PyCharm数据序列化实战案例:深入剖析与高效问题解决
发布时间: 2024-12-11 17:28:22 阅读量: 7 订阅数: 14 

微信小程序源码医院挂号系统设计与实现-服务端-毕业设计.zip

# 1. PyCharm与数据序列化基础
在IT行业中,数据序列化是一种常见的技术手段,通过将数据结构或对象状态转换为可存储或传输的格式进行处理。本章节将带你深入理解序列化的基础概念,并介绍如何在PyCharm中利用Python实现序列化操作。
## 1.1 序列化定义及其重要性
序列化(Serialization)是将数据结构或对象状态转换为可存储或传输的格式的过程,常用于数据交换、持久化存储、缓存等场景。在Python中,常见的序列化格式包括JSON、XML和Protobuf等。
```python
import json
import pickle
# 示例:使用JSON序列化一个Python字典
data = {'name': 'Alice', 'age': 25}
json_data = json.dumps(data)
```
## 1.2 Python中的序列化方式
Python提供了多种内置方式来实现数据序列化。例如,`json`模块可以进行JSON格式的序列化,而`pickle`模块则支持Python特有的序列化格式。了解这些方式对于选择合适的序列化策略至关重要。
```python
# 使用pickle模块进行对象序列化
pickled_data = pickle.dumps(data)
```
## 1.3 PyCharm工具在序列化工作中的角色
PyCharm,作为一款功能强大的Python IDE,提供了丰富的调试、优化和代码管理工具,能够显著提高序列化代码的开发效率和质量。在本章节中,我们将探讨如何在PyCharm中高效实现和管理序列化任务。
本章内容仅作为数据序列化和PyCharm使用方法的起点,后续章节将深入探讨不同序列化格式的详细应用和优化技巧。通过本章的学习,你将为掌握更复杂的序列化技术打下坚实的基础。
# 2. JSON序列化与反序列化实践
在这一章中,我们将深入探索JSON序列化的世界,通过具体的实践和技巧,来掌握如何有效地在Python中处理JSON数据。JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。JSON的普及性使其成为Web应用和数据交换的理想选择。
## 2.1 JSON序列化的基本原理
### 2.1.1 JSON格式的介绍
JSON格式的数据以键值对的方式存储,它支持多种数据类型,包括字符串、数字、数组、布尔值以及null。JSON结构简单且易于理解,主要由对象(Object)和数组(Array)组成,对象用大括号`{}`包围,数组用中括号`[]`包围。对象包含一组无序的键值对,而数组包含一系列有序的值。
### 2.1.2 Python中的json模块使用
Python标准库中的`json`模块提供了处理JSON数据的工具。`json.dumps()`用于将Python对象编码成JSON字符串,`json.loads()`用于将JSON字符串解码成Python对象。以下是一个简单的例子:
```python
import json
# Python字典转换为JSON字符串
data = {
"name": "John Doe",
"age": 30,
"is_employee": True
}
json_str = json.dumps(data)
print(json_str) # {"name": "John Doe", "age": 30, "is_employee": true}
# JSON字符串转换为Python字典
new_data = json.loads(json_str)
print(new_data) # {'name': 'John Doe', 'age': 30, 'is_employee': True}
```
使用`json`模块时,我们需要注意数据类型的一致性,以及可能的编码错误。JSON标准只支持UTF-8、UTF-16和UTF-32编码的文本。
## 2.2 JSON序列化的高级技巧
### 2.2.1 定制化的JSON编码器
在某些情况下,我们需要定制JSON编码器来处理特定的数据类型,比如日期时间对象或自定义类。我们可以继承`json.JSONEncoder`类,重写`default()`方法来实现这一功能。
```python
import json
from datetime import datetime
class DateTimeEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, datetime):
return obj.isoformat()
return super().default(obj)
date = datetime.now()
print(json.dumps(date, cls=DateTimeEncoder))
```
### 2.2.2 处理特殊数据类型的序列化
对于一些特殊的数据类型,比如Python中的`set`类型,我们可能需要在编码前将其转换为`list`,因为JSON标准不支持集合类型。
```python
data = {"name": "John Doe", "hobbies": {"reading", "swimming"}}
# 将set转换为list
data['hobbies'] = list(data['hobbies'])
json_str = json.dumps(data)
print(json_str)
```
## 2.3 JSON反序列化的深度解析
### 2.3.1 校验JSON数据的有效性
在反序列化JSON数据之前,我们需要确保这些数据是有效的。`json`模块提供了`json.JSONDecoder`类的`decode()`方法,该方法会抛出`JSONDecodeError`异常,如果输入的字符串不是有效的JSON格式。我们可以通过捕获这个异常来校验数据的有效性。
```python
try:
data = '{"name": "John Doe", "age": "thirty"}'
result = json.loads(data)
except json.JSONDecodeError:
print("Invalid JSON data.")
```
### 2.3.2 反序列化过程中的异常处理
在处理复杂的JSON数据时,我们可能会遇到格式错误或数据类型不匹配的情况。我们需要在反序列化过程中添加异常处理逻辑,以确保程序的健壮性。
```python
json_str = '{"name": "John Doe", "age": 30, "is_employee": true}'
try:
data = json.loads(json_str)
print(data)
except json.JSONDecodeError as e:
print(f"Failed to parse JSON: {e}")
```
通过深入掌握JSON序列化和反序列化的基础和高级技巧,我们可以有效地在Python项目中处理JSON数据,无论是存储到数据库、传输到Web服务,还是用于配置管理。随着章节的深入,我们将会逐步介绍XML和Protobuf序列化技术,并探讨如何解决序列化过程中可能遇到的问题,最终通过真实世界的案例应用来巩固我们的知识。
# 3. XML序列化实战
XML(Extensible Markup Language)是一种用于存储和传输数据的标记语言,以其结构化和自我描述性的特点被广泛应用于各种数据交换格式中。序列化与反序列化是数据持久化和传输的关键步骤,特别是在需要跨平台或跨语言交换数据时。本章将详细探讨XML的序列化与反序列化过程,以及如何在Python中高效地实现这些操作。
## 3.1 XML序列化与反序列化的概念
### 3.1.1 XML的基本结构和特点
XML文档由元素组成,元素可以包含属性、文本和嵌套的子元素。基本的XML结构是树状的,由声明、元素、属性、注释、文本、CDATA部分和处理指令组成。
```xml
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<bo
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 PyCharm 中数据序列化的具体方法,涵盖了 JSON 和 XML 序列化的详细指南。专栏标题为“PyCharm 使用数据序列化的具体方法”,旨在为读者提供全面的理解和应用知识。文章标题包括“PyCharm 中 JSON 序列化的艺术”、“PyCharm 中 XML 序列化的专家指南”和“PyCharm 数据序列化:框架对比与最佳序列化工具的选择”,突出了不同序列化技术的深入分析。专栏旨在帮助读者掌握 PyCharm 中数据序列化的各个方面,从基本概念到高级技巧和最佳实践。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
HDQ协议与BQ27742协同工作:解决实际问题的实战案例分析
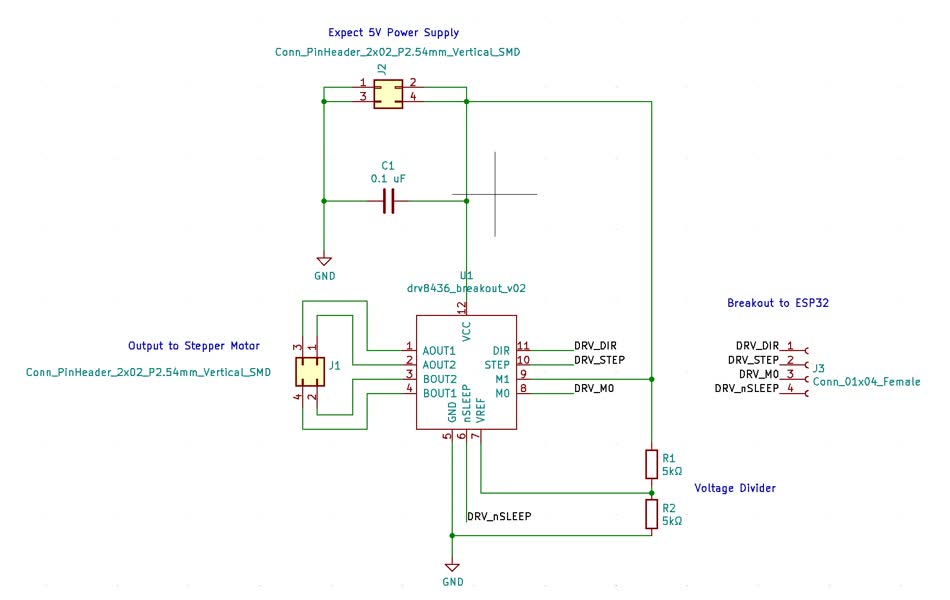
# 摘要
本文重点探讨了HDQ协议及其在智能电池管理芯片BQ27742中的应用。首先,文章概述了HDQ协议的背景、特点及其与I2C通信协议的对比,然后深入分析了BQ27742芯片的功能特性、与主机系统的交互方式和编程模型。在此基础上,文章通过实例详细阐述了HDQ协议与BQ27742的协同工作,包括硬件连接、数据采集处理流程
汇川伺服驱动故障诊断速成:功能码助你快速定位问题
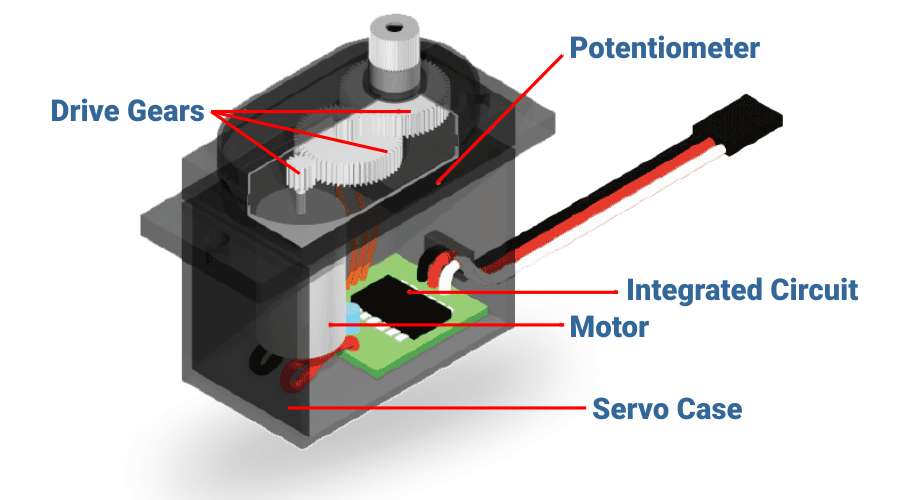
# 摘要
随着自动化技术的不断进步,伺服驱动系统在工业生产中扮演着关键角色。本文第一章提供了伺服驱动故障诊断的基础知识,为深入理解后续章节内容打下基础。第二章详述了功能码在伺服驱动故障诊断中的关键作用,包括功能码的定义、分类、重要性、读取方法以及与伺服驱动器状态的关联。第三章基于功能码对伺服驱动常见故障进行判断与分析,并提出了故障定位的具体应用和维护优化的建议。第四章探讨了故障诊断的进阶技巧,
【物联网与IST8310融合】:打造智能传感网络的终极秘诀

# 摘要
本文深入探讨了物联网技术的基础知识及IST8310传感器的特性与应用。首先,介绍了IST8310传感器的工作原理、通信协议、配置与校准方法,为进一步研究奠定基础。随后,文章详细阐述了IST8310与物联网网络架构的融合,以及其在智能传感网络中的应用,着重分析了数据安全、传感器数据流管理及安全特性。通过多个实践案例,展示了如何从理
富勒WMS故障排除:常见问题快速解决指南

# 摘要
随着信息技术的快速发展,富勒WMS在仓储管理领域得到了广泛应用,但其稳定性和性能优化成为了行业关注的焦点。本文首先概述了富勒WMS系统的基本概念和故障排查所需预备知识,然后深入探讨了故障诊断的理论基础和实践技巧,包括日志分析、网络诊断工具使用以及性能监控。接着,文章详细分析了硬件和软件故障的类型、识别、处理与修复方法,并通过案例分析加深理解。此外,本文还重点介绍了网络故障的理论和
【从启动日志中解码】:彻底解析Ubuntu的kernel offset信息
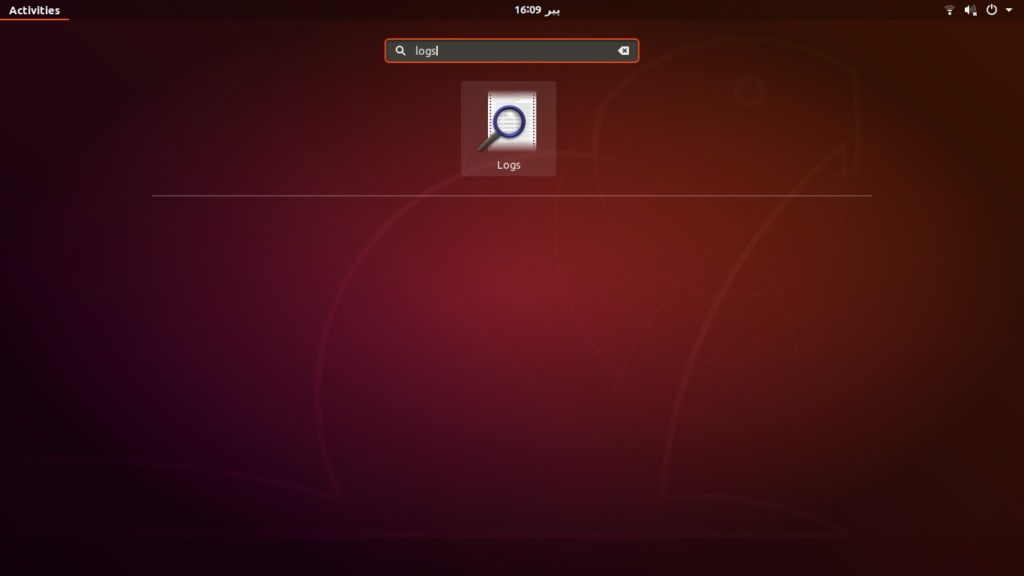
# 摘要
本文针对Ubuntu系统中的Kernel Offset进行了全面深入的研究。首先介绍了Kernel Offset的定义、重要性以及在系统启动和安全方面的作用。文章通过对Ubuntu启动日志的分析,阐述了如何获取和解析Kernel Offset信息,以及它在系统中的具体应用。此外,本文还详细介绍了如何在实际操作中修改和调试Kernel Offset,
Rational Rose与敏捷开发的融合:提升团队协作与效率的必备指南

# 摘要
本文针对Rational Rose工具在敏捷开发中的应用进行全面探讨,重点分析了Rational Rose的基础功能与敏捷开发流程的结合,以及如何在敏捷团队中高效应用该工具进行项目规划、迭代管理、持续集成和测试、沟通协作等方面。同时,文章也对Rational Rose的高级应用和优化进行了深入分析,包括模型驱动开发实践、自动化代码生成和
【qBittorrent进阶应用】:自定义配置与优化指南

# 摘要
本文详细介绍了qBittorrent这款流行的BitTorrent客户端软件,从基本概念、安装步骤到用户界面操作,再到高级功能的自定义与优化。文中深入探讨了qBittorrent的高级设置选项,如何通过优化网络接口、带
【6SigmaET散热分析实践】:R13_PCB文件导入与散热分析,实战演练提升技能
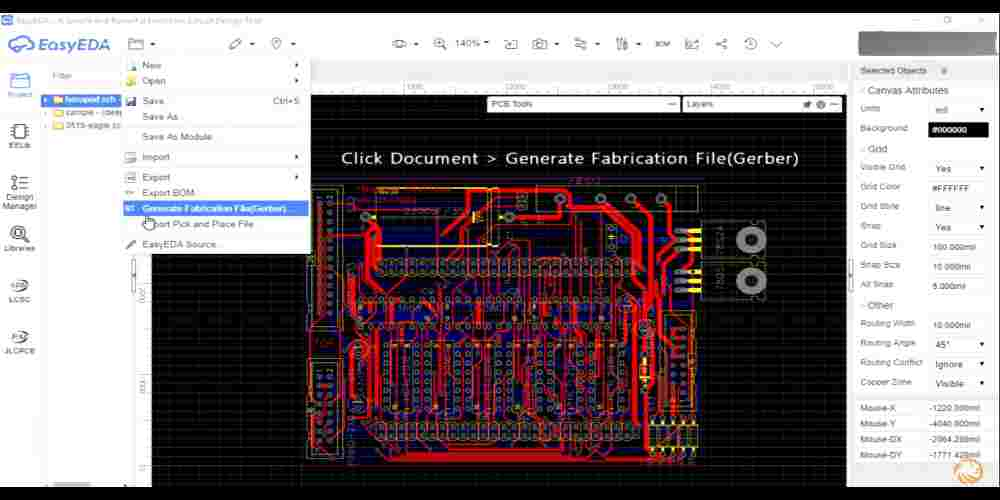
# 摘要
本文深入探讨了6SigmaET软件在散热分析中的应用,涵盖了散热分析的基础理论、R13_PCB文件的导入流程、散热分析原理与应用、实战演练以及高级散热分析技术等内容。首先介绍了6SigmaET散热分析的基础知识和R13_PCB文件的关键结构与导入步骤。接着,本文阐述了散热分析理论基础和在6SigmaET中建立散热模型
宠物殡葬业的数据备份与灾难恢复:策略与实施的最佳实践

# 摘要
随着宠物殡葬业对数据安全和业务连续性的日益重视,本文提供了该行业在数据备份与恢复方面的全面概述。文章首先探讨了数据备份的理论基础,包括备份的重要性、类型与技术,以及最佳实践。接着,分析了灾难恢复计划的制定、执行以及持续改进的过程。通过实际案例,本文还讨论了备份与恢复
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )