提升ARM平台OpenCV性能的7大优化技巧:解锁图像处理潜能
发布时间: 2024-08-13 06:26:40 阅读量: 128 订阅数: 25 

2024年OpenCV基础功能快速上手指南:图像处理与特征提取

# 1. ARM平台OpenCV性能优化概述
OpenCV(Open Source Computer Vision Library)是一个开源计算机视觉库,广泛应用于图像处理、计算机视觉和机器学习等领域。在ARM平台上优化OpenCV性能至关重要,因为它可以提高应用程序的效率和响应能力。本章将概述OpenCV性能优化的重要性、常见瓶颈以及可用的优化策略。
# 2. OpenCV优化原理
### 2.1 OpenCV架构与并行计算
OpenCV是一个跨平台计算机视觉库,提供广泛的图像处理和计算机视觉算法。其架构旨在支持并行计算,以充分利用多核处理器和GPU的处理能力。
OpenCV的并行计算机制主要基于以下技术:
- **多线程:** OpenCV使用OpenMP库实现多线程并行,允许在多个线程上同时执行任务。
- **SIMD(单指令多数据):** OpenCV利用SIMD指令集,如ARM NEON和Intel SSE,在单个时钟周期内对多个数据元素执行相同的操作。
- **GPU加速:** OpenCV支持使用CUDA和OpenCL等GPU加速库,将计算密集型任务卸载到GPU上执行。
### 2.2 性能瓶颈分析与优化策略
OpenCV性能优化涉及识别和解决影响应用程序性能的瓶颈。常见的瓶颈包括:
- **算法复杂度:** 某些算法的计算复杂度很高,导致处理时间过长。
- **数据处理:** 图像和视频数据处理涉及大量数据传输和操作,可能成为性能瓶颈。
- **内存访问:** 频繁的内存访问会增加延迟,特别是当数据不位于缓存中时。
- **并行效率:** 并行算法的效率取决于任务的粒度和同步开销。
优化策略包括:
- **选择合适的算法:** 根据任务选择具有较低复杂度的算法。
- **优化数据处理:** 使用高效的数据结构和算法来处理数据。
- **优化内存访问:** 尽量将数据保存在缓存中,并使用内存对齐技术减少缓存未命中。
- **提高并行效率:** 调整任务粒度和同步机制以最大化并行性。
通过分析性能瓶颈并应用适当的优化策略,可以显著提高OpenCV应用程序的性能。
# 3. 指令集与编译器优化
### 3.1 ARM指令集优化
#### 3.1.1 NEON指令集
NEON(新扩展技术)指令集是ARM处理器中的一组单指令多数据(SIMD)指令,专门用于加速多媒体和信号处理任务。NEON指令集支持128位和64位数据类型,并提供了一系列用于向量操作的指令。
**NEON指令集优化示例:**
```c++
// 原代码
float sum = 0;
for (int i = 0; i < N; i++) {
sum += data[i];
}
// 使用NEON指令集优化后的代码
float32x4_t sum_vec = vdupq_n_f32(0.0f);
for (int i = 0; i < N; i += 4) {
sum_vec = vaddq_f32(sum_vec, vld1q_f32(data + i));
}
float sum = vaddvq_f32(sum_vec);
```
**逻辑分析:**
* 原代码使用循环逐个累加数组中的元素,计算总和。
* 优化后的代码使用NEON指令集的`vdupq_n_f32`、`vaddq_f32`和`vaddvq_f32`指令。
* `vdupq_n_f32`指令创建一个包含给定值的4个元素浮点向量。
* `vaddq_f32`指令将两个4个元素浮点向量相加。
* `vaddvq_f32`指令将4个元素浮点向量中的所有元素相加,得到一个标量结果。
* 优化后的代码将数组元素加载到NEON向量中,然后使用SIMD指令进行并行计算,从而提高了性能。
#### 3.1.2 SIMD指令集
SIMD(单指令多数据)指令集是一组指令,允许处理器一次对多个数据元素执行相同的操作。ARM处理器支持各种SIMD指令集,包括NEON和浮点SIMD指令集。
**SIMD指令集优化示例:**
```c++
// 原代码
float sum = 0;
for (int i = 0; i < N; i++) {
sum += data[i] * weight[i];
}
// 使用SIMD指令集优化后的代码
float32x4_t sum_vec = vdupq_n_f32(0.0f);
for (int i = 0; i < N; i += 4) {
float32x4_t data_vec = vld1q_f32(data + i);
float32x4_t weight_vec = vld1q_f32(weight + i);
sum_vec = vaddq_f32(sum_vec, vmulq_f32(data_vec, weight_vec));
}
float sum = vaddvq_f32(sum_vec);
```
**逻辑分析:**
* 原代码使用循环逐个计算数组元素与权重的乘积,然后累加。
* 优化后的代码使用SIMD指令集的`vdupq_n_f32`、`vld1q_f32`、`vmulq_f32`和`vaddvq_f32`指令。
* `vdupq_n_f32`指令创建一个包含给定值的4个元素浮点向量。
* `vld1q_f32`指令将4个元素浮点向量从内存加载到NEON向量中。
* `vmulq_f32`指令将两个4个元素浮点向量相乘。
* `vaddvq_f32`指令将4个元素浮点向量中的所有元素相加,得到一个标量结果。
* 优化后的代码将数组元素和权重加载到NEON向量中,然后使用SIMD指令进行并行计算,从而提高了性能。
### 3.2 编译器优化
#### 3.2.1 编译器选项
编译器选项可以影响编译后的代码的性能。ARM编译器提供了各种选项,用于优化代码大小、速度和功耗。
**编译器选项优化示例:**
```
arm-none-eabi-gcc -O3 -march=armv8-a -mfpu=neon
```
**参数说明:**
* `-O3`:启用最高级别的优化。
* `-march=armv8-a`:指定目标ARM架构。
* `-mfpu=neon`:启用NEON指令集支持。
这些选项将指示编译器生成针对ARMv8-A架构并使用NEON指令集优化的代码。
#### 3.2.2 代码重构
代码重构是指修改代码结构和组织,以提高其性能。代码重构可以包括:
* **循环展开:**将循环体中的代码复制到循环之外,从而消除循环开销。
* **内联函数:**将小函数的代码直接插入到调用它的函数中,从而避免函数调用开销。
* **数据结构优化:**使用更适合特定任务的数据结构,例如使用数组而不是链表。
**代码重构优化示例:**
```c++
// 原代码
for (int i = 0; i < N; i++) {
if (data[i] > 0) {
sum += data[i];
}
}
// 代码重构后的代码
int sum = 0;
for (int i = 0; i < N; i++) {
sum += data[i] > 0 ? data[i] : 0;
}
```
**逻辑分析:**
* 原代码使用`if`语句检查每个元素是否大于0,然后将其添加到`sum`中。
* 优化后的代码使用条件运算符(`? :`)来简化条件检查,从而减少了分支开销。
# 4. 算法与数据结构优化
### 4.1 算法优化
#### 4.1.1 并行算法
在计算机视觉任务中,并行算法可以有效提升处理速度。OpenCV提供了多种并行算法,例如:
- **OpenMP**:基于共享内存的并行编程模型,支持多线程并行。
- **CUDA**:基于图形处理器的并行编程模型,支持大规模并行计算。
- **OpenCL**:跨平台的并行编程模型,支持异构计算。
选择合适的并行算法需要考虑任务的特性和硬件平台。例如,对于图像处理任务,OpenMP并行算法通常具有较好的性能。
#### 4.1.2 近似算法
在某些情况下,近似算法可以替代精确算法,以降低计算复杂度。近似算法通过牺牲一定精度来提高性能。
OpenCV提供了多种近似算法,例如:
- **快速傅里叶变换 (FFT)**:近似傅里叶变换,用于图像处理和信号处理。
- **均值漂移算法**:近似聚类算法,用于图像分割和目标跟踪。
- **哈希表**:近似数据结构,用于快速查找和插入。
使用近似算法时,需要权衡精度和性能之间的取舍。
### 4.2 数据结构优化
#### 4.2.1 缓存优化
缓存是计算机系统中用于存储最近访问的数据的高速存储器。优化数据结构以利用缓存可以显著提高性能。
以下是一些缓存优化技术:
- **空间局部性**:将相关数据存储在相邻的内存位置,以提高缓存命中率。
- **时间局部性**:将近期访问的数据存储在缓存中,以提高重用率。
- **数据对齐**:将数据结构对齐到缓存行边界,以减少缓存未命中。
#### 4.2.2 内存对齐
内存对齐是指将数据结构的成员对齐到特定边界。这可以提高内存访问效率,特别是在使用SIMD指令集时。
以下是一些内存对齐技术:
- **编译器选项**:使用编译器选项(例如,`-msse2`)来启用内存对齐。
- **手动对齐**:使用`__attribute__((aligned(n)))`属性手动对齐数据结构。
```cpp
// 手动对齐数据结构
struct AlignedStruct {
__attribute__((aligned(16))) int a;
__attribute__((aligned(16))) int b;
};
```
# 5. 系统与环境优化
### 5.1 系统优化
#### 5.1.1 操作系统选择
不同的操作系统对OpenCV的性能影响较大。对于ARM平台,推荐使用以下操作系统:
- **Linux**:Linux内核提供对ARM指令集的原生支持,并且具有较好的实时性和稳定性。
- **Android**:Android是基于Linux内核的移动操作系统,针对移动设备进行了优化,具有较低的资源占用和功耗。
#### 5.1.2 内核参数调优
内核参数的调优可以提升系统性能。对于OpenCV优化,可以考虑以下参数:
- **vm.swappiness**:控制内存交换的积极性,较低的数值可以减少内存交换,提升性能。
- **kernel.sched_latency_ns**:控制调度延迟,较低的数值可以减少调度延迟,提升实时性。
- **net.core.rmem_max**:控制接收缓冲区大小,较大的数值可以提高网络吞吐量。
### 5.2 环境优化
#### 5.2.1 OpenCV版本选择
OpenCV的版本选择对性能也有影响。一般来说,较新的版本包含了更多的优化和改进。对于ARM平台,推荐使用以下版本:
- **OpenCV 4.x**:最新版本,包含了对ARM指令集的优化和支持。
- **OpenCV 3.x**:较稳定版本,也提供了对ARM指令集的优化。
#### 5.2.2 OpenCV模块配置
OpenCV包含了大量的模块,根据实际应用需求选择和配置模块可以减少内存占用和提升性能。以下是一些常用的模块:
- **core**:核心模块,包含图像处理和计算机视觉的基本功能。
- **imgproc**:图像处理模块,提供图像滤波、形态学操作等功能。
- **highgui**:高层用户界面模块,提供图像显示和交互功能。
通过使用这些优化策略,可以显著提升ARM平台上OpenCV的性能,满足高性能计算和实时处理的需求。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了在 ARM 平台上交叉编译和移植 OpenCV 的方方面面。它提供了 10 个秘籍,涵盖从构建图像处理系统到性能优化和故障排除的各个方面。专栏深入解析了移植原理,提供了实用技巧,并分享了最佳实践,帮助读者掌握 ARM 平台上 OpenCV 移植的精髓。通过案例研究和自动化工具,专栏展示了 OpenCV 在 ARM 平台上的广泛应用和简化移植流程的方法。它还探讨了跨平台兼容性、内存优化、安全性考虑和性能基准测试,为读者提供全面的指南,让他们能够构建稳定高效的 ARM 平台图像处理系统。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
深入理解Pspice:选择与设置仿真工具的专家指南

# 摘要
本文系统地介绍了Pspice仿真工具的概述、基础理论与实践应用,以及其高级功能和集成其他工具的方法。首先,概述了Pspice的基础理论,包括电路仿真原理和仿真环境的介绍。然后,阐述了如何根据仿真需求选择合适的Pspice版本,以及进行基本设置的方法。接着,详细探讨了Pspice的高级仿真功能和在复杂电路中的应用,特别是电源转换电路和模拟滤波器设计。
VB开发者的图片插入指南

# 摘要
本论文深入探讨了使用Visual Basic (VB)进行图片处理的各个方面,包括基础概念、技术实现以及实践技巧。文章首先介绍了VB中图片处理的基础知识,然后详细阐述了图片的加载、显示、基本操作和高级处理技术。此外,论文还提供了图片处理实践中的技巧,包括文件的读取与保存、资源管理和错误处理。进阶应用部分讨论了图片处理技术在界面设计、第三方库集成以及数据可视化中
面板数据处理终极指南:Stata中FGLS估计的优化与实践

# 摘要
本文系统地介绍了面板数据处理的基础知识、固定效应与随机效应模型的选择与估计、广义最小二乘估计(FGLS)的原理与应用,以及优化策略和高级处理技巧。首先,文章提供了面板数据模型的理论基础,并详细阐述了固定效应模型与随机效应模型的理论对比及在Stata中的实现方法。接着,文章深入讲解了FGLS估计的数学原理和在Stat
响应式设计技巧深度揭秘:Renewal UI如何应对多屏幕挑战
![[Renewal UI] Chapter4_3D Inspector.pdf](https://docs.godotengine.org/en/3.0/_images/texturepath.png)
# 摘要
响应式设计是适应不同设备和屏幕尺寸的一种设计方法论,它通过灵活的布局、媒体查询和交互元素来优化用户体验。Renewal UI作为一套响应式框架,在多屏幕适配方面提供了有效实践,包括移动端和平板端的适配技巧,强调了设计与开发协作以及兼容性测试的重要性。本文深入探讨了响应式设计的理论基础、关键技术实现以及未来发展的创新趋势,特别是在人工智能、虚拟现实和增强现实中的应用前景。此外,强调
ngspice噪声分析深度剖析:原理透析与实战应用
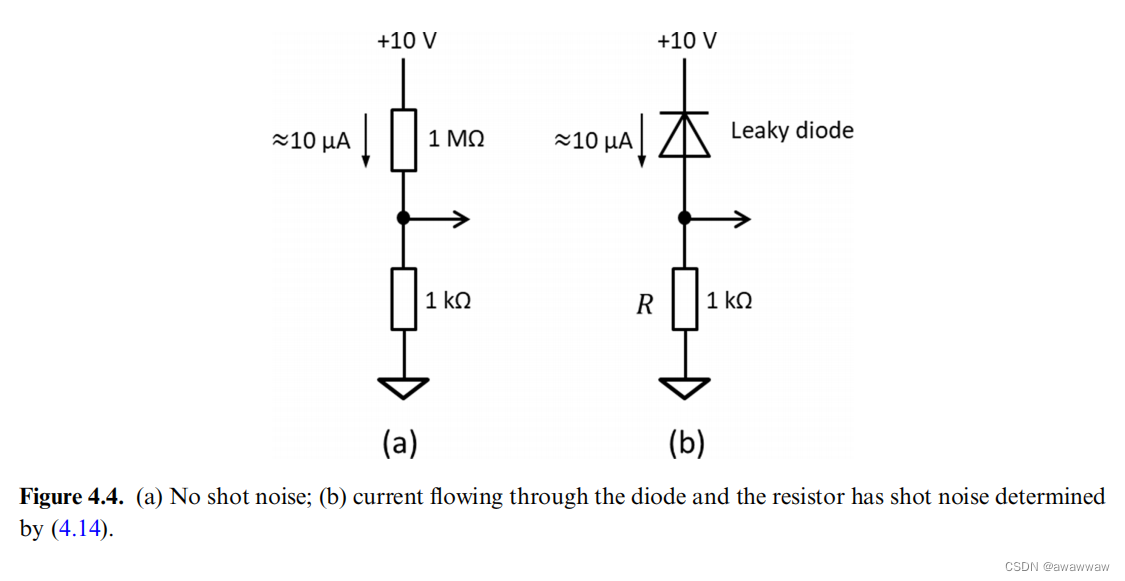
# 摘要
本文深入探讨了ngspice在噪声分析领域的应用,从基础理论到高级应用,系统地介绍了噪声分析的基本概念、数学模型及其在电路设计中的重要性。通过对ngspice仿真环境的设置与噪声分析命令的使用进行说明,本文为读者提供了噪声分析结果解读和误差分析的指导。同时,本文还探讨了噪声分析在不同电路类型中的应用,并提出了优化技巧和自动化工具使用方法。实战案例分析部分提供了射频放大器噪声优化和低
PID控制算法深度解析:从理论到实战的技巧与调优
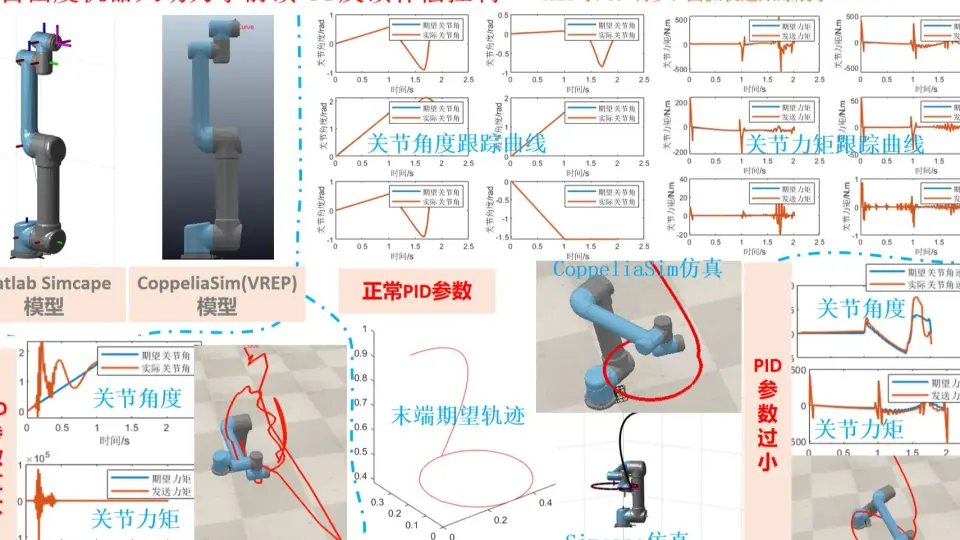
# 摘要
本文全面介绍了PID控制算法,从理论基础到实际应用,详细阐述了PID控制器的设计原理、数学模型及其参数调节方法。文中分析了模拟实现PID控制的编程技巧,实验调整PID参数的技术,以及在实际系统中应用PID控制的案例。进一步探讨了PID控制算法的调优与优化策略,包括预测控制结合PID的方法和多变量系统的优化。文章还讨论了PID控制在非线性系统、分布式网络控制和新兴领域的拓
【故障诊断】:FANUC机器人常见问题快速排查

# 摘要
FANUC机器人作为工业自动化的重要组成部分,其稳定性和可靠性对生产线效率至关重要。本文全面概述了FANUC机器人在硬件、软件、通信等方面的故障诊断技术。从硬件的传感器、电机和驱动器,到软件的系统软件和用户程序,再到通信的网络和串行通讯,每个部分的故障诊断方法和流程都得到了详细阐释。此外,本文还探讨了维护计划的制定、故障预防策略的实施,以及故障处理流程的优化。通过对故障诊断和预防性维护策
【LAMMPS结果分析】:数据处理与可视化技术,让你的模拟结果脱颖而出
![[emuch.net]lammps使用手册-中文简版(Michael博客).pdf](https://opengraph.githubassets.com/e5efe9fb3252044aa64ec90caa3617e838c8b8ed2e0cd8b8c56f8a3674658327/lammps/lammps-plugins)
# 摘要
LAMMPS(Large-scale Atomic/Molecular Massively Parallel Simulator)是进行原子、分子动力学模拟的常用软件。本文从数据分析和结果可视化的角度出发,系统介绍了LAMMPS模拟结果的处理和解释。首
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )