使用Spark SQL进行数据清洗与规范化技巧
发布时间: 2023-12-16 11:32:55 阅读量: 76 订阅数: 28 

数据清洗
# 1. 理解数据清洗与规范化
## 1.1 数据清洗的概念与重要性
数据清洗是指在数据分析和挖掘过程中,对数据进行筛选、整理和转换,以去除脏数据、错误数据、重复数据和不完整数据,确保数据的准确性和完整性。数据清洗是数据预处理的重要步骤,能够提高数据质量,保证后续分析和建模的准确性和可靠性。
## 1.2 数据规范化的原理与作用
数据规范化是指将不同格式、不同来源的数据统一为一致的标准格式和规范的数据结构,使得数据具有一致性和可比性。数据规范化能够简化数据处理和分析过程,减少数据冗余,提高数据的可读性和可维护性。
## 1.3 数据清洗与规范化在大数据处理中的意义
在大数据处理中,数据量庞大且多样化,可能存在大量的脏数据和非规范数据,如果不进行清洗和规范化,将会影响后续的数据分析和挖掘效果,甚至导致错误的决策和信息失真。因此,数据清洗和规范化在大数据处理中显得尤为重要,能够提高数据的质量和价值,为后续的数据应用提供可靠的基础。
# 2. Spark SQL简介与基础知识回顾
Apache Spark是一个快速、通用、可扩展的大数据处理系统,其中的Spark SQL模块是用来操作结构化数据的核心组件之一。本章将对Spark SQL进行简要介绍,并回顾其基础知识。
### 2.1 Spark SQL的基本概念与原理
Spark SQL是Spark中用来操作结构化数据的API,它提供了DataFrame和SQL的抽象。DataFrame是一种分布式的数据集合,它可以被看作是一个表,也可以被看作是一个RDD。Spark SQL利用DataFrame这种数据抽象,能够更方便地进行数据处理和分析。
Spark SQL的原理是通过Catalyst优化器将SQL查询转换为一系列的RDD操作,同时支持读取不同的数据源(如JSON、Parquet、Hive等),并将其转换为DataFrame进行处理。
### 2.2 Spark SQL与传统SQL的区别与联系
传统SQL是用于关系型数据库的查询语言,而Spark SQL则是针对大数据处理的工具,能够处理分布式数据。虽然两者的语法很相似,但Spark SQL提供了更丰富的数据处理能力,支持复杂的数据分析和机器学习功能。
Spark SQL与传统SQL的联系在于,Spark SQL提供了类似传统SQL的语法和功能,使得熟悉传统SQL的用户可以更快地上手Spark SQL。
### 2.3 Spark SQL在数据处理中的优势与应用场景
Spark SQL在数据处理中有许多优势,包括灵活的数据处理能力、丰富的数据源支持、优化的查询性能等。它被广泛应用于数据清洗、数据规范化、数据分析、机器学习等领域。
在大数据处理场景下,Spark SQL广泛应用于企业级数据仓库构建、数据湖处理,以及实时数据分析等场景。其高效处理能力和丰富的功能使得其成为大数据处理的重要工具。
接下来,我们将深入探讨如何利用Spark SQL进行数据清洗,敬请关注后续内容。
# 3. 使用Spark SQL进行数据清洗
数据清洗是指在数据处理过程中,对数据中存在的异常值、缺失值、重复值等进行识别和处理,以保证数据的准确性和完整性。使用Spark SQL可以方便地进行数据清洗操作,并提供了多种函数与技巧来处理各种数据质量问题。
#### 3.1 数据异常值的识别与处理
在数据中,常常会存在异常值,即与大部分数据明显不符的值。异常值的存在可能会导致计算结果的不准确,因此需要进行识别和处理。
使用Spark SQL可以使用统计方法来识别异常值,例如计算数据的均值、方差等指标,然后通过设置阈值来判定是否为异常值。以下是使用Spark SQL进行异常值处理的示例代码:
```python
from pyspark.sql import SparkSession
from pyspark.sql.functions import stddev
# 创建SparkSession对象
spark = SparkSession.builder.appName("data_cleansing").getOrCreate()
# 读取数据
data = spark.read.csv("data.csv", header=True, inferSchema=True)
# 计算每列的标准差
stddev_data = data.select(stddev(data["column_name"]))
# 设置异常值阈值
threshold = 3 * stddev_data
# 过滤出异常值
outliers = data.filter(data["column_name"] > threshold)
# 删除异常值
clean_data = data.join(outliers, on=["column_name"], how="left_anti")
```
#### 3.2 缺失值的处理与填充
在数据中,缺失值是指某些字段或数据项的取值缺失或未被记录的情况。缺失值的存在会影响数据分析与建模的结果,因此需要进行填充处理。
使用Spark SQL可以使用fillna函数来填充缺失值,填充的策略可以是使用固定值、均值、中位数等。以下是使用Spark SQL进行缺失值处理的示例代码:
```python
from pyspark.sql import SparkSession
# 创建SparkSession对象
spark = SparkSession.builder.appName("data_cleansing").getOrCreate()
# 读取数据
data = spark.read.csv("data.csv", header=True, inferSchema=True)
# 填充缺失值
filled_data = data.fillna({"column_name": 0}) # 使用固定值填充缺失值
# 或者使用均值填充缺失值
mean_value = data.select(avg(data["column_name"])).collect()[0][0]
filled_data = data.fillna({"column_name": mean_value})
```
#### 3.3 数据重复值的识别与去重
数据中的重复值是指数据中存在完全相同或相似的多条记录。重复值的存在会导致数据分析和建模的偏差,因此需要进行识别和去重处理。
使用Spark SQL可以使用dropDuplicates函数来识别和删除重复值。以下是使用Spark SQL进行重复值处理的示例代码:
```python
from pyspark.sql import SparkSession
# 创建SparkSession对象
spark = SparkSession.builder.appName("data_cleansing").getOrCreate()
# 读取数据
data = spark.read.csv("data.csv", header=True, inferSchema=True)
# 识别重复值
duplicate_data = data.groupBy("column_name").count().filter("count > 1")
# 删
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏《Spark SQL》为读者介绍了Spark SQL的基本概念和功能,以帮助读者深入了解并掌握Spark SQL的使用技巧。专栏包含了多篇文章,从创建和操作DataFrame到使用SQL查询数据,从数据类型处理和转换到聚合函数的使用方法,从Join操作的最佳实践到窗口函数的应用与效益,从UDF和UDAF的编写与应用到数据分区和分桶等等。此外,专栏还探讨了索引优化、性能优化等方面的技巧和策略,在处理复杂的JSON数据和XML数据时提供了相关技术和解析方法。同时,专栏还介绍了字符串处理函数的最佳实践,以及使用Spark SQL进行数据清洗、规范化和时间序列数据处理与分析的方法。最后,专栏还介绍了Spark SQL中的机器学习库MLlib的应用,并分享如何在Spark SQL中进行数据可视化处理。通过阅读本专栏,读者将能够全面掌握Spark SQL的各项功能,并运用于实际项目中,提高数据处理和分析的效率。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【跨模块协同效应】:SAP MM与PP结合优化库存管理的5大策略

# 摘要
本文旨在探讨SAP MM(物料管理)和PP(生产计划)模块在库存管理中的核心应用与协同策略。首先介绍了库存管理的基础理论,重点阐述了SAP MM模块在材料管理和库存控制方面的作用,以及PP模块如何与库存管理紧密结合实现生产计划的优化。接着,文章分析了SAP MM与PP结合的协同策略,包括集成供应链管理和需求驱动的库存管理方法,以减少库存
【接口保护与电源管理】:RS232通信接口的维护与优化
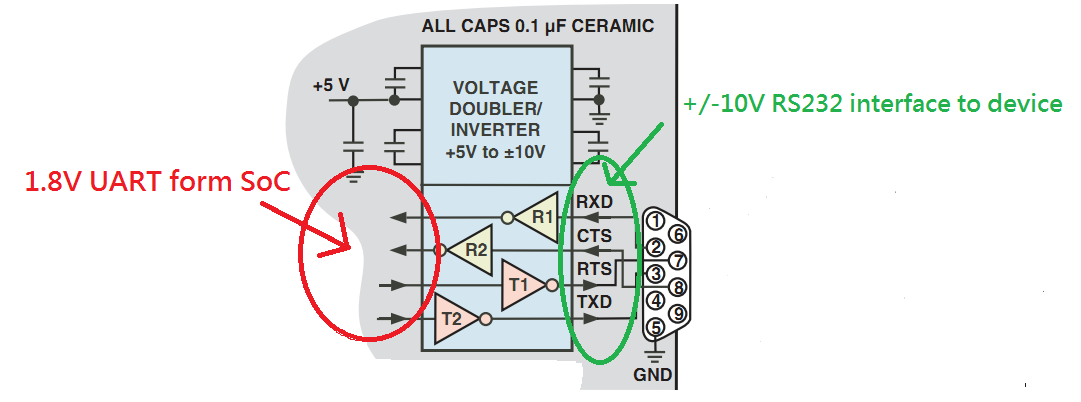
# 摘要
本文全面探讨了RS232通信接口的设计、保护策略、电源管理和优化实践。首先,概述了RS232的基本概念和电气特性,包括电压标准和物理连接方式。随后,文章详细分析了接口的保护措施,如静电和过电压防护、物理防护以及软件层面的错误检测机制。此外,探讨了电源管理技术,包括低功耗设计和远程通信设备的案例
零基础Pycharm教程:如何添加Pypi以外的源和库

# 摘要
Pycharm作为一款流行的Python集成开发环境(IDE),为开发人员提供了丰富的功能以提升工作效率和项目管理能力。本文从初识Pycharm开始,详细介绍了环境配置、自定义源与库安装、项目实战应用以及高级功能的使用技巧。通过系统地讲解Pycharm的安装、界面布局、版本控制集成,以及如何添加第三方源和手动安装第三方库,本文旨在帮助读者全面掌握Pycharm的使用,特
【ArcEngine进阶攻略】:实现高级功能与地图管理(专业技能提升)

# 摘要
本文深入介绍了ArcEngine的基本应用、地图管理与编辑、空间分析功能、网络和数据管理以及高级功能应用。首先,本文概述了ArcEngine的介绍和基础使用,然后详细探讨了地图管理和编辑的关键操作,如图层管理、高级编辑和样式设置。接着,文章着重分析了空间分析的基础理论和实际应用,包括缓冲区分析和网络分析。在此基础上,文章继续阐述了网络和数据库的基本操作
【VTK跨平台部署】:确保高性能与兼容性的秘诀

# 摘要
本文详细探讨了VTK(Visualization Toolkit)跨平台部署的关键方面。首先概述了VTK的基本架构和渲染引擎,然后分析了在不同操作系统间进行部署时面临的挑战和优势。接着,本文提供了一系列跨平台部署策略,包括环境准备、依赖管理、编译和优化以及应用分发。此外,通过高级跨平台功能的
函数内联的权衡:编译器优化的利与弊全解
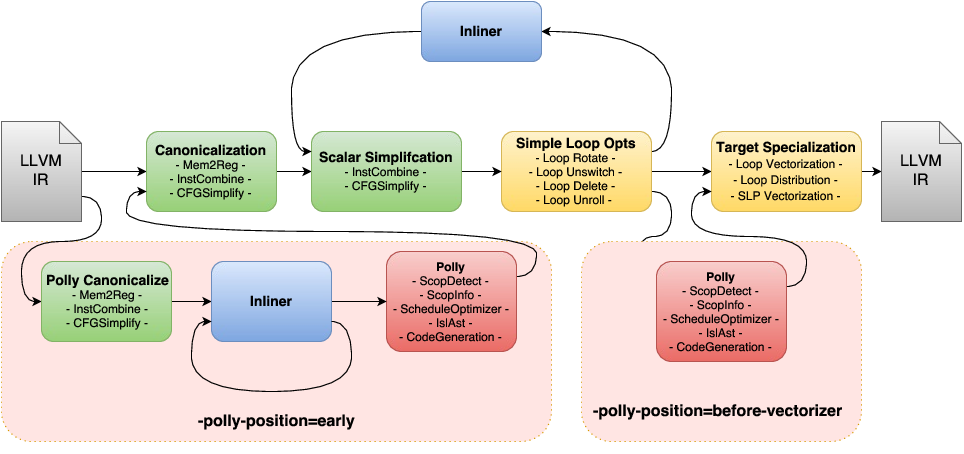
# 摘要
函数内联是编译技术中的一个优化手段,通过将函数调用替换为函数体本身来减少函数调用的开销,并有可能提高程序的执行效率。本文从基础理论到实践应用,全面介绍了函数内联的概念、工作机制以及与程序性能之间的关系。通过分析不同编译器的内联机制和优化选项,本文进一步探讨了函数内联在简单和复杂场景下的实际应用案例。同时,文章也对函数内联带来的优势和潜在风险进行了权衡分析,并给出了相关的优化技
【数据处理差异揭秘】

# 摘要
数据处理是一个涵盖从数据收集到数据分析和应用的广泛领域,对于支持决策过程和知识发现至关重要。本文综述了数据处理的基本概念和理论基础,并探讨了数据处理中的传统与现代技术手段。文章还分析了数据处理在实践应用中的工具和案例,尤其关注了金融与医疗健康行业中的数据处理实践。此外,本文展望了数据处理的未来趋势,包括人工智能、大数据、云计算、边缘计算和区块链技术如何塑造数据处理的未来。通过对数据治理和
C++安全编程:防范ASCII文件操作中的3个主要安全陷阱

# 摘要
本文全面介绍了C++安全编程的核心概念、ASCII文件操作基础以及面临的主要安全陷阱,并提供了一系列实用的安全编程实践指导。文章首先概述C++安全编程的重要性,随后深入探讨ASCII文件与二进制文件的区别、C++文件I/O操作原理和标准库中的文件处理方法。接着,重点分析了C++安全编程中的缓冲区溢出、格式化字符串漏洞和字符编码问题,提出相应的防范
时间序列自回归移动平均模型(ARMA)综合攻略:与S命令的完美结合
# 摘要
时间序列分析是理解和预测数据序列变化的关键技术,在多个领域如金融、环境科学和行为经济学中具有广泛的应用。本文首先介绍了时间序列分析的基础知识,特别是自回归移动平均(ARMA)模型的定义、组件和理论架构。随后,详细探讨了ARMA模型参数的估计、选择标准、模型平稳性检验,以及S命令语言在实现ARMA模型中的应用和案例分析。进一步,本文探讨了季节性ARMA模
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )