Restful API设计与实践
发布时间: 2023-12-17 09:38:34 阅读量: 41 订阅数: 41 

restful api设计
# 第一章:Restful API简介
## 1.1 Restful API概述
## 1.2 Restful API的特点
## 1.3 Restful API与传统API的区别
## 第二章:Restful API设计原则
### 2.1 资源的命名
在Restful API设计中,准确的资源命名是非常重要的。资源的命名应该使用名词,并且使用复数形式。例如,对于用户资源,可以使用`/users`来表示。同时,应该避免在命名中使用动词,因为HTTP动词已经用于表示对资源的操作。
### 2.2 使用HTTP动词
HTTP协议提供了一系列的动词(GET、POST、PUT、DELETE等),这些动词可以用来对资源进行不同的操作。在Restful API设计中,应该合理地使用这些HTTP动词来表示对资源的操作。
- GET:用于获取资源的信息。
- POST:用于创建新的资源。
- PUT:用于更新已有资源的信息。
- DELETE:用于删除资源。
使用恰当的HTTP动词可以使API的设计更加符合规范,提高开发者的易用性和效率。
### 2.3 状态码的运用
在Restful API中,使用合适的HTTP状态码可以方便地表示接口的执行结果。常用的状态码有:
- 200 OK:表示请求成功。
- 201 Created:表示资源创建成功。
- 400 Bad Request:表示请求参数有误。
- 401 Unauthorized:表示未经授权。
- 404 Not Found:表示资源不存在。
- 500 Internal Server Error:表示服务器内部错误。
选择合适的状态码可以提供更好的用户体验,并使接口的调用更加明确和可靠。
### 2.4 数据格式和版本控制
Restful API中的数据格式通常使用JSON或XML,但JSON是目前更为流行的选择。JSON格式具有良好的可读性和扩展性,能够满足大多数场景的需求。
在设计API时,还应该考虑到版本控制的问题。当API发生变化时,为了兼容老版本的调用者,可以在URL中添加版本号。例如,`/v1/users`表示版本1的用户资源。
### 3. 第三章:Restful API设计实践
在本章中,我们将深入探讨如何实践设计一个符合Restful API规范的接口。我们将讨论URI的设计、请求与响应的格式规范、安全认证及权限管理,以及性能优化与缓存策略的实践方法。
#### 3.1 URI设计
在Restful API设计中,URI的设计是非常重要的一环。一个好的URI设计能够使API更加易读、易用,并且能够清晰地表达资源的层级关系和操作。通常来说,URI应该采用名词来表示资源,采用HTTP动词来表示对资源的操作。比如:
```python
# Python 示例
# 获取所有用户信息
GET /users
# 获取特定用户信息
GET /users/{id}
# 创建新用户
POST /users
# 更新特定用户信息
PUT /users/{id}
# 删除特定用户
DELETE /users/{id}
```
#### 3.2 请求与响应的格式规范
在Restful API设计中,请求与响应的格式规范是需要严格遵守的。通常来说,我们可以使用JSON格式来作为数据交换的格式,因为JSON具有良好的可读性和通用性。同时,在响应中应该包含适当的HTTP状态码,以便客户端能够根据状态码进行相应的处理。比如:
```python
# Python 示例
# 请求格式
{
"name": "Alice",
"age": 25,
"email": "alice@example.com"
}
# 响应格式
{
"id": 1,
"name": "Alice",
"age": 25,
"email": "alice@example.com"
}
```
#### 3.3 安全认证及权限管理
在Restful API设计中,安全认证及权限管理是至关重要的。通常来说,我们可以采用OAuth 2.0等标准协议来进行用户身份认证和授权管理。同时,对于不同等级的用户,需要设计合理的权限管理策略,确保用户只能访问其具有权限的资源。比如:
```python
# Python 示例
# 用户身份认证
POST /auth/token
# 获取特定用户详细信息(需要权限)
GET /users/{id}
```
#### 3.4 性能优化与缓存策略
在Restful API设计实践中,性能优化与缓存策略是需要重点考虑的方面。我们可以通过合理的接口设计、合适的数据缓存策略来提升API的性能和响应速度,同时减轻服务器的压力。比如:
```python
# Python 示例
# 数据缓存策略
# 设置响应缓存
Cache-Control: max-age=3600
# 利用ETag进行缓存验证
ETag: "33a64df551425fcc55e4d42a148795d9f25f89d4"
```
### 4. 第四章:Restful API的错误处理与异常情况
在设计和实现Restful API时,错误处理和异常情况的处理是非常重要的。良好的错误处理能够提升API的可用性和用户体验,同时也能够提供给开发者清晰的异常信息,方便定位和解决问题。
#### 4.1 错误码的设计
在Restful API中,错误码的设计是至关重要的。错误码应当具有一定的规范和约定,以便开发者能够快速了解错误的类型和原因。
一般而言,错误码的设计应当包含以下几个方面:
- **错误类型分类**:例如将错误码分为服务端错误、客户端错误、权限错误等,便于开发者快速定位问题。
- **错误码的具体含义**:每个错误码应当具有清晰的含义,开发者能够根据错误码快速了解错误的类型和原因。
- **错误码的范围**:建议采用一定的错误码范围划分,例如2xx表示成功,4xx表示客户端错误,5xx表示服务端错误等。
以下是一个简单的错误码设计示例(使用Python):
```python
class ErrorCode:
SUCCESS = 200
CLIENT_ERROR_START = 400
NOT_FOUND = 404
AUTH_ERROR = 401
SERVER_ERROR_START = 500
INTERNAL_ERROR = 500
DATABASE_ERROR = 501
```
#### 4.2 异常处理机制
在Restful API中,异常处理是非常重要的一环。合理的异常处理机制能够保证API的稳定性和可靠性。
常见的异常处理机制包括:
- **异常类型的定义**:定义一些常见的异常类型,例如数据不存在异常、权限不足异常、参数错误异常等。
- **统一异常处理**:对于不同类型的异常,应当进行统一的处理,例如返回统一的错误格式,方便开发者快速定位问题。
以下是一个简单的异常处理机制示例(使用Python):
```python
class DataNotFoundException(Exception):
pass
class PermissionDeniedException(Exception):
pass
@app.errorhandler(DataNotFoundException)
def handle_data_not_found_error(error):
response = jsonify({'error': 'Data not found'})
response.status_code = 404
return response
@app.errorhandler(PermissionDeniedException)
def handle_permission_denied_error(error):
response = jsonify({'error': 'Permission denied'})
response.status_code = 403
return response
```
#### 4.3 接口文档与规范
在Restful API中,良好的接口文档和规范能够帮助开发者更好地理解和使用API,从而减少错误和提高工作效率。
常见的接口文档和规范包括:
- **接口文档的编写**:详细描述每个API的输入参数、输出参数、返回示例等内容,方便开发者快速上手。
- **接口规范的约定**:统一接口的命名规范、参数传递方式、错误处理方式等,使得接口风格和规范保持一致。
- **接口版本管理**:针对不同版本的API,需要进行清晰的版本管理,并及时更新文档和规范。
综上所述,错误处理和异常情况的处理是Restful API设计中非常重要的环节,良好的错误码设计、异常处理机制和接口文档规范能够提升API的稳定性和易用性。
## 第五章:Restful API测试与调试
### 5.1 单元测试
单元测试是指对软件中的最小可测试单元进行检查和验证,对于Restful API的开发来说,单元测试是十分重要的环节。通过编写单元测试可以确保API的功能正常、接口参数正确,并且可以及早地发现和修复潜在的问题。下面是一个使用Python进行单元测试的示例:
```python
import unittest
import requests
class APITestCase(unittest.TestCase):
def setUp(self):
self.base_url = "http://api.example.com/"
def test_get_user(self):
url = self.base_url + "users/1"
response = requests.get(url)
self.assertEqual(response.status_code, 200)
self.assertEqual(response.json()["name"], "John")
def test_create_user(self):
url = self.base_url + "users"
data = {
"name": "Jane",
"age": 25
}
response = requests.post(url, json=data)
self.assertEqual(response.status_code, 201)
self.assertEqual(response.json()["id"], 2)
def tearDown(self):
# 清理测试数据或关闭资源的操作
pass
if __name__ == "__main__":
unittest.main()
```
在上述代码中,首先定义了一个继承自`unittest.TestCase`的测试类`APITestCase`,在`setUp`方法中初始化了测试用例需要使用的参数,比如API的基础URL。接下来,每个测试用例都通过`requests`模块发送HTTP请求,并使用断言方法进行响应结果的验证。最后,在`tearDown`方法中可以执行一些测试后的清理操作。
### 5.2 集成测试
集成测试是指在系统开发的后期阶段对整体系统进行测试和验证,主要检验各个模块之间的协同配合是否正常。对于Restful API的开发来说,集成测试可以确保不同API之间的调用和数据传递是否正确,同时也可以发现系统架构上的问题。下面是一个使用Java和JUnit进行集成测试的示例:
```java
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.boot.test.web.client.TestRestTemplate;
import org.springframework.http.HttpEntity;
import org.springframework.http.HttpHeaders;
import org.springframework.http.HttpMethod;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.test.context.junit4.SpringRunner;
@RunWith(SpringRunner.class)
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
public class APITest {
@Autowired
private TestRestTemplate restTemplate;
@Test
public void testGetUser() {
String url = "/users/1";
ResponseEntity<User> response = restTemplate.getForEntity(url, User.class);
assertThat(response.getStatusCode(), equalTo(HttpStatus.OK));
assertThat(response.getBody().getName(), equalTo("John"));
}
@Test
public void testCreateUser() {
String url = "/users";
User user = new User("Jane", 25);
HttpHeaders headers = new HttpHeaders();
headers.add("Content-Type", "application/json");
HttpEntity<User> requestEntity = new HttpEntity<>(user, headers);
ResponseEntity<User> response = restTemplate.exchange(url, HttpMethod.POST, requestEntity, User.class);
assertThat(response.getStatusCode(), equalTo(HttpStatus.CREATED));
assertThat(response.getBody().getId(), equalTo(2L));
}
}
```
在上述代码中,使用了Spring Boot的`TestRestTemplate`来模拟HTTP请求。在每个测试方法中,首先构建请求的URL或请求体,并发送HTTP请求,然后通过断言方法来验证响应结果。
### 5.3 接口调试工具的使用
在Restful API的开发过程中,使用接口调试工具可以方便地对API进行调试和测试。常用的接口调试工具有Postman、curl等。下面以Postman为例,演示如何使用其进行调试:
1. 打开Postman,输入API的请求URL。
2. 选择请求方法,如GET、POST等,并配置请求头和请求体。
3. 点击发送按钮,查看接口的响应结果和状态码。
通过接口调试工具,开发人员可以直观地观察接口的请求和响应过程,并可以方便地进行参数的调整和测试。
这是第五章的内容,包括了单元测试、集成测试以及接口调试工具的使用。单元测试和集成测试可以保证API的功能正确性,接口调试工具可以方便地进行接口的调试和测试。在实际开发过程中,这些工具和方法是非常重要的,能够提高开发效率和代码质量。
### 6. 第六章:Restful API的部署与监控
在本章中,我们将探讨Restful API的部署与监控相关的内容,包括API的部署方式、监控与日志记录、API版本化的管理以及API的运维管理与故障处理。
#### 6.1 API的部署方式
Restful API的部署方式通常包括传统的单机部署和现代的云原生部署两种方式。单机部署可以选择常见的Web服务器,如Nginx、Apache等,通过反向代理实现负载均衡和高可用。而云原生部署则可以借助Docker容器和Kubernetes进行集群化部署,实现弹性伸缩和自动化运维。
```python
# Dockerfile示例
FROM python:3.7
WORKDIR /app
COPY . /app
CMD ["python", "app.py"]
```
#### 6.2 API的监控与日志记录
为了确保Restful API的稳定运行,监控与日志记录是必不可少的。可以利用Prometheus和Grafana等工具进行实时监控和性能分析,同时通过ELK(Elasticsearch、Logstash、Kibana)技术栈实现日志的集中存储与搜索分析。
```java
// 使用Prometheus进行指标监控
import io.prometheus.client.Counter;
import io.prometheus.client.exporter.HTTPServer;
public class ApiMonitor {
static final Counter requestTotal = Counter.build()
.name("api_requests_total")
.help("Total requests to the API.")
.register();
public static void main(String[] args) throws Exception {
HTTPServer server = new HTTPServer(1234);
// Your code here.
}
}
```
#### 6.3 API版本化的管理
随着业务的发展,Restful API可能需要进行版本迭代。为了保证新旧版本的兼容性,可以通过在URI中添加版本号或者采用请求头中的版本标识来进行API版本化管理。
```go
// 使用URI添加版本号
mux.HandleFunc("/v1/users", handlers.UserHandlerV1)
// 使用请求头中的版本标识
req.Header.Add("API-Version", "v2")
```
#### 6.4 API的运维管理与故障处理
运维管理涉及到API的监控报警、灰度发布、自动化运维等内容;而故障处理则需要建立健全的故障处理机制,包括异常情况的处理、快速定位问题、故障恢复等方面。
```javascript
// 灰度发布示例
const percentage = 25;
if (Math.floor(Math.random() * 100) < percentage) {
// 灰度发布代码
} else {
// 正常发布代码
}
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《ddl》专栏涵盖了计算机编程和网络技术的广泛主题,旨在帮助读者打好计算机领域的基础知识。从“初识编程:入门教程”开始,逐步深入了解HTML、CSS、JavaScript等基础知识,以及Python的语法与应用。此外,网络基础、数据库、操作系统、Git版本控制、Restful API设计等方面也被涵盖其中。同时,专栏还介绍了数据结构与算法、计算机网络原理与应用、云计算、Docker容器技术、大数据、机器学习、人工智能等热门领域的基础知识。此外,专栏还介绍了软件开发中的测试与调试技巧以及Web安全基础知识。无论您是初学者还是有一定基础的技术人员,本专栏都能帮助您打好计算机领域的基础,为未来的学习和发展奠定坚实的基础。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【MATLAB C4.5算法性能提升秘籍】:代码优化与内存管理技巧

# 摘要
本论文首先概述了MATLAB中C4.5算法的基础知识及其在数据挖掘领域的应用。随后,探讨了MATLAB代码优化的基础,包括代码效率原理、算法性能评估以及优化技巧。深入分析了MATLAB内存管理的原理和优化方法,重点介绍了内存泄漏的检测与预防
【稳定性与混沌的平衡】:李雅普诺夫指数在杜芬系统动力学中的应用

# 摘要
本文旨在介绍杜芬系统的概念与动力学基础,深入分析李雅普诺夫指数的理论和计算方法,并探讨其在杜芬系统动力学行为和稳定性分析中的应用。首先,本文回顾了杜芬系统的动力学基础,并对李雅普诺夫指数进行了详尽的理论探讨,包括其定义、性质以及在动力系统中的角色。
QZXing在零售业中的应用:专家分享商品快速识别与管理的秘诀

# 摘要
QZXing作为一种先进的条码识别技术,在零售业中扮演着至关重要的角色。本文全面探讨了QZXing在零售业中的基本概念、作用以及实际应用。通过对QZXing原理的阐述,展示了其在商品快速识别中的核心技术优势,例如二维码识别技术及其在不同商品上的应用案例。同时,分析了QZXing在提高商品识别速度和零售效率方面的实际效果
【AI环境优化高级教程】:Win10 x64系统TensorFlow配置不再难

# 摘要
本文详细探讨了在Win10 x64系统上安装和配置TensorFlow环境的全过程,包括基础安装、深度环境配置、高级特性应用、性能调优以及对未来AI技术趋势的展望。首先,文章介绍了如何选择合适的Python版本以及管理虚拟环境,接着深入讲解了GPU加速配置和内存优化。在高级特性应用
【宇电温控仪516P故障解决速查手册】:快速定位与修复常见问题

# 摘要
本文全面介绍了宇电温控仪516P的功能特点、故障诊断的理论基础与实践技巧,以及常见故障的快速定位方法。文章首先概述了516P的硬件与软件功能,然后着重阐述了故障诊断的基础理论,包括故障的分类、系统分析原理及检测技术,并分享了故障定位的步骤和诊断工具的使用方法。针对516P的常见问题,如温度显示异常、控制输出不准确和通讯故障等,本文提供了详尽的排查流程和案例分析,并探讨了电气组件和软件故障的修复方法。此外
【文化变革的动力】:如何通过EFQM模型在IT领域实现文化转型

# 摘要
EFQM模型是一种被广泛认可的卓越管理框架,其在IT领域的适用性与实践成为当前管理创新的重要议题。本文首先概述了EFQM模型的核心理论框架,包括五大理念、九个基本原则和持续改进的方法论,并探讨了该模型在IT领域的具体实践案例。随后,文章分析了EFQM模型如何在IT企业文化中推动创新、强化团队合作以及培养领导力和员工发展。最后,本文研究了在多样化
RS485系统集成实战:多节点环境中电阻值选择的智慧
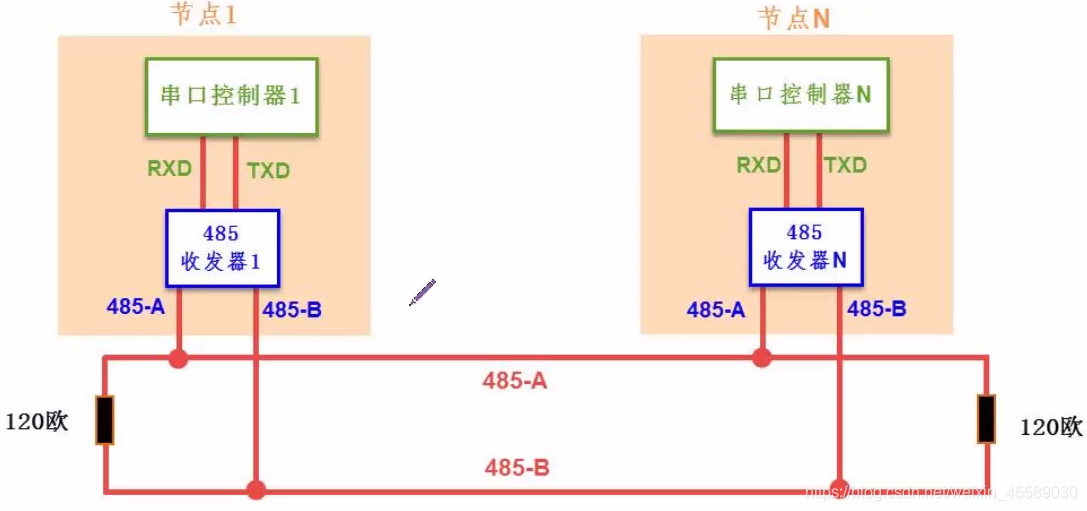
# 摘要
本文系统性地探讨了RS485系统集成的基础知识,深入解析了RS485通信协议,并分析了多节点RS485系统设计中的关键原则。文章
【高级电磁模拟】:矩量法在复杂结构分析中的决定性作用
# 摘要
本文全面介绍了电磁模拟与矩量法的基础理论及其应用。首先,概述了矩量法的基本概念及其理论基础,包括电磁场方程和数学原理,随后深入探讨了积分方程及其离散化过程。文章着重分析了矩量法在处理多层介质、散射问题及电磁兼容性(EMC)方面的应用,并通过实例展示了其在复杂结构分析中的优势。此外,本文详细阐述了矩量法数值模拟实践,包括模拟软件的选用和模拟流程,并对实际案例
SRIO Gen2在云服务中的角色:云端数据高效传输技术深度支持

# 摘要
本文旨在深入探讨SRIO Gen2技术在现代云服务基础架构中的应用与实践。首先,文章概述了SRIO Gen2的技术原理,及其相较于传统IO技术的显著优势。然后,文章详细分析了SRIO Gen2在云服务中尤其是在数据中心的应用场景,并提供了实际案例研
先农熵在食品质量控制的重要性:确保食品安全的科学方法

# 摘要
本文深入探讨了食品质量控制的基本原则与重要性,并引入先农熵理论,阐述其科学定义、数学基础以及与热力学第二定律的关系。通过对先农熵在食品稳定性和保质期预测方面作用的分析,详细介绍了先农熵测量技术及其在原料质量评估、加工过程控制和成品质量监控中的应用。进一步,本文探讨了先农熵与其他质量控制方法的结合,以及其在创新食品保存技术和食品安全法规标准中的应用。最后,通过案例分析,总结了先农熵在食品质量控制中
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )