更是整个系统性能和可靠性的重要保障。优秀的存
【Python模块导入机制深度解析】:掌握PYTHONPATH与模块搜索的秘诀
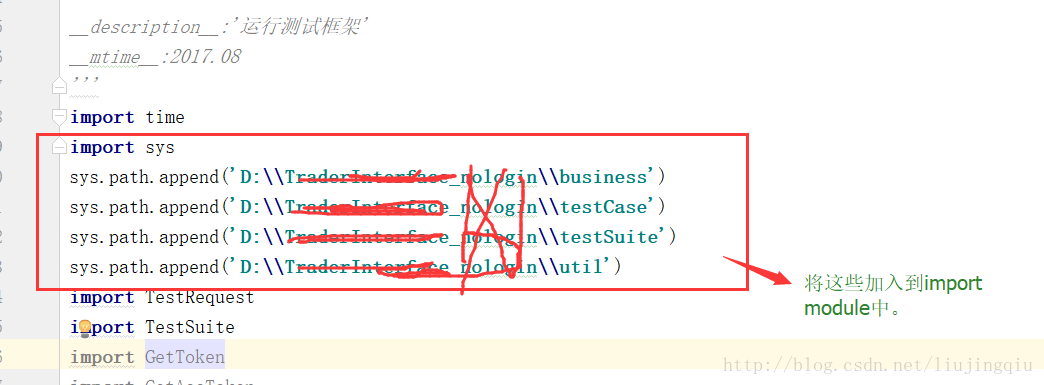
参考资源链接:[pycharm运行出现ImportError:No module named的解决方法](https://wenku.csdn.ne
MAB-MAAB-5.0中文版升级攻略:旧版本用户必看的升级指南
参考资源链接:[MAB规范5.0中文版:Simulink与Stateflow建模命名指南](https://wenku.csdn.net/doc/6401ad16cce7214c316ee3ec?spm=1055.2635.3001.10343)
# 1. MAB-MAAB-5.0新版本概览
## 1.1 新版本引入
随着技术的不断进步,MAB-MAAB-5.0作为一款前沿的软件应用,它的推出标志着产品进入了一个新
Verdi故障排查秘籍:问题诊断与解决的全面方法

参考资源链接:[Verdi教程](https://wenku.csdn.net/doc/3rbt4txqyt?spm=1055.2635.3001.10343)
# 1. Verdi故障排查基础
## 1.1 Verdi故障排查的重要性
在现代IT基础设施中,故障排查是确保系统稳定运行的关键环节。Verdi作为一种先进的故障排查工具,其应用在确保企业业务连续性和用户体验方面扮
【UDEC宏编程精进】:中文实例助你精通编程技巧

参考资源链接:[UDEC中文详解:初学者快速入门指南](https://wenku.csdn.net/doc/5fdi050ses?spm=1055.2635.3001.10343)
# 1. UDEC宏编程概述
## 1.1 UDEC宏编程简介
UDEC(Universal Distinct Element Code)是一个用于模拟岩石及其他离散材料的二维离散元
Python中的OOP深度解析:掌握面向对象编程的艺术

参考资源链接:[头歌Python实践:顺序结构与复数运算解析](https://wenku.csdn.net/doc/ov1zuj84kh?spm=1055.2635.3001.10343)
# 1. 面向对象编程(OOP)基础
面向对象编程(OOP)是一种计算机编程架构,它使用对象来模拟现实世界中的实体和它们之间的交互。在OOP中,每个对象都是某个特定类的实例,并拥有自己的属性和方法
DEFORM-3D_v6.1问题速查手册:毛坯与模具接触关系的解决方案
参考资源链接:[DEFORM-3D v6.1:交互对象操作详解——模具与毛坯接触关系设置](https://wenku.csdn.net/doc/5d6awvqjfp?spm=1055.2635.3001.10343)
# 1. DEFORM-3D_v6.1概述与基础设置
## 1.1 DEFORM-3D_v6.1简介
DEFORM-3D_v6.1是一款先进的有限元分析
【JSON书源故障速解】:专家团队提供加载与兼容性问题的终极解决方案
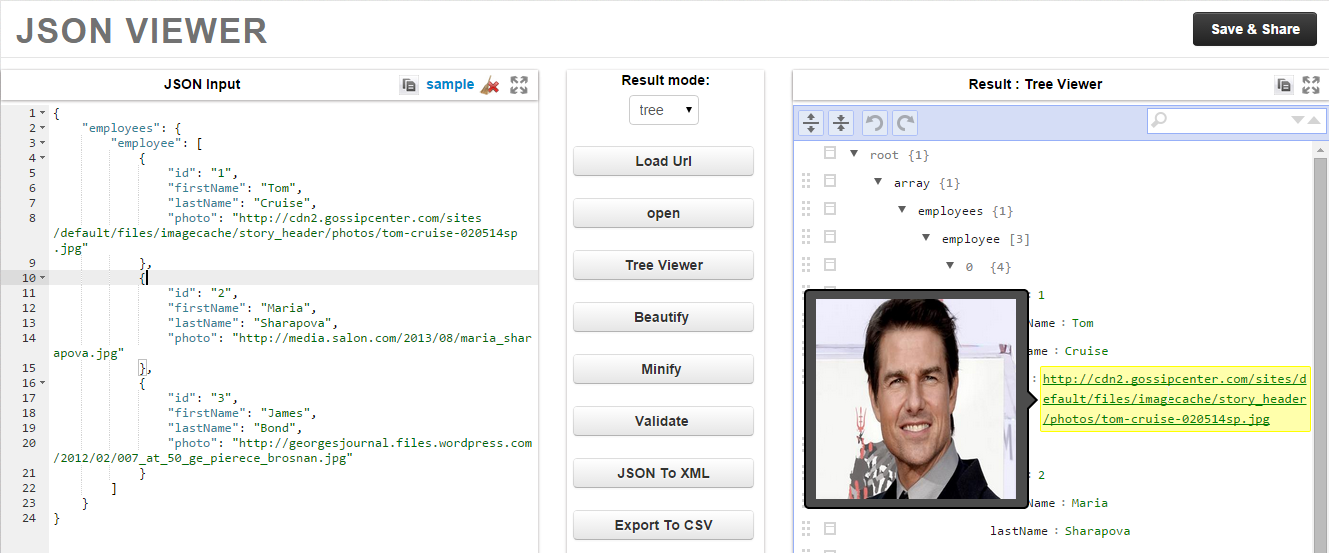
参考资源链接:[1629个精品阅读书源,提升你的阅读体验](https://wenku.csdn.net/doc/6z9pjm3s9m?spm=1055.2635.3001.10343)
# 1. JSON书源故障速解概述
在数字化时代,数据的交换和处理变得至关重要,JSON(JavaScript Object Notation)作为轻量级的数据交换格式,因其简单性、易读性和易生成性,在网络数据交互中占据着举足轻重的地位
印刷术语全解析:中英文对照与应用场景(速成印刷专家)

参考资源链接:[印刷术语大全:中英文对照与专业解析](https://wenku.csdn.net/doc/1y36sp606t?spm=1055.2635.3001.10343)
# 1. 印刷术语概览与分类
## 1.1 印刷术语的定义与重要性
印刷术语是指在印刷行业中专门用于描述印刷过程、技术和材料的特定
硬件设计新手必读
参考资源链接:[PR2000K_AHD转MIPI调试原理图.pdf](https://wenku.csdn.net/doc/645d9a0995996c03ac437fcb?spm=1055.2635.3001.10343)
# 1. 硬件设计的入门知识
## 1.1 硬件设计的定义
硬件设计是电子工程的一个重要分支,涉及电子系统或产品中物理组件的选择、布局和互连。它要求设计者具有扎实的电子电路、计算机架构
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )