




线程安全性与函数式编程:django.utils.functional模块的深入探讨


ImportError:无法从“django.utils.encoding”导入名称“force text”Python 错误
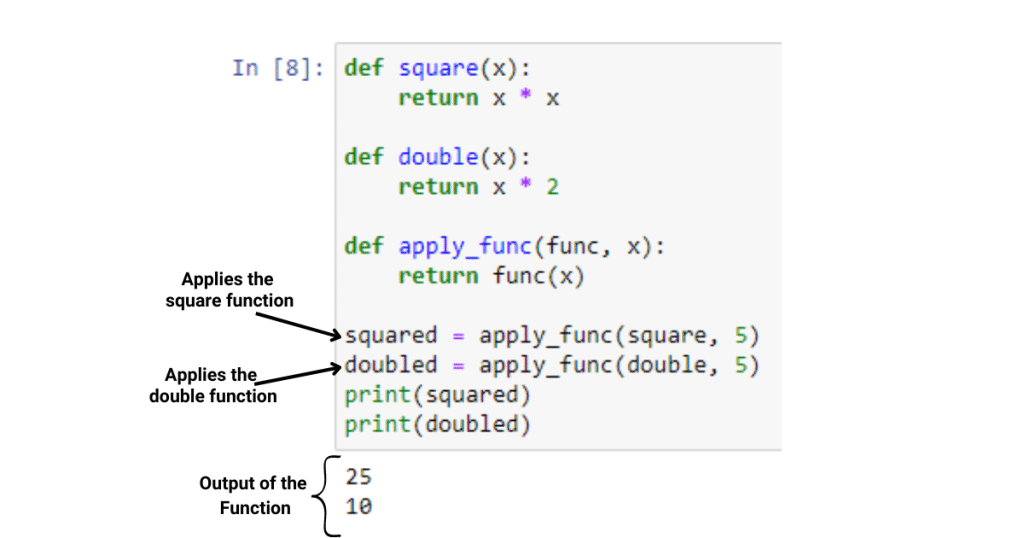
1. 线程安全性与函数式编程概述
在现代软件开发中,随着多核处理器的普及和应用程序对高并发处理需求的增加,线程安全性和函数式编程成为了开发者必须掌握的关键技术。线程安全性是指当多个线程访问某个类时,不管运行时序如何,这个类都能保证正确的执行。而函数式编程,作为一种编程范式,强调使用函数来构建软件,并且倡导不可变性和引用透明性。
在本章中,我们将首先探讨线程安全性的基本概念和其在并发编程中的重要性,接着介绍线程同步机制,如锁、信号量、原子操作和内存模型,最后通过案例分析来了解常见线程安全问题。此外,我们也将简要介绍函数式编程的核心理念,包括不变性和引用透明性,以及其在数据结构设计中的应用,如不可变集合和持久化数据结构,高阶函数与闭包。通过对比,我们将探讨函数式编程在代码简洁性和模块化方面带来的优势,同时也会分析其面临的性能挑战和优化策略。这将为接下来的章节中,深入探讨django.utils.functional模块以及在Django项目中如何结合线程安全性与函数式编程提供坚实的理论基础。
2. 线程安全性的理论基础
2.1 线程安全性的概念与重要性
2.1.1 理解线程安全
在多线程环境中,线程安全是一个确保共享资源访问不会导致不可预测行为或数据损坏的概念。线程安全的关键在于状态管理,它要求在任何时刻,对共享资源的访问都必须保持一致性和完整性。
线程安全问题通常出现在多个线程同时读写同一个变量或者同一段代码时。在没有适当的同步机制的情况下,这可能会导致数据竞争(race condition)等问题。数据竞争是指两个或多个线程在没有适当同步机制的情况下,同时访问和修改同一数据,从而导致程序结果不确定的情况。
在Java中,要实现线程安全,可以通过使用synchronized关键字、ReentrantLock锁等同步工具来控制对共享资源的访问。此外,Java还提供了线程安全的集合类,如ConcurrentHashMap和CopyOnWriteArrayList等。
2.1.2 线程安全与并发编程
线程安全是并发编程中的核心议题。在并发程序设计中,正确处理线程安全问题,确保数据一致性是至关重要的。这不仅涉及到基本的数据类型,还包括复杂的对象和对象图。
并发编程通常需要开发者在设计和编码时考虑如下几个方面:
- 线程创建和管理
- 同步机制的使用
- 线程之间的协作和通信
- 错误处理和异常安全
理解线程安全,对于设计可扩展、高效的并发应用至关重要。在多核处理器日益普及的今天,能否合理地利用多线程的能力,直接关系到程序的性能表现。
2.2 线程同步机制
2.2.1 锁和信号量
在多线程程序中,锁是一种同步机制,用于控制对共享资源的访问。锁可以防止多个线程同时进入临界区(critical section),从而避免竞态条件。
锁的两种基本类型是互斥锁(mutexes)和读写锁(read-write locks)。互斥锁保证在任何时刻只有一个线程可以访问某个资源。读写锁则允许多个线程同时读取共享资源,但写操作必须独占访问。
信号量(semaphores)是另一种同步机制,它允许多个线程同时访问有限数量的资源。信号量可以用来控制对资源池的访问,例如,限制同时访问数据库的线程数。
- // Java 示例:使用互斥锁
- Lock lock = new ReentrantLock();
- lock.lock();
- try {
- // 临界区
- // 访问或修改共享资源
- } finally {
- lock.unlock();
- }
在上述代码中,lock和unlock方法分别在进入和退出临界区时调用,确保了在临界区的代码块执行时,不会被其他线程中断。
2.2.2 原子操作和内存模型
原子操作是指那些在执行过程中不会被其他线程中断的操作。在硬件层面,许多现代处理器提供了原子指令来支持这些操作,如原子比较和交换(compare-and-swap)。
在软件层面,许多编程语言也提供了原子操作的库函数或内建方法。例如,在Java中,java.util.concurrent.atomic包提供了一系列原子类,如AtomicInteger和AtomicReference等。
原子操作通常用于实现锁和其他同步机制,它们保证了即使在多线程环境下,操作的执行仍然是不可分割的。
在多处理器系统中,内存模型定义了处理器间如何共享内存以及变量之间的可见性。这意味着,即便是在硬件层面实现了原子操作,程序员还是需要理解内存模型以确保代码在多线程环境下正确运行。
2.3 线程安全编程实践
2.3.1 设计模式在线程安全中的应用
在并发编程中,设计模式能够帮助我们以一种结构化的方式解决特定问题。一些设计模式,如监视器模式(Monitor Object Pattern)和读写器模式(Reader-Writer Pattern),直接关注于线程安全问题。
监视器模式通过一个对象来同步对共享资源的访问,这个对象包含了对象状态以及访问这些状态的方法。Java中的synchronized关键字可以用来实现监视器模式。
- // Java 示例:监视器模式
- public class MonitorObject {
- private final Object objectLock = new Object();
- private String sharedResource;
- public void accessResource() {
- synchronized (objectLock) {
- // 安全地访问和修改 sharedResource
- }
- }
- }
读写器模式适用于读多写少的场景,它允许多个读者同时访问共享资源,但在写入时必须独占访问。使用读写锁(如ReadWriteLock)可以实现该模式。
2.3.2 常见线程安全问题案例分析
在实际开发中,线程安全问题可能会非常隐蔽,只有在特定的并发条件下才会暴露。常见的线程安全问题包括数据竞争、死锁、资源泄露和活锁。
数据竞争是由于多个线程对同一资源进行无序写入导致数据不一致。
死锁发生在两个或多个线程相互等待对方释放锁,导致程序僵持。
资源泄露是由于长时间保持不必要的锁或资源,导致资源耗尽。
活锁是指线程因为避免冲突而不断重复执行某些操作,但又无法取得进展。
解决这些问题,通常需要仔细设计代码逻辑,尽可能减少共享资源的使用,合理分配锁的作用范围,并定期对线程安全代码进行审查和测试。例如,可以使用以下方式预防死锁:
- 确保锁总是按照相同的顺序获取和释放。
- 限制获取锁的等待时间。
- 使用锁的调试工具和代码检查器来帮助识别和预防死锁。
本节内容对线程安全性的理论基础进行了深入探讨,分析了线程安全的核心概念及其重要性,并详细介绍了线程同步机制,如锁和信号量以及原子操作和内存模型。同时,通过实际案例展示了设计模式在解决线程安全问题中的应用,以及对常见线程安全问题的案例分析。理解并运用这些知识对于提升多线程编程的能力和编写出健壮的并发代码至关重要。
3. 函数式编程的理论框架
3.1 函数式编程的核心理念
3.1.1 不变性与引用透明性
函数式编程强调不可变数据结构和引用透明性的概念。不可变性指的是数据一旦创建便不可更改

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【FLUKE_8845A_8846A维护秘籍】:专家分享的快速故障排除与校准技巧
【通信优化攻略】:深入BSW模块间通信机制,提升网络效率
EPLAN 3D功能:【从2D到3D的飞跃】:掌握设计转变的关键技术
内存优化:快速排序递归调用栈的【深度分析】与防溢出策略
无线定位技术:GPS与室内定位系统的挑战与应用
【Web开发者福音】:一站式高德地图API集成指南
【云网络模拟新趋势】:eNSP在VirtualBox中的云服务集成
【精挑细选RFID系统组件】:专家教你如何做出明智选择
【故障快速排除】:三启动U盘制作中的7大常见问题及其解决策略
空间数据分析与可视化:R语言与GIS结合的6大实战技巧


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















