【Django数据库架构深度解析】:揭秘django.db.backends.creation的强大内核
发布时间: 2024-10-17 21:12:12 阅读量: 30 订阅数: 30 

知识领域: 后端开发 技术关键词: Node.js、Django、Flask 内容关键词: RESTful API、数据库管理、

# 1. Django数据库架构概述
Django作为一个高级Web框架,其背后隐藏着复杂的数据库架构,它允许开发者高效地处理数据存储和检索的问题。本章将从高层次概述Django如何处理数据库,为后续深入了解细节打下基础。
Django默认使用SQLite作为开发环境的数据库,而在生产环境中,为了应对高并发和大数据量的情况,通常会选用如PostgreSQL或MySQL这类更为强大的数据库系统。无论选择哪种数据库,Django都通过其数据库抽象层(Database Abstraction Layer)为开发者提供统一的API接口。
数据库抽象层是Django中核心概念之一,其设计理念是使得开发者能够编写独立于具体数据库后端的代码。这一层将数据库操作封装为Python对象和函数,简化了数据库的操作,同时保持了代码的可移植性。
接下来的章节将深入探讨Django的数据库后端系统,包括数据库的创建、迁移、以及操作核心函数,让您更深入理解Django是如何让数据库操作变得简单而强大的。
# 2. 深入理解Django的数据库后端系统
Django作为一个全栈Web框架,对数据库的支持和操作是其核心能力之一。在本章中,我们将深入探讨Django的数据库后端系统,从架构的概览到数据库迁移机制,再到操作核心函数的实现,逐一剖析Django如何管理和操作数据库层的细节。
## 2.1 Django数据库后端架构概览
在介绍Django的数据库后端架构之前,先让我们了解它在整个Web应用中的位置和作用。
### 2.1.1 数据库抽象层的作用与设计
Django的数据库抽象层(Database Abstraction Layer, DBAL)是一个核心组件,它定义了Django如何与数据库交互的接口和协议。通过DBAL,Django为开发者提供了与特定数据库无关的编程接口。
#### 设计哲学
Django DBAL的设计理念是将具体的数据库细节抽象化,使得开发者可以利用统一的API进行数据库操作,而无需深入了解后端数据库的具体实现。这大大降低了数据库迁移和维护的复杂性,同时也提高了代码的可移植性。
#### 代码实现
在Django的源码中,DBAL的实现主要集中在`django/db`模块。下面的代码段展示了如何通过DBAL来获取数据库连接,并执行一个简单的查询操作:
```python
from django.db import connection
# 获取默认数据库连接
conn = connection
# 执行一个SQL查询
with conn.cursor() as cursor:
cursor.execute("SELECT * FROM my_table")
rows = cursor.fetchall()
for row in rows:
print(row)
```
通过这段代码,我们可以看到,开发者无需关心数据库的类型,只需通过Django提供的高层接口即可完成数据库操作。
### 2.1.2 数据库连接管理与池化
数据库连接的管理是保证应用性能和资源效率的关键因素。Django DBAL内部实现了连接池(Connection Pooling)机制,以提高数据库操作的效率。
#### 连接池的概念
连接池是一种技术,用于管理数据库连接的生命周期。它通过重用一组有限的数据库连接来降低数据库连接的创建和销毁开销,从而提升性能。
#### Django中的实现
在Django中,连接池的实现是通过一个连接池类来完成的,该类负责维护一定数量的数据库连接。当应用需要执行数据库操作时,会从连接池中获取一个可用连接,操作完成后将连接归还给连接池,而不是关闭它。这大大减少了频繁打开和关闭数据库连接的开销。
```python
from django.db import connection
# 获取连接池中的一个连接
with connection.cursor() as cursor:
cursor.execute("SELECT * FROM some_table")
results = cursor.fetchall()
```
通过这样的机制,Django能够在高并发的场景下,有效管理数据库连接资源,提高应用的性能。
## 2.2 Django数据库创建与迁移机制
Django的迁移系统(Migrations)是一个强大的工具,用于创建、修改和管理数据库模式(Schema)。它提供了一种方式来保持代码和数据库结构的同步。
### 2.2.1 数据库模式迁移的内部机制
Django的迁移是通过一系列迁移文件来实现的,这些文件记录了数据库模式的变化。每当你使用Django模型(Model)定义数据表结构时,通过迁移文件可以创建或修改数据库中的表结构。
#### 迁移文件的生成
Django提供了`manage.py makemigrations`命令来自动生成迁移文件。这个命令会读取你的模型定义,并将这些定义转换为数据库能够理解的SQL语句。
```shell
python manage.py makemigrations
```
这段命令会为你的应用生成一个或多个迁移文件,这些文件位于应用的`migrations`目录下。
#### 迁移文件的执行
生成迁移文件之后,你可以使用`manage.py migrate`命令来应用这些迁移,从而更新数据库结构。
```shell
python manage.py migrate
```
这个命令会检查数据库中已存在的迁移,并将新的迁移应用到数据库中。每个迁移文件都是一个Python脚本,它包含了一个函数,该函数通过Django的数据库抽象层来执行SQL命令。
### 2.2.2 自动创建和修改数据库表结构
Django的迁移系统使得自动创建和修改数据库表结构变得简单。Django模型中定义的字段类型(如`CharField`, `IntegerField`等)都会被转换为相应的数据库列类型(如`VARCHAR`, `INT`等)。
#### 自动创建
当你第一次创建一个新的Django模型并运行迁移命令时,Django会自动在数据库中创建对应的数据表。
```python
# models.py
from django.db import models
class MyModel(models.Model):
name = models.CharField(max_length=100)
description = models.TextField()
```
在上述代码中定义了一个简单的模型`MyModel`,当你运行迁移命令时,Django会生成表结构并创建数据表。
#### 自动修改
如果后续对模型进行了修改(比如添加或删除字段),Django同样可以通过迁移系统来修改现有的数据库表结构。Django会生成一个迁移文件,其中包含了修改表结构所需的SQL命令。
```python
# models.py
from django.db import models
class MyModel(models.Model):
name = models.CharField(max_length=100)
description = models.TextField()
new_field = models.BooleanField(default=False) # 添加了一个新字段
```
在上述代码中向`MyModel`模型添加了`new_field`字段。运行`makemigrations`和`migrate`命令之后,Django会自动在数据库表中添加对应的字段。
通过以上机制,Django使得数据库模式的管理变得简单和可自动化,极大地降低了数据库模式变更的复杂性。
## 2.3 Django数据库操作核心函数
Django通过其数据库抽象层提供了一系列核心函数来处理数据库操作。这些核心函数对基本的CRUD(创建、读取、更新、删除)操作进行了封装,并提供了一些高级的查询功能。
### 2.3.1 基本的CRUD操作封装
Django将CRUD操作封装为简单易用的函数和方法。以下是这些核心函数的基本使用方法:
#### 创建(Create)
创建新记录使用`save()`方法。当你创建一个模型实例,并填充数据之后,可以通过调用此方法将数据保存到数据库中。
```python
# 假设已经定义了MyModel模型
obj = MyModel(name="Example", description="An example instance.")
obj.save()
```
#### 读取(Read)
读取记录主要使用`filter()`, `get()`, 和 `exclude()`方法。这些方法返回一个查询集(QuerySet),可以进一步用来过滤、排序等。
```python
# 查询特定字段的记录
MyModel.objects.filter(name='Example')
# 获取单个对象
MyModel.objects.get(id=1)
# 排除特定记录
MyModel.objects.exclude(name='Example')
```
#### 更新(Update)
更新记录可以使用`update()`方法。这个方法可以直接在数据库层面执行更新操作,效率较高。
```python
# 更新特定对象的字段
MyModel.objects.filter(id=1).update(name='New Name')
```
#### 删除(Delete)
删除记录使用`delete()`方法。这将从数据库中删除指定的记录。
```python
# 删除特定对象
MyModel.objects.filter(id=1).delete()
```
### 2.3.2 高级查询与聚合函数实现
Django不仅提供了基本的CRUD操作封装,还实现了一系列高级查询功能,包括聚合函数(Aggregates)和注释(Annotations)。
#### 聚合函数
聚合函数是对一组值执行计算并返回单个值的函数。在Django中,这些函数可以通过`aggregate()`方法来调用。
```python
from django.db.models import Count, Max
# 计算所有记录的数量
count_result = MyModel.objects.aggregate(count=Count('id'))
# 计算name字段的最大值
max_result = MyModel.objects.aggregate(max_name=Max('name'))
```
#### 注释
注释允许你在查询集中添加额外的信息。使用`annotate()`方法可以为每个对象添加注释。
```python
from django.db.models import F
# 在查询集中为每个对象添加一个注释,显示其名称的长度
MyModel.objects.annotate(name_length=F('name').length)
```
以上就是Django数据库操作核心函数的基本介绍。在下一章节中,我们将继续深入探讨Django ORM的机制,了解如何利用这些高级特性来简化数据库操作并提高开发效率。
# 3. Django ORM机制详解
在深入了解Django的数据库后端系统之后,接下来我们将重点放在Django的ORM(对象关系映射)机制上。ORM是一种编程技术,用于将程序中的对象模型与数据库中的关系模型相互转换,无需编写复杂的SQL语句。这种技术在Python Web开发框架Django中得到了广泛的应用。
## 3.1 ORM的工作原理与设计哲学
### 3.1.1 数据映射与对象关系映射
在传统的数据库操作中,开发者需要手动编写SQL查询语句来操作数据库,这不仅增加了开发的工作量,而且提高了出错的可能性。ORM的核心是提供一种机制,将数据库中的表映射到程序中的对象,将表中的行映射为对象的实例,将表中的列映射为对象的属性。
Django ORM允许开发者通过操作Python对象来完成数据的CRUD(创建、读取、更新、删除)操作,而无需直接编写SQL语句。它通过一个叫做元数据(Meta)的内部类来定义模型,从而实现数据的映射。例如:
```python
from django.db import models
class Person(models.Model):
first_name = models.CharField(max_length=30)
last_name = models.CharField(max_length=30)
```
上述代码定义了一个Person模型,并且在Django ORM的内部处理中,这个模型会映射到一个对应的数据库表中,`first_name` 和 `last_name` 字段也会映射到表的列上。
### 3.1.2 通过ORM提高数据操作效率
使用Django ORM,开发者可以避免直接写SQL查询,而是使用Python的方式来操作数据库。这种方法不仅可以减少SQL注入的风险,还可以提高代码的可读性和可维护性。同时,Django ORM还提供了一些工具和技巧来提高数据操作的效率。
例如,使用ORM中的查询集(QuerySet)API可以减少数据库的查询次数,它采用了一种称为“惰性加载”的机制,只有在真正需要数据的时候才会执行数据库查询。这可以通过`filter()`、`exclude()`等方法来实现。
```python
Person.objects.filter(first_name="John", last_name="Lennon")
```
这行代码实际上并不会立即访问数据库,而是构建了一个查询集对象,它只在遍历或转换为列表时才会执行SQL查询。
## 3.2 Django查询集API深入剖析
### 3.2.1 查询集的构建与执行
查询集(QuerySet)是Django ORM的核心概念,它是一个可迭代的对象,用于表示数据库中的查询。在构建查询集时,可以链式调用多种方法来定制查询。
在构建查询集时,Django ORM会创建一个Q对象,用于构建复杂的查询条件。例如:
```python
from django.db.models import Q
queryset = Person.objects.filter(Q(first_name="John") | Q(last_name="Lennon"))
```
这行代码构建了一个查询集,其中包含所有名字是John或姓氏是Lennon的人。
### 3.2.2 查询优化技巧与最佳实践
在使用Django ORM进行数据查询时,合理的优化可以大幅提升应用程序的性能。查询优化主要涉及到减少数据库查询次数、减少数据传输量、利用索引等方面。
例如,使用`select_related`和`prefetch_related`可以优化外键相关的查询,避免了N+1查询问题。`select_related`用于优化多表连接查询,而`prefetch_related`用于优化多对多和一对多反向关系的查询。
```python
# 预获取相关的对象
people = Person.objects.prefetch_related('contact').all()
```
在上述代码中,`prefetch_related`会一次性获取所有的联系信息,而不是在遍历`people`时对每个`Person`对象单独查询一次联系信息。
## 3.3 Django ORM的事务与并发控制
### 3.3.1 事务的控制与隔离级别
数据库事务确保了数据的一致性和完整性。在Django中,可以使用装饰器`@transaction.atomic`来控制事务,保证代码块在执行过程中要么完全成功,要么完全回滚。
```python
from django.db import transaction
@transaction.atomic
def my_view(request):
# 此部分代码将作为一个事务执行
pass
```
在上述代码块中,如果`my_view`函数中的任何操作失败,整个事务会被回滚。
Django还提供了设置事务的隔离级别的功能。隔离级别决定了事务与其他事务的隔离程度,常见的隔离级别有读未提交、读已提交、可重复读和串行化。
```python
with transaction.atomic():
# 在这个块中的代码将作为一个事务执行
# 同时具有默认的隔离级别
pass
```
### 3.3.2 并发中的数据一致性问题
在多用户并发访问的环境下,数据的一致性很容易受到破坏。Django的ORM通过提供乐观锁和悲观锁的机制来处理并发数据一致性问题。
乐观锁机制是在对象上设置一个版本字段(通常是一个整数),在更新时检查版本号是否发生变化。例如:
```python
from django.db import models
class Entry(models.Model):
title = models.CharField(max_length=200)
body = models.TextField()
created = models.DateTimeField(auto_now_add=True)
updated = models.DateTimeField(auto_now=True)
number_of_comments = models.IntegerField(default=0)
class Meta:
get_latest_by = 'updated'
```
在上述代码中,`Entry`模型包含了一个`updated`字段,可以用来实现乐观锁。
悲观锁机制通常是通过数据库层面的锁来实现的,Django ORM提供了几种方法来使用数据库的悲观锁,如`select_for_update()`。
```python
# 使用悲观锁
with transaction.atomic():
entry = Entry.objects.select_for_update().get(pk=1)
```
这段代码会对获取的对象加上一个数据库级别的锁,防止其他事务同时修改这个对象。
通过上述章节的深入探讨,我们可以清晰地看到Django ORM提供了强大的工具来简化数据库操作。接下来,我们将进一步深入了解Django数据库后端的高级特性。
# 4. Django数据库后端高级特性
## 4.1 自定义数据库后端实现
在处理复杂的业务场景时,可能需要针对特定数据库或特定数据库特性进行优化,这时就需要自定义数据库后端。本小节将深入讨论自定义数据库后端的实现步骤和性能优化策略。
### 4.1.1 创建自定义数据库后端的步骤与要求
自定义数据库后端需要遵循Django的数据库抽象层协议。以下是创建自定义数据库后端的基本步骤:
1. **定义数据库连接**:实现`DatabaseWrapper`类,这是自定义数据库后端的核心,它需要定义如何连接到数据库,以及如何处理数据库的连接池。
2. **执行SQL语句**:重写`execute`、`insert`、`update`和`delete`方法,这些方法用于执行SQL语句。
3. **数据类型映射**:处理Python数据类型与数据库数据类型的映射,确保数据在Python和数据库间正确转换。
4. **SQL语法生成器**:提供生成SQL语法的组件,Django ORM将利用这些组件构建查询。
5. **连接池管理**:实现连接池逻辑,以优化数据库连接的使用效率。
### 4.1.2 自定义后端的性能优化
自定义数据库后端的性能优化,重点是减少数据库连接的开销以及提高查询效率。以下是一些优化策略:
- **连接池优化**:通过调整连接池的大小、连接超时时间等参数,可以提高对数据库资源的利用率。
- **查询优化**:利用预编译语句和批量操作减少SQL语句的解析时间,提高查询效率。
- **缓存使用**:通过内置缓存机制缓存常用的数据和查询结果,避免重复执行相同的查询操作。
- **异步IO操作**:对于支持异步IO的数据库,可以使用异步编程模式,提升数据库的响应速度。
下面是一个简单的示例代码,展示如何创建一个自定义数据库后端:
```python
from django.db.backends.base.base import BaseDatabaseWrapper
from django.db.backends.utils import CursorDebugWrapper
class CustomCursor(CursorDebugWrapper):
# 在这里实现自定义的游标操作
class CustomDatabaseWrapper(BaseDatabaseWrapper):
def cursor(self):
if self._cursor is None:
self._cursor = self.make_debug_cursor(CustomCursor(self))
return self._cursor
def close(self):
# 在这里实现连接关闭逻辑
pass
# 其他必要的重写方法...
```
在上述代码中,我们定义了一个自定义的数据库连接对象`CustomDatabaseWrapper`,以及一个自定义的游标`CustomCursor`。`cursor`方法是每次调用时创建新的游标对象的地方。这只是一个基础模板,根据实际需求,还需要添加很多其他的方法和逻辑来完善后端功能。
### 4.2 Django对数据库的扩展性支持
Django作为一款成熟的Web框架,提供了强大的数据库扩展性支持。本小节将探讨如何利用Django对数据库进行扩展,包括多数据库路由机制以及数据库读写分离策略。
#### 4.2.1 支持多数据库路由机制
Django允许开发者使用多个数据库,并通过数据库路由机制来控制数据的流向。一个数据库路由负责决定某个模型操作应该使用哪个数据库。
- **定义数据库路由类**:在应用的配置文件中定义一个继承自`BaseDatabaseRouter`的类,重写`db_for_read`、`db_for_write`等方法,来指定不同模型使用哪个数据库。
- **配置多数据库设置**:在`settings.py`文件中设置`DATABASES`字典,定义多个数据库配置项,然后在`DATABASE_ROUTERS`设置中指定使用的路由类。
下面是一个简单的数据库路由类的示例:
```python
from django.db import router
class CustomRouter(object):
def db_for_read(self, model, **hints):
# 根据模型决定读取的数据库
if model._meta.app_label == 'myapp':
return 'db1'
return None
def db_for_write(self, model, **hints):
# 根据模型决定写入的数据库
if model._meta.app_label == 'myapp':
return 'db2'
return None
```
在这个例子中,`db_for_read`和`db_for_write`方法决定`myapp`应用中的模型读写操作分别使用`db1`和`db2`数据库。
#### 4.2.2 数据库读写分离的策略与实现
读写分离是数据库扩展性支持的另一个重要方面,可以显著提升系统的性能和可用性。读写分离可以通过数据库中间件实现,也可以通过Django的多数据库支持来手动实现。
- **手动实现读写分离**:开发者可以利用前面提到的数据库路由机制,在路由类中根据读写操作将请求路由到不同的数据库实例。
- **中间件实现**:使用如`django-split-database`这样的中间件,可以在应用层自动处理读写请求的分发。
### 4.3 Django数据库后端的测试与诊断
随着项目的增长,数据库后端可能会遇到各种性能瓶颈和问题。有效的测试和诊断策略对于保持数据库的稳定性和性能至关重要。
#### 4.3.* 单元测试与集成测试策略
单元测试和集成测试是保证数据库操作正确性和性能的基础。
- **单元测试**:测试单个数据库操作的正确性,可以使用Django自带的测试框架来实现。
- **集成测试**:测试多个数据库操作和不同数据库间的交互,需要模拟实际应用环境下的操作。
下面是一个简单的单元测试例子:
```python
from django.test import TestCase
class MyModelTest(TestCase):
def test_model_save(self):
obj = MyModel()
obj.save()
self.assertTrue(MyModel.objects.filter(id=obj.id).exists())
```
这个测试检查`MyModel`在被保存后是否能被查询到。
#### 4.3.2 数据库性能诊断与调优
数据库性能诊断与调优是一个持续的过程,包括监控数据库性能指标、分析慢查询日志、优化索引等。
- **监控**:使用如`django-debug-toolbar`这样的工具可以实时监控数据库查询。
- **分析慢查询**:定期分析数据库的慢查询日志,找出并优化这些慢查询。
- **优化索引**:合理设计和使用数据库索引,可以极大提高查询效率。
在诊断和调优的过程中,可能需要使用到如`EXPLAIN`这样的SQL命令来分析查询的执行计划。根据分析结果,我们可以优化查询语句或调整索引策略。
## 总结
本章深入探讨了Django数据库后端的高级特性,从自定义数据库后端实现到多数据库扩展性支持,再到测试与诊断策略。通过这些高级特性,Django能够更好地应对日益增长和变化的业务需求,同时保证数据库操作的性能和稳定性。在下一章中,我们将转向实战案例分析,通过具体的场景来展示如何将本章的知识应用到实际开发中。
# 5. Django数据库实战案例分析
## 5.1 复杂业务场景下的数据库设计
### 5.1.1 多对多关系与联结表设计
在处理复杂业务逻辑时,多对多关系是常见的数据模型之一。以用户与角色的关系为例,一个用户可以拥有多个角色,而一个角色也可以被多个用户共享。在Django中,这种关系是通过内建的`ManyToManyField`实现的。
```python
class User(models.Model):
name = models.CharField(max_length=100)
roles = models.ManyToManyField('Role')
class Role(models.Model):
name = models.CharField(max_length=100)
```
在数据库层面,Django会自动创建一个名为`appname_user_roles`的联结表(junction table),其中包含两个外键字段,分别指向用户表和角色表。这种设计使得在代码层面操作多对多关系变得非常简单,例如为用户分配角色:
```python
user = User.objects.get(name='Alice')
role = Role.objects.get(name='Admin')
user.roles.add(role)
```
然而,在联结表设计时,可能需要考虑额外的字段,如开始时间、结束时间或优先级等。Django允许在`ManyToManyField`中使用`through`参数指定一个自定义的联结表模型:
```python
class UserRoles(models.Model):
user = models.ForeignKey(User, on_delete=models.CASCADE)
role = models.ForeignKey(Role, on_delete=models.CASCADE)
start_date = models.DateField()
end_date = models.DateField()
class User(models.Model):
name = models.CharField(max_length=100)
roles = models.ManyToManyField('Role', through='UserRoles')
```
### 5.1.2 高效处理大规模数据的策略
当处理大规模数据时,性能和可扩展性成为核心问题。Django提供了一些工具和最佳实践来优化数据库性能,例如:
- 索引优化:合理地为经常查询的字段添加索引。
- 查询优化:使用select_related和prefetch_related优化数据库查询。
- 分表策略:当单表数据量非常大时,可以通过分表来提高查询效率。
- 异步处理:对于写操作,可以使用消息队列异步处理。
以分表策略为例,虽然Django本身不提供分表功能,但可以手动实现,或者使用第三方库如`django-partitioning`来简化操作。分表的目的是将一张大表拆分成多个小表,每张表只存储一部分数据,从而减少单次查询的数据量。
```python
class UserPartition(models.Model):
user_id = models.IntegerField()
# 其他字段
data = models.JSONField()
for i in range(10): # 假设有10个分表
UserPartition.objects.create_table(f'partition_{i}')
```
在代码层面,开发者需要根据业务逻辑合理分配数据到不同的分表中。例如,可以根据用户ID的哈希值来决定存储到哪个分表:
```python
def get_partition(user_id):
partition_id = hash(str(user_id)) % 10 # 简单的哈希分片
return f'partition_{partition_id}'
```
## 5.2 Django与PostgreSQL的深度集成
### 5.2.1 PostgreSQL特有的数据类型与索引
PostgreSQL作为Django支持的数据库之一,具有多种特有的数据类型和索引策略,可以为特定的业务场景提供更好的支持。例如,PostgreSQL提供了`JSON`和`JSONB`数据类型,非常适合存储和查询半结构化的数据。Django ORM从1.10版本开始原生支持这些数据类型。
在Django模型中使用JSONB数据类型:
```python
class Event(models.Model):
data = models.JSONField()
```
JSONB不仅支持普通的查询,还可以利用其强大的索引能力进行高效查询。例如,可以为JSON字段创建B-tree索引或GIN索引:
```sql
CREATE INDEX idx_event_data ON event USING gin (data jsonb_path_ops);
```
### 5.2.2 使用PostgreSQL的全文搜索功能
PostgreSQL内置全文搜索功能,可以通过`tsvector`和`tsquery`类型实现全文索引,对于文本搜索非常有效。Django从1.11版本开始提供PostgreSQL全文搜索的ORM支持。
在Django模型中启用全文搜索:
```python
from django.contrib.postgres.search import SearchVectorField
class Article(models.Model):
title = models.CharField(max_length=200)
body = models.TextField()
search_vector = SearchVectorField()
```
创建全文搜索向量:
```python
Article.objects.create(
title='PostgreSQL full-text search example',
body='This is an example for full-text search using PostgreSQL.'
)
```
通过设置`SearchVector`字段,Django ORM可以利用PostgreSQL的全文搜索能力。需要注意的是,要使全文搜索有效,必须在模型中正确地创建和更新`search_vector`字段。
## 5.3 Django数据库迁移的历史与管理
### 5.3.1 数据库迁移的历史记录与回滚
Django的数据库迁移系统记录了数据库架构的所有变更历史。每个迁移都是一个记录了数据库变更的Python模块,这些迁移文件存储在`migrations`目录中。开发者可以使用Django的管理命令来查看历史记录、执行迁移或者回滚到之前的版本。
查看所有迁移历史:
```shell
python manage.py showmigrations
```
执行所有迁移:
```shell
python manage.py migrate
```
回滚到特定的迁移:
```shell
python manage.py migrate app_name name_of_migration
```
为了安全地回滚,每个迁移操作在数据库层面都是可以逆转的。这意味着每个迁移文件都应该包含向前和向后迁移的方法。开发者在设计自己的迁移时,需要确保`forwards()`方法和`backwards()`方法都可以无误地执行。
### 5.3.2 数据库迁移的最佳实践
为了管理好数据库迁移,有几个最佳实践建议遵循:
- 定期运行`makemigrations`和`migrate`命令,保持数据库架构的更新。
- 不要手动编辑数据库架构,让迁移系统来管理所有变更。
- 在进行大规模数据迁移时,先在开发环境测试迁移脚本。
- 使用版本控制系统管理迁移文件,这样可以跟踪变更,并且在出现问题时可以快速回滚。
- 为每个迁移文件编写清晰的注释,描述该迁移所做的变更。
通过遵循这些最佳实践,可以减少因迁移错误导致的生产环境故障,并确保数据库架构的稳定性。
通过本章节的介绍,读者应该能理解和掌握在Django项目中,如何针对复杂业务场景进行数据库设计,如何与PostgreSQL这样的强大数据库系统深度集成,以及如何管理数据库迁移的历史记录和回滚操作。这些实战案例分析不仅提供了具体的代码实现,还涉及到了数据迁移的最佳实践,让开发者在面对复杂的数据库操作时可以更加游刃有余。
# 6. 未来Django数据库架构的发展趋势
随着技术的不断进步,Django作为一个成熟的Web框架,其数据库架构也在不断地进化以适应新的开发需求和技术标准。本章节将探讨未来Django数据库架构可能的发展方向,以及社区如何驱动这些变化。
## 6.1 新兴数据库技术与Django的融合
Django作为一个全栈框架,一直致力于提供强大的数据库支持。随着NoSQL数据库在处理大规模数据集和提供灵活性方面的优势逐渐显现,Django也开始探索对NoSQL的支持。
### 6.1.1 对NoSQL数据库的支持与集成
Django已经可以通过其ORM进行一些NoSQL数据库的操作,例如MongoDB。不过,这些操作大多需要额外的库支持。未来的Django可能会更加集成对NoSQL的原生支持,这包括但不限于:
- 提供一套标准接口以支持不同的NoSQL数据库。
- 增加与NoSQL数据库兼容的数据序列化和反序列化功能。
- 通过迁移框架支持NoSQL数据模型的变更管理。
### 6.1.2 数据库云服务与Django的协同工作
随着云计算的兴起,数据库作为服务(DBaaS)也变得越来越流行。Django未来的发展可能会更加注重与数据库云服务的集成,包括:
- 无缝支持数据库云服务的连接、配置和优化。
- 提供工具和接口,简化数据库在云环境中的部署和管理。
- 确保Django应用能够利用云服务提供的弹性伸缩、备份和恢复等功能。
## 6.2 Django数据库抽象层的改进与优化
Django的数据库抽象层(DBAL)是其数据库架构的核心。它不仅提供了独立于具体数据库的数据操作接口,还保证了代码的可移植性。Django未来的发展可能会集中在以下方面:
### 6.2.1 对未来数据库支持的架构设计
在设计上,Django可能会:
- 进一步抽象数据库操作,使开发人员在使用不同的数据库时需要更少的改动。
- 提供更好的工具以处理不同数据库之间的兼容性问题。
### 6.2.2 性能优化与跨数据库兼容性增强
为了应对日益增长的性能需求,Django可能会:
- 优化核心查询生成器以减少数据库负载并提高效率。
- 支持更多的数据库特定优化,例如索引提示和查询计划。
- 在保持数据库抽象层的同时,允许开发者利用特定数据库的高级特性。
## 6.3 社区驱动的数据库创新与应用案例
社区是Django发展的重要驱动力。社区成员在不断地贡献代码、分享经验和提出需求。
### 6.3.1 开源社区在数据库架构创新中的角色
Django社区在推动数据库架构的创新方面可能:
- 通过社区贡献,引入新的数据库驱动和支持新的数据库特性。
- 通过讨论和协作,共同解决数据库集成和优化过程中遇到的问题。
### 6.3.2 行业案例分享:不同数据库架构的实现与效果评估
Django项目中的实际案例对其他开发者具有极大的参考价值。因此:
- 定期分享不同行业、不同规模项目中的数据库架构使用案例。
- 分析和评估各种架构实现的效果和性能,以及它们如何满足特定的业务需求。
通过社区的合作和创新,Django的数据库架构将不断发展,以适应更加多样化和复杂的业务需求。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Django 中至关重要的模块 django.db.backends.creation,提供了全面且深入的指南,涵盖了数据库性能优化、迁移策略、架构解析、连接池进阶、配置技巧、迁移故障排除、事务原理、并发控制、查询加速、数据模型序列化、安全术、备份恢复、实时监控、日志管理、缓存策略、兼容性解决方案和扩展应用等各个方面。通过掌握这些策略和技术,开发者可以大幅提升 Django 数据库的性能、可靠性和安全性,为应用程序提供坚实的基础。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
数据链路层深度剖析:帧、错误检测与校正机制,一次学懂

# 摘要
数据链路层是计算机网络架构中的关键组成部分,负责在相邻节点间可靠地传输数据。本文首先概述了数据链路层的基本概念和帧结构,包括帧的定义、类型和封装过程。随后,文章详细探讨了数据链路层的错误检测机制,包括检错原理、循环冗余检验(CRC)、奇偶校验和校验和,以及它们在错误检测中的具体应用。接着,本文介绍了数据链路层的错误校正技术,如自动重传请求(ARQ
【数据完整性管理】:重庆邮电大学实验报告中的关键约束技巧
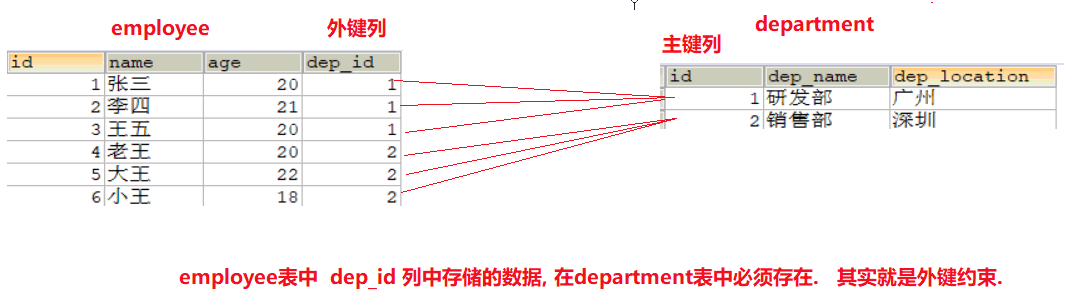
# 摘要
数据完整性是数据库管理系统中至关重要的概念,它确保数据的质量和一致性。本文首先介绍了数据完整性的概念、分类以及数据库约束的基本原理和类型。随后,文章深入探讨了数据完整性约束在实践中的具体应用,包括主键和外键约束的设置、域约束的管理和高级技巧如触发器和存储过程的运用。接着,本文分析了约束带来的性能影响,并提出了约束优化与维护的策略。最后,文章通过案例分析,对数据完整性管理进行了深度探讨,总结了实际操作中的
深入解析USB协议:VC++开发者必备的8个关键点
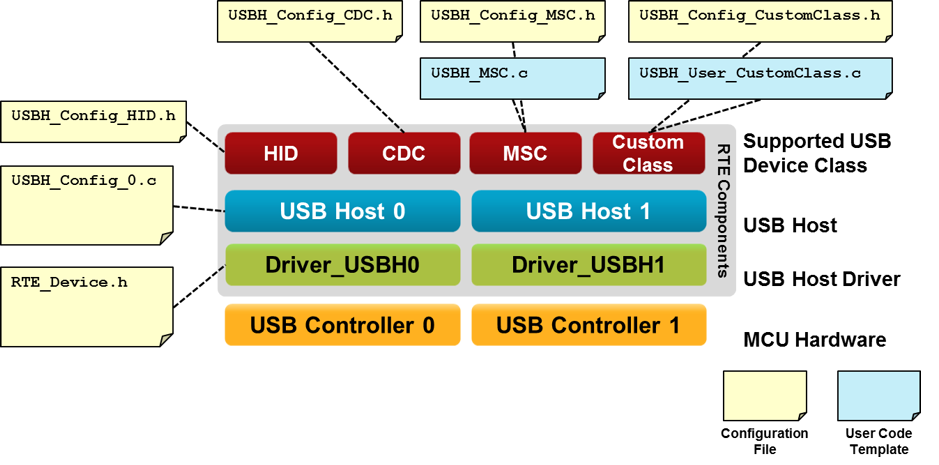
# 摘要
本文系统地介绍了USB协议的基础知识、硬件基础、数据传输机制、在VC++中的实现以及高级特性与编程技巧。首先概述USB协议的基础,然后详细探讨了USB硬件的物理接口、连接规范、电源管理和数据传输的机制。文章接着阐述了在VC++环境下USB驱动程序的开发和与USB设备通信的编程接口。此外,还涉及了USB设备的热插拔与枚举过程、性能优化,以及USB协议高级特性和编程技巧。最后,本文提供了USB设备的调试工具和方法,以
【科东纵密性能调优手册】:监控系统到极致优化的秘笈

# 摘要
性能调优是提高软件系统效率和响应速度的关键环节。本文首先介绍了性能调优的目的与意义,概述了其基本原则。随后,深入探讨了系统性能评估的方法论,包括基准测试、响应时间与吞吐量分析,以及性能监控工具的使用和系统资源的监控。在硬件优化策略方面,详细分析了CPU、内存和存储的优化方法。软件与服务优化章节涵盖了数据库、应用程序和网络性能调
【FPGA引脚规划】:ug475_7Series_Pkg_Pinout.pdf中的引脚分配最佳实践

# 摘要
本文全面探讨了FPGA引脚规划的关键理论与实践方法,旨在为工程师提供高效且可靠的引脚配置策略。首先介绍了FPGA引脚的基本物理特性及其对设计的影响,接着分析了设计时需考虑的关键因素,如信号完整性、热管理和功率分布。文章还详细解读了ug475_7S
BY8301-16P语音模块全面剖析:从硬件设计到应用场景的深度解读
# 摘要
本文详细介绍了BY8301-16P语音模块的技术细节、硬件设计、软件架构及其应用场景。首先概述了该模块的基本功能和特点,然后深入解析其硬件设计,包括主控芯片、音频处理单元、硬件接口和电路设计的优化。接着,本文探讨了软件架构、编程接口以及高级编程技术,为开发者提供了编程环境搭建和
【Ansys命令流深度剖析】:从脚本到高级应用的无缝进阶
# 摘要
本文深入探讨了Ansys命令流的基础知识、结构和语法、实践应用、高级技巧以及案例分析与拓展应用。首先,介绍了Ansys命令流的基本构成,包括命令、参数、操作符和分隔符的使用。接着,分析了命令流的参数化、数组操作、嵌套命令流和循环控制,强调了它们在提高命令流灵活性和效率方面的作用。第三章探讨了命令流在材料属性定义、网格划分和结果后处理中的应用,展示了其在提高仿真精度和效率上的实际价值。第四章介绍了命令流的高级技巧,包括宏定义、用户自定义函数、错误处理与调试以及并行处理与性能优化。最后,第五章通过案例分析和扩展应用,展示了命令流在复杂结构模拟和多物理场耦合中的强大功能,并展望了其未来趋势
【Ubuntu USB转串口驱动安装】:新手到专家的10个实用技巧

# 摘要
本文详细介绍了在Ubuntu系统下安装和使用USB转串口驱动的方法。从基础介绍到高级应用,本文系统地探讨了USB转串口设备的种类、Ubuntu系统的兼容性检查、驱动的安装步骤及其验证、故障排查、性能优化、以及在嵌入式开发和远程管理中的实际应用场景。通过本指南,用户可以掌握USB转串口驱动的安装与管理,确保与各种USB转串口设备的顺畅连接和高效使用。同时,本文还提
RH850_U2A CAN Gateway高级应用速成:多协议转换与兼容性轻松掌握

# 摘要
本文全面概述了RH850_U2A CAN Gateway的技术特点,重点分析了其多协议转换功能的基础原理及其在实际操作中的应用。通过详细介绍协议转换机制、数据封装与解析技术,文章展示了如何在不同通信协议间高效转换数据包。同时,本文还探讨了RH850_U2A CAN Gateway在实际操作过程中的设备初始化、协议转换功能实现以及兼容性测试等关键环节。此外,文章还介
【FPGA温度监测:Xilinx XADC实际应用案例】

# 摘要
本文探讨了FPGA在温度监测中的应用,特别是Xilinx XADC(Xilinx Analog-to-Digital Converter)的核心
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )