【容器化与Kubernetes入门】:简化部署与管理的容器技术,轻松驾驭容器
发布时间: 2025-01-10 05:43:17 阅读量: 1 订阅数: 4 

驾驭容器化浪潮:Linux中Kubernetes容器编排实战指南

# 摘要
随着云计算和微服务架构的兴起,容器化技术已经成为了现代应用开发和部署的关键组成部分。本文首先介绍了容器化技术的基础知识,并详细解析了容器的核心原理和结构,对比了容器与虚拟机的区别,并探讨了Docker作为主流容器技术的基础知识。随后,本文深入阐述了Kubernetes的核心概念,包括架构、资源对象模型以及集群管理与调度原理。在实践操作章节中,文章提供了部署和管理Kubernetes集群的具体步骤,并讨论了监控与日志管理的重要性。接着,探讨了容器化技术的高级主题,如CI/CD的实践、容器安全以及多云和混合云环境下的应用。最后,文章展望了容器化技术和Kubernetes的未来发展趋势,包括容器编排工具的演变和Kubernetes社区的发展。本文通过对容器化技术及其在云平台中应用的全面分析,为读者提供了一个深入理解这一关键技术领域的指南。
# 关键字
容器化技术;Docker;Kubernetes;CI/CD;容器安全;多云部署
参考资源链接:[SAGA GIS 5.0用户指南:免费开源的地理信息系统](https://wenku.csdn.net/doc/22jgxt5uf4?spm=1055.2635.3001.10343)
# 1. 容器化技术简介
## 1.1 容器化技术的兴起
在现代软件开发和部署领域,容器化技术已经成为了一种变革性的力量。容器化允许开发者在可移植的、自给自足的容器中封装应用程序及其依赖环境,从而确保应用在不同环境中的运行一致性。这种技术的发展,不仅大幅提高了应用的部署速度,还增强了应用的可移植性和可扩展性。
## 1.2 容器化的优势
与传统的虚拟机技术相比,容器化技术具有显著的优势。容器启动速度更快,资源占用更少,因此能够提供更高的效率和密度。通过容器化,开发团队可以在本地开发环境中构建、测试并运行生产级的应用,极大地减少了“在我的机器上能运行”的问题。
## 1.3 容器化技术的广泛应用
容器化技术已经广泛应用于微服务架构、持续集成/持续部署(CI/CD)、DevOps实践以及多云和混合云部署策略中。企业通过容器化简化了复杂系统的管理,提高了系统的灵活性和弹性,实现了快速响应市场变化的能力。
随着容器技术的不断完善和成熟,IT专业人士和企业都在寻找如何有效利用这一技术来优化和加速软件的开发和部署过程。接下来的章节将详细介绍容器技术的原理、结构以及容器化技术在实际应用中的案例和最佳实践。
# 2. 容器技术详解
## 2.1 容器的原理和结构
容器是一种轻量级、可移植的封装技术,它将应用程序和应用程序运行所需的环境打包在一起,包括代码、运行时、系统工具、系统库以及设置。这种打包方式使得应用程序能够在任何支持容器引擎的环境中一致地运行。
### 2.1.1 容器与虚拟机的对比
虚拟机(VM)是通过虚拟化技术将一台物理服务器分割成多个隔离的虚拟环境,每个环境都可以安装操作系统、软件和应用程序。相比之下,容器不包含操作系统层,而是共享宿主机的操作系统内核,这使得容器在启动速度和资源消耗上大大优于虚拟机。
| 特性 | 容器 | 虚拟机 |
| ------------ | ------------------ | ---------------- |
| 启动速度 | 几秒钟 | 几分钟 |
| 系统资源消耗 | 较低 | 较高 |
| 硬件隔离 | 无 | 有 |
| 操作系统 | 共享宿主机内核 | 每个虚拟机内嵌 |
| 移植性 | 可移植 | 较差 |
| 部署复杂性 | 较简单 | 较复杂 |
容器的轻量级特性让其在现代DevOps实践中更为流行,因为它们能够快速响应应用程序的部署需求,并提供更高的资源利用效率。
### 2.1.2 容器的内核特性
容器的核心技术基础是Linux内核的namespace和cgroup特性。Namespace提供了系统资源的隔离,而cgroup用于限制、记录、隔离进程组所使用的物理资源(CPU、内存、磁盘I/O等)。
- Namespace提供了六个方面的隔离:Mount、UTS、IPC、PID、Network、User。
- cgroups可以限制容器使用的资源,例如CPU使用率、内存使用量、I/O。
以下是关于namespace和cgroup的代码块示例:
```c
// namespace示例代码:创建一个新的UTS namespace
int child_pid;
char *const child_args[] = {"/bin/bash", NULL};
// 使用clone系统调用创建新进程和新namespace
child_pid = clone(child_stack, stacktop, SIGCHLD | CLONE_NEWUTS, NULL);
```
```c
// cgroup示例代码:设置CPU限制
char *path = "/sys/fs/cgroup/cpu/our_cgroup";
mkdir(path, 0755);
FILE *f;
f = fopen(path"/cpu.cfs_period_us", "w");
fwrite("100000", sizeof(char), 6, f);
fclose(f);
f = fopen(path"/cpu.cfs_quota_us", "w");
fwrite("-1", sizeof(char), 3, f); // 限制为任意数量的CPU时间,-1 表示无限制
fclose(f);
```
## 2.2 Docker技术基础
### 2.2.1 Docker的安装与配置
Docker是一个开源的应用容器引擎,它使得开发者能够打包他们的应用以及应用的依赖包到一个可移植的容器中,然后发布到任何支持Docker的平台上。安装Docker涉及几个步骤:下载安装包、安装Docker服务、启动服务,并验证安装。
```bash
# 安装Docker
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io
# 启动Docker服务
sudo systemctl start docker
# 验证安装
sudo docker run hello-world
```
### 2.2.2 Docker镜像与容器的生命周期管理
Docker镜像是一个只读模板,用来创建Docker容器。容器是镜像的可运行实例。Docker提供了一系列命令来管理镜像和容器的生命周期,包括创建、启动、停止、删除等。
```bash
# 下载一个镜像
docker pull ubuntu:latest
# 创建并启动一个容器
docker run -it ubuntu bash
# 列出当前运行的容器
docker ps
# 停止一个容器
docker stop <container_id>
# 删除一个容器
docker rm <container_id>
```
### 2.2.3 Docker网络与存储的配置
Docker提供了灵活的网络配置选项,包括默认的桥接网络和用户定义的桥接网络、宿主网络以及无网络配置。此外,Docker支持数据卷(Volumes)和绑定挂载(Bind Mounts)等多种存储方式,以实现数据的持久化和在不同容器间的共享。
```bash
# 创建一个数据卷
docker volume create my-volume
# 创建一个绑定挂载
docker run -v /path/on/host:/path/in/container
```
## 2.3 容器化的实际应用
### 2.3.1 单容器应用部署
单容器应用部署是将单个应用程序封装到一个容器中,然后启动和管理这个容器。它适用于那些相对独立的应用程序,比如简单的Web服务、数据库服务等。
```bash
# 使用Docker部署一个Nginx服务器
docker run --name my-nginx -p 8080:80 -d nginx
```
### 2.3.2 多容器应用的编排与管理
对于需要多个服务协同工作的复杂应用,容器编排工具如Docker Compose和Kubernetes就显得尤为重要。它们帮助管理和编排多个容器之间的依赖关系和生命周期。
```yaml
# Docker Compose配置文件示例
version: '3'
services:
web:
image: nginx
ports:
- "8080:80"
app:
image: my-app
depends_on:
- web
```
```bash
# 使用Docker Compose启动服务
docker-compose up -d
```
通过本章节的介绍,我们从原理和结构上对容器技术有了深入的理解,包括容器与虚拟机的对比以及容器的内核特性。紧接着,我们学习了Docker技术基础,涵盖了Docker的安装与配置、镜像与容器的生命周期管理,以及网络和存储的配置。最后,我们探讨了容器化的实际应用,包括单容器应用部署和多容器应用的编排与管理。这些内容为下一章节Kubernetes核心概念的深入理解奠定了坚实的基础。
# 3. Kubernetes核心概念
## Kubernetes架构概述
### 控制平面与工作节点
Kubernetes通过分离控制平面(Control Plane)和工作节点(Worker Node)的方式来实现集群的高效管理。控制平面负责决策,即决定集群的状态,而工作节点负责实际的容器运行。控制平面由API服务器、调度器(Scheduler)、控制器管理器(Controller Manager)等组件组成。API服务器是Kubernetes的前端,所有的管理操作都是通过它进行的。调度器负责将容器放置到合适的工作节点上。控制器管理器则运行控制器进程,这些控制器是集群的后台线程,负责实现不同的集群功能。
工作节点是Kubernetes集群中的工作负载节点,每个节点上运行着Kubelet和Kube-Proxy服务。Kubelet是负责管理容器生命周期的主要服务,它确保容器中的Pods正常运行。Kube-Proxy负责实现服务的网络规则,维护节点上的网络。
```mermaid
flowchart LR
subgraph "控制平面"
apiserver(apiserver)
scheduler(scheduler)
controller("控制器管理器")
end
subgraph "工作节点"
kubelet(kubelet)
kubeproxy("kube-proxy")
end
apiserver -->|API请求| scheduler
apiserver -->|API请求| controller
controller -->|控制信号| kubelet
controller -->|网络规则| kubeproxy
```
### 核心组件的作用与交互
Kubernetes的核心组件通过定义良好的API和控制循环(Control Loop)来维护集群的状态。API服务器作为集群的入口点,所有的操作都需要通过它进行。调度器则负责根据资源需求和可用资源将Pods调度到合适的节点上。控制器管理器中的控制器会不断检查集群的当前状态,并与期望的状态进行比较,如有差异则采取行动进行纠正。
例如,副本控制器(Replication Controller)会确保集群中始终有预期数量的Pod副本在运行。端点控制器(Endpoints Controller)管理服务(Service)与Pods之间的连接,确保服务可以访问到正确的Pods。命名空间控制器(Namespace Controller)会监控命名空间的变化,并创建默认的资源对象。
## Kubernetes资源对象模型
### Pod、Service和Deployment
在Kubernetes中,Pod是最小的部署单元,它封装了一个或多个容器(通常是Docker容器)、存储资源、一个独立的网络IP以及容器运行的指令等。Pod是短暂的,不具有自愈能力。因此,通常我们会使用Deployment来管理Pod的生命周期。Deployment为Pod和ReplicaSet提供声明式更新,可以描述应用的期望状态,并且持续监控Pod的实际状态,确保应用的期望状态得以实现。
Service是一组Pod的抽象,它为一组功能相同的Pod提供一个固定的访问点。通过Service,我们可以实现服务发现和负载均衡。Service通过标签选择器将流量路由到Pods,而不需要关心Pods的IP地址。
```mermaid
flowchart LR
deployment --> replicas[ReplicaSet]
replicas --> pods(Pods)
service --> selector[标签选择器]
selector --> pods
```
### ConfigMap和Secrets
ConfigMap和Secrets是存储配置信息的资源。ConfigMap用于存储非保密性质的配置信息,而Secrets则用于存储敏感信息,如密码、OAuth令牌和ssh密钥。通过将配置信息外部化,我们能够更容易地修改和更新配置,而无需重建容器镜像。
ConfigMap可以被Pod作为卷(Volume)挂载,或者以环境变量的形式注入到Pod的容器中。Secrets则通常以卷的形式挂载到Pod中,并且以文件的形式存储在Pod的文件系统内。使用Secrets可以确保敏感数据的安全性,因为它只会在请求的节点上解密为可用的文件。
## 集群管理与调度原理
### Kubernetes调度器的工作机制
Kubernetes调度器的工作机制是将未调度的Pods分配到健康的节点上运行。调度器会考虑多个因素,比如资源需求、资源限制、硬件/软件/策略约束、亲和性和反亲和性等。调度过程可以分为两个阶段:首先是预选(Predicate),即过滤掉不符合要求的节点;其次是优选(Prioritize),即对符合要求的节点进行优先级排序。
在预选阶段,调度器会进行一系列检查,例如节点是否健康、是否有足够的资源以及是否符合Pod的特定要求等。一旦预选阶段完成,调度器将进入优选阶段,对剩下的节点进行排序,根据预定的策略(如资源使用率、节点亲和性等)为Pod选择最佳节点。
### 资源配额与限制
在Kubernetes集群中,资源配额(Resource Quotas)和资源限制(Resource Limits)用于管理资源的使用。资源配额用于限制命名空间中所有资源的总量,包括CPU、内存和存储等,以防止资源的过度使用。资源限制则是设定Pods或容器可以使用的最大资源量。
资源配额和限制通常是配合使用的。配额确保了集群资源的合理分配,而限制则保证了单个Pod或容器不会占用过多资源,影响到其他Pods的运行。通过这样的机制,Kubernetes集群能够更加稳定和高效地运行,避免资源竞争导致的服务质量下降。
```yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-quota
spec:
hard:
pods: "10"
requests.cpu: "1"
requests.memory: 1Gi
limits.cpu: "2"
limits.memory: 2Gi
```
以上示例是一个资源配额的定义,限制了命名空间中Pods的数量以及CPU和内存的请求和限制。
以上内容详细介绍了Kubernetes架构、资源对象模型以及集群管理和调度的原理。这些核心概念是理解和使用Kubernetes的基础,掌握它们对于实现高效的容器化应用部署和管理至关重要。接下来的章节中,我们将深入了解如何将这些理论应用到实践中去。
# 4. Kubernetes实践操作
## 4.1 部署Kubernetes集群
### 4.1.1 使用kubeadm部署集群
`kubeadm`是Kubernetes官方提供的集群部署工具,它简化了集群部署的流程,允许用户快速设置Kubernetes控制平面和工作节点。下面介绍如何使用`kubeadm`来部署一个高可用性的Kubernetes集群。
首先,需要准备至少两台服务器,一台作为控制平面节点,其余作为工作节点。在所有节点上执行以下操作:
安装`kubeadm`、`kubelet`和`kubectl`:
```bash
# 安装kubeadm、kubelet和kubectl
sudo apt-get update && sudo apt-get install -y apt-transport-https curl
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
cat <<EOF | sudo tee /etc/apt/sources.list.d/kubernetes.list
deb https://apt.kubernetes.io/ kubernetes-xenial main
EOF
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
sudo apt-mark hold kubelet kubeadm kubectl
```
初始化控制平面节点:
```bash
# 初始化集群控制平面
sudo kubeadm init --pod-network-cidr=10.244.0.0/16
```
在初始化过程中,`kubeadm`会输出一个`kubeadm join`命令,这个命令稍后在工作节点加入集群时会用到。
配置`kubectl`访问:
```bash
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
```
安装网络插件,例如使用`flannel`:
```bash
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
```
对于工作节点,需要在每台工作节点上执行以下命令:
```bash
# 使用从控制平面初始化时获取的kubeadm join命令加入集群
sudo kubeadm join [your-control-plane-ip]:6443 --token [token] --discovery-token-ca-cert-hash sha256:[hash]
```
在控制平面节点上,通过`kubectl get nodes`命令验证所有节点是否已成功加入集群并处于`Ready`状态。
### 4.1.2 集群的扩展与维护
Kubernetes集群的扩展通常指的是增加新的工作节点,以便能够承载更多的工作负载。使用`kubeadm`扩展集群是一个相对简单的过程,只需要在新的工作节点上重复上述工作节点加入集群的步骤即可。
集群维护主要包括更新集群组件的版本、升级`kubeadm`和`kubelet`、重新配置或替换损坏的节点等。为了安全和稳定性,集群升级应遵循一定的计划和步骤:
1. 使用`kubeadm version`检查当前集群版本,并在kubernetes.io网站上查阅升级路径和版本兼容性。
2. 根据官方升级指南,逐步升级控制平面节点上的`kube-apiserver`、`kube-controller-manager`、`kube-scheduler`等核心组件。
3. 依次升级工作节点上的`kubelet`。
4. 在升级过程中,使用`kubectl get nodes`和`kubectl get pods -A`检查集群状态,确保所有组件和Pods都正常运行。
5. 清理旧版本的Pods和容器,确保它们在升级后能够使用新版本的API正常运行。
#### 表格:Kubernetes集群版本升级前后的检查项
| 检查项 | 升级前 | 升级后 |
| --- | --- | --- |
| 控制平面状态 | 所有控制平面组件运行正常 | 所有控制平面组件运行正常 |
| 工作节点状态 | 所有节点运行正常 | 所有节点运行正常 |
| Pod运行状态 | 所有Pods都在预期的命名空间内运行 | 所有Pods都在预期的命名空间内运行,且不使用已弃用的API |
| API版本兼容性 | 所有客户端与当前版本API兼容 | 所有客户端与新版本API兼容 |
| 附加组件更新 | 所有附加组件(如网络插件)兼容当前集群版本 | 所有附加组件更新至兼容新版本的集群 |
集群的扩展和维护是日常操作的一部分,这些操作需要谨慎进行,以避免潜在的服务中断。通过执行上述步骤,管理员可以确保集群持续稳定地运行,并能够适应不断变化的资源需求。
## 4.2 Kubernetes应用部署与管理
### 4.2.1 使用kubectl部署和管理应用
`kubectl`是Kubernetes的命令行工具,用于部署和管理应用。它提供了丰富的命令来与Kubernetes API交互,从而完成各种操作。下面介绍如何使用`kubectl`来部署一个简单的应用,并对其进行管理。
首先,创建一个简单的nginx部署:
```bash
# 创建一个名为nginx-deployment的Deployment
kubectl create deployment nginx-deployment --image=nginx
```
之后,可以通过`kubectl get`命令查看 Deployment 状态:
```bash
# 查看Deployments状态
kubectl get deployments
```
为了让外部能够访问这个nginx服务,可以创建一个Service:
```bash
# 创建Service
kubectl expose deployment nginx-deployment --port=80 --type=LoadBalancer
```
查看Service状态:
```bash
# 查看Services状态
kubectl get services
```
使用`kubectl`管理应用时,经常需要执行的操作包括但不限于扩缩容Pods数量、滚动更新应用、回滚到旧版本等。例如扩缩容Pods:
```bash
# 扩缩容Pods到3个副本
kubectl scale deployment nginx-deployment --replicas=3
```
滚动更新:
```bash
# 更新Deployment的镜像
kubectl set image deployment/nginx-deployment nginx=nginx:1.15.5
```
回滚操作:
```bash
# 回滚到上一个版本
kubectl rollout undo deployment/nginx-deployment
```
#### mermaid格式流程图:kubectl管理应用的典型流程
```mermaid
graph LR
A[创建Deployment] --> B[查看Deployments]
B --> C[创建Service]
C --> D[查看Services]
D --> E[扩缩容Pods]
E --> F[滚动更新应用]
F --> G[回滚到旧版本]
```
管理Kubernetes应用需要对`kubectl`命令有深入理解,并熟悉Kubernetes资源对象的操作。通过一系列的`kubectl`命令,管理员可以有效地部署、扩展和更新集群中的应用程序。
### 4.2.2 网络策略和存储的配置
Kubernetes网络策略(NetworkPolicy)是一种定义策略,用于控制Pod间的访问流量。它是基于标签选择器来指定哪些Pod可以相互通信。
下面是一个简单的网络策略配置示例:
```yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector:
matchLabels:
role: db
policyTypes:
- Ingress
- Egress
ingress:
- from:
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 6379
egress:
- to:
- podSelector:
matchLabels:
role: backend
ports:
- protocol: TCP
port: 80
```
通过`kubectl apply`应用上述配置,可以限制只有标签为`role: frontend`的Pod可以访问标签为`role: db`的Pod,并且只有标签为`role: db`的Pod可以访问标签为`role: backend`的Pod。
Kubernetes存储的配置涉及到PersistentVolume(PV)、PersistentVolumeClaim(PVC)和StorageClass的设置。PV是集群中的一块存储空间,PVC是对存储空间的请求。StorageClass用于管理不同类型的存储,例如,基于本地存储、云存储或网络存储。
配置存储的一般步骤如下:
1. 创建StorageClass资源:
```yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: example-storageclass
provisioner: kubernetes.io/aws-ebs
parameters:
type: gp2
reclaimPolicy: Retain
allowVolumeExpansion: true
volumeBindingMode: Immediate
```
2. 创建PVC请求存储:
```yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: example-pvc
spec:
storageClassName: example-storageclass
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
```
3. 在Pod定义中使用PVC:
```yaml
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
containers:
- name: example-container
image: nginx
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: example-storage
volumes:
- name: example-storage
persistentVolumeClaim:
claimName: example-pvc
```
通过上述步骤,Pod就可以使用持久化的存储,当Pod被删除时,PVC会保留下来,如果Pod重新创建,仍然可以使用原来的存储数据。
管理存储是确保Kubernetes应用可靠运行的重要环节。正确配置网络策略和存储资源,可以帮助维护应用的数据安全和持久性。
## 4.3 监控与日志管理
### 4.3.1 集群状态监控
Kubernetes的监控一般分为两类:集群级监控和应用级监控。集群级监控关注集群资源的使用情况,比如CPU、内存和存储的使用情况,以及节点和Pod的状态。Prometheus是目前广泛使用的集群监控工具,它不仅支持拉取(Pull)监控数据,还支持推送(Push)监控数据。
以下是使用Prometheus监控Kubernetes集群的简单步骤:
1. 部署Prometheus Operator,它负责管理Prometheus实例:
```bash
# 安装Prometheus Operator
kubectl apply -f https://raw.githubusercontent.com/coreos/prometheus-operator/release-0.30/bundle.yaml
```
2. 创建Prometheus资源定义文件,指定监控的目标:
```yaml
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: k8s
spec:
serviceMonitorSelector:
matchLabels:
team: frontend
```
3. 创建ServiceMonitor来监控特定的部署:
```yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
team: frontend
name: frontend-monitor
spec:
endpoints:
- interval: 30s
port: web
selector:
matchLabels:
app: frontend
namespaceSelector:
matchNames:
- default
```
这样,Prometheus就会定期从标签为`app: frontend`的Pods中的`web`端口收集数据。
#### 表格:监控Kubernetes集群的关键指标
| 指标 | 描述 |
| --- | --- |
| Node资源使用情况 | CPU、内存和磁盘的使用率 |
| Pod资源使用情况 | 每个Pod的CPU和内存使用量 |
| Pod状态 | 每个Pod的健康状态和重启次数 |
| API Server健康 | Kubernetes API Server的响应时间和服务状态 |
| ETCD健康 | Kubernetes的键值存储的性能和状态 |
| Controller Manager和Scheduler状态 | 控制平面组件的状态 |
集群状态监控有助于快速识别性能瓶颈或故障节点,从而保持集群的稳定性和可用性。
### 4.3.2 应用日志的聚合与分析
Kubernetes中的应用日志可以通过标准输出(stdout)和标准错误(stderr)捕获。集群中可能有成百上千的Pods,手动管理和分析这些日志非常繁琐。因此,使用日志聚合系统(如ELK Stack,即Elasticsearch, Logstash和Kibana)来集中管理日志变得尤为重要。
部署ELK Stack到Kubernetes集群中的一般步骤如下:
1. 使用Helm或其他部署工具部署Elasticsearch和Kibana。Helm是Kubernetes的包管理工具,可以方便地部署复杂应用。
```bash
# 使用Helm添加Elasticsearch官方仓库
helm repo add elastic https://helm.elastic.co
# 安装Elasticsearch
helm install elasticsearch elastic/elasticsearch
# 安装Kibana
helm install kibana elastic/kibana
```
2. 部署Filebeat,它是一个轻量级的日志传输代理,可以将日志文件传输到Elasticsearch中进行索引。
```yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
data:
filebeat.yml: |
filebeat.inputs:
- type: container
paths:
- /var/log/containers/*.log
output.elasticsearch:
hosts: ["elasticsearch-master:9200"]
```
3. 部署完成后,使用Kibana的Web界面来创建索引模式,并通过它查看、搜索和分析日志。
应用日志的聚合与分析使得监控应用的健康状况和性能变得更加容易,有助于快速定位和解决生产环境中的问题。
Kubernetes的监控和日志管理是保持系统稳定性和高效运行的重要组成部分。通过合理配置和使用这些工具,可以大大减轻运维团队的工作负担,提升整个系统的维护效率。
# 5. 容器化高级主题
## 5.1 持续集成与持续部署(CI/CD)
### 5.1.1 CI/CD管道的概念和工具
CI/CD是现代软件开发中实现快速迭代和交付的核心实践,它整合了开发和运维工作流程,确保了代码变更能够安全、高效地自动部署到生产环境中。
CI(持续集成)要求开发人员频繁地将代码变更合并到共享仓库中。每次代码提交都会触发自动化构建和测试,以确保新代码与现有代码库兼容,不会引入新的错误。CD(持续部署)和持续交付(持续交付是一个相关的实践,它确保软件在发布给用户之前随时保持在可发布状态)是CI的自然延伸,自动化将通过所有测试的代码变更部署到生产环境。
实现CI/CD的工具有很多,比如Jenkins、GitLab CI、CircleCI、Travis CI和Spinnaker等。这些工具提供了流水线管理,自动化测试,环境配置,代码部署等功能,能够适应不同的开发和部署需求。
### 代码块示例
以下是一个简单的Jenkinsfile示例,用于定义CI/CD管道的各个阶段。
```groovy
pipeline {
agent any
stages {
stage('Checkout') {
steps {
checkout scm
}
}
stage('Build') {
steps {
// 使用Maven构建项目
sh 'mvn clean package'
}
}
stage('Test') {
steps {
// 运行测试
sh 'mvn test'
}
}
stage('Deploy') {
steps {
// 使用kubectl部署到Kubernetes集群
script {
sh "kubectl apply -f ./deployments"
}
}
}
}
}
```
在这个例子中,每个阶段都清晰地定义了其目的和执行的动作。在"Build"阶段,我们调用了Maven命令来编译和打包应用程序。在"Test"阶段,我们运行了测试用例来验证代码质量。最后,在"Deploy"阶段,使用`kubectl`将应用程序部署到Kubernetes集群。
## 5.2 容器安全基础
### 5.2.1 容器安全的风险与对策
容器技术虽然带来了巨大的便利,但也引入了新的安全挑战。容器化环境的一个主要风险是潜在的安全漏洞,如操作系统级别的漏洞和未授权访问。容器之间的隔离性并不像虚拟机那样强,因此,如果一个容器被攻破,攻击者可能会利用这一路径攻击其他容器或宿主机。
对策包括但不限于:
- 使用最小化基础镜像,减少潜在攻击面。
- 定期更新和打补丁。
- 使用容器安全扫描工具,如Aqua Security、Twistlock等,来发现容器内的安全漏洞和配置问题。
- 实施严格的访问控制和网络策略,例如使用Kubernetes的Network Policies来限制容器间的通信。
- 对容器进行持续监控和日志分析,以便于及时检测异常行为。
### 代码块示例
```yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny
spec:
podSelector: {}
policyTypes:
- Ingress
- Egress
```
这个NetworkPolicy示例定义了一个名为`default-deny`的策略,它默认拒绝所有入站和出站的网络流量。所有的Pod都将使用此策略,除非另有指定的NetworkPolicy覆盖了它。
## 5.3 多云与混合云环境下的容器化
### 5.3.1 多云部署的挑战与解决方案
多云部署意味着在不同的云服务提供商之间部署和管理应用程序和服务。这种做法带来了灵活性和选择性的好处,同时也伴随着管理复杂性、一致性和合规性的挑战。
挑战包括:
- 管理分散的资源和监控工具。
- 确保跨云的网络连通性和数据一致性。
- 遵守不同云服务提供商的安全政策和标准。
解决方案包括:
- 使用统一的容器管理平台,如Kubernetes,来管理跨云部署。
- 利用云原生工具和服务,比如云服务提供商的负载均衡器和数据库服务。
- 实施跨云的监控和日志策略,例如使用Prometheus和Loki等开源工具。
### 表格示例
下面是不同云服务提供商提供的一些关键云服务的对比表格。
| 服务 | AWS | Google Cloud | Azure |
|------------|---------------------|----------------------|---------------------|
| 容器服务 | Amazon EKS | Google Kubernetes Engine | Azure Kubernetes Service |
| 负载均衡器 | ELB | Google Load Balancer | Azure Load Balancer |
| 数据库服务 | Amazon RDS | Google Cloud SQL | Azure SQL Database |
| 对象存储 | Amazon S3 | Google Cloud Storage | Azure Blob Storage |
通过这样的对比,技术人员可以清晰地看到各个云服务提供商在容器化服务方面的特点和优势,从而更好地规划跨云部署策略。
# 6. 容器化与Kubernetes的未来展望
容器化技术与Kubernetes在过去几年中已经深刻改变了IT行业的运维和开发方式。随着技术的不断发展和实践的深入,我们可以看到其未来的趋势、社区的发展,以及在不同行业中的具体应用案例。以下将深入探讨这些话题。
## 6.1 容器化技术的发展趋势
容器化技术正在不断地演变,其中,容器编排工具的改进尤为重要。从早期的简单容器部署到现在复杂的应用编排,容器化技术经历了飞速的发展。
### 6.1.1 容器编排工具的演变
随着容器技术的普及,编排工具也在不断创新和演化。Kubernetes已经成为容器编排领域的事实标准。然而,新的工具和解决方案仍在不断涌现,以满足更复杂的业务需求。例如,开源工具如Argo和Rancher都已经为Kubernetes提供了更多的功能和更简化的用户体验。
### 6.1.2 Serverless架构与容器的结合
Serverless计算模型通过抽象底层基础设施,使开发者能够专注于编写代码而不是管理服务器。Kubernetes作为编排平台,正在与Serverless架构相融合。例如,Knative就是Kubernetes上的一个开源项目,旨在为构建、部署和管理现代无服务器工作负载提供便利。
## 6.2 Kubernetes社区与生态系统
Kubernetes社区非常活跃,且随着Kubernetes的普及,其生态系统正在快速增长。
### 6.2.1 Kubernetes的社区资源
社区贡献了大量的资源,包括最佳实践、文档和工具。社区论坛、Slack频道和KubeCon都是Kubernetes学习和交流的重要平台。此外,CNCF还提供了大量的案例研究、教程和其他学习资料。
### 6.2.2 生态系统中的工具和服务
围绕Kubernetes的工具和服务已经构成了一个庞大的生态系统。从云服务商提供的托管Kubernetes服务到专门的监控和日志工具,都在不断优化以支持Kubernetes的使用。例如,Prometheus和Grafana已成为监控Kubernetes集群的流行组合。
## 6.3 案例研究:容器化技术的行业应用
容器化和Kubernetes正在被越来越多的行业所采用,特别是在那些对敏捷性、可扩展性要求极高的领域,如金融和互联网行业。
### 6.3.1 金融行业的容器化实践
金融行业依赖于高可靠性和严格的安全标准。容器化通过提高代码的可移植性、缩短部署时间以及提供更好的资源隔离,帮助金融机构在保持安全的同时快速响应市场变化。例如,摩根大通的Kubernetes集群已经承载了其核心银行业务的负载。
### 6.3.2 互联网公司的容器化案例分享
互联网公司对技术的快速迭代和弹性需求极高,容器化技术的引入可以大幅度提升部署效率和资源利用率。以Netflix为例,其庞大的微服务架构已经完全运行在Kubernetes上,提高了系统的灵活性和稳定性。通过自动化容器编排,Netflix能够更快速地发布新功能,并且能够轻松地扩展其服务以应对用户量的激增。
容器化和Kubernetes的未来将继续沿着提高自动化、加强安全性、拓展更多行业应用的方向发展。同时,开源社区的活力和整个生态系统中工具的创新将是推动技术发展的关键因素。随着技术的成熟,容器化将成为企业数字化转型的重要驱动力。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《UserGuideV5.pdf》专栏汇集了涵盖多个技术领域的实用指南和深入见解。从大数据处理到DevOps实践,再到容器化和微服务架构,专栏提供了一系列关键技术和最佳实践,旨在帮助读者提升效率、创新和系统稳定性。此外,专栏还涵盖移动应用开发、IT项目管理和软件架构设计等主题,为读者提供了构建可扩展、弹性和可维护系统的全面指南。通过深入探讨行业趋势和最佳实践,《UserGuideV5.pdf》专栏为技术专业人士和业务领导者提供了宝贵的资源,帮助他们驾驭技术变革,实现数字化转型目标。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
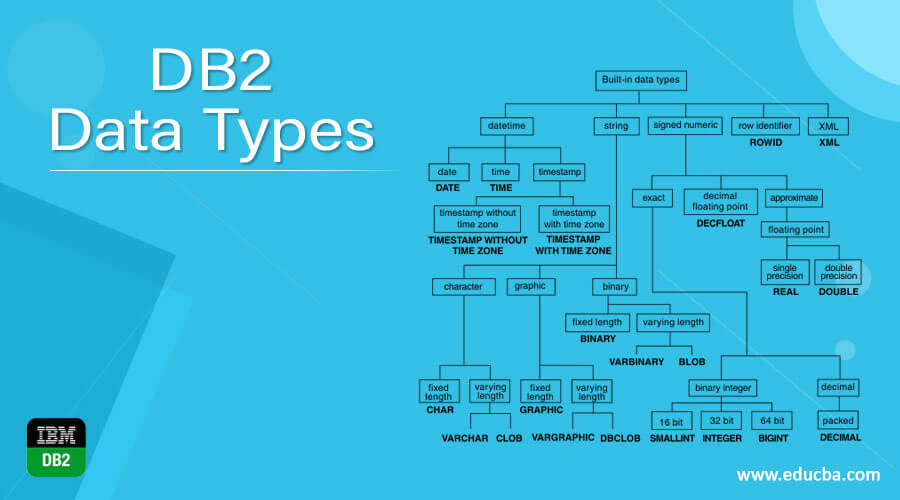
Toad for DB2解决方案:10个专业技巧助你成为数据库管理大师
# 摘要
本文全面介绍了Toad for DB2这一强大的数据库管理工具,涵盖了从基础安装配置到高级查询优化、自动化管理以及故障诊断的全方位实践知识。文中详细解析了Toad for DB2的用户界面和工具,数据库对象和安全管理的细节,还包括了SQL编程、性能监控与调优的高级技巧。此外,本文还探讨了如何创建和管理自动化任务,进行脚本调试与错误处理,以及批量数据操作与变更管理。最后,分享了Toa
CAA3D标注技术深度剖析:原理、应用与实战演练
# 摘要
CAA3D标注技术作为一种先进的三维标注方法,正逐渐应用于包括工业设计、虚拟现实和医疗健康等多个领域。本文首先概述了CAA3D标注技术的基本概念及其理论基础,然后详细探讨了其在不同领域的具体应用,如3D模型构建、逆向工程、VR/AR内容开发、医学图像标注等。文章还通过实战演练的方式,介绍了标注
Nginx错误日志分析技巧:快速定位并解决启动失败的秘诀

# 摘要
Nginx作为高性能的HTTP和反向代理服务器,其错误日志是监控、诊断和优化服务器性能的关键资源。本文第一章概述了Nginx错误日志的重要性及其作用。第二章深入解析了错误日志的结构和内容,包括日志级别、时间戳、常见错误类型,以及关键的HTTP状态码和错误代码。第三章讨论
宇龙V4.8数控仿真软件与实际加工对比分析:为什么它是行业的选择?

# 摘要
本文对宇龙V4.8数控仿真软件进行了全面的概述和分析。首先介绍了数控加工的基础理论,包括数控机床工作原理、核心技术及其精度和质量控制。接着深入探讨了宇龙V4.8的理论基础,其中包括仿真工作机制、在数控教学中的应用及优化发展趋势。之后,通过对比分析,探讨了宇龙V4.8与实际数控加工的仿真准确性、安全性和操作便捷性,以及成本效益。文章还通过行业
【TongWeb V8.0新手必备】:7步打造快速响应的Web应用

# 摘要
本文旨在详细介绍TongWeb V8.0的部署、性能优化以及高级功能应用。首先对TongWeb V8.0的基础架构和快速搭建Web应用环境的步骤进行了全面介绍,包括系统兼容性、软件安装、以及安装配置过程。接着,文章深入探讨了Web应用性能优化技巧,涵盖代码优化、资源压缩
【Mann-Whitney Test实战高手】:独立样本分析的终极指南
# 摘要
Mann-Whitney测试是一种非参数统计方法,用于比较两个独立样本的中位数是否存在显著差异。本文首先介绍了Mann-Whitney测试的基本概念和理论基础,包括假设检验、独立样本的定义、测试工作原理及统计量的计算方法。接着,文章详细阐述了Mann-Whitney测试的实践步骤,包括数据的准备、使用不同统计软件进行测试,以及结果的解读和报告撰写。此外,文章还探讨了Mann-Whitney测试的高级应用,如多组比较、非参数效应量的计算以及缺失数据的处理策略。最后,通过案例分析,本文展示了Mann-Whitney测试在实际研究中的应用,并对研究结果进行了解释和讨论。
# 关键字
Ma
【蓝牙通信稳定性研究】:CH9141DS1在复杂环境下的性能揭秘
# 摘要
蓝牙通信作为一种无线技术,广泛应用于短距离数据传输中。本文首先概述了蓝牙技术及其标准,重点介绍了CH9141DS1芯片的特点与优势。随后,文章分析了复杂环境下蓝牙通信所面临的挑战,探讨了信号干扰、环境噪声等因素对通信稳定性的影响,并提出了保证连接稳定性和数据传输速率的关键要素。为了验证CH9141D
操作系统课程设计报告:揭秘操作系统设计的9个必备要素与实施细节

# 摘要
本文系统地介绍了操作系统的概念、组成和实践应用,并深入探讨了其安全设计与性能优化的关键技术。通过对系统内核、内存管理、文件系统、多任务处理、设备驱动以及安全机制的分析,本文阐述了操作系统的基本功能和设计要素。同时,针对操作系统安全性的各个方面,包括认证授权
单片机基础编程教程:掌握这5大技能,编程不再是难题

# 摘要
本论文全面介绍了单片机编程的各个方面,从基础硬件和编程语言的概述到高级应用和项目实战技巧的提升。首先,概述了单片机编程的重要性及其硬件基础,包括CPU、存储器、输入/输出端口、外围设备等关键组成部分。接着,深入探讨了汇编语言和C语言在单片机编程中的应用,以及集成开发环境(IDE)和编译烧录工具等编程环境和工具的使用。在实践技巧方面,详细说
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )