Access数据库表格创建与管理技巧
发布时间: 2024-03-06 00:18:03 阅读量: 52 订阅数: 23 
# 1. Access数据库基础介绍
## 1.1 数据表的概念和作用
数据表是数据库中用于存储特定类型数据的结构化对象。在Access数据库中,数据表可以看作是以行和列组成的网格,每一行代表一个记录,每一列代表一个字段。数据表的作用是存储、组织和管理数据,为用户提供方便的数据操作界面,并且支持数据的增加、删除和修改操作。
## 1.2 Access数据库的特点和优势
- **易用性高**:Access提供了直观的图形化界面,使得用户能够轻松地创建和管理数据库表格,而无需深入了解复杂的数据库原理。
- **功能丰富**:Access提供了丰富的功能模块,包括数据表设计、表单设计、报表生成等,满足了用户对于数据库管理和数据分析的多样化需求。
- **灵活性强**:Access支持创建复杂的关系型数据表,同时还提供了丰富的查询和筛选功能,能够帮助用户快速准确地获取所需数据。
- **可视化设计**:Access提供了直观的可视化设计界面,用户可以通过拖拽字段、设置属性等方式轻松完成数据表的设计和管理。
以上是关于Access数据库基础介绍的内容,接下来我们将深入探讨如何在Access中创建数据库表格。
# 2. 创建Access数据库表格
在这一章中,我们将学习如何在Access数据库中创建表格,并探讨表格设计的关键要点。
### 2.1 如何新建数据库
在Access中,可以通过以下步骤新建数据库:
```python
# Python示例代码
import win32com.client
# 创建Access应用实例
accApp = win32com.client.Dispatch('Access.Application')
# 新建数据库
dbName = 'C:/Users/User/Documents/NewDatabase.accdb'
accApp.DBEngine.CreateDatabase(dbName, win32com.client.constants.dbLangGeneral)
```
### 2.2 设计数据表的字段和属性
在创建数据表时,需要考虑字段类型、长度、约束等属性:
```java
// Java示例代码
public void createTable() {
String sql = "CREATE TABLE Employees " +
"(ID INT PRIMARY KEY NOT NULL, " +
"LastName VARCHAR(255), " +
"FirstName VARCHAR(255), " +
"City VARCHAR(255))";
}
```
### 2.3 设置主键和索引
主键和索引可以帮助提升数据库查询性能,可通过以下方式设置:
```go
// Go示例代码
package main
import (
"database/sql"
_ "github.com/mattn/go-adodb"
)
func main() {
db, err := sql.Open("adodb", "Provider=Microsoft.ACE.OLEDB.12.0;Data Source=C:/Users/User/Documents/NewDatabase.accdb;")
if err != nil {
panic(err)
}
// 设置主键
_, err = db.Exec("ALTER TABLE Employees ADD PRIMARY KEY (ID)")
// 创建索引
_, err = db.Exec("CREATE INDEX LastNameIndex ON Employees (LastName)")
}
```
通过以上方法,我们可以轻松地在Access数据库中创建表格,并设置字段属性、主键和索引,为数据存储奠定坚实的基础。
# 3. 数据录入和编辑
在Access数据库中,数据录入和编辑是非常常见且重要的操作。本章节将介绍如何进行数据录入以及编辑,包括快速录入数据、数据验证与格式化以及使用表单简化数据录入的技巧。
#### 3.1 快速录入数据
快速录入数据是提高工作效率的一种方法,尤其在大批量数据录入时尤为重要。在Access中,我们可以通过SQL语句或者使用导入功能来实现快速录入数据。下面是使用SQL语句进行快速录入数据的示例:
```sql
INSERT INTO Employees (EmployeeID, LastName, FirstName, Title)
VALUES (1, 'Smith', 'John', 'Manager'),
(2, 'Johnson', 'Jane', 'Sales Rep'),
(3, 'Williams', 'Robert', 'IT Specialist');
```
通过以上SQL语句,我们可以一次性将多条数据插入到名为"Employees"的数据表中,从而实现快速录入数据的目的。
#### 3.2 数据验证与格式化
数据验证与格式化是保证数据准确性和完整性的关键步骤。在Access中,我们可以通过设置字段的数据类型、输入掩码、验证规则等来实现数据验证与格式化。例如,我们可以设置手机号码字段的输入掩码为"(999) 999-9999",以确保录入的手机号码符合特定的格式要求。
#### 3.3 使用表单简化数据录入
表单是Access中的一个重要工具,可以帮助用户简化数据录入的过程。通过创建表单,我们可以按照自定义的布局和样式来呈现数据,并且可以通过表单的控件来进行数据录入和编辑。使用表单可以提高用户体验,减少录入错误的几率。
通过本章节的介绍,我们学习了在Access数据库中如何进行数据录入和编辑,以及如何利用快速录入、数据验证与格式化以及表单等技巧来提高工作效率和数据准确性。
# 4. 数据导入和导出
在Access数据库中,数据的导入和导出是非常常见的操作,可以方便地将数据与其他应用程序进行交互和共享。本章将介绍如何在Access数据库中进行数据导入和导出的相关技巧。
#### 4.1 从外部数据源导入数据
在Access中,可以从各种外部数据源如Excel、文本文件、其他数据库等导入数据到当前数据库的数据表中。以下是一个简单的示例,演示如何从Excel文件导入数据到Access数据库表格中。
```python
# Python示例代码 - 从Excel导入数据到Access数据库表格
import pyodbc
import pandas as pd
# 连接Access数据库
conn_str = (
r'DRIVER={Microsoft Access Driver (*.mdb, *.accdb)};'
r'DBQ=C:\path\to\your\database.accdb;'
)
conn = pyodbc.connect(conn_str)
cursor = conn.cursor()
# 从Excel文件中读取数据
excel_data = pd.read_excel('path/to/your/excel/file.xlsx')
# 将数据插入到Access数据库表格中
for index, row in excel_data.iterrows():
cursor.execute("INSERT INTO YourTableName (Column1, Column2, Column3) VALUES (?, ?, ?)", row['Column1'], row['Column2'], row['Column3'])
conn.commit()
cursor.close()
conn.close()
```
**代码总结:**
- 首先通过pyodbc库连接到Access数据库。
- 使用pandas库读取Excel文件中的数据。
- 通过游标执行INSERT语句将数据插入到Access数据库的表格中。
- 最后提交事务并关闭连接。
**结果说明:**
成功运行该代码后,您将看到Excel文件中的数据已经被导入到了Access数据库的指定表格中。
#### 4.2 将数据表格导出为其他格式
除了导入数据外,Access数据库还提供了将数据表格导出为其他格式的功能,如文本文件、Excel表格等。下面是一个示例,演示如何将Access数据库中的数据表格导出为CSV文件。
```java
// Java示例代码 - 将Access数据库表格数据导出为CSV文件
import java.io.FileWriter;
import java.io.IOException;
import java.sql.*;
public class ExportDataToCSV {
public static void main(String[] args) {
try {
Connection conn = DriverManager.getConnection("jdbc:odbc:Driver={Microsoft Access Driver (*.mdb, *.accdb)};DBQ=C:\\path\\to\\your\\database.accdb;");
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT * FROM YourTableName");
FileWriter writer = new FileWriter("path/to/your/output/file.csv");
while (rs.next()) {
writer.append(rs.getString("Column1"));
writer.append(",");
writer.append(rs.getString("Column2"));
writer.append(",");
writer.append(rs.getString("Column3"));
writer.append("\n");
}
writer.flush();
writer.close();
System.out.println("数据已成功导出到CSV文件!");
conn.close();
} catch (SQLException | IOException e) {
e.printStackTrace();
}
}
}
```
**代码总结:**
- 建立与Access数据库的连接,并执行SELECT语句获取数据。
- 将查询结果逐行写入CSV文件。
- 关闭资源,输出成功信息。
**结果说明:**
运行该Java程序后,您将在指定目录下找到生成的CSV文件,其中包含了从Access数据库表格导出的数据。
# 5. 表格关系管理
在Access数据库中,表格之间的关系管理非常重要,可以有效组织和管理数据,提高数据的完整性和准确性。本章将详细介绍如何建立不同数据表之间的关联,实现一对一、一对多、多对多关系,并讨论外键约束和参照完整性的应用。
### 5.1 建立不同数据表之间的关联
在Access中,可以通过创建关系来连接不同的数据表,共享相关信息。通过图形界面或SQL语句,可以轻松地建立表格之间的关系,以便进行查询和数据分析。
#### 示例代码(SQL语句):
```sql
CREATE TABLE Customers (
CustomerID int PRIMARY KEY,
CustomerName varchar(255)
);
CREATE TABLE Orders (
OrderID int PRIMARY KEY,
OrderDate date,
CustomerID int,
FOREIGN KEY (CustomerID) REFERENCES Customers(CustomerID)
);
```
### 5.2 一对一、一对多、多对多关系的实现
Access支持一对一、一对多和多对多等不同类型的表格关系。通过适当的设计和连接,可以实现不同表格之间的多种关系,满足实际业务需求。
#### 示例代码(创建一对多关系):
```sql
CREATE TABLE Departments (
DepartmentID int PRIMARY KEY,
DepartmentName varchar(255)
);
CREATE TABLE Employees (
EmployeeID int PRIMARY KEY,
EmployeeName varchar(255),
DepartmentID int,
FOREIGN KEY (DepartmentID) REFERENCES Departments(DepartmentID)
);
```
### 5.3 外键约束和参照完整性
在建立表格关系时,外键约束和参照完整性能够确保数据的一致性和完整性,防止出现不合法的数据关联,保障数据的准确性。
#### 示例代码(定义外键约束):
```sql
CREATE TABLE Orders (
OrderID int PRIMARY KEY,
OrderDate date,
CustomerID int,
FOREIGN KEY (CustomerID) REFERENCES Customers(CustomerID) ON DELETE CASCADE
);
```
在本章中,我们学习了Access数据库中表格关系的管理方法,包括建立关联、实现不同类型的关系以及维护数据的完整性。合理地设计和管理表格关系,将极大地提升数据库的有效性和可靠性。
# 6. 表格维护和优化
在这一章中,我们将学习如何对Access数据库表格进行维护和优化,以确保数据的完整性和性能的高效运行。
#### 6.1 数据表备份与恢复
在日常工作中,数据丢失是一种不可避免的风险,因此进行定期的数据备份非常重要。在Access中,可以通过创建备份数据库的方式来实现数据的备份。同时,如果数据意外丢失或损坏,我们也需要学会如何进行数据恢复,这需要在备份数据库的基础上进行操作。
```SQL
-- 创建数据表备份
SELECT * INTO backup_table FROM original_table;
-- 恢复数据表
SELECT * INTO original_table FROM backup_table;
```
#### 6.2 性能优化和索引设计
随着数据量的增加,数据库的性能可能会受到影响,因此需要进行性能优化。在Access中,可以通过设计合适的索引来提高查询效率。索引的设计需要根据实际的查询需求和数据特点来进行,避免过多或不必要的索引,以免影响插入和更新操作的性能。
```SQL
-- 创建索引
CREATE INDEX idx_name ON table_name (column_name);
```
#### 6.3 定期表格修正和清理
定期对数据表进行修正和清理也是保持数据质量的重要方式。我们需要检查数据表中是否存在异常数据、重复数据或者无效数据,并进行相应的清理和修正操作,以确保数据的准确性和一致性。
```SQL
-- 检查并清理重复数据
DELETE FROM table_name
WHERE id NOT IN (SELECT MIN(id) FROM table_name GROUP BY column1, column2);
```
通过以上内容,我们可以更好地理解如何在Access中对数据库表格进行维护和优化的操作。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【ADXL362应用实例解析】:掌握在各种项目中的高效部署方法
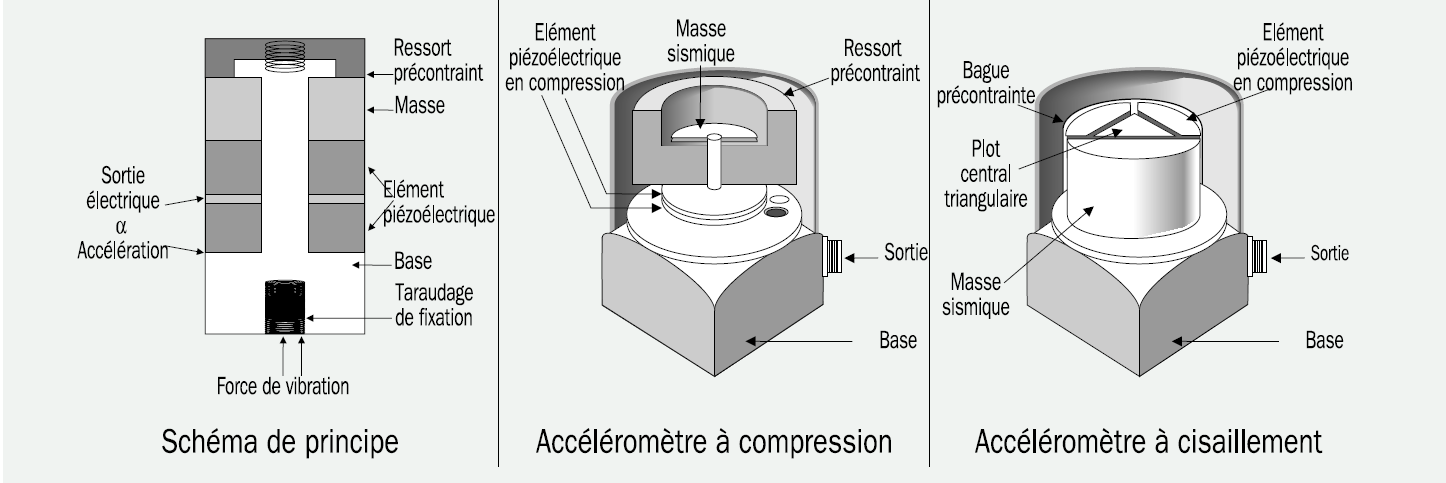
# 摘要
ADXL362是一款先进的低功耗三轴加速度计,广泛应用于多种项目中,包括穿戴设备、自动化系统和物联网设备。本文旨在详细介绍ADXL362的基本概念、硬件集成、数据采集与处理、集成应用以及软件开发和调试,并对未来的发展趋势进行展望。文章首先介绍了ADXL362的特性,并且深入探讨了其硬件集成和配置方法,如电源连接、通信接口连接和配置
【设备充电兼容性深度剖析】:能研BT-C3100如何适应各种设备(兼容性分析)

# 摘要
本文对设备充电兼容性进行了全面分析,特别是针对能研BT-C3100充电器的技术规格和实际兼容性进行了深入研究。首先概述了设备充电兼容性的基础,随后详细分析了能研BT-C3100的芯片和电路设计,充电协议兼容性以及安全保护机制。通过实际测试,本文评估了BT-C3100与多种设备的充电兼容性,包括智能手机、平板电脑、笔记本电脑及特殊设备,并对充电效率和功率管理进行了评估。此外,本文还探讨了BT-C3100的软件与固件
【SAP角色维护进阶指南】:深入权限分配与案例分析

# 摘要
本文全面阐述了SAP系统中角色维护的概念、流程、理论基础以及实践操作。首先介绍了SAP角色的基本概念和角色权限分配的理论基础,包括权限对象和字段的理解以及分配原则和方法。随后,文章详细讲解了角色创建和修改的步骤,权限集合及组合角色的创建管理。进一步,探讨了复杂场景下的权限分配策略,角色维护性能优化的方法,以及案例分析中的问题诊断和解决方案的制定
【CAPL语言深度解析】:专业开发者必备知识指南

# 摘要
本文详细介绍了一种专门用于CAN网络编程和模拟的脚本语言——CAPL(CAN Access Programming Language)。首先,文章介绍了CAPL的基
MATLAB时域分析大揭秘:波形图绘制与解读技巧
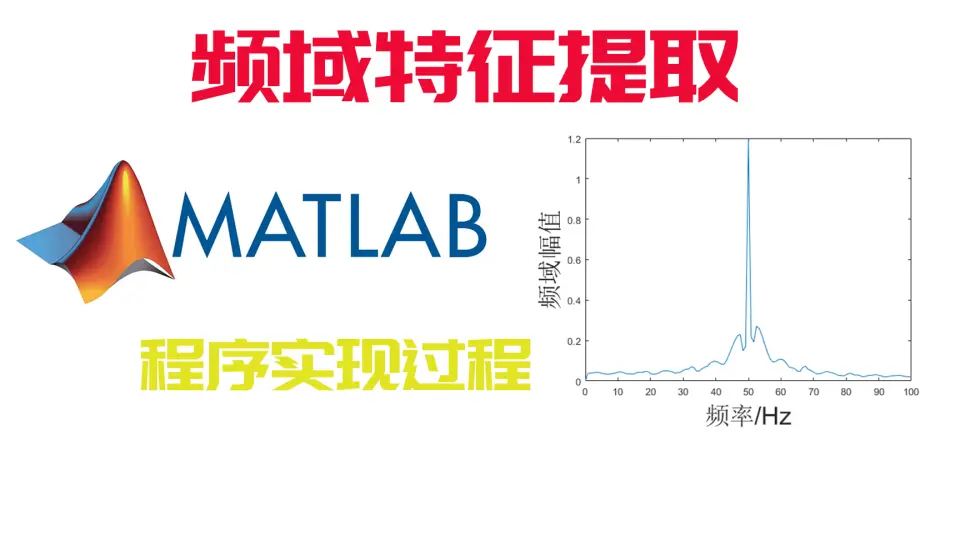
# 摘要
本文详细探讨了MATLAB在时域分析和波形图绘制中的应用,涵盖了波形图的基础理论、绘制方法、数据解读及分析、案例研究和美化导出技巧。首先介绍时域分析的基础知识及其在波形图中的作用,然后深入讲解使用MATLAB绘制波形图的技术,包括基本图形和高级特性的实现。在数据解读方面,本文阐述了波形图的时间和幅度分析、信号测量以及数学处理方法。通过案例研究部分,文章展示了如何应用波形图
汉化质量控制秘诀:OptiSystem组件库翻译后的校对与审核流程

# 摘要
随着软件国际化的需求日益增长,OptiSystem组件库汉化项目的研究显得尤为重要。本文概述了汉化项目的整体流程,包括理论基础、汉化流程优化、质量控制及审核机制。通过对汉化理论的深入分析和翻译质量评价标准的建立,本文提出了一套汉化流程的优化策略,并讨论了翻译校对的实际操作方法。此外,文章详细介绍了汉化组件库
PADS电路设计自动化进阶:logic篇中的脚本编写与信号完整性分析

# 摘要
本文综合介绍PADS电路设计自动化,从基础脚本编写到高级信号完整性分析,详细阐述了PADS Logic的设计流程、脚本编写环境搭建、基本命令以及进阶的复杂设计任务脚本化和性能优化。同时,针对信号完整性问题,本文深入讲解了影响因素、分析工具的使用以及解决策略,提供了高速接口电路设计案例和复杂电路板设计挑战的分析。此外,本文还探讨了自动化脚本与
【Java多线程编程实战】:掌握并行编程的10个秘诀
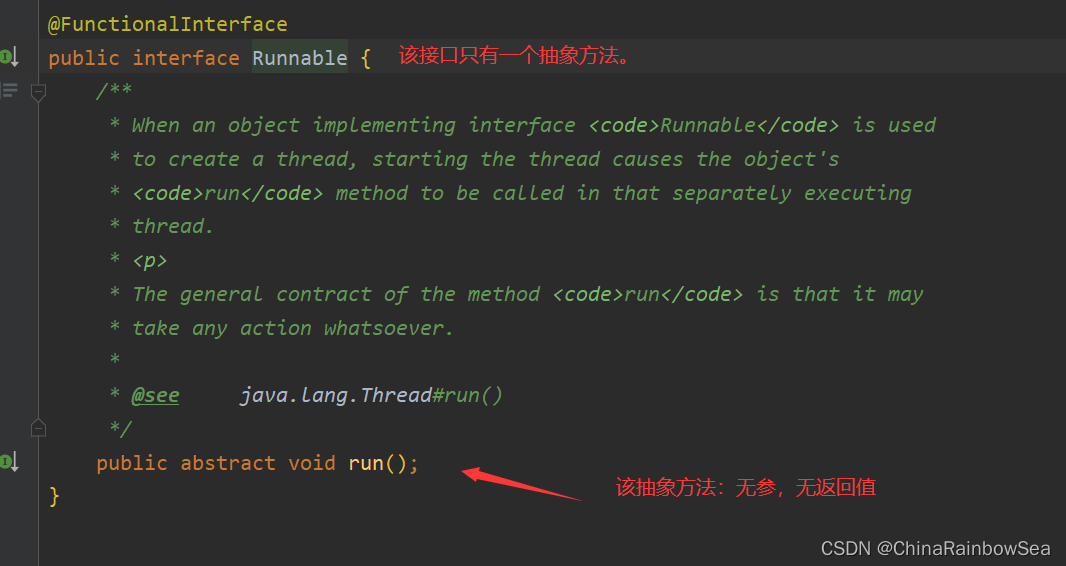
# 摘要
Java多线程编程是一种提升应用程序性能和响应能力的技术。本文首先介绍了多线程编程的基础知识,随后深入探讨了Java线程模型,包括线程的生命周期、同步机制和通信协作。接着,文章高级应用章节着重于并发工具的使用,如并发集合框架和控制组件,并分析了原子类与内存模型。进一步地,本文讨论了多线程编程模式与实践,包括设计模式的应用、常见错误分析及高性能技术。
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )