初识GraphQL:如何在Vue应用中使用GraphQL
发布时间: 2024-01-10 15:51:00 阅读量: 161 订阅数: 46 

vue3-graphql-棒球:vue组成api + vue-apollo + graphql
# 1. GraphQL简介
## 1.1 什么是GraphQL?
GraphQL是一种由Facebook于2012年开发的用于API开发的查询语言。它提供了一种更高效、强大的方式来描述客户端-服务器之间的数据交互。与传统的RESTful API相比,GraphQL允许客户端精确地指定其需要的数据结构,避免了多次请求和响应过大的问题。
## 1.2 GraphQL与RESTful API的对比
在RESTful API中,每个端点通常具有固定的数据结构,客户端只能获取该端点所提供的数据,如果需要其他数据,则需要发起新的请求。而GraphQL允许客户端通过单个请求指定所需的数据,从而减少了不必要的数据传输和提高了请求效率。
## 1.3 为什么选择GraphQL?
GraphQL具有以下优点:
- 灵活性:客户端可以精确指定需要的数据,避免了过多或过少的数据传输。
- 性能优化:可以减少请求次数,减小数据传输的大小,提高网络传输效率。
- 可扩展性:新增数据字段不影响现有客户端,客户端也不必担心后端接口的版本兼容性问题。
通过对GraphQL的简介,我们可以初步了解其与传统RESTful API的不同之处,接下来我们将进一步学习如何在Vue应用中集成GraphQL。
# 2. 在Vue应用中集成GraphQL
在这一章中,我们将介绍如何在Vue应用中集成GraphQL。首先,我们将了解一下Vue.js的基本知识,并学习如何安装GraphQL库。然后,我们将配置Vue项目以便使用GraphQL。
### 2.1 了解Vue.js
Vue.js是一款流行的JavaScript框架,用于构建用户界面。它被设计成易于学习和使用,同时也具备高度的可扩展性和灵活性。如果你对Vue.js还不太熟悉,可以先阅读Vue.js的官方文档,以便更好地理解后续的内容。
### 2.2 安装GraphQL库
要在Vue应用中使用GraphQL,我们首先需要安装GraphQL库。可以通过npm或yarn来安装,具体方式如下:
```bash
# 使用npm安装
npm install graphql
# 使用yarn安装
yarn add graphql
```
安装完成后,我们就可以在Vue项目中引入并使用GraphQL了。
### 2.3 设置Vue项目以便使用GraphQL
在Vue项目中使用GraphQL需要进行一些配置。首先,我们需要在Vue应用的入口文件(通常是`main.js`)中引入所需的GraphQL库:
```javascript
import { createApp } from 'vue'
import { default as ApolloClient, createHttpLink } from 'apollo-client'
import { default as VueApollo, ApolloProvider } from '@vue/apollo-client'
const apolloClient = new ApolloClient({
link: createHttpLink({ uri: 'http://localhost:4000/graphql' }),
cache: new InMemoryCache()
})
const app = createApp(App)
app.use(VueApollo)
app.provide('apolloClient', apolloClient)
app.provide('gql', gql)
app.mount('#app')
```
上述代码中创建了一个ApolloClient实例,配置了GraphQL的HTTP链接。其中,`uri`指定了GraphQL服务器的地址。当然,你需要根据实际情况进行修改。
接下来,我们使用VueApollo库将ApolloClient集成到Vue应用中。在Vue实例创建之前,使用`app.use(VueApollo)`注册VueApollo插件,并使用`app.provide()`方法将`apolloClient`和`gql`(GraphQL标签函数)提供给所有子组件使用。
现在,我们已经完成了在Vue应用中集成GraphQL的配置。
在下一章中,我们将学习GraphQL的基础知识,以便在Vue组件中使用GraphQL进行数据查询和变更。
# 3. GraphQL基础知识
GraphQL是一种用于API的查询语言,它提供了一种灵活、强大且直观的方法来获取和修改数据。在本章中,我们将介绍GraphQL的基础知识,包括查询、变异和片段的基本语法。
#### 3.1 GraphQL查询(Query)的基本语法
GraphQL查询是用来获取数据的。它的语法类似于JSON对象,你可以指定你想要从API获取的数据的结构。下面是一个简单的GraphQL查询示例:
```graphql
query {
user(id: "123") {
name
email
posts {
title
content
}
}
}
```
在这个查询中,我们请求获取一个用户的姓名、邮箱和他们的帖子标题及内容。这个查询将返回一个包含以上指定字段的JSON结构。
#### 3.2 GraphQL变异(Mutation)的基本语法
GraphQL变异用于修改数据。它类似于查询,但是用于向后端服务发送修改请求。下面是一个简单的GraphQL变异示例:
```graphql
mutation {
createUser(name: "Alice", email: "alice@example.com") {
id
name
email
}
}
```
在这个变异中,我们发送了一个创建用户的请求,将会返回一个包含新创建用户的ID、姓名和邮箱的JSON结构。
#### 3.3 GraphQL片段(Fragment)的用法
GraphQL片段可以让你定义可重用的字段集合,这样你可以在多个查询中引用它们。下面是一个简单的GraphQL片段示例:
```graphql
fragment userInfo on User {
id
name
email
}
query {
user(id: "123") {
...userInfo
posts {
title
content
}
}
}
```
在这个示例中,我们定义了一个名为userInfo的片段,包含了用户的ID、姓名和邮箱。然后我们在查询中使用了这个片段来获取用户信息和帖子内容。
以上是GraphQL的一些基础知识,接下来我们将会在第四章中展示如何在Vue组件中使用GraphQL来查询和修改数据。
# 4. 在Vue组件中使用GraphQL
在这一章节中,我们将学习如何在Vue组件中使用GraphQL来查询和修改数据。我们将创建一个简单的Vue组件,并演示如何使用GraphQL查询数据以及使用GraphQL变异来修改数据。
#### 4.1 创建一个简单的Vue组件
首先,让我们创建一个简单的Vue组件,假设我们需要显示一个用户列表,并且允许用户点击按钮来添加新用户。我们将使用GraphQL来查询用户列表并添加新用户。
```javascript
<template>
<div>
<h2>用户列表</h2>
<ul>
<li v-for="user in users" :key="user.id">{{ user.name }}</li>
</ul>
<button @click="addUser">添加用户</button>
</div>
</template>
<script>
export default {
data() {
return {
users: []
};
},
methods: {
addUser() {
// 在这里发起GraphQL变异来添加新用户
}
},
// 在这里使用GraphQL查询来获取用户列表并将数据存储在this.users中
};
</script>
```
#### 4.2 使用GraphQL查询数据
在上面的代码中,我们可以使用一个GraphQL查询来获取用户列表并将数据存储在`this.users`中。我们可以通过Vue的生命周期钩子来执行这个查询,比如`created`钩子。
```javascript
<script>
import { gql } from 'graphql-tag';
export default {
// ... 其他代码 ...
created() {
this.$apollo.query({
query: gql`
query {
users {
id
name
}
}
`,
}).then(res => {
this.users = res.data.users;
}).catch(err => {
console.error('GraphQL查询错误', err);
});
}
// ... 其他代码 ...
};
</script>
```
#### 4.3 使用GraphQL变异修改数据
在`addUser`方法中,我们可以使用GraphQL变异来添加新用户。
```javascript
<script>
import { gql } from 'graphql-tag';
export default {
// ... 其他代码 ...
methods: {
addUser() {
this.$apollo.mutate({
mutation: gql`
mutation($name: String!) {
addUser(name: $name) {
id
name
}
}
`,
variables: {
name: 'New User'
}
}).then(res => {
this.users.push(res.data.addUser);
}).catch(err => {
console.error('GraphQL变异错误', err);
});
}
}
// ... 其他代码 ...
};
</script>
```
通过上面的代码,我们可以在Vue组件中使用GraphQL查询数据并修改数据。这样一来,我们就能够充分利用GraphQL的能力来处理数据,而不需要过多的复杂的状态管理。
在上述代码中,我们使用了`vue-apollo`库来集成GraphQL到Vue应用中,并利用了`graphql-tag`库来处理GraphQL查询和变异的字符串模板。
# 5. 处理GraphQL的错误与性能优化
在使用GraphQL进行开发时,我们需要注意如何处理网络请求中可能出现的错误,并且合理地优化应用的性能。本章将介绍如何处理GraphQL的错误,并提供一些性能优化的方法。
### 5.1 处理GraphQL返回的错误
在使用GraphQL进行数据查询和变异操作时,我们需要考虑处理GraphQL返回的错误。GraphQL服务器会将错误信息作为响应的一部分返回给客户端,因此我们可以通过检查响应中的错误字段来处理这些错误。
在Vue应用中,我们可以使用`apollo-client`来从GraphQL服务器获取响应数据并处理错误。以下是一个示例:
```js
<template>
<div>
<button @click="fetchData">获取数据</button>
<div v-if="loading">数据加载中...</div>
<div v-else-if="error">数据加载失败:{{ error.message }}</div>
<div v-else>
<ul>
<li v-for="item in data">{{ item.name }}</li>
</ul>
</div>
</div>
</template>
<script>
import { gql } from 'apollo-boost';
import { useQuery } from '@apollo/vue-hooks';
export default {
setup() {
const { loading, error, data } = useQuery(gql`
query {
users {
name
}
}
`);
const fetchData = () => {
// 处理错误
if (error) {
console.error('数据加载失败:', error);
return;
}
// 处理数据
console.log('数据:', data);
};
return {
loading,
error,
data,
fetchData
};
}
};
</script>
```
在上述示例中,我们使用了`useQuery`钩子从GraphQL服务器获取数据,并根据`loading`和`error`状态来显示相应的信息。如果发生错误,则会将错误信息打印到控制台。
### 5.2 使用分页与缓存优化性能
GraphQL具有灵活的查询语法和强大的缓存机制,这使得我们可以通过分页和缓存来优化应用的性能。
#### 5.2.1 使用分页
在处理大量数据时,我们可以使用GraphQL的分页功能来降低数据获取的开销。通过在查询中使用`offset`和`limit`参数,我们可以只获取需要的部分数据,而不需要一次性获取所有数据。
以下是一个示例,演示如何使用分页查询来获取用户列表:
```js
<template>
<ul>
<li v-for="user in users" :key="user.id">{{ user.name }}</li>
<button @click="loadMore">加载更多</button>
</ul>
</template>
<script>
import { reactive, ref, toRefs } from 'vue';
import { gql } from 'apollo-boost';
import { useQuery } from '@apollo/vue-hooks';
export default {
setup() {
const pageInfo = ref({
offset: 0,
limit: 10
});
const { loading, error, data } = useQuery(gql`
query($offset: Int!, $limit: Int!) {
users(offset: $offset, limit: $limit) {
id
name
}
}
`, {
variables: pageInfo.value
});
const users = ref([]);
if (data && data.users) {
users.value = data.users;
}
const loadMore = () => {
// 更新分页参数
pageInfo.value.offset += pageInfo.value.limit;
// 重新获取数据
// ...
};
return {
...toRefs(reactive(pageInfo)),
loading,
error,
users,
loadMore
};
}
};
</script>
```
在上述示例中,我们使用了`offset`和`limit`参数来控制每次查询的数据量,并通过点击“加载更多”按钮来获取下一页数据。这样,即使数据非常庞大,也能够保持较好的性能。
#### 5.2.2 使用缓存
GraphQL具有默认的请求和响应缓存机制,可以显著提高应用的性能和响应速度。使用缓存可以避免相同的数据重复请求,而是从缓存中直接获取。
在`apollo-client`中,默认情况下会启用缓存。如果我们需要自定义缓存策略或手动管理缓存,可以使用`apollo-cache`相关的库,例如`apollo-cache-inmemory`或`apollo-cache-persist`。
### 5.3 GraphQL的最佳实践
在使用GraphQL进行开发时,我们还应该遵循一些最佳实践,以提高开发效率和减少潜在的问题。
- 设计良好的数据模式:良好的数据模式可以使查询更加简洁和高效。合理命名和组织GraphQL模式中的类型和字段,并使用GraphQL内置的特性,如接口(Interface)和联合类型(Union)。
- 使用适当的指令:GraphQL的指令可以用于控制查询和变异操作的行为。使用`@include`和`@skip`指令可以根据条件进行字段的选择。
- 合理使用片段:GraphQL的片段允许我们组合和重用查询中的字段,以减少冗余和提高可维护性。使用片段可以使查询更加模块化和可组合。
- 对安全性进行考虑:GraphQL的强大查询能力也可能带来安全隐患。我们应该考虑实施身份验证(Authentication)和授权(Authorization)机制,以确保只有经过授权的用户才能访问相关数据。
通过遵循这些最佳实践,我们可以更好地利用GraphQL的优势,并构建出高质量的应用程序。
在本章中,我们学习了如何处理GraphQL返回的错误,并介绍了一些性能优化的方法,包括使用分页和缓存。此外,我们还提供了一些GraphQL的最佳实践,以便在开发过程中能够更加高效和安全地使用GraphQL。
# 6. 实战应用:构建一个使用GraphQL的Vue应用
在本章中,我们将实际动手构建一个使用GraphQL的Vue应用。我们将按照以下步骤进行:
### 6.1 设计应用需求
在开始编码之前,我们首先需要明确我们的应用需求。这有助于我们更好地理解应用的业务逻辑和功能。
我们假设我们正在构建一个电影列表应用,该应用可以展示电影列表、电影详情以及允许用户添加和修改电影信息。
### 6.2 实现Vue组件与GraphQL的整合
在开始编写代码之前,我们需要确保我们的Vue应用已经集成了GraphQL。如果你还没有完成这一步骤,请回到第二章中的相关部分。
#### 6.2.1 创建电影列表组件
首先,我们将创建一个电影列表组件来展示电影列表。我们将使用GraphQL查询来获取电影数据并在组件中显示。
```javascript
<template>
<div>
<h1>电影列表</h1>
<ul>
<li v-for="movie in movies" :key="movie.id">{{ movie.title }}</li>
</ul>
</div>
</template>
<script>
import { gql, useQuery } from '@apollo/client';
export default {
name: 'MovieList',
setup() {
const GET_MOVIES = gql`
query {
movies {
id
title
}
}
`;
const { loading, error, data } = useQuery(GET_MOVIES);
return {
movies: data && data.movies,
};
}
}
</script>
```
在上面的代码中,我们使用了`@apollo/client`库来发起GraphQL查询,并使用`useQuery`钩子函数来执行查询。我们定义了一个名为`GET_MOVIES`的查询,该查询会从服务器获取电影列表数据。
在`setup`函数中,我们调用`useQuery(GET_MOVIES)`来执行查询,并获取返回的`loading`、`error`和`data`。我们将`data.movies`赋值给`movies`变量,并在模板中使用`v-for`指令来遍历电影列表。
#### 6.2.2 创建电影详情组件
接下来,我们将创建一个电影详情组件,该组件将显示选定电影的详细信息。
```javascript
<template>
<div v-if="movie">
<h1>{{ movie.title }}</h1>
<p>{{ movie.description }}</p>
</div>
<div v-else>
<p>请选择电影</p>
</div>
</template>
<script>
import { gql, useQuery } from '@apollo/client';
export default {
name: 'MovieDetail',
props: {
movieId: {
type: String,
required: true,
}
},
setup(props) {
const GET_MOVIE = gql`
query Movie($id: String!) {
movie(id: $id) {
title
description
}
}
`;
const { loading, error, data } = useQuery(GET_MOVIE, {
variables: { id: props.movieId },
});
return {
movie: data && data.movie,
};
}
}
</script>
```
在上面的代码中,我们定义了一个名为`MovieDetail`的组件,并使用`props`属性定义了一个名为`movieId`的传入属性,用于指定要显示的电影的ID。
在`setup`函数中,我们定义了一个名为`GET_MOVIE`的查询,并使用`useQuery`钩子函数执行查询。我们使用`variables`选项将`props.movieId`作为查询的参数传入。
在模板中,我们根据是否有选定的电影来显示不同的内容。
#### 6.2.3 创建添加电影组件
最后,我们将创建一个添加电影的组件,允许用户添加新的电影信息到列表中。
```javascript
<template>
<div>
<h1>添加电影</h1>
<form @submit.prevent="addMovie">
<label for="title">标题:</label>
<input type="text" v-model="title" required>
<label for="description">描述:</label>
<textarea v-model="description"></textarea>
<button type="submit">添加</button>
</form>
<p v-if="error">{{ error.message }}</p>
</div>
</template>
<script>
import { gql, useMutation } from '@apollo/client';
export default {
name: 'MovieForm',
setup() {
const ADD_MOVIE = gql`
mutation AddMovie($input: MovieInput!) {
addMovie(input: $input) {
id
title
description
}
}
`;
const [addMovie, { loading, error }] = useMutation(ADD_MOVIE);
const title = ref('');
const description = ref('');
const addMovie = () => {
addMovie({
variables: {
input: {
title: title.value,
description: description.value,
}
}
})
.then(() => {
// 添加成功的逻辑处理
})
.catch((error) => {
// 添加失败的逻辑处理
});
};
return {
addMovie,
title,
description,
error,
};
}
}
</script>
```
在上面的代码中,我们定义了一个名为`MovieForm`的组件,用于添加电影信息。我们使用`useMutation`钩子函数来执行添加电影的变异操作。
在`setup`函数中,我们定义了一个名为`ADD_MOVIE`的变异,并使用`useMutation`钩子函数声明了一个名为`addMovie`的函数,用于执行添加电影的操作。
在模板中,我们使用`v-model`指令将输入框的值绑定到`title`和`description`变量上,并使用`@submit`事件监听表单的提交事件。在提交时,我们调用`addMovie`函数来执行变异操作。
### 6.3 测试、部署与优化
在代码编写完成后,我们可以运行应用进行测试。可以使用Vue开发服务器或者打包构建应用,具体步骤请参考Vue官方文档。
在测试过程中,我们应该关注应用的功能是否正常以及性能是否满足预期。如果存在问题,我们可以使用Chrome开发者工具等工具进行调试和优化。
完成测试后,我们可以将应用部署到生产环境中。将应用部署到云服务器、容器或者服务器less平台等,具体部署步骤请参考相关文档。
在部署后,我们还可以继续优化应用的性能和用户体验。可以通过使用CDN加速、使用缓存、使用懒加载等技术手段来提升应用的性能。
至此,我们完成了一个使用GraphQL的Vue应用的构建过程。希望本章内容对你有所帮助!

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏将带领读者深入探讨在Vue中使用GraphQL实现聊天室的全过程。从初识GraphQL开始,介绍如何在Vue应用中使用GraphQL,逐步深入讨论Vue组件的基础概念及其在GraphQL中的应用。在此基础上,专栏将重点讲解使用Vue Router实现GraphQL在聊天室中的导航功能,以及如何利用Vuex在聊天室中管理GraphQL的状态。通过实现基本的聊天室功能,读者将了解到如何利用GraphQL查询语言在Vue中展示消息,并使用Apollo Client实现实时聊天。而后,专栏还将介绍如何利用GraphQL Subscriptions实现聊天室的实时通信功能。此外,读者还将学习到如何使用GraphQL在Vue中进行数据加载、缓存、搜索和过滤等性能优化操作,以及如何构建安全的聊天室防护策略。通过本专栏的学习,读者将全面掌握在Vue中结合GraphQL实现聊天室的全套技术方案,从而为自己的项目开发提供有力支持。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
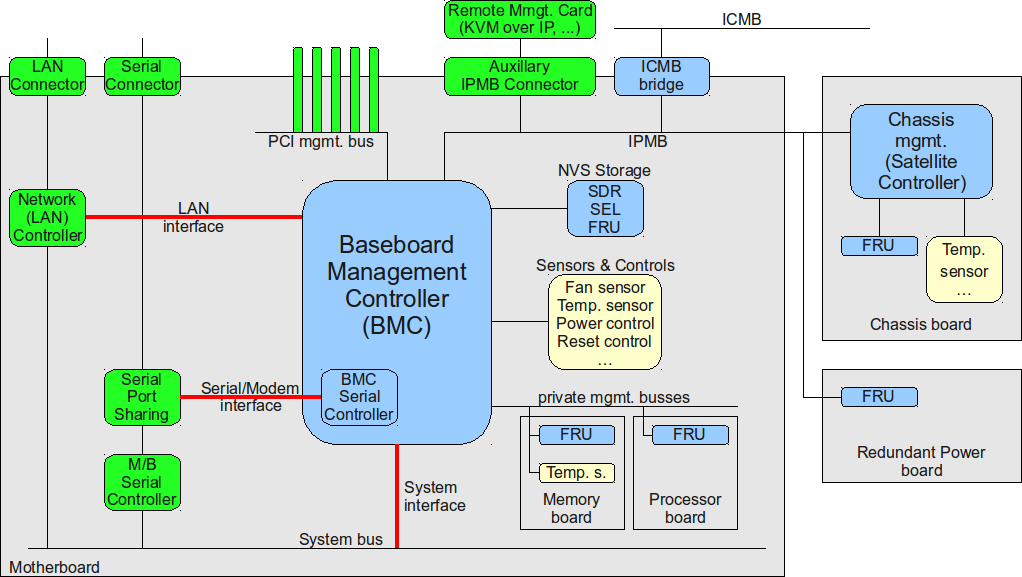
IPMI标准V2.0与物联网:实现智能设备自我诊断的五把钥匙
# 摘要
本文旨在深入探讨IPMI标准V2.0在现代智能设备中的应用及其在物联网环境下的发展。首先概述了IPMI标准V2.0的基本架构和核心理论,重点分析了其安全机制和功能扩展。随后,本文讨论了物联网设备自我诊断的必要性,并展示了IPMI标准V2.0在智能硬件设备和数据中心健康管理中的应用实例。最后,本文提出了实现智能设备IPMI监控系统的设计与开发指南,
【EDID兼容性高级攻略】:跨平台显示一致性的秘诀

# 摘要
电子显示识别数据(EDID)是数字视频接口中用于描述显示设备特性的标准数据格式。本文全面介绍了EDID的基本知识、数据结构以及兼容性问题的诊断与解决方法,重点关注了数据的深度解析、获取和解析技术。同时,本文探讨了跨平台环境下EDID兼容性管理和未来技术的发展趋势,包括增强型EDID标准的发展和自动化配置工具的前景。通过案例研究与专家建议,文章提供了在多显示器设置和企业级显示管理中遇到的ED
PyTorch张量分解技巧:深度学习模型优化的黄金法则

# 摘要
PyTorch张量分解技巧在深度学习领域具有重要意义,本论文首先概述了张量分解的概念及其在深度学习中的作用,包括模型压缩、加速、数据结构理解及特征提取。接着,本文详细介绍了张量分解的基础理论,包括其数学原理和优化目标,随后探讨了在PyTorch中的操作实践,包括张量的创建、基本运算、分解实现以及性能评估。论文进一步深入分析了张量分解在深度学习模型中的应用实例,展示如何通过张量分解技术实现模型
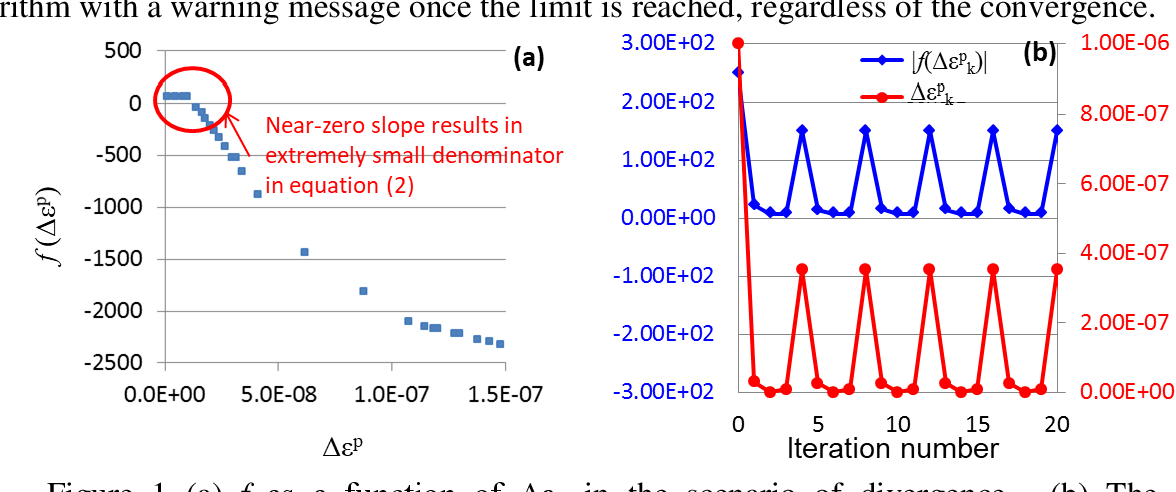
【参数校准艺术】:LS-DYNA材料模型方法与案例深度分析
# 摘要
本文全面探讨了LS-DYNA软件在材料模型参数校准方面的基础知识、理论、实践方法及高级技术。首先介绍了材料模型与参数校准的基础知识,然后深入分析了参数校准的理论框架,包括理论与实验数据的关联以及数值方法的应用。文章接着通过实验准备、模拟过程和案例应用详细阐述了参数校准的实践方法。此外,还探
系统升级后的验证:案例分析揭秘MAC地址修改后的变化

# 摘要
本文系统地探讨了MAC地址的基础知识、修改原理、以及其对网络通信和系统安全性的影响。文中详细阐述了软件和硬件修改MAC地址的方法和原理,并讨论了系统升级对MAC地址可能产生的变化,包括自动重置和保持不变的情况。通过案例分析,本文进一步展示了修改MAC地址后进行系统升级的正反两面例子。最后,文章总结了当前研究,并对今后关于MAC地址的研究方向进行了展望。
# 关键字
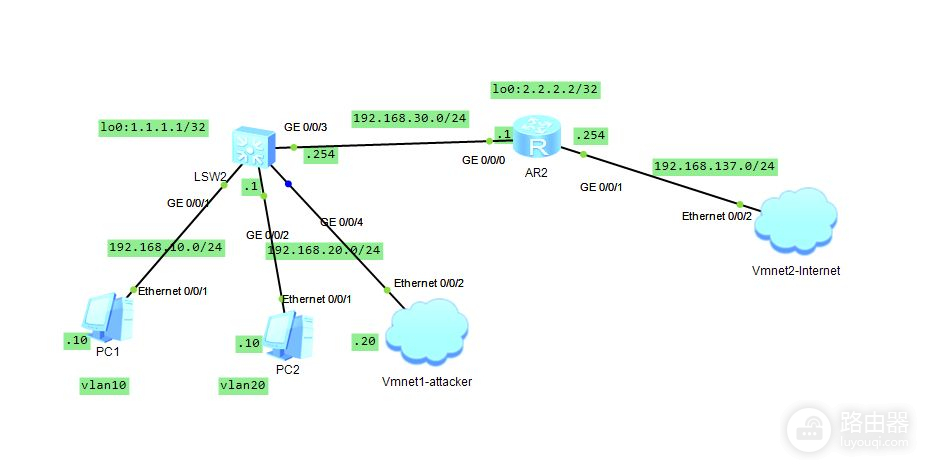
华为交换机安全加固:5步设置Telnet访问权限
# 摘要
随着网络技术的发展,华为交换机在企业网络中的应用日益广泛,同时面临的安全威胁也愈加复杂。本文首先介绍了华为交换机的基础知识及其面临的安全威胁,然后深入探讨了Telnet协议在交换机中的应用以及交换机安全设置的基础知识,包括用户认证机制和网络接口安全。接下来,文章详细说明了如何通过访问控制列表(ACL)和用户访问控制配置来实现Telnet访问权限控制,以增强交换机的安全性。最后,通过具体案例分析,本文评估了安
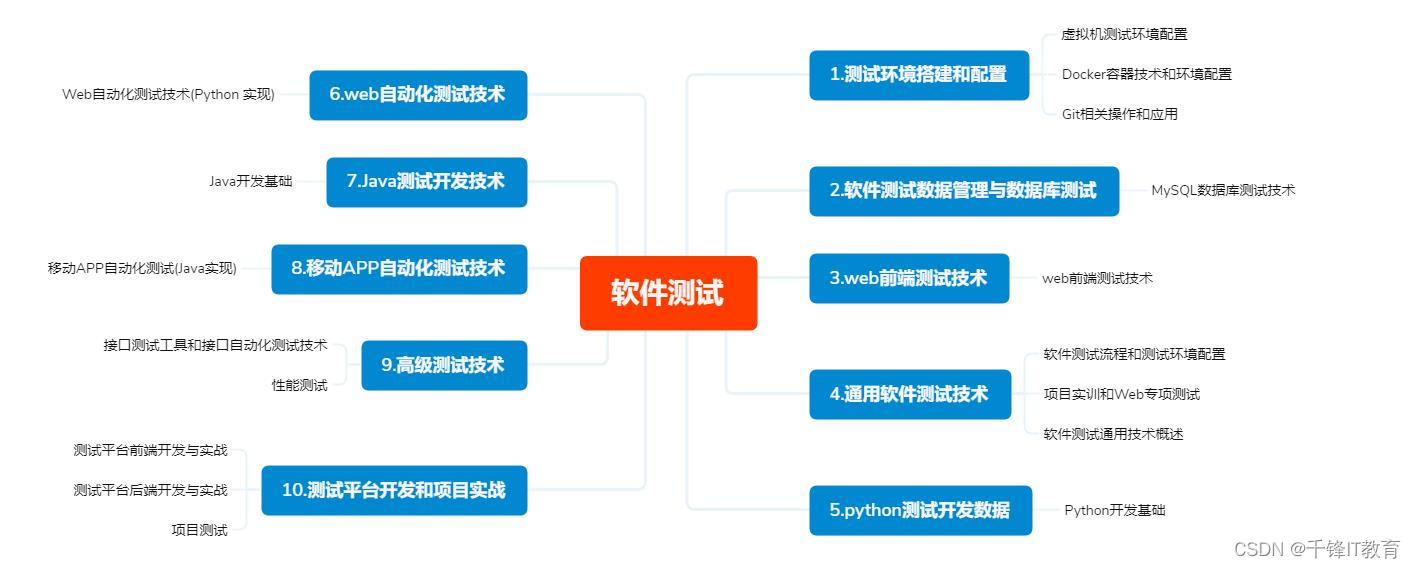
【软硬件集成测试策略】:4步骤,提前发现并解决问题
# 摘要
软硬件集成测试是确保产品质量和稳定性的重要环节,它面临诸多挑战,如不同类型和方法的选择、测试环境的搭建,以及在实践操作中对测试计划、用例设计、缺陷管理的精确执行。随着技术的进步,集成测试正朝着性能、兼容性和安全性测试的方向发展,并且不断优化测试流程和数据管理。未来趋势显示,自动化、人工智能和容器化等新兴技术的应用,将进一步提升测试效率和质量。本文系统地分析了集成测试的必要性、理论基础、实践操作
CM530变频器性能提升攻略:系统优化的5个关键技巧

# 摘要
本文综合介绍了CM530变频器在硬件与软件层面的优化技巧,并对其性能进行了评估。首先概述了CM530的基本功能与性能指标,然后深入探讨了硬件升级方案,包括关键硬件组件选择及成本效益分析,并提出了电路优化和散热管理的策略。在软件配置方面,文章讨论了软件更新流程、固件升级准备、参数调整及性能优化方法。系统维护与故障诊断部分提供了定期维护的策略和故障排除技巧。最后,通过实战案例分析,展示了CM530在特定应用中的优化效果,并对未来技术发展和创新
CMOS VLSI设计全攻略:从晶体管到集成电路的20年技术精华
# 摘要
本文对CMOS VLSI设计进行了全面概述,从晶体管级设计基础开始,详细探讨了晶体管的工作原理、电路模型以及逻辑门设计。随后,深入分析了集成电路的布局原则、互连设计及其对信号完整性的影响。文章进一步介绍了高级CMOS电路技术,包括亚阈值电路设计、动态电路时序控制以及低功耗设计技术。最后,通过VLSI设计实践和案例分析,阐述了设计流程、
三菱PLC浮点数运算秘籍:精通技巧全解

# 摘要
本文系统地介绍了三菱PLC中浮点数运算的基础知识、理论知识、实践技巧、高级应用以及未来展望。首先,文章阐述了浮点数运算的基础和理论知识,包括表示方法、运算原理及特殊情况的处理。接着,深入探讨了三菱PLC浮点数指令集、程序设计实例以及调试与优化方法。在高级应用部分,文章分析了浮点数与变址寄存器的结合、高级算法应用和工程案例。最后,展望了三菱PLC浮点数运算技术的发展趋势,以及与物联网的结合和优化
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )