了解Tornado框架:入门指南
发布时间: 2024-01-12 09:32:55 阅读量: 62 订阅数: 45 

燃料电池汽车Cruise整车仿真模型(燃料电池电电混动整车仿真模型) 1.基于Cruise与MATLAB Simulink联合仿真完成整个模型搭建,策略为多点恒功率(多点功率跟随)式控制策略,策略模
# 1. 什么是Tornado框架
## 1.1 Tornado框架的背景和起源
Tornado框架是一个用Python语言编写的Web应用框架,由FriendFeed公司开发并于2009年开源。它最初是为了应对FriendFeed网站的高并发请求而设计的,后来逐渐成为了一个强大且受欢迎的Web开发框架。
Tornado框架的初始目标是提供一个高性能、可扩展的服务器端框架,用于处理大量的并发连接。与传统的多线程/多进程服务器模型不同,Tornado采用了异步非阻塞的I/O模型,能够处理数以万计的并发连接,非常适合构建高性能的Web应用程序和实时应用。
## 1.2 Tornado框架的特点和优势
Tornado框架具有以下几个突出的特点和优势:
- **高性能**:Tornado框架采用的单线程异步I/O模型,能够处理大量并发连接,具备很高的性能表现。它通过非阻塞的方式处理客户端请求,减少线程切换和上下文切换的开销,提高系统的吞吐量。
- **支持协程**:Tornado框架引入了协程(Coroutine)的概念,通过使用`gen.coroutine`装饰器和`yield`关键字,可以编写出非阻塞且易读的异步代码。协程与回调结合,使得异步编程更加简洁和可维护。
- **全面的功能**:Tornado框架包含了众多的功能模块,例如内置的HTTP服务器、请求处理器、模板引擎、数据库访问、用户认证、身份验证等,开发者可以基于这些模块快速构建出功能完备的Web应用。
- **可扩展性强**:Tornado框架提供了灵活且易于扩展的架构,允许开发者根据项目的需求定制和扩展各个组件。例如,可以通过实现自定义的请求处理器、中间件或路由规则来满足特定的业务需求。
- **文档丰富**:Tornado框架拥有详细和完善的官方文档,还有许多优秀的社区资源和教程可供参考。开发者可以轻松地查找到所需的文档和示例代码,快速上手并解决问题。
总结起来,Tornado框架以其高性能、协程支持、全面的功能和灵活的扩展性而备受关注和喜爱。它是构建高并发、实时Web应用的不错选择。接下来,我们将深入探讨Tornado框架的核心组件和使用方法。
# 2. Tornado框架的核心组件
Tornado框架的核心组件是构成其基础架构的重要部分。了解这些组件将帮助我们更好地理解和使用Tornado框架。
### 2.1 异步I/O和事件循环
Tornado框架使用非阻塞的异步I/O模式,它可以处理大量的并发连接而不会阻塞线程。这是Tornado的一大特点和优势,使其能够处理高并发的Web应用程序。
Tornado的异步I/O模式依靠事件循环来实现。事件循环负责监听和响应事件,包括网络I/O事件和定时事件。当事件发生时,事件循环会调用相应的回调函数来处理事件。
下面是一个简单的示例代码,演示了Tornado框架中的异步处理:
```python
import tornado.ioloop
import tornado.web
class MainHandler(tornado.web.RequestHandler):
async def get(self):
# 模拟异步操作,比如访问数据库或发送HTTP请求
result = await async_operation()
self.write("Async operation result: %s" % result)
def make_app():
return tornado.web.Application([
(r"/", MainHandler),
])
if __name__ == "__main__":
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
```
在上面的代码中,`tornado.ioloop.IOLoop.current().start()`启动了Tornado的事件循环。当有请求进来时,`MainHandler`中的`get`方法将被调用,其中的异步操作`async_operation`通过`await`关键字实现非阻塞的异步执行。
### 2.2 请求处理和路由
Tornado框架提供了强大的请求处理和路由功能。请求处理器负责处理客户端的HTTP请求,并生成相应的HTTP响应。路由规则则定义了不同URL路径与请求处理器之间的映射关系。
下面是一个简单的示例代码,演示了Tornado框架中的请求处理和路由:
```python
import tornado.ioloop
import tornado.web
class MainHandler(tornado.web.RequestHandler):
def get(self):
self.write("Hello, Tornado!")
class HelloHandler(tornado.web.RequestHandler):
def get(self, name):
self.write("Hello, %s!" % name)
def make_app():
return tornado.web.Application([
(r"/", MainHandler),
(r"/hello/(\w+)", HelloHandler),
])
if __name__ == "__main__":
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
```
在上面的代码中,`MainHandler`和`HelloHandler`分别是请求处理器。`MainHandler`处理根路径的请求,`HelloHandler`处理形如`/hello/xxx`的请求,其中`xxx`是URL中的参数。
### 2.3 模板引擎和静态文件处理
Tornado框架内置了灵活的模板引擎,可以方便地生成动态的HTML响应。模板引擎支持在模板中嵌入动态内容和逻辑,并提供了丰富的模板标签和过滤器。
另外,Tornado还提供了静态文件处理的功能,可以方便地处理和服务于静态文件,如CSS、JavaScript、图片等。
下面是一个简单的示例代码,演示了Tornado框架中模板引擎和静态文件处理的用法:
```python
import tornado.ioloop
import tornado.web
class MainHandler(tornado.web.RequestHandler):
def get(self):
self.render("index.html", title="Tornado Demo")
def make_app():
return tornado.web.Application([
(r"/", MainHandler),
(r"/static/(.*)", tornado.web.StaticFileHandler, {"path": "static"}),
])
if __name__ == "__main__":
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
```
在上面的代码中,`MainHandler`通过调用`render`方法渲染了名为`index.html`的模板,并传递了一个名为`title`的参数。另外,`(r"/static/(.*)", tornado.web.StaticFileHandler, {"path": "static"})`定义了静态文件处理的路由规则,将URL路径中的`/static/`映射到名为`static`的文件夹。
# 3. Tornado框架的安装和配置
Tornado框架的安装和配置是使用该框架的第一步,本章将介绍Tornado框架的安装和配置方法。
#### 3.1 安装Tornado框架的准备工作
在开始安装Tornado框架之前,需要确保系统已经安装了Python解释器。Tornado框架兼容Python 2.7和Python 3.3及以上版本。
#### 3.2 在Windows系统上安装Tornado框架
在Windows系统上安装Tornado框架可以通过pip包管理工具进行安装,打开命令提示符或PowerShell窗口,执行以下命令即可安装Tornado框架:
```bash
pip install tornado
```
#### 3.3 在Linux/Mac系统上安装Tornado框架
在Linux/Mac系统上同样可以使用pip进行Tornado框架的安装,打开终端窗口,输入以下命令:
```bash
pip install tornado
```
如果系统中同时安装了Python 2和Python 3,可以使用pip3命令来安装Tornado框架:
```bash
pip3 install tornado
```
#### 3.4 配置Tornado框架的常用选项
Tornado框架的配置通常可以通过定义配置文件、环境变量等方式进行。常用的配置选项包括:
- 服务器端口配置
- 日志输出格式和级别
- 调试模式设置
- 静态文件路径配置
- 数据库连接信息配置等
通过在Tornado应用程序中加载配置文件或设置环境变量,可以灵活地配置Tornado框架的各项选项,以适应不同的部署环境和需求。
本章节介绍了Tornado框架的安装方法及常用配置选项,下一章将深入讨论Tornado框架的基本用法。
以上是第三章节的内容,包括了Tornado框架的安装和配置方法,希望对你有所帮助。
# 4. Tornado框架的基本用法
在本章中,我们将学习如何使用Tornado框架来构建基本的Web应用程序。我们将了解如何创建Tornado应用程序实例,定义请求处理器和路由规则,以及如何启动和运行Tornado应用程序。
### 4.1 创建Tornado应用程序实例
首先,我们需要创建一个Tornado应用程序的实例。在Python中,可以通过创建一个继承自`tornado.web.Application`的类来实现。
下面是一个简单的例子,展示了如何创建一个Tornado应用程序的实例:
```python
import tornado.ioloop
import tornado.web
class MainHandler(tornado.web.RequestHandler):
def get(self):
self.write("Hello, Tornado!")
def make_app():
return tornado.web.Application([
(r'/', MainHandler),
])
if __name__ == "__main__":
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
```
在上面的例子中,我们创建了一个名为`MainHandler`的请求处理器类,它继承自`tornado.web.RequestHandler`。在`MainHandler`中,我们定义了一个`get`方法来处理HTTP的GET请求,并通过`self.write`方法向客户端返回了一个简单的字符串。
然后,我们通过`make_app`函数创建了一个Tornado应用程序实例,将`MainHandler`与路由规则进行关联。在本例中,我们将`MainHandler`与根路径"/"进行了关联。
最后,我们通过`app.listen(8888)`来指定应用程序要监听的端口号,并通过`tornado.ioloop.IOLoop.current().start()`启动了Tornado的I/O循环。
### 4.2 定义请求处理器和路由规则
在Tornado框架中,我们可以通过定义请求处理器和路由规则来处理不同的请求。
请求处理器是一个类,继承自`tornado.web.RequestHandler`,用于处理特定的HTTP请求方法(例如GET、POST等)和路径。
下面是一个例子,展示了如何定义一个请求处理器和路由规则:
```python
class MainHandler(tornado.web.RequestHandler):
def get(self):
self.write("Hello, Tornado!")
def post(self):
self.write("Hello, POST request!")
def make_app():
return tornado.web.Application([
(r'/', MainHandler),
])
```
在上面的例子中,我们定义了一个名为`MainHandler`的请求处理器类。在`MainHandler`中,我们定义了两个方法,分别用于处理GET请求和POST请求。
通过在`make_app`函数中将`MainHandler`与根路径"/"进行关联,我们就可以在该路径下进行GET和POST请求的处理。
### 4.3 启动和运行Tornado应用程序
当我们完成了请求处理器的定义和路由规则的设置后,就可以启动和运行Tornado应用程序了。
在之前的示例中,我们使用了以下代码来启动Tornado应用程序:
```python
if __name__ == "__main__":
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
```
在上面的代码中,我们首先使用`make_app`函数创建了一个Tornado应用程序实例,然后通过调用`app.listen`方法指定应用程序要监听的端口号。
最后,我们调用`tornado.ioloop.IOLoop.current().start()`来启动Tornado的I/O循环,使应用程序可以开始接受和处理请求。
通过运行以上代码,我们就可以在浏览器中访问"http://localhost:8888/"来查看Tornado应用程序返回的结果了。
总结:
在本章中,我们学习了如何使用Tornado框架来构建基本的Web应用程序。我们了解了如何创建Tornado应用程序实例,定义请求处理器和路由规则,以及如何启动和运行Tornado应用程序。通过掌握这些基本用法,可以帮助我们更好地理解和使用Tornado框架。
# 5. Tornado框架的高级特性
Tornado框架作为一个高性能的Web框架,在开发过程中还提供了一些高级特性,以满足更复杂的业务需求。本章节将介绍Tornado框架的几个高级特性。
#### 5.1 异步编程和协程支持
Tornado框架在处理高并发请求时,采用了异步的编程方式,通过使用协程来实现。协程是一种轻量级的线程,可以在不创建新线程的情况下实现并发执行和任务切换。
在Tornado框架中,可以使用`@gen.coroutine`装饰器来定义异步协程函数。下面是一个示例:
```python
from tornado import gen
@gen.coroutine
def async_func():
# 执行一些耗时操作,比如访问数据库、调用外部API等
yield some_asynchronous_task()
# 其他操作
@gen.coroutine
def main():
result = yield async_func()
# 处理返回结果
```
在上面的示例中,`async_func`是一个异步协程函数,使用`yield`关键字来暂停函数的执行,等待耗时操作完成后再继续执行后面的操作。
#### 5.2 数据库访问和ORM框架的集成
Tornado框架可以方便地与数据库进行交互,并支持各种常见的数据库,如MySQL、PostgreSQL、MongoDB等。同时,Tornado还提供了一些ORM(对象关系映射)框架的集成,简化数据库操作的流程。
下面是一个使用Tornado框架和SQLAlchemy ORM进行MySQL数据库操作的示例:
```python
import tornado.ioloop
import tornado.web
from tornado_sqlalchemy import SQLAlchemy
db = SQLAlchemy(url='mysql://user:password@localhost/database')
class User(db.Model):
__tablename__ = 'users'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(50))
class MainHandler(tornado.web.RequestHandler):
@tornado.gen.coroutine
def get(self):
users = yield self.db.query(User).all()
self.write(users)
def make_app():
return tornado.web.Application([
(r"/", MainHandler),
])
if __name__ == "__main__":
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
```
在上面的示例中,首先通过`SQLAlchemy`创建了一个数据库连接,并定义了一个`User`模型。然后,在`MainHandler`中使用`self.db.query(User).all()`来查询所有用户,并将结果返回给客户端。
#### 5.3 WebSocket和长连接的处理
Tornado框架也提供了对WebSocket和长连接的支持,可以用于实时通信、推送消息等场景。在Tornado中使用WebSocket需要继承`WebSocketHandler`类来处理连接和消息的交互。
下面是一个简单的WebSocket示例:
```python
import tornado.ioloop
import tornado.web
import tornado.websocket
class WebSocketHandler(tornado.websocket.WebSocketHandler):
def open(self):
print("WebSocket opened")
def on_message(self, message):
self.write_message("You said: " + message)
def on_close(self):
print("WebSocket closed")
def make_app():
return tornado.web.Application([
(r"/websocket", WebSocketHandler),
])
if __name__ == "__main__":
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
```
在上面的示例中,WebSocketHandler类继承自`tornado.websocket.WebSocketHandler`,重写了`open`、`on_message`和`on_close`方法,分别处理打开连接、接收消息和关闭连接的事件。
以上是Tornado框架的部分高级特性的介绍。在实际开发过程中,可以根据具体需求选择合适的特性来进行开发。下一章将介绍Tornado框架的部署和性能优化。
# 6. Tornado框架的部署和性能优化
在本章中,我们将探讨如何部署和优化Tornado应用程序的性能。首先,我们将介绍一些Tornado应用程序的部署选项,然后讨论如何优化其性能。最后,我们还将涉及Tornado框架的横向扩展和负载均衡。
### 6.1 Tornado应用程序的部署选项
Tornado应用程序有多种部署选项,可以根据实际需求选择适合的方式。
#### 6.1.1 单进程模式
在开发和测试阶段,可以选择在单个进程中运行Tornado应用程序。这种模式简单且方便,适用于小型应用或开发环境。
下面是一个使用单进程模式运行Tornado应用程序的示例:
```python
import tornado.ioloop
import tornado.web
class MainHandler(tornado.web.RequestHandler):
def get(self):
self.write("Hello, World!")
def make_app():
return tornado.web.Application([
(r"/", MainHandler),
])
if __name__ == "__main__":
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
```
#### 6.1.2 多进程模式
对于高并发的应用程序,可以选择使用多个进程来处理请求。多进程模式可以提高系统的并发能力,但也需要注意进程间的通信和资源共享问题。
下面是一个使用多进程模式运行Tornado应用程序的示例:
```python
import tornado.ioloop
import tornado.web
from tornado.httpserver import HTTPServer
from tornado.netutil import bind_sockets
from tornado.process import fork_processes
class MainHandler(tornado.web.RequestHandler):
def get(self):
self.write("Hello, World!")
def make_app():
return tornado.web.Application([
(r"/", MainHandler),
])
if __name__ == "__main__":
sockets = bind_sockets(8888)
fork_processes(0)
app = make_app()
server = HTTPServer(app)
server.add_sockets(sockets)
tornado.ioloop.IOLoop.current().start()
```
#### 6.1.3 使用反向代理服务器
为了提高Tornado应用程序的性能和可靠性,可以考虑使用反向代理服务器作为前端,将请求分发给多个Tornado进程或多台服务器。
常见的反向代理服务器有Nginx、Apache等。下面是一个使用Nginx作为反向代理服务器的示例配置:
```
http {
upstream tornado {
server 127.0.0.1:8888;
server 127.0.0.1:8889;
}
server {
listen 80;
server_name example.com;
location / {
proxy_pass http://tornado;
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
}
}
}
```
### 6.2 优化Tornado应用程序的性能
在部署Tornado应用程序之前,还可以优化其性能以提高响应速度和吞吐量。下面是一些常用的性能优化策略。
#### 6.2.1 使用异步非阻塞的数据库访问
Tornado支持异步非阻塞的数据库访问,可以使用`tornado.gen`模块和相应的数据库驱动来实现。
下面是一个使用异步非阻塞的MySQL数据库访问的示例:
```python
import tornado.ioloop
import tornado.web
from tornado.concurrent import Future
from tornado import gen
import aiomysql
async def get_user():
pool = await aiomysql.create_pool(host='localhost', port=3306, user='root', password='password', db='test')
async with pool.acquire() as conn:
async with conn.cursor() as cursor:
await cursor.execute("SELECT * FROM users")
result = await cursor.fetchall()
return result
class MainHandler(tornado.web.RequestHandler):
async def get(self):
users = await get_user()
self.write(users)
def make_app():
return tornado.web.Application([
(r"/", MainHandler),
])
if __name__ == "__main__":
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
```
#### 6.2.2 启用缓存
可以使用Tornado的`@tornado.web.cache_page`装饰器来开启缓存,并设置缓存时间。这样可以减少对后端资源的访问,提高响应速度。
下面是一个使用缓存的示例:
```python
import tornado.ioloop
import tornado.web
from tornado.web import cache_page
class MainHandler(tornado.web.RequestHandler):
@cache_page(60) # 缓存60秒
def get(self):
self.write("Hello, World!")
def make_app():
return tornado.web.Application([
(r"/", MainHandler),
])
if __name__ == "__main__":
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
```
#### 6.2.3 静态文件的优化
可以使用Tornado的静态文件处理功能来优化静态文件的加载速度。可以将静态文件存放在CDN上,并设置合适的缓存时间。
下面是一个使用Tornado静态文件处理功能的示例:
```python
import tornado.ioloop
import tornado.web
class MainHandler(tornado.web.RequestHandler):
def get(self):
self.render("index.html")
def make_app():
return tornado.web.Application([
(r"/", MainHandler),
], static_path="/static")
if __name__ == "__main__":
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
```
### 6.3 Tornado框架的横向扩展和负载均衡
当单个Tornado实例无法处理大量并发请求时,可以考虑对Tornado应用程序进行横向扩展和负载均衡。
横向扩展可以通过启动多个Tornado进程或部署多个Tornado服务器来实现。可以使用反向代理服务器将请求分发给这些Tornado实例。
负载均衡可以使用硬件或软件负载均衡器来实现,例如Nginx、HAProxy等。负载均衡器可以根据请求的负载情况,将请求分发给不同的Tornado实例,以实现负载均衡。
总结:本章介绍了Tornado应用程序的部署选项,包括单进程模式、多进程模式和使用反向代理服务器。同时,还介绍了一些优化Tornado应用程序性能的策略,如使用异步非阻塞的数据库访问、启用缓存和优化静态文件的加载。最后,讨论了横向扩展和负载均衡的方法,以应对高并发的情况。通过合理的部署和优化,可以提高Tornado应用程序的性能和可靠性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《lucky带你玩转高并发tornado框架》专栏涵盖了Tornado框架的全面解析与实践技巧,通过一系列深入浅出的文章,带领读者从入门到实战,探索Tornado框架在高并发环境下的强大表现。专栏首先通过"了解Tornado框架:入门指南"为读者打下坚实基础,随后深入剖析Tornado框架的异步编程与协程原理、高效的WebSocket应用实现以及路由处理、请求参数解析等核心技术。此外,专栏还探讨了Tornado框架下的模板引擎和视图渲染、安全防护与异常处理、数据存储和数据库操作、RESTful API构建、微服务架构应用等实际项目开发技巧,同时还提供了性能优化、负载均衡、内存管理、容器化部署、大数据处理与监控日志等高级主题的详细指南。最后,通过珍珠奶茶店管理系统、在线课程学习平台、智能家居控制系统等实战案例,读者可以深入实践应用Tornado框架所学技术,全面掌握其在实际项目中的应用与优化策略。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
5G NR信号传输突破:SRS与CSI-RS差异的实战应用
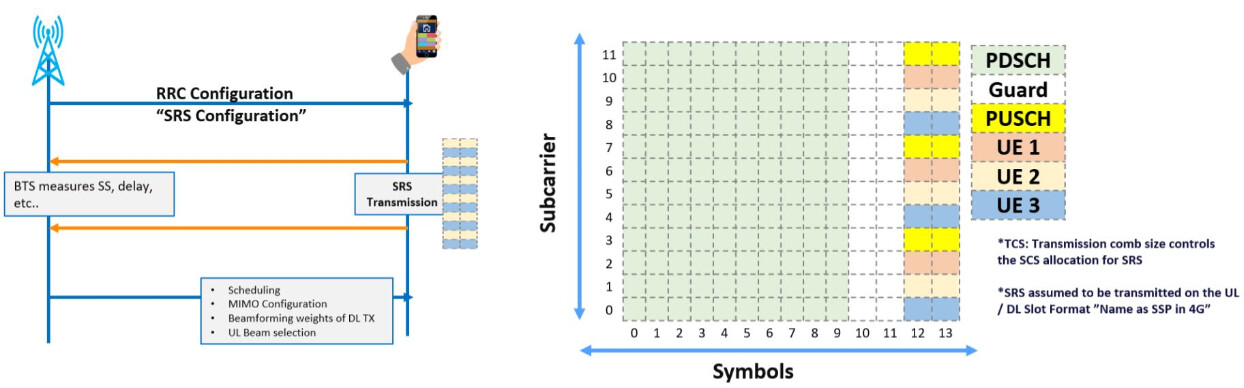
# 摘要
本文深入探讨了5G NR信号传输中SRS信号和CSI-RS信号的理论基础、实现方式以及在5G网络中的应用。首先介绍了SRS信号的定义、作用以及配置和传输方法,并探讨了其优化策略。随后,文章转向CSI-RS信号,详细阐述了其定义、作用、配置与传输,并分析了优化技术。接着,本文通过实际案例展示了SRS和CSI-RS在5G N
【性能分析】:水下机器人组装计划:性能测试与提升的实用技巧
# 摘要
水下机器人作为探索海洋环境的重要工具,其性能分析与优化是当前研究的热点。本文首先介绍了水下机器人性能分析的基础知识,随后详细探讨了性能测试的方法,包括测试环境的搭建、性能测试指标的确定、数据收集与分析技术。在组装与优化方面,文章分析了组件选择、系统集成、调试过程以及性能提升的实践技巧。案例研究部分通过具体实例,探讨了速度、能源效率和任务执行可靠性的
【性能基准测试】:ILI9881C与其他显示IC的对比分析

# 摘要
随着显示技术的迅速发展,性能基准测试已成为评估显示IC(集成电路)性能的关键工具。本文首先介绍性能基准测试的基础知识和显示IC的概念。接着,详细探讨了显示IC性能基准测试的理论基础,包括性能指标解读、测试环境与工具选择以及测试方法论。第三章专注于ILI
从零到英雄:MAX 10 LVDS IO电路设计与高速接口打造

# 摘要
本文主要探讨了MAX 10 FPGA在实现LVDS IO电路设计方面的应用和优化。首先介绍了LVDS技术的基础知识、特性及其在高速接口中的优势和应用场景。随后,文章深入解析了MAX 10器件的特性以及在设计LVDS IO电路时的前期准备、实现过程和布线策略。在高速接口设计与优化部分,本文着重阐述了信号完整性、仿真分析以及测试验证的关键步骤和问题解决方法。最
【群播技术深度解读】:工控机批量安装中的5大关键作用

# 摘要
群播技术作为高效的网络通信手段,在工控机批量安装领域具有显著的应用价值。本文旨在探讨群播技术的基础理论、在工控机批量安装中的实际应用以及优化策略。文章首先对群播技术的原理进行解析,并阐述其在工控机环境中的优势。接着,文章详细介绍了工控机批量安装前期准备、群播技术实施步骤及效果评估与优化。深入分析了多层网络架构中群播的实施细节,以及在保证安全性和可靠性的同时,群播技术与现代工控机发展
Twincat 3项目实战:跟随5个案例,构建高效的人机界面系统
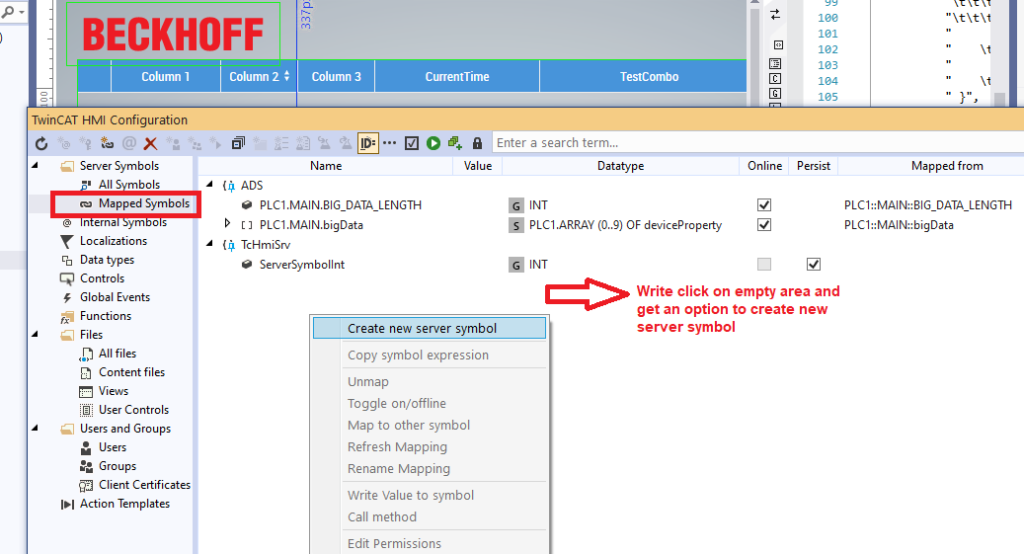
# 摘要
本论文提供了一个全面的Twincat 3项目实战概览,涵盖了从基础环境搭建到人机界面(HMI)设计,再到自动化案例实践以及性能优化与故障诊断的全过程。文章详细介绍了硬件选择、软件配置、界面设计原则、功能模块实现等关键步骤,并通过案例分析,探讨了简单与复杂自动化项目的设计与执行。最后,针对系统性能监测、优化和故障排查,提出了实用的策略和解决方案,并
【MT2492降压转换器新手必读】:快速掌握0到1的使用技巧与最佳实践

# 摘要
本文全面介绍了MT2492降压转换器的设计、理论基础、实践操作、性能优化以及最佳实践应用。首先,本文对MT2492进行了基本介绍,阐释了其工作原理和主要参数。接着,详细解析了硬件接线和软件编程的相关步骤和要点。然后,重点讨论了性能优化策略,包括热管理和故障诊断处理。最后,本文提供了MT2492在不同应用场景中的案例分析,强调了其在电
【水务行业大模型指南】:现状剖析及面临的挑战与机遇
# 摘要
本论文对水务行业的现状及其面临的数据特性挑战进行了全面分析,并探讨了大数据技术、机器学习与深度学习模型在水务行业中的应用基础与实践挑战。通过分析水质监测、水资源管理和污水处理等应用场景下的模型应用案例,本文还着重讨论了模型构建、优化算法和模型泛化能力等关键问题。最后,展望了水务行业大模型未来的技术发展趋势、政策环境机遇,以及大模型在促进可持续发展中的潜在作用。
# 关键字
水务行业;大数据技术;机器学习
SoMachine V4.1与M241的协同工作:综合应用与技巧
# 摘要
本文介绍了SoMachine V4.1的基础知识、M241控制器的集成过程、高级应用技巧、实践应用案例以及故障排除和性能调优方法。同时,探讨了未来在工业4.0和智能工厂融合背景下,SoMachine V4.1与新兴技术整合的可能性,并讨论了教育和社区资源拓展的重要性。通过对SoMachine V4.1和M241控制器的深入分析,文章旨在为工业自动化领域提供实用的实施策略和优化建议,确保系统的高效运行和可靠控
【Cadence Virtuoso热分析技巧】:散热设计与热效应管理,轻松搞定
# 摘要
随着集成电路技术的快速发展,热分析在电子设计中的重要性日益增加。本文系统地介绍了Cadence Virtuoso在热分析方面的基础理论与应用,涵盖了散热设计、热效应管理的策略与技术以及高级应用。通过对热传导、对流、辐射等基础知识的探讨,本文详细分析了散热路径优化、散热材料选择以及热仿真软件的使用等关键技术,并结合电源模块、SoC和激光二极管模块的实践案例进行了深入研究。文章还探讨了多物理场耦合分析、高效热分析流程的建立以
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )