利用Electron实现数据持久化:使用IndexedDB和SQLite
发布时间: 2023-12-17 04:48:51 阅读量: 223 订阅数: 46 

数据持久化
# 1. 简介
## 1.1 Electron简介
Electron是一个跨平台的桌面应用程序开发框架,它基于Node.js和Chromium,可以用HTML、CSS和JavaScript创建原生应用程序。Electron提供了一种使用Web技术开发桌面应用的简单方式,无需掌握复杂的编程语言或工具。
Electron的特点包括:
- 具有丰富的API和插件生态系统,可以轻松访问底层操作系统功能。
- 支持多平台,可以在Windows、macOS和Linux等操作系统上运行。
- 提供自定义窗口和菜单的能力。
- 支持跨窗口和跨进程通信。
- 可以使用众多的开源工具和库来增强应用的功能。
由于Electron基于Web技术,它使得开发者可以使用熟悉的前端技术栈来构建桌面应用程序,降低了开发门槛并提高了开发效率。
## 1.2 数据持久化简介
数据持久化是指将数据长久保存在存储介质中的过程。在桌面应用程序中,数据持久化非常重要,因为用户的数据需要在应用程序关闭后仍然存在。
常见的数据持久化方式包括文件存储、关系型数据库、键值对数据库等。不同的数据持久化方式适用于不同的场景,开发者需要根据具体需求选择合适的方式。
在本文中,我们将介绍两种常见的数据持久化方式:IndexedDB和SQLite,并探讨它们在Electron中的使用。我们将分别介绍它们的特点、使用方法以及优缺点,帮助读者选择最合适的数据持久化方案。
## 2. IndexedDB介绍与使用
IndexedDB是一种在浏览器中存储大量结构化数据的浏览器内数据库。它提供一个类似于SQL的API,用于执行事务性数据库操作,并具有较高的性能和可扩展性。
### 2.1 IndexedDB介绍
IndexedDB是浏览器端的非关系型数据库,其设计目标是存储大量结构化数据并支持高性能的增删改查操作。它使用对象存储空间来存储数据,与传统的关系型数据库相比,它更适合存储大规模的非结构化或半结构化数据。
### 2.2 在Electron中使用IndexedDB
在Electron应用程序中,可以使用IndexedDB来实现数据的持久化存储。Electron提供了对IndexedDB的原生支持,开发者可以直接在Electron的主进程或渲染进程中使用IndexedDB来管理数据。
### 2.3 编写基本的IndexedDB操作代码
以下是在Electron渲染进程中使用IndexedDB的基本操作代码示例:
```javascript
// 打开或创建数据库
let request = window.indexedDB.open('my_database', 1);
// 数据库打开/创建成功回调
request.onsuccess = function(event) {
let database = event.target.result;
// ...进行数据库操作
};
// 数据库打开/创建失败回调
request.onerror = function(event) {
console.log("IndexedDB error: " + event.target.errorCode);
};
// 数据库升级回调
request.onupgradeneeded = function(event) {
let database = event.target.result;
let objectStore = database.createObjectStore('my_object_store', { keyPath: 'id' });
// ...设置对象存储空间的结构
};
// 执行事务性操作
let transaction = database.transaction(['my_object_store'], 'readwrite');
let objectStore = transaction.objectStore('my_object_store');
// ...进行增删改查操作
// 关闭数据库
database.close();
```
### 2.4 IndexedDB的优缺点
优点:
- 支持存储大量数据,并且对大型数据集有较好的性能表现
- 提供了事务性操作,确保数据的完整性和一致性
- 可以在浏览器端独立于网络连接进行操作
缺点:
- API较为复杂,学习曲线较陡
- 不支持简单的SQL查询语法,需要通过游标进行数据检索
- 兼容性问题,在某些旧版本的浏览器中可能存在兼容性和性能问题
### 3. SQLite数据库介绍与使用
#### 3.1 SQLite数据库介绍
SQLite是一种基于文件的轻型关系型数据库,它不需要一个独立的服务器进程,而是直接从应用程序中访问存储在磁盘上的数据库文件。SQLite具有简单、高效、可靠、易于使用的特点,被广泛应用于各种应用程序中,包括桌面应用、移动应用和嵌入式设备等。
#### 3.2 在Electron中使用SQLite
在Electron中使用SQLite需要借助第三方库,比如`sqlite3`。首先,我们需要在Electron项目中安装`sqlite3`库:
```shell
npm install sqlite3 --save
```
安装完成后,就可以在Electron的渲染进程(renderer process)中使用SQLite了。
#### 3.3 通过SQLite实现数据持久化的例子
接下来,我们通过一个简单的例子来演示如何使用SQLite在Electron中实现数据持久化。假设我们正在开发一个笔记应用,需要将用户的笔记保存到数据库中。
首先,我们需要创建一个SQLite数据库文件,命名为`notes.db`。
然后,我们可以使用以下代码来创建一个`notes`表,用于存储用户的笔记:
```javascript
const sqlite3 = require('sqlite3').verbose();
// 创建数据库
const db = new sqlite3.Database('notes.db');
// 创建notes表
db.serialize(() => {
db.run(`
CREATE TABLE IF NOT EXISTS notes (
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT,
content TEXT
)
`);
});
// 关闭数据库连接
db.close();
```
以上代码中,我们使用`sqlite3`库的`Database`类创建了一个数据库连接,并通过`db.run()`方法执行了一个SQL语句来创建`notes`表。`notes`表包含三个字段:`id`、`title`和`content`。
接下来

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以Electron为主题,深入探讨了如何利用这一技术构建强大的桌面应用。首先从基础入手,介绍了如何利用HTML、CSS和JavaScript开发第一个桌面应用,并详细讲解了Electron的主进程与渲染进程的通信机制。随后,专栏从窗口管理、界面设计、菜单、导航栏等方面展开,帮助读者全面掌握Electron应用的界面设计技巧。此外,还涵盖了与本地文件系统的交互、数据持久化、网络通信、跨平台支持、进程管理与调试、快捷键和热键定制、安全与加密、自动化测试、事件驱动编程、插件开发、数据可视化、实时通讯、音视频处理以及硬件交互等众多领域。通过本专栏的学习,读者可以全面掌握Electron的应用开发技能,实现更加丰富多样的桌面应用功能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
YXL480扩展性探讨:系统升级与扩展的8大策略
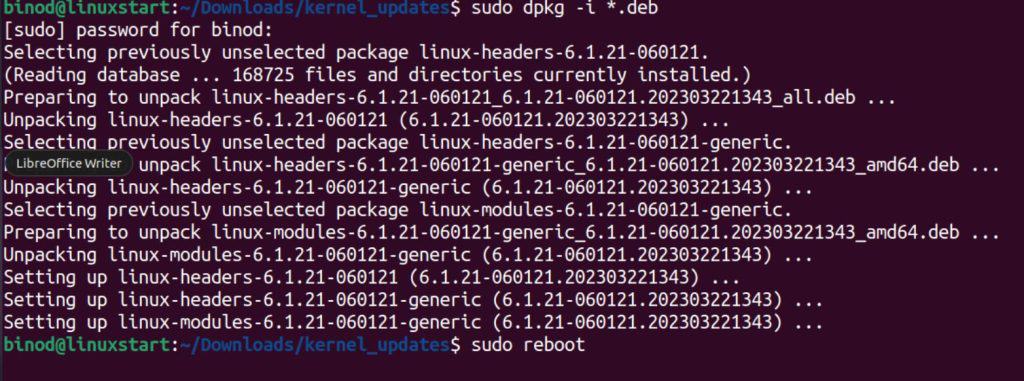
# 摘要
随着信息技术的快速发展,YXL480系统面临着不断增长的性能和容量需求。本文对YXL480的扩展性进行了全面概述,并详细分析了系统升级和扩展策略,包括硬件和软件的升级路径、网络架构的优化、模块化扩展方法、容量规划以及技术债务管理。通过实践案例分析,本文揭示了系统升级与扩展过程中的关键策略与决策,挑战与解决方案,并进行了综合评估与反馈。文章最后对新兴技术
【编译原理核心算法】:掌握消除文法左递归的经典算法(编译原理中的算法秘籍)

# 摘要
编译原理中的文法左递归问题一直是理论与实践中的重要课题。本文首先介绍编译原理与文法左递归的基础知识,随后深入探讨文法左递归的理论基础,包括文法的定义、分类及其对解析的影响。接着,文章详细阐述了消除直接与间接左递归的算法原理与实践应用,并
【S7-1200_S7-1500故障诊断与维护】:最佳实践与案例研究

# 摘要
本文首先对S7-1200/1500 PLC进行了概述,介绍了其基本原理和应用基础。随后,深入探讨了故障诊断的理论基础,包括故障诊断概念、目的、常见故障类型以及诊断方法和工具。文章第三章聚焦于S7-1200/1500 PLC的维护实践,讨论了日常维护流程、硬件维护技巧以及软件维护与更新的策略。第四章通过故障案例研究与分析,阐述了实际故障处理和维护
分析劳动力市场趋势的IT工具:揭秘如何保持竞争优势

# 摘要
在不断变化的经济环境中,劳动力市场的趋势分析对企业和政策制定者来说至关重要。本文探讨了IT工具在收集、分析和报告劳动力市场数据中的应用,并分析了保持竞争优势的IT策略。文章还探讨了未来IT工具的发展方向,包括人工智能与自动化、云计算与大数据技术,以及
搜索引擎核心组成详解:如何通过数据结构优化搜索算法

# 摘要
搜索引擎是信息检索的重要工具,其工作原理涉及复杂的数据结构和算法。本文从搜索引擎的基本概念出发,逐步深入探讨了数据结构基础,包括文本预处理、索引构建、搜索算法中的关键数据结构以及数据压缩技术。随后,文章分析了搜索引擎算法实践应用,讨论了查询处理、实时搜索、个性化优化等关键环节。文章还探讨了搜索引擎高级功能的实现,如自然语言处理和多媒体搜索技术,并分析了大数据环境下搜索引
Edge存储释放秘籍:缓存与历史清理策略

# 摘要
Edge存储是边缘计算中的关键组成部分,其性能优化对于提升整体系统的响应速度和效率至关重要。本文首先介绍了Edge存储的基础概念,包括缓存的作用、优势以及管理策略,探讨了如何在实践中权衡缓存大小
解决兼容性难题:Aspose.Words 15.8.0 如何与旧版本和平共处

# 摘要
Aspose.Words是.NET领域内用于处理文档的强大组件,广泛应用于软件开发中以实现文档生成、转换、编辑等功能。本文从版本兼容性问题、新版本改进、代码迁移与升级策略、实际案例分析
深入SPC世界:注塑成型质量保证与风险评估的终极指南
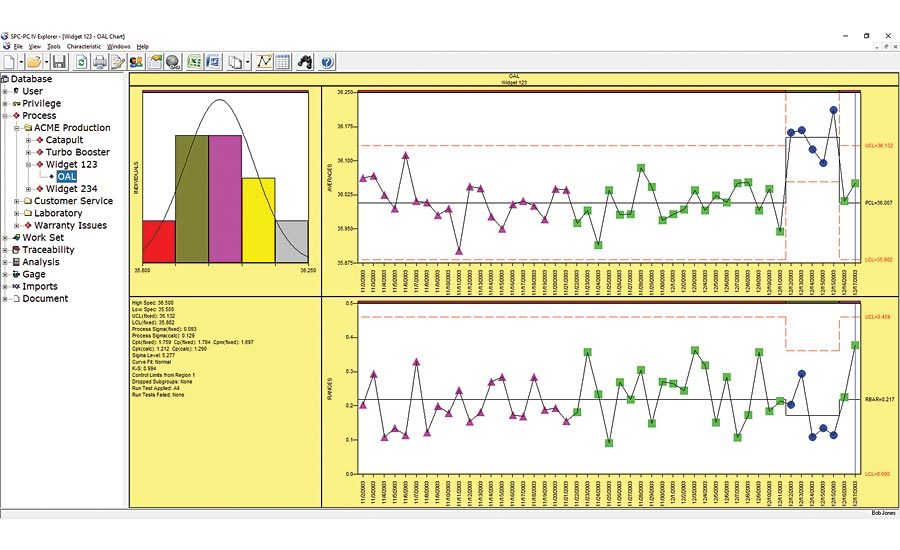
# 摘要
本文综合探讨了注塑成型技术中统计过程控制(SPC)的应用、风险管理以及质量保证实践。首先介绍了SPC的基础知识及其在注塑成型质量控制中的核心原理和工具。接着,文章详述了风险管理流程,包括风险识别、评估和控制策略,并强调了SPC在其中的应用
IT服务连续性管理策略:遵循ISO20000-1:2018的实用指南
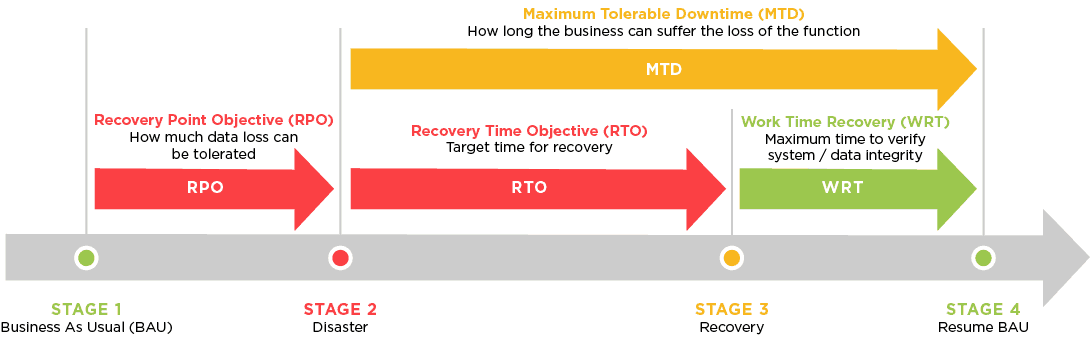
# 摘要
本文详细探讨了IT服务连续性管理,并对ISO20000-1:2018标准进行了深入解读。通过分析服务连续性管理的核心组成部分、关键概念和实施步骤,本文旨在为读者构建一个全面的管理体系。同时,文章强调了风险评估与管理
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )