Python类与函数深度剖析:提升代码复用与模块化的艺术
发布时间: 2024-09-20 19:47:49 阅读量: 177 订阅数: 35 
# 1. Python类与函数的基础概念
## 1.1 Python类的基本概念
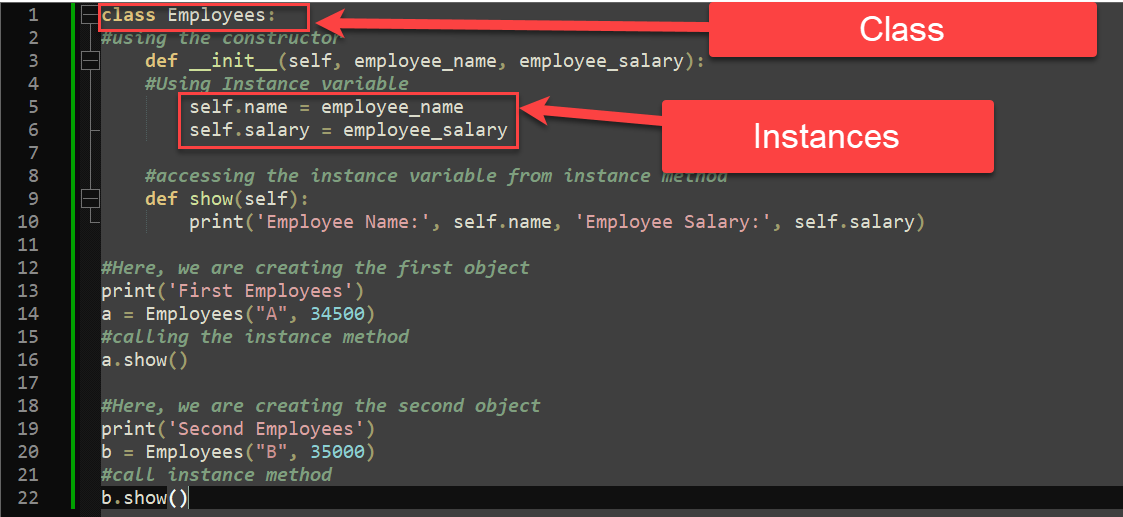
Python类是一种结构化编程的强大工具,它允许程序员创建自己的数据类型。类可以包含属性(数据)和方法(函数)。类的定义使用关键字`class`,后面跟类名和冒号。例如:
```python
class Dog:
kind = 'canine' # 类变量
def __init__(self, name):
self.name = name # 实例变量
```
在这个例子中,`Dog`是一个类,拥有一个类变量`kind`和一个实例变量`name`,这个变量是每个实例都有的。
## 1.2 Python函数的基本概念
函数是一段执行特定任务的代码块,可以带参数,也可以返回值。Python中的函数使用`def`关键字来定义:
```python
def say_hello(name):
return "Hello, " + name + "!"
```
这里的`say_hello`是一个函数,它接受一个参数`name`,并返回一个字符串。
## 1.3 类与函数的比较
类和函数是面向对象编程中两个不同的概念。类是一种模板,用于创建对象;而函数是一种独立的代码块,它可以与类协作,也可以单独存在。在Python中,函数可以定义在类中,这时它们被称为方法。方法可以访问类的属性和其他方法。与函数相比,类提供了一种更系统的方式来组织和封装代码。
理解类与函数的基础概念是学习Python面向对象编程的关键起点。在后续章节中,我们将深入探讨如何使用类和函数来构建复杂的应用程序,以及如何通过继承、多态等面向对象的原则来优化和重构代码。
# 2. 深入理解Python类的设计
### 2.1 类的定义与实例化
#### 2.1.1 类的声明与初始化
在Python中,类是通过关键字`class`来定义的。一个基本的类定义包括一个包含属性和方法的类名和一个初始化方法`__init__`,该方法会在创建类的新实例时自动调用。初始化方法通常用来初始化实例的状态。
```python
class Dog:
def __init__(self, name, age):
self.name = name # 实例属性
self.age = age # 实例属性
# 创建一个Dog类的实例
my_dog = Dog('Buddy', 5)
```
在上述代码中,`Dog`类有两个实例属性:`name`和`age`。`__init__`方法接受`self`参数,它指向实例本身,此外还有`name`和`age`参数。创建`Dog`类的实例时,需要提供这两个参数。类实例化之后,可以在外部通过实例名访问属性,如`my_dog.name`和`my_dog.age`。
#### 2.1.2 实例属性与方法
实例属性是在实例中定义的变量,它们是对象状态的一部分。实例方法是一种特殊的方法,第一个参数总是`self`,表示调用该方法的对象。
```python
class Circle:
def __init__(self, radius):
self.radius = radius # 实例属性
def area(self):
return 3.14 * self.radius ** 2 # 实例方法
# 创建一个Circle类的实例
circle = Circle(5)
# 调用实例方法来计算面积
print(circle.area())
```
`Circle`类有一个实例属性`radius`和一个实例方法`area`。`area`方法被用来计算并返回圆的面积。通过实例`circle`调用`area`方法计算半径为5的圆面积。
### 2.2 面向对象的继承机制
#### 2.2.1 基类与派生类的创建
继承是面向对象编程的重要特性之一。通过继承,我们可以创建一个新类(派生类)来继承一个已存在的类(基类)的属性和方法。
```python
class Animal:
def __init__(self, name):
self.name = name # 基类属性
def speak(self):
pass # 基类方法,空实现
class Dog(Animal): # Dog派生自Animal
def speak(self):
return f"{self.name} says woof!" # 重写speak方法
# 创建Dog类的实例
my_dog = Dog("Buddy")
print(my_dog.speak())
```
在上述代码中,`Animal`类是基类,定义了一个属性`name`和一个方法`speak`。`Dog`类继承自`Animal`类,并重写了`speak`方法。创建`Dog`类实例`my_dog`后,调用`speak`方法会返回派生类中定义的结果。
#### 2.2.2 方法解析顺序(MRO)
在继承体系中,方法解析顺序(Method Resolution Order, MRO)决定了方法调用的顺序。Python通过C3线性化算法来确定MRO。
```python
class A:
pass
class B(A):
pass
class C(A):
pass
class D(B, C):
pass
print(D.mro()) # 打印D类的MRO
```
输出的MRO显示了从当前类到基类的继承顺序。`D.mro()`会返回一个列表,包含`D`, `B`, `C`, `A`, `object`。这表示Python解释器首先会在`D`类中查找方法,如果找不到,则会在`B`中查找,以此类推,直到找到该方法或到达继承树的顶端`object`。
#### 2.2.3 super()函数的使用
`super()`函数可以帮助我们在子类中调用父类的方法。它通常用于在派生类中扩展或修改基类的行为。
```python
class Vehicle:
def __init__(self, color):
self.color = color
class Car(Vehicle):
def __init__(self, color, wheels):
super().__init__(color) # 调用父类的初始化方法
self.wheels = wheels
car = Car('red', 4)
print(car.color, car.wheels)
```
在这个例子中,`Car`类继承自`Vehicle`类。使用`super().__init__(color)`调用基类的初始化方法,确保在派生类中基类也被正确初始化。创建`Car`类的实例后,我们可以看到它既拥有来自`Vehicle`类的颜色属性,也拥有自己的轮子属性。
### 2.3 封装、多态与类的高级特性
#### 2.3.1 私有成员与公共成员
在Python中,私有成员通常通过在成员名前加双下划线`__`来定义,而公共成员则是直接使用标识符。然而,Python中的所谓私有成员仍然可以通过特定的语法访问。
```python
class Secretive:
def __init__(self):
self.__hidden = "I'm a secret"
def get_hidden(self):
return self.__hidden
instance = Secretive()
print(instance.get_hidden()) # 正常访问
# print(instance.__hidden) # 将引发错误,尝试直接访问私有成员
```
`Secretive`类有一个私有属性`__hidden`。虽然我们不能直接访问它(尝试直接访问会引发属性错误),但是可以通过公有的方法`get_hidden`来间接访问。这种机制提供了一定程度的封装性,但不是完全的私有化。
#### 2.3.2 运算符重载与多态性
Python支持运算符重载,允许开发者对类实例定义或修改运算符的行为。多态性指的是同一操作作用于不同的对象,可以有不同的解释和不同的执行结果。
```python
class Vector2D:
def __init__(self, x, y):
self.x = x
self.y = y
def __add__(self, other):
return Vector2D(self.x + other.x, self.y + other.y)
v1 = Vector2D(5, 5)
v2 = Vector2D(3, 4)
v3 = v1 + v2
print(v3.x, v3.y) # 输出结果是两个向量相加后的坐标 (8, 9)
```
`Vector2D`类重载了加法运算符,定义了两个向量相加的行为。创建`Vector2D`的实例后,我们可以通过`+`运算符对两个`Vector2D`实例进行相加操作,并得到它们的和。
#### 2.3.3 类装饰器与元类编程
类装饰器是修改或增强类行为的一种方式,而元类是创建类的“类”。通过元类编程,我们可以控制类的创建过程。
```python
# 定义一个类装饰器
def trace(cls):
orig_init = cls.__init__
def new_init(self, *args, **kwargs):
print(f"Trace: calling {cls.__name
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 中类和函数的方方面面,旨在帮助开发者充分掌握这些基本概念。从面向对象编程的原则到函数式编程的技巧,再到类和函数的深入剖析,专栏涵盖了广泛的主题。此外,还介绍了类的继承、多态和装饰器等高级技术,以及性能优化、参数处理、单元测试和并发编程等实用技巧。通过深入理解 Python 中的类和函数,开发者可以编写出更强大、更灵活、更可维护的代码。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
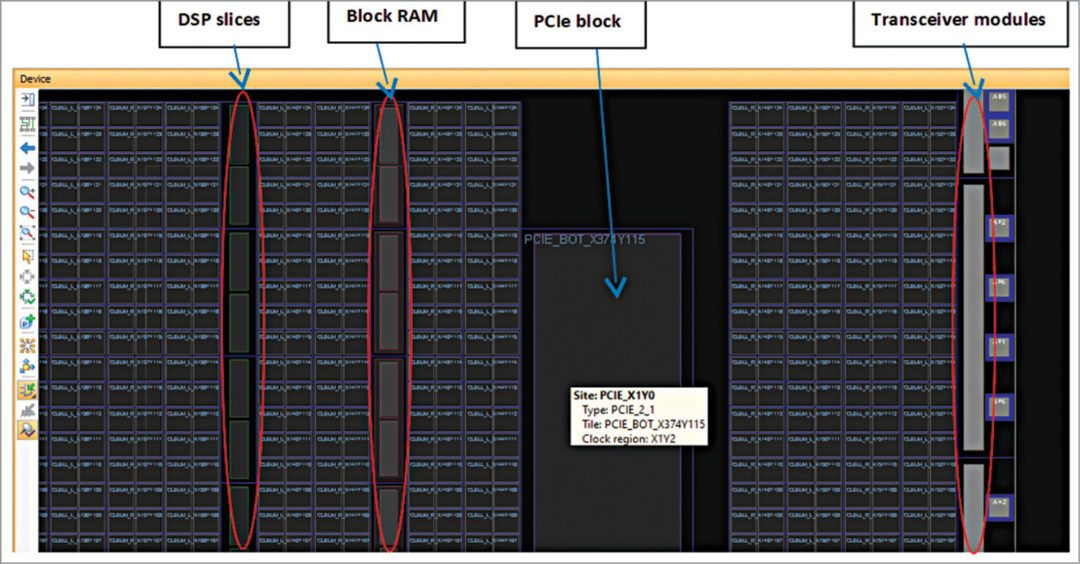
【性能优化】:提升Virtex-5 FPGA RocketIO GTP Transceiver效率的实用指南
# 摘要
本文针对Virtex-5 FPGA RocketIO GTP Transceiver的性能优化进行了全面的探讨。首先介绍了GTP Transceiver的基本概念和性能优化的基础理论,包括信号完整性、时序约束分析以及功耗与热管理。然后,重点分析了硬件设计优化实践,涵盖了原理图设计、PCB布局布线策略以及预加重与接收端均衡的调整。在固件开发方面,文章讨论了GTP初始化与配置优化、串行协议栈性能调优及专用IP核的
【LBM方柱绕流模拟中的热流问题】:理论研究与实践应用全解析

# 摘要
本文全面探讨了Lattice Boltzmann Method(LBM)在模拟方柱绕流问题中的应用,特别是在热流耦合现象的分析和处理。从理论基础和数值方法的介绍开始,深入到流场与温度场相互作用的分析,以及热边界层形成与发展的研究。通过实践应用章节,本文展示了如何选择和配置模拟软
MBIM协议版本更新追踪:最新发展动态与实施策略解析

# 摘要
随着移动通信技术的迅速发展,MBIM(Mobile Broadband Interface Model)协议在无线通信领域扮演着越来越重要的角色。本文首先概述了MBIM协议的基本概念和历史背景,随后深入解析了不同版本的更新内容,包括新增功能介绍、核心技术的演进以及技术创新点。通过案例研究,本文探讨了MB
海泰克系统故障处理快速指南:3步恢复业务连续性
# 摘要
本文详细介绍了海泰克系统的基本概念、故障影响,以及故障诊断、分析和恢复策略。首先,概述了系统的重要性和潜在故障可能带来的影响。接着,详细阐述了在系统出现故障时的监控、初步响应、故障定位和紧急应对措施。文章进一步深入探讨了系统
从零开始精通DICOM:架构、消息和对象全面解析
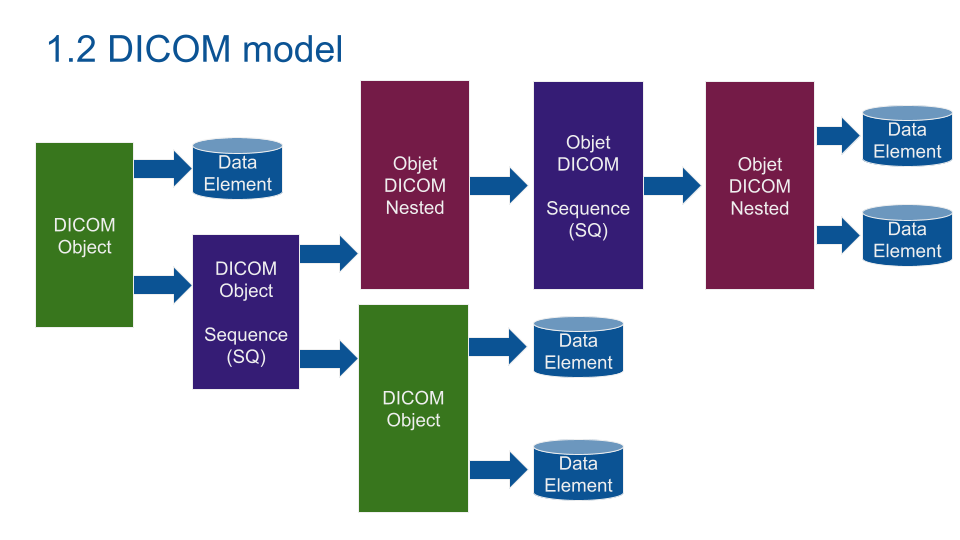
# 摘要
DICOM(数字成像和通信医学)标准是医疗影像设备和信息系统中不可或缺的一部分,本文从DICOM标准的基础知识讲起,深入分析了其架构和网络通信机制,消息交换过程以及安全性。接着,探讨了DICOM数据对象和信息模型,包括数据对象的结构、信息对象的定义以及映射资源的作用。进一步,本文分析了DICOM在医学影像处理中的应用,特别是医学影像设备的DICOM集成、医疗信息系统中的角色以及数据管理与后处理的
配置管理数据库(CMDB):最佳实践案例与深度分析

# 摘要
本文系统地探讨了配置管理数据库(CMDB)的概念、架构设计、系统实现、自动化流程管理以及高级功能优化。首先解析了CMDB的基本概念和架构,并对其数据模型、数据集成策略以及用户界面进行了详细设计说明。随后,文章深入分析了CMDB自
【DisplayPort over USB-C优势大揭秘】:为何技术专家力荐?

# 摘要
DisplayPort over USB-C作为一种新兴的显示技术,将DisplayPort视频信号通过USB-C接口传输,提供了更高带宽和多功能集成的可能性。本文首先概述了DisplayPort over USB-C技术的基础知识,包括标准的起源和发展、技术原理以及优势分析。随后,探讨了在移动设备连接、商
RAID级别深度解析:IBM x3650服务器数据保护的最佳选择

# 摘要
本文全面探讨了RAID技术的原理与应用,从基本的RAID级别概念到高级配置及数据恢复策略进行了深入分析。文中详细解释了RAID 0至RAID 6的条带化、镜像、奇偶校验等关键技术,探讨了IBM x3650服务器中RAID配置的实际操作,并分析了不同RAID级别在数据保护、性能和成本上的权衡。此外,本文还讨论了RAID技术面临的挑战,包括传统技术的局限性和新兴技术趋势,预测了RAID在硬件加速和软件定义存储领域的发展方向。通过对RAID技术的深入
【jffs2数据一致性维护】

# 摘要
本文全面探讨了jffs2文件系统及其数据一致性的理论与实践操作。首先,概述了jffs2文件系统的基本概念,并分析了数据一致性的基础理论,包括数据一致性的定义、重要性和维护机制。接着,详细描述了jffs2文件系统的结构以及一致性算法的核心组件,如检测和修复机制,以及日志结构和重放策略。在实践操作部分,文章讨论了如何配置和管理jffs2文件系统,以及检查和维护
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )