Python机器学习入门指南
发布时间: 2023-12-16 19:41:52 阅读量: 66 订阅数: 24 
# 1. Python机器学习入门概述
## 1.1 什么是机器学习?
机器学习是一门人工智能领域的重要分支,通过构建和应用算法模型,使计算机能够从数据中自动学习和改善性能,而无需进行明确的编程。机器学习在现代科技中的应用非常广泛,包括图像识别、语音识别、自然语言处理、推荐系统等等。
## 1.2 为什么选择Python作为机器学习的编程语言
Python作为一种简洁、易学易用的编程语言,成为了机器学习领域的首选语言。其主要原因如下:
- **广泛的机器学习库支持**:Python拥有丰富的机器学习库,例如Scikit-learn、TensorFlow、Keras等,这些库提供了完善的机器学习算法和工具,方便用户进行开发和实验。
- **简洁的语法和易读性**:Python的语法简洁优雅,易于理解和阅读,使得代码编写更加高效和可维护。
- **强大的数据处理能力**:Python的数据处理库(如Pandas和NumPy)提供了丰富的数据结构和函数,方便用户进行数据的清洗、转换和分析。
- **大量的社区支持**:Python拥有活跃的开源社区,用户可以快速获取帮助和分享经验。
## 1.3 Python机器学习库的概述
Python拥有众多优秀的第三方机器学习库,下面介绍几个常用的库:
- **Scikit-learn**:Scikit-learn是一个功能强大的Python机器学习库,提供了包括分类、回归、聚类、降维等多种机器学习算法,同时还包括了模型评估和数据预处理等工具。
- **TensorFlow**:TensorFlow是一个开源的深度学习框架,提供了高效的数值计算库和灵活的机器学习工具。它支持各种类型的神经网络模型构建和训练,广泛应用于图像识别、自然语言处理等领域。
- **Keras**:Keras是一个高级神经网络API,建立在TensorFlow、Theano和CNTK之上。它提供了一种快速搭建、快速实验的方式,适用于初学者快速入门以及专业人士快速原型开发。
- **Pandas**:Pandas是一个数据分析库,提供了高性能、易用的数据结构和数据分析工具。它可以处理结构化数据,并进行数据清洗、转换、分析和可视化。
综上所述,Python作为机器学习的编程语言,不仅拥有丰富的机器学习库支持,而且具有简洁的语法和强大的数据处理能力,因此成为了机器学习领域的首选语言之一。
接下来,我们将回顾一下Python的基础知识。
# 2. Python基础知识回顾
### 2.1 Python基础语法回顾
Python语言作为一门简洁优雅的高级编程语言,具有很强的可读性和易学性。在开始学习Python机器学习之前,我们先来回顾一下Python的基础语法知识,以便顺利理解后续的内容。
### 2.1.1 变量和数据类型
在Python中,可以通过赋值运算符"="给变量赋值,并且不需要事先声明变量类型。Python支持许多不同的数据类型,包括整数(int)、浮点数(float)、字符串(string)、布尔值(bool)等。
```python
# 变量赋值
x = 10
y = 3.14
name = "John"
is_student = True
# 数据类型转换
a = 5
b = float(a) # 将整数a转换为浮点数
# 打印变量的值
print(x)
print(y)
print(name)
print(is_student)
```
**代码总结:** 在Python中,可以使用赋值运算符"="来给变量赋值,而数据类型可以根据赋值的内容自动推断出来。通过print函数,可以打印出变量的值。
**结果说明:** 上述代码的输出结果分别为:10,3.14,John,True。
### 2.1.2 条件语句和循环语句
条件语句和循环语句是编程中非常重要的控制结构。在Python中,使用if-else语句进行条件判断,并使用for和while循环进行迭代。
```python
# 条件语句
x = 10
if x > 5:
print("x is greater than 5")
else:
print("x is less than or equal to 5")
# for循环
for i in range(1, 5):
print(i)
# while循环
count = 0
while count < 5:
print(count)
count += 1
```
**代码总结:** 使用if-else语句进行条件判断,冒号后的缩进代码块为条件为True时执行的代码。使用range函数生成一个迭代序列,并使用for循环来遍历序列中的每个元素。使用while循环在满足条件的情况下重复执行一段代码。
**结果说明:** 上述代码的输出结果为:
```
x is greater than 5
1
2
3
4
0
1
2
3
4
```
### 2.1.3 函数和模块
在Python中,函数是一段执行特定任务的代码块,可以重复使用。模块是一个包含函数、变量和语句的文件,用于组织和重用代码。下面是一些函数和模块的常用操作示例。
```python
# 定义函数
def add(a, b):
return a + b
# 调用函数
result = add(3, 4)
print(result)
# 导入模块
import math
# 使用模块中的函数
sqrt_result = math.sqrt(25)
print(sqrt_result)
```
**代码总结:** 使用def关键字定义一个函数,冒号后的缩进代码块为函数体,可以使用return语句返回值。通过模块的导入,可以使用模块中的函数和变量。
**结果说明:** 上述代码的输出结果为:
```
7
5.0
```
以上是Python基础知识回顾的内容。通过对Python的基础语法、变量和数据类型、条件语句和循环语句、函数和模块的回顾,我们为后续的机器学习入门做好了准备。
# 3. Python机器学习常用库介绍
在本章节中,我们将介绍在Python中常用的机器学习库,包括Numpy、Pandas、Matplotlib和Seaborn。这些库在机器学习领域中起着至关重要的作用,能够帮助我们进行数据处理和可视化。让我们一起来深入了解它们。
#### 3.1 Numpy库的基本用法
Numpy是Python中用于科学计算的核心库之一,在机器学习中广泛使用。它提供了高性能的多维数组对象,以及各种用于数组操作的工具。以下是Numpy库的基本用法:
```python
# 导入numpy库
import numpy as np
# 创建一个1维数组
arr1 = np.array([1, 2, 3, 4, 5])
print(arr1)
# 创建一个2维数组
arr2 = np.array([[1, 2, 3], [4, 5, 6]])
print(arr2)
# 数组的形状和大小
print(arr1.shape)
print(arr2.shape)
print(arr2.size)
# 数组的运算
arr3 = arr1 + 10
print(arr3)
```
**代码总结:** Numpy库提供了丰富的数组操作功能,包括数组的创建、形状和大小的获取以及数组的运算。
**结果说明:** 上述代码演示了Numpy库的基本用法,包括数组的创建和运算操作,对于机器学习中的数据处理和运算非常实用。
#### 3.2 Pandas库在数据处理中的应用
Pandas是一个提供了快速、灵活和方便的数据结构,特别适合于时间序列数据和关系型数据的数据处理工具。让我们看一下Pandas库在数据处理中的应用:
```python
# 导入pandas库
import pandas as pd
# 创建一个DataFrame
data = {'Name': ['Tom', 'Jerry', 'Mickey', 'Minnie'],
'Age': [28, 23, 25, 27]}
df = pd.DataFrame(data)
print(df)
# 选取DataFrame的列
print(df['Name'])
print(df.Age)
# 描述性统计
print(df.describe())
```
**代码总结:** Pandas库可以帮助我们轻松地创建和操作数据框架,包括数据的增删查改以及描述性统计分析。
**结果说明:** 以上代码演示了Pandas库在数据处理中的常用操作,如DataFrame的创建和描述性统计分析,这些功能对于机器学习中的数据预处理非常有帮助。
#### 3.3 Matplotlib和Seaborn数据可视化工具
Matplotlib和Seaborn是Python中常用的数据可视化工具,能够帮助我们对数据进行可视化分析,直观地展示数据特征和规律。让我们来看一下它们的基本用法:
```python
# 导入matplotlib和seaborn库
import matplotlib.pyplot as plt
import seaborn as sns
# 绘制折线图
x = [1, 2, 3, 4, 5]
y = [2, 3, 5, 7, 11]
plt.plot(x, y)
plt.show()
# 绘制柱状图
plt.bar(x, y)
plt.show()
# 绘制箱线图
sns.boxplot(data=y)
plt.show()
```
**代码总结:** Matplotlib和Seaborn库提供了丰富的数据可视化功能,包括折线图、柱状图和箱线图等,能够帮助我们直观地理解和展示数据。
**结果说明:** 上述代码演示了Matplotlib和Seaborn库的基本用法,包括常用图表的绘制,这些功能对于机器学习中的数据可视化和分析非常重要。
# 4. 机器学习算法入门
在这一章节,我们将介绍机器学习的基本算法,包括监督学习算法、无监督学习算法以及机器学习模型的评估方法。
#### 4.1 监督学习算法介绍
监督学习是一种机器学习范式,通过使用有标签的训练数据来训练模型,然后对新数据进行预测或分类。在监督学习中常用的算法包括:
- 线性回归
- 逻辑回归
- 决策树
- 随机森林
- 支持向量机
- 朴素贝叶斯
下面是一个简单的示例,使用Python的scikit-learn库进行线性回归的实现:
```python
# 导入所需的库
import numpy as np
from sklearn.linear_model import LinearRegression
# 准备训练数据
X = np.array([1, 2, 3, 4, 5]).reshape(-1, 1)
y = np.array([2, 4, 5, 4, 5])
# 创建线性回归模型
model = LinearRegression()
# 拟合模型
model.fit(X, y)
# 进行预测
X_test = np.array([6]).reshape(-1, 1)
y_pred = model.predict(X_test)
print("预测结果:", y_pred)
```
通过上述代码,我们实现了简单的线性回归模型,并对新数据进行了预测。
#### 4.2 无监督学习算法介绍
无监督学习是一种机器学习方法,用于对不带标签的数据进行建模和处理。在无监督学习中常用的算法包括:
- K均值聚类
- DBSCAN
- 主成分分析(PCA)
- t分布邻域嵌入(t-SNE)
- 关联规则学习
下面是一个简单的示例,使用Python的scikit-learn库进行K均值聚类的实现:
```python
# 导入所需的库
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 准备数据
X = np.array([[1, 2], [1, 4], [1, 0], [4, 2], [4, 4], [4, 0]])
# 创建K均值聚类模型
kmeans = KMeans(n_clusters=2, random_state=0)
# 拟合模型
kmeans.fit(X)
# 可视化结果
plt.scatter(X[:, 0], X[:, 1], c=kmeans.labels_, cmap='viridis')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], c='red', marker='x')
plt.show()
```
通过上述代码,我们实现了简单的K均值聚类,并对数据进行了可视化展示。
#### 4.3 机器学习模型评估方法
在机器学习中,评估模型的性能是非常重要的。常用的模型评估方法包括:
- 准确率(Accuracy)
- 精确率和召回率(Precision and Recall)
- F1分数
- ROC曲线和AUC值
- 混淆矩阵
我们可以使用Python的scikit-learn库来实现模型评估,以下是一个简单的示例:
```python
# 导入所需的库
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_curve, auc, confusion_matrix
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
import numpy as np
# 准备数据
X, y = np.array([[1, 2], [2, 3], [3, 4], [4, 5], [5, 6], [6, 7]]), np.array([0, 0, 0, 1, 1, 1])
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建逻辑回归模型
model = LogisticRegression()
# 拟合模型
model.fit(X_train, y_train)
# 模型预测
y_pred = model.predict(X_test)
# 评估模型性能
print("准确率:", accuracy_score(y_test, y_pred))
print("精确率:", precision_score(y_test, y_pred))
print("召回率:", recall_score(y_test, y_pred))
print("F1分数:", f1_score(y_test, y_pred))
print("混淆矩阵:", confusion_matrix(y_test, y_pred))
```
通过上述代码,我们使用了逻辑回归模型,对数据进行划分、训练、预测,并对模型性能进行了评估。
以上便是机器学习算法入门的内容,包括监督学习算法、无监督学习算法以及模型评估方法。在实际应用中,我们可以根据具体问题的特点选择合适的算法和评估方法,从而进行机器学习模型的构建和优化。
# 5. Python机器学习实战
在本章节中,我们将深入实际项目,介绍Python机器学习的实战应用。我们将包括数据准备和预处理、监督学习模型训练与预测以及无监督学习模型应用等内容。
### 5.1 数据准备和预处理
在实际的机器学习项目中,数据准备和预处理是非常重要的一步。这一步包括数据清洗、特征选择、特征变换、数据集划分等工作。下面是一个简单的数据准备和预处理示例:
```python
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 读取数据
data = pd.read_csv('data.csv')
# 数据清洗
data.dropna(inplace=True)
# 特征选择
X = data[['feature1', 'feature2', 'feature3']]
# 目标变量
y = data['target']
# 数据集划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 特征标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
```
这段代码演示了如何使用Pandas库读取数据,并进行数据清洗、特征选择、数据集划分和特征标准化的过程。
### 5.2 监督学习模型训练与预测
接下来,我们将介绍监督学习模型的训练与预测。我们以一个简单的线性回归模型为例进行演示:
```python
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 模型训练
model = LinearRegression()
model.fit(X_train, y_train)
# 模型预测
y_pred = model.predict(X_test)
# 评估模型
mse = mean_squared_error(y_test, y_pred)
print("Mean Squared Error:", mse)
```
以上代码展示了如何使用Scikit-learn库训练一个线性回归模型,并对测试集进行预测,最后评估模型的性能。
### 5.3 无监督学习模型应用
在无监督学习模型应用中,我们以聚类算法K均值为例进行演示:
```python
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 模型训练
kmeans = KMeans(n_clusters=3, random_state=42)
kmeans.fit(X)
# 可视化聚类结果
plt.scatter(X['feature1'], X['feature2'], c=kmeans.labels_, cmap='viridis')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], c='red', marker='x')
plt.show()
```
这段代码演示了如何使用Scikit-learn库进行K均值聚类,并通过Matplotlib库可视化聚类结果。
通过本章内容的学习,我们将对Python机器学习的实际应用有更深入的了解。
# 6. Python机器学习的进阶内容
在本章中,我们将深入探讨Python机器学习的进阶内容,包括特征工程与模型优化、深度学习与神经网络入门以及Python机器学习在实际项目中的应用案例。
#### 6.1 特征工程与模型优化
特征工程是指利用领域知识和相关技术对原始数据进行处理,以创建能够更好地表达预测模型的特征。在Python中,我们可以使用Scikit-learn库进行特征工程,例如数据标准化、特征选择、特征变换等。下面是一个简单的特征工程示例代码:
```python
# 导入所需库
from sklearn.preprocessing import StandardScaler
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
from sklearn.decomposition import PCA
# 标准化数据
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 特征选择
selector = SelectKBest(score_func=chi2, k=5)
X_train_selected = selector.fit_transform(X_train, y_train)
X_test_selected = selector.transform(X_test)
# 特征变换
pca = PCA(n_components=2)
X_train_pca = pca.fit_transform(X_train)
X_test_pca = pca.transform(X_test)
```
通过特征工程的处理,我们可以提取出最具代表性的特征,有效提高模型的预测性能。
#### 6.2 深度学习与神经网络入门
深度学习是机器学习领域的热门分支,通过构建多层神经网络模型,可以处理复杂的非线性关系和大规模数据。在Python中,我们可以使用TensorFlow、Keras等库来构建深度学习模型。以下是一个简单的神经网络构建示例:
```python
# 导入所需库
import tensorflow as tf
from tensorflow import keras
# 构建神经网络模型
model = keras.Sequential([
keras.layers.Dense(64, activation='relu', input_shape=(10,)),
keras.layers.Dense(64, activation='relu'),
keras.layers.Dense(1, activation='sigmoid')
])
# 编译模型
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
# 模型训练
model.fit(X_train, y_train, epochs=10, batch_size=32)
```
#### 6.3 Python机器学习在实际项目中的应用案例
最后,我们将介绍Python机器学习在实际项目中的应用案例,例如基于Scikit-learn库的分类、回归、聚类等算法在真实数据集上的应用,并展示模型评估和效果分析的过程。
在本章节中,我们将深入了解并实践Python机器学习的进阶内容,包括特征工程与模型优化、深度学习与神经网络入门以及实际项目中的应用案例。通过学习本章内容,读者将能够更加深入地理解和应用Python机器学习技术。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
这个专栏提供了丰富实用的Python机器学习案例,帮助读者从入门到精通掌握机器学习的基本概念和实践技巧。专栏内包含多篇文章,包括Python机器学习入门指南、数据预处理和特征工程、监督学习算法解析、逻辑回归实战案例、线性回归应用实例、决策树算法实际应用、聚类分析实践指南、回归分析与模型优化、支持向量机(SVM)的实战应用、神经网络应用案例解析、深度学习算法实战分析等。此外还包括模型评估与效果展示、特征选择与降维技术、异常检测技术实际案例、关联规则挖掘实战分析、时间序列分析实际案例、推荐系统的技术深入分析、文本挖掘与情感分析的实战,以及集成学习算法实践指南等。无论是初学者还是有经验的开发者,都能从这个专栏中学到有关Python机器学习的宝贵知识和实践技巧。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【SketchUp设计自动化】

# 摘要
本文系统地探讨了SketchUp设计自动化在现代设计行业中的概念与重要性,着重介绍了SketchUp的基础操作、脚本语言特性及其在自动化任务中的应用。通过详细阐述如何通过脚本实现基础及复杂设计任务的自动化
【科大讯飞语音识别:二次开发的6大技巧】:打造个性化交互体验
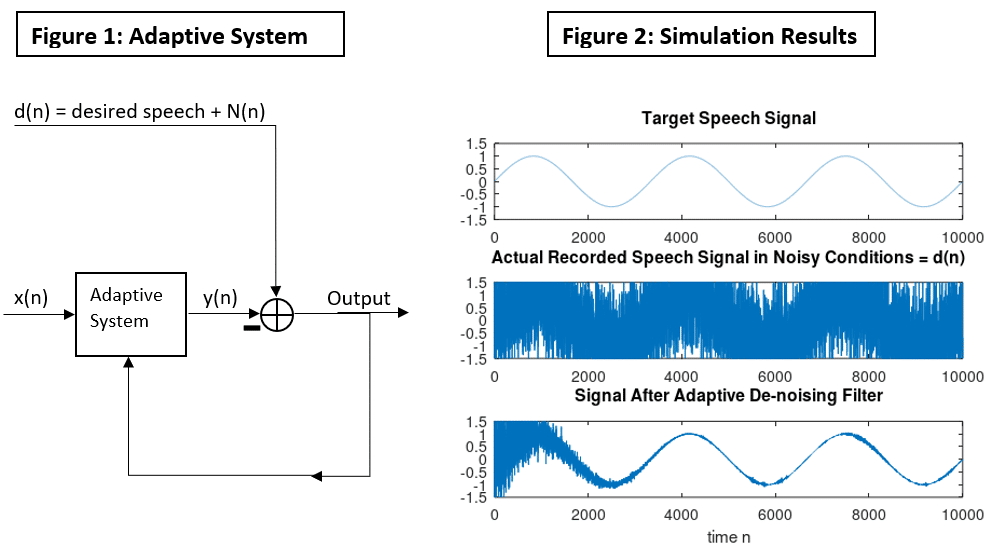
# 摘要
科大讯飞作为领先的语音识别技术提供商,其技术概述与二次开发基础是本篇论文关注的焦点。本文首先概述了科大讯飞语音识别技术的基本原理和API接口,随后深入探讨了二次开发过程中参数优化、场景化应用及后处理技术的实践技巧。进阶应用开发部分着重讨论了语音识别与自然语言处理的结合、智能家居中的应用以及移动应用中的语音识别集成。最后,论文分析了性能调优策略、常见问题解决方法,并展望了语音识别技术的未来趋势,特别是人工
【电机工程独家技术】:揭秘如何通过磁链计算优化电机设计

# 摘要
电机工程的基础知识与磁链概念是理解和分析电机性能的关键。本文首先介绍了电机工程的基本概念和磁链的定义。接着,通过深入探讨电机电磁学的基本原理,包括电磁感应定律和磁场理论基础,建立了电机磁链的理论分析框架。在此基础上,详细阐述了磁链计算的基本方法和高级模型,重点包括线圈与磁通的关系以及考虑非线性和饱和效应的模型。本文还探讨了磁链计算在电机设计中的实际应
【用户体验(UX)在软件管理中的重要性】:设计原则与实践

# 摘要
用户体验(UX)是衡量软件产品质量和用户满意度的关键指标。本文深入探讨了UX的概念、设计原则及其在软件管理中的实践方法。首先解析了用户体验的基本概念,并介绍了用户中心设计(UCD)和设计思维的重要性。接着,文章详细讨论了在软件开发生命周期中整合用户体验的重要性,包括敏捷开发环境下的UX设计方法以及如何进行用户体验度量和评估。最后,本文针对技术与用户需求平
【MySQL性能诊断】:如何快速定位和解决数据库性能问题

# 摘要
MySQL作为广泛应用的开源数据库系统,其性能问题一直是数据库管理员和技术人员关注的焦点。本文首先对MySQL性能诊断进行了概述,随后介绍了性能诊断的基础理论,包括性能指标、监控工具和分析方法论。在实践技巧章节,文章提供了SQL优化策略、数据库配置调整和硬件资源优化建议。通过分析性能问题解决的案例,例如慢
【硬盘管理进阶】:西数硬盘检测工具的企业级应用策略(企业硬盘管理的新策略)

# 摘要
硬盘作为企业级数据存储的核心设备,其管理与优化对企业信息系统的稳定运行至关重要。本文探讨了硬盘管理的重要性与面临的挑战,并概述了西数硬盘检测工具的功能与原理。通过深入分析硬盘性能优化策略,包括性能检测方法论与评估指标,本文旨在为企业提供硬盘维护和故障预防的最佳实践。此外,本文还详细介绍了数据恢复与备份的高级方法,并探讨了企业硬盘管理的未来趋势,包括云存储和分布式存储的融合,以及智能化管理工具的发展
【sCMOS相机驱动电路调试实战技巧】:故障排除的高手经验
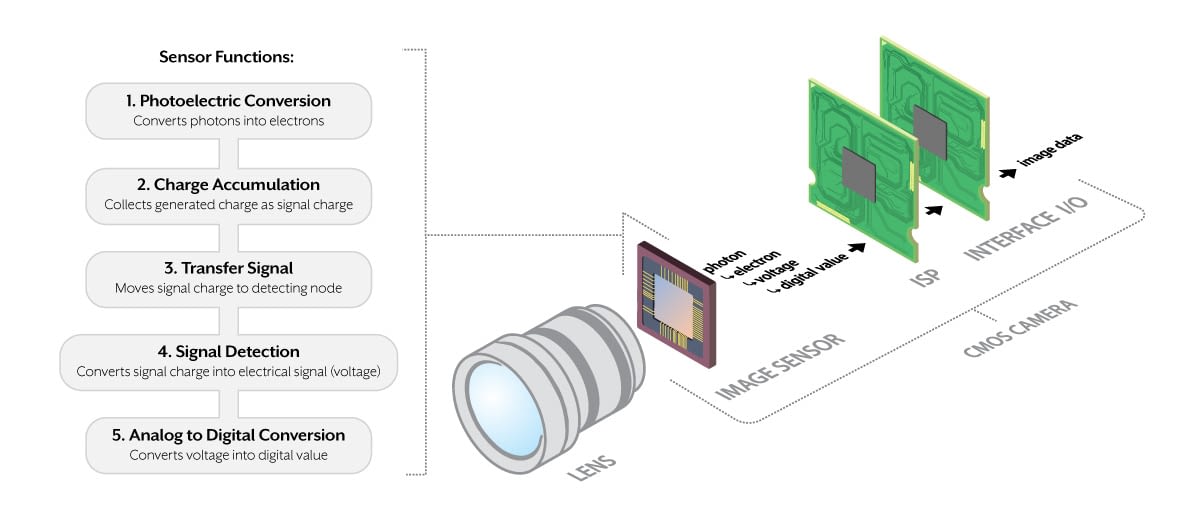
# 摘要
sCMOS相机驱动电路是成像设备的重要组成部分,其性能直接关系到成像质量与系统稳定性。本文首先介绍了sCMOS相机驱动电路的基本概念和理论基础,包括其工作原理、技术特点以及驱动电路在相机中的关键作用。其次,探讨了驱动电路设计的关键要素,
【LSTM双色球预测实战】:从零开始,一步步构建赢率系统
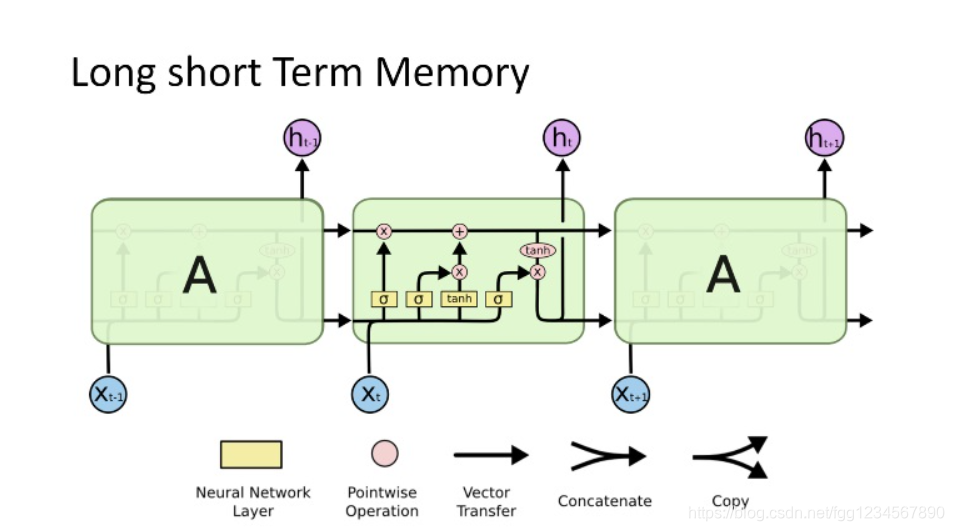
# 摘要
本文旨在通过LSTM(长短期记忆网络)技术预测双色球开奖结果。首先介绍了LSTM网络及其在双色球预测中的应用背景。其次,详细阐述了理
EMC VNX5100控制器SP更换后性能调优:专家的最优实践

# 摘要
本文全面介绍了EMC VNX5100存储控制器的基本概念、SP更换流程、性能调优理论与实践以及故障排除技巧。首先概述了VNX5100控制器的特点以及更换服务处理器(SP)前的准备工作。接着,深入探讨了性能调优的基础理论,包括性能监控工具的使用和关键性能参数的调整。此外,本文还提供了系统级性能调优的实际操作指导
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )