【R语言时间序列】:RColorBrewer包应用,让时间数据图表更吸引人
发布时间: 2024-11-09 01:34:03 阅读量: 37 订阅数: 28 
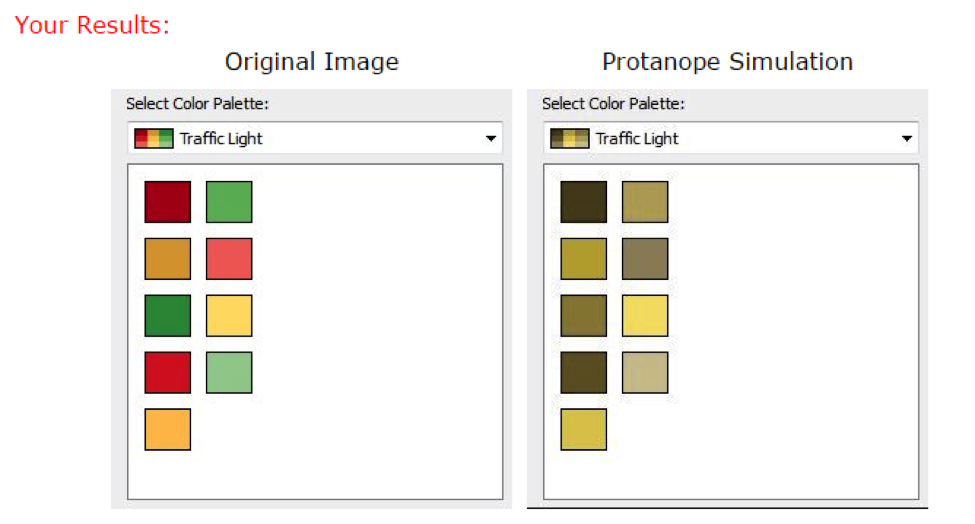
# 1. R语言时间序列分析基础
在开始我们的探索之前,我们需要对时间序列分析的基础有一个全面的了解。时间序列数据是一系列按照时间顺序排列的数据点,它们以固定的时间间隔被记录下来,用于分析和预测随时间变化的模式和趋势。在R语言中,时间序列分析不仅包括了数据的结构识别和建模,还包括对数据的前处理、预测和可视化。
我们将从时间序列数据的基础知识讲起,逐步涉及一些核心概念,比如时间序列的平稳性、季节性和周期性。理解这些概念对于深入分析时间序列至关重要,因为它们关系到如何选择合适的预测模型和处理方法。
随着时间序列分析的深入,我们将介绍一些常用的统计函数和R包,比如 `stats` 包中的 `arima` 函数,用于拟合自回归移动平均模型(ARIMA),这是时间序列预测中最常用的方法之一。此外,我们还将探索如何使用 `forecast` 包,它提供了一整套用于时间序列预测的工具,包括模型的选择、拟合和预测。
在下一章节,我们将进入RColorBrewer包的世界,它将帮助我们更好地可视化时间序列数据,使得分析结果更易于理解与交流。
# 2. RColorBrewer包的理论与应用
### 2.1 RColorBrewer包的简介
#### 2.1.1 RColorBrewer包的起源和发展
RColorBrewer包诞生于数据可视化的迫切需求,其起源可以追溯至色彩专家的理论研究与实践经验。此包旨在为R语言用户提供一系列经过精心挑选的色彩方案,以改善数据图表的视觉呈现质量。RColorBrewer包的发展,随着数据可视化重要性的日益提升而不断优化,逐步加入了更多符合色彩科学的配色方案,提供了更丰富的接口与选项,满足了各种数据类型和场景的需求。
#### 2.1.2 色彩理论在数据可视化中的重要性
色彩理论在数据可视化中的应用至关重要。色彩不仅能够影响人的心理感知,还能够提升信息的识别效率与记忆效果。恰当的色彩选择可以帮助强调数据中的关键信息,简化复杂的数据集,并为观众提供清晰、直观的视觉体验。RColorBrewer包通过提供符合色彩理论的配色方案,使得用户能够有效地应用色彩理论,从而增强数据可视化的表现力。
### 2.2 RColorBrewer包的色彩设计原则
#### 2.2.1 色彩的分类和用途
色彩在数据可视化中通常分为几类,如连续色、定性色和定量色。连续色适用于表示数据的连续变化,如温度分布图;定性色用于区分数据中的不同类别或组别,如各类商品的销售量;定量色则用于展示数据大小或比例,如人口密度分布图。RColorBrewer包支持各种类型的色彩需求,并提供了一系列相关的配色方案。
#### 2.2.2 色彩搭配原则与最佳实践
色彩搭配是一项挑战性的工作,RColorBrewer包提供了一些色彩搭配原则和最佳实践的指南。这些原则包括色彩对比度的考量、色彩饱和度的选择以及色彩和谐的把握。最佳实践方面,建议使用包中的预设方案,同时也鼓励用户根据具体数据特点和目标观众进行个性化调整。
### 2.3 RColorBrewer包在时间序列分析中的应用
#### 2.3.1 时间序列数据的特点与挑战
时间序列数据通常具有时间相关性和趋势性等特点,挑战在于如何清晰地展示数据随时间的变化趋势,同时突出关键信息。时间序列分析不仅要关注数据的准确性,还要在可视化中解决重叠和遮挡问题。RColorBrewer包通过提供有效的色彩方案,助力用户解决这些挑战。
#### 2.3.2 实例分析:使用RColorBrewer包提升图表吸引力
在具体应用中,可以利用RColorBrewer包来增加图表的视觉吸引力和信息的可读性。以下是一个简单的示例代码,展示如何在R语言中应用RColorBrewer包生成带有色块的线性图。
```r
# 安装并加载RColorBrewer包
if (!require("RColorBrewer")) install.packages("RColorBrewer")
library(RColorBrewer)
# 准备时间序列数据
time_series <- data.frame(
Date = seq.Date(as.Date("2020-01-01"), by = "month", length.out = 12),
Value = c(15, 20, 25, 30, 25, 20, 15, 20, 25, 30, 25, 20)
)
# 绘制带有色块的线性图
plot(time_series$Date, time_series$Value, type = "o", col = "black", lwd = 2,
xlab = "Date", ylab = "Value", main = "Time Series Plot with RColorBrewer")
rect(time_series$Date, par("usr")[3], time_series$Date + 1, par("usr")[4],
col = brewer.pal(n = 9, name = "Blues")[time_series$Value], border = NA)
# 添加图例
legend("topleft", legend = paste("Value", unique(time_series$Value)),
fill = brewer.pal(n = 9, name = "Blues")[unique(time_series$Value)],
border = NA)
```
本节代码通过`plot`函数绘制了一个时间序列的线性图,并通过`rect`函数添加了色块。颜色的选取是通过`brewer.pal`函数实现的,该函数来自RColorBrewer包,它能够根据数据值来选择合适的色彩。代码中特别注意了如何将时间序列数据值映射到色彩方案上,并且在绘制色块时添加了相应的边界。通过这种方式,我们可以清楚地看到数据随时间变化的趋势,并以色彩的差异突出显示了不同时间点的数据值大小。
在实际应用中,可以根据时间序列数据的特点和可视化需求,选择合适的色彩方案,以及调整色块的透明度和边界,以进一步优化图表的视觉效果。此外,该包还支持交互式图表工具,为用户提供了更多的交互性选择,使得最终图表的表现形式更加多样化和个性化。
# 3. 时间序列数据的可视化技巧
时间序列数据的可视化是数据科学中一个重要的环节,它有助于直观地展示数据随时间变化的趋势、周期性和季节性等特征。数据的可视化不仅限于绘制简单的折线图,还包括通过色彩、形状、大小等多种方式来增强图表的表达能力。
## 3.1 时间序列数据的预处理
### 3.1.1 数据清洗和格式化
在进行时间序列分析之前,首先需要对数据进行清洗和格式化。数据清洗通常包括去除异常值、填补缺失值、处理重复记录等步骤。格式化则是指将数据转换为适合进行时间序列分析的格式,比如统一日期时间格式,确保数据的连续性和周期性。
```r
# 示例代码:R语言进行数据清洗和格式化
# 假设df是我们的数据框(data frame),其中包含时间戳(Timestamp)和某个变量的值(Value)
# 转换时间戳格式
df$Timestamp <- as.POSIXct(df$Timestamp, format = "%Y-%m-%d %H:%M:%S")
# 去除异常值
df <- df[abs(df$Value - mean(df$Valu
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏提供有关 RColorBrewer 数据包的全面指南,该数据包是 R 语言中用于数据可视化配色方案的强大工具。从入门到高级技巧,本专栏涵盖了广泛的主题,包括:
* 创建专业图表配色方案
* 定制个性化配色方案
* 优化不同类型数据可视化的配色
* 避免对比度不足
* 在 RShiny 中集成配色方案
* 提升时间数据图表和地图数据可视化的吸引力
* 掌握交互式图表中的配色策略
* 提高数据可读性
通过深入的教程、实战案例和专家级技巧,本专栏旨在帮助 R 用户提升数据可视化的美感和表现力,让数据图表生动起来,并传达清晰的信息。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
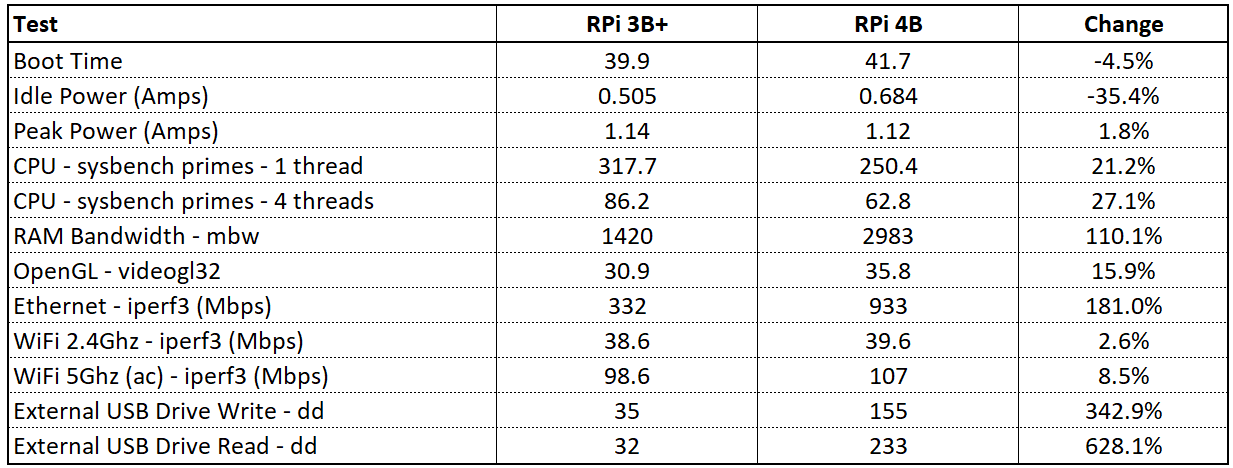
Odroid XU4与Raspberry Pi比较分析
# 摘要
本文详细比较了Odroid XU4与Raspberry Pi的硬件规格、操作系统兼容性、性能测试与应用场景分析,并进行了成本效益分析。通过对比处理器性能、内存存储能力、扩展性和连接性等多个维度,揭示了两款单板计算机的优劣。文章还探讨了它们在图形处理、视频播放、科学计算和IoT应用等方面的实际表现,并对初次购买成本与长期运营维护成本进行了
WinRAR CVE-2023-38831漏洞全生命周期管理:从漏洞到补丁

# 摘要
WinRAR CVE-2023-38831漏洞的发现引起了广泛关注,本文对这一漏洞进行了全面概述和分析。我们深入探讨了漏洞的技术细节、成因、利用途径以及受影响的系统和应用版本,评估了漏洞的潜在风险和影响等级。文章还提供了详尽的漏洞应急响应策略,包括初步的临时缓解措施、长期修复
【数据可视化个性定制】:用Origin打造属于你的独特图表风格

# 摘要
随着数据科学的发展,数据可视化已成为传达复杂信息的关键手段。本文详细介绍了Origin软件在数据可视化领域的应用,从基础图表定制到高级技巧,再到与其他工具的整合,最后探讨了最佳实践和未来趋势。通过Origin丰富的图表类型、强大的数据处理工具和定制化脚本功能,用户能够深入分析数据并创建直观的图表。此外,本文还探讨了如何利用Origin的自动化和网络功能实现高效的数据可视化协作和分享。通
【初学者到专家】:LAPD与LAPDm帧结构的学习路径与进阶策略
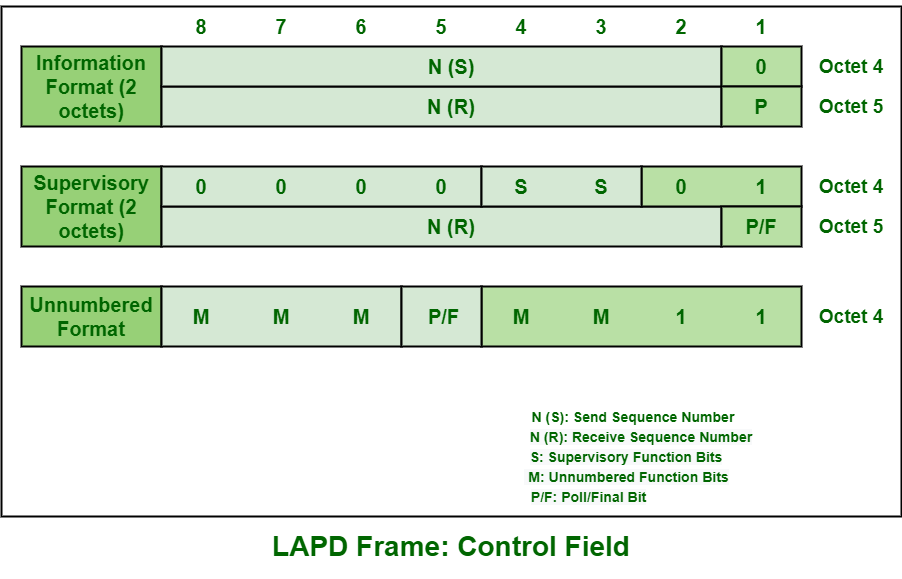
# 摘要
本文全面阐述了LAPD(Link Access Procedure on the D-channel)和LAPDm(LAPD modified)协议的帧结构及其相关理论,并深入探讨了这两种协议在现代通信网络中的应用和重要性。首先,对LAPD和LAPDm的帧结构进行概述,重点分析其组成部分与控制字段。接着,深入解析这两种协议的基础理论,包括历史发展、主要功能与特点
医学成像革新:IT技术如何重塑诊断流程

# 摘要
本文系统探讨了医学成像技术的历史演进、IT技术在其中的应用以及对诊断流程带来的革新。文章首先回顾了医学成像的历史与发展,随后深入分析了IT技术如何改进成像设备和数据管理,特别是数字化技术与PACS的应用。第三章着重讨论了IT技术如何提升诊断的精确性和效率,并阐述了远程医疗和增强现实技术在医学教育和手术规划中的应用。接着,文章探讨了数据安全与隐私保护的挑战,以及加密
TriCore工具链集成:构建跨平台应用的链接策略与兼容性解决

# 摘要
本文对TriCore工具链在跨平台应用构建中的集成进行了深入探讨。文章首先概述了跨平台开发的理论基础,包括架构差异、链接策略和兼容性问题的分析。随后,详细介绍了TriCore工具链的配置、优化以及链接策略的实践应用,并对链接过程中的兼容性
【ARM调试技巧大公开】:在ARMCompiler-506中快速定位问题

# 摘要
本文详述了ARM架构的调试基础,包括ARM Compiler-506的安装配置、程序的编译与优化、调试技术精进、异常处理与排错,以及调试案例分析与实战。文中不仅提供安装和配置ARM编译器的具体步骤,还深入探讨了代码优化、工具链使用、静态和动态调试、性能分析等技术细节。同时,本文还对ARM异常机制进行了解
【远程桌面工具稳定安全之路】:源码控制与版本管理策略
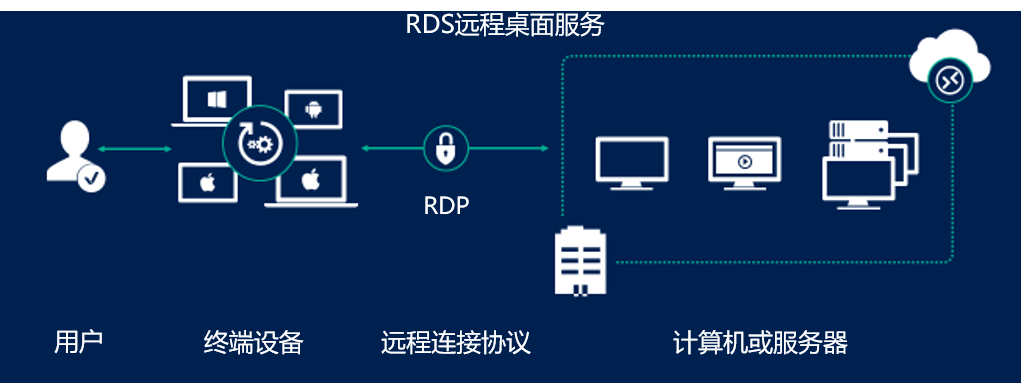
# 摘要
本文系统地介绍了远程桌面工具与源码控制系统的概念、基础和实战策略。文章首先概述了远程桌面工具的重要性,并详细介绍了源码控制系统的理论基础和工具分类,包括集中式与分布式源码控制工具以及它们的工作流程。接着,深入讨论了版本管理策略,包括版本号规范、分支模型选择和最佳实践。本文还探讨了远程桌面工具源码控制策略中的安全、权限管理、协作流程及持续集成。最后,文章展望了版本管理工具与
【网络连接优化】:用AT指令提升MC20芯片连接性能,效率翻倍(权威性、稀缺性、数字型)

# 摘要
随着物联网设备的日益普及,MC20芯片在移动网络通信中的作用愈发重要。本文首先概述了网络连接优化的重要性,接着深入探讨了AT指令与MC20芯片的通信原理,包括AT指令集的发展历史、结构和功能,以及MC20芯片的网络协议栈。基于理论分析,本文阐述了AT指令优化网络连接的理论基础,着重于网络延迟、吞吐量和连接质量的评估。实
【系统稳定性揭秘】:液态金属如何提高计算机物理稳定性
# 摘要
随着计算机硬件性能的不断提升,计算机物理稳定性面临着前所未有的挑战。本文综述了液态金属在增强计算机稳定性方面的潜力和应用。首先,文章介绍了液态金属的理论基础,包括其性质及其在计算机硬件中的应用。其次,通过案例分析,探讨了液态金属散热和连接技术的实践,以及液态金属在提升系统稳定性方面的实际效果。随后,对液态金属技术与传统散热材
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )