【lxml在Python项目中的实践】:集成与错误处理的终极指南
发布时间: 2024-10-05 23:09:43 阅读量: 3 订阅数: 4 

# 1. lxml库概览与安装
## lxml库简介
lxml是一个高性能的Python库,专门用于处理XML和HTML文档。它基于libxml2和libxslt库,提供了易于使用的API和丰富的功能,包括对XPath和XSLT的支持。lxml在速度和性能上都优于许多其他Python XML处理库,并且它非常灵活,支持Python对象模型,使其可以轻松集成到各种Python应用程序中。
## 安装lxml库
lxml库可通过Python的包管理工具pip进行安装。只需在终端或命令提示符中输入以下命令即可:
```shell
pip install lxml
```
该命令会从Python包索引(PyPI)下载lxml库及其依赖,并完成安装过程。
安装完成后,可以通过简单地尝试导入库来验证安装是否成功:
```python
import lxml.etree as ET
```
如果没有任何错误信息提示,则表示lxml库已经成功安装。如果遇到问题,请检查您的Python环境配置是否正确,或尝试安装依赖的库。
## lxml库版本更新和维护
lxml库一直在积极开发中,定期更新以修复bug和添加新功能。使用以下命令可以检查当前安装的版本,并且可以使用同样的方式来升级到最新版本:
```shell
pip install --upgrade lxml
```
开发者和贡献者会持续对lxml库进行维护,以确保其功能齐全且与最新标准兼容。对于在生产环境中使用lxml的开发者来说,定期更新库以利用性能改进和安全修复是一个好习惯。
# 2. lxml的基础元素和结构
## 2.1 lxml的基本组件
### 2.1.1 ElementTree对象模型
ElementTree 是 lxml 中用于处理 XML 和 HTML 文档的主要对象模型。它代表了整个文档,并提供了遍历和修改文档的方法。ElementTree 对象模型由三个主要的类组成:`ElementTree`、`Element` 和 `Comment`。
- **ElementTree** 代表整个文档树,提供了创建、写入和遍历文档的方法。
- **Element** 代表文档树中的单个节点,它是XML或HTML中的元素,拥有标签名、属性和子节点。
- **Comment** 用于表示文档中的注释,可以作为 `Element` 的子节点存在。
下面是一个使用 ElementTree 进行基本操作的示例代码:
```python
from lxml import etree
# 解析HTML文档
html_doc = """
<html>
<head>
<title>示例文档</title>
</head>
<body>
<h1>欢迎使用lxml</h1>
</body>
</html>
# 创建一个ElementTree对象
tree = etree.HTML(html_doc)
# 获取根节点
root = tree.getroot()
# 遍历子节点
for child in root:
print(child.tag) # 输出子节点的标签名
```
在这段代码中,首先导入 `lxml.etree` 模块,然后解析了一个简单的HTML文档,并获取了它的根节点。最后,代码遍历并打印了根节点的所有子节点的标签名。
### 2.1.2 XPath选择器的使用
XPath 是一种在 XML 文档中查找信息的语言,它允许用户定义选择节点的路径表达式。lxml 库支持使用 XPath 表达式来快速定位文档中的特定元素或属性。
```python
# 使用XPath选择第一个h1标签
h1_element = tree.xpath('//h1')[0]
# 打印h1元素的文本内容
print(h1_element.text) # 输出: 欢迎使用lxml
```
在这个例子中,`tree.xpath('//h1')` 返回了文档中所有 `<h1>` 标签的列表,然后我们通过索引访问列表中的第一个元素,并打印出它的文本内容。
## 2.2 lxml与HTML文档的解析
### 2.2.1 解析HTML文档的方法
lxml 支持两种方式解析 HTML 文档:
1. 使用 `etree.HTML()` 函数直接解析字符串形式的 HTML 内容。
2. 使用 `etree.parse()` 函数从文件对象中解析 HTML 文件。
使用 `etree.HTML()` 时,需要确保 HTML 字符串是完整的,并且没有格式错误。而使用 `etree.parse()` 则更适合解析存储在文件系统中的 HTML 文档。
### 2.2.2 常见的HTML元素处理技巧
处理 HTML 文档时,经常需要操作特定的元素,例如:
- 获取元素的属性值。
- 修改元素的文本内容。
- 插入新的元素或属性。
```python
# 获取并修改元素的属性值
a_tag = tree.xpath('//a')[0]
print(a_tag.get('href')) # 输出href属性的值
a_tag.set('href', '***') # 修改href属性的值
# 插入新元素
new_text = etree.Element('p')
new_text.text = '这是一个新段落。'
tree.getroot().append(new_text) # 添加到根节点下
```
## 2.3 lxml与XML文档的解析
### 2.3.1 解析XML文档的方法
解析 XML 文档与解析 HTML 文档的方法类似,但 XML 的严格性要求其结构更加规范。lxml 对 XML 文档的解析同样支持通过字符串和文件对象两种方式:
```python
# 解析字符串形式的XML文档
xml_doc = """
<root>
<element>内容</element>
</root>
xml_tree = etree.fromstring(xml_doc)
# 解析存储在文件中的XML文档
with open('example.xml', 'rb') as ***
***
```
### 2.3.2 XML命名空间的应用
XML 命名空间用于区分不同 XML 文档或 XML 元素中的同名元素。它通过在元素名前添加前缀来实现。
```python
# 使用命名空间前缀
namespaces = {'ns': '***'}
elements = tree.xpath('//ns:element', namespaces=namespaces)
```
在这个例子中,我们定义了一个命名空间字典 `namespaces`,并将前缀 'ns' 映射到了目标命名空间的 URL。在 XPath 表达式中使用这个前缀来指定我们想要选择的带命名空间的元素。
# 3. lxml的高级功能和性能优化
## 3.1 lxml的命名空间处理
### 3.1.1 命名空间的定义和应用
在处理XML或HTML文档时,命名空间是一个重要的概念,它允许我们在文档中使用相同名称的元素或属性,但来自不同的命名空间。命名空间在lxml中通常以字符串的形式表示,并且通过一个URL来唯一标识。
例如,若要处理包含多个命名空间的XML文档,可以按照以下步骤进行:
1. 创建一个包含命名空间的解析器。
2. 使用`register_namespace`方法注册命名空间。
3. 使用注册的命名空间在XPath查询中选择元素。
```python
from lxml import etree
# 创建一个命名空间映射
namespaces = {
"html": "***",
"math": "***"
}
# 解析一个带有命名空间的XML文档
xml_doc = etree.XML('<html:div xmlns:html="***"></html:div>')
# 使用XPath和命名空间获取元素
element = xml_doc.find(".//html:div", namespaces)
print(element.tag)
# 输出: {***}div
```
在上述代码中,我们首先定义了一个包含两个键值对的`namespaces`字典,其中一个键是命名空间的前缀,另一个是该命名空间的URL。然后我们使用`etree.XML`方法解析一个带有命名空间的XML字符串。最后,我们使用`find`方法结合XPath和命名空间字典来选取特定的元素。
### 3.1.2 避免命名空间冲突的策略
在处理包含多个命名空间的XML文档时,命名空间冲突是常见的问题。为了避免这些冲突,可以采取以下策略:
- 使用具体的命名空间前缀。在编写XPath查询时,使用具体的命名空间前缀来确保查询是针对正确的命名空间。
- 为每个元素创建独立的命名空间字典。如果一个XML文档中的元素属于不同的命名空间,为每个元素的查询创建独立的命名空间字典,可以避免冲突。
- 重命名冲突的元素。如果可能,修改文档中冲突元素的名称或命名空间,以确保它们在查询中是唯一的。
## 3.2 lxml的事件驱动处理
### 3.2.1 事件驱动模型的原理
事件驱动模型是一种程序设计模式,它依赖于事件的触发来驱动程序执行。在解析XML或HTML文档时,事件驱动模型允许开发者在解析过程中响应各种事件,比如开始标签、结束标签和文本节点等。
lxml库中的事件驱动处理是通过`lxml.etree.XMLParser`类来实现的,它允许开发者定义事件处理器,这些处理器会在解析过程中遇到相应的事件时被调用。事件处理可以用于生成新的XML文档、修改文档树结构、验证文档内容等。
### 3.2.2 lxml中的事件处理器实现
在lxml中,事件处理器是通过创建`lxml.etree.XMLParser`类的实例,并使用`events`参数定义需要处理的事件类型。然后,可以定义回调函数来响应这些事件。
```python
def start_element_handler(tag, attrib):
print(f"Start element: {tag} with attributes: {attrib}")
def end_element_handler(tag):
print(f"End element: {tag}")
from lxml import etree
# 创建带有事件处理的解析器
parser = etree.XMLParser(events=('start', 'end'))
# 解析文档并注册事件处理器
xml_doc = etree.parse("example.xml", parser)
# 这里会触发之前定义的start_element_handler和end_element_handler函数
```
在上述示例中,定义了两个事件处理器函数`start_element_handler`和`end_element_handler`。然后,创建了一个带有事件处理功能的解析器实例,并将其用于解析XML文档。当解析过程中遇到开始标签和结束标签时,相应的事件处理器会被自动调用。
## 3.3 lxml的内存和性能优化
### 3.3.1 内存使用的监控和优化
lxml库在解析大型文档时可

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python lxml 库的全面学习指南!本专栏深入探讨了 lxml 库,从基础知识到高级应用,帮助您提升 XML 处理能力。我们揭秘了 lxml 库的性能优化秘诀,并比较了 lxml 与 BeautifulSoup,为您提供选择合适解析器的最佳建议。通过内存管理和优化技术,您将学习如何提高 Python 数据处理效率。本专栏还提供了大规模数据处理的策略和案例研究,以及自定义 lxml 解析器的分步指南。此外,您将了解 lxml 在 Python 项目中的实践,包括集成和错误处理。我们还探索了 lxml 在网络爬虫中的应用,以及利用 XSLT 实现高级 XML 转换的技巧。最后,本专栏介绍了面向对象编程与 lxml 的结合,帮助您处理复杂的 XML 结构。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【数据探索的艺术】:Jupyter中的可视化分析与探索性处理技巧
# 1. 数据探索的艺术:Jupyter入门
## 1.1 数据探索的重要性
数据探索是数据分析过程中的核心环节,它涉及对数据集的初步调查,以识别数据集的模式、异常值、趋势以及数据之间的关联。良好的数据探索可以为后续的数据分析和建模工作打下坚实的基础,使分析人员能够更加高效地识别问题、验
【feedparser教育应用】:在教育中培养学生信息技术的先进方法
# 1. feedparser技术概览及教育应用背景
## 1.1 feedparser技术简介
Feedparser是一款用于解析RSS和Atom feeds的Python库,它能够处理不同来源的订阅内容,并将其统一格式化。其强大的解析功能不仅支持多种语言编码,还能够处理各种数据异
【Django代码质量】:URL配置测试与调试的高级策略
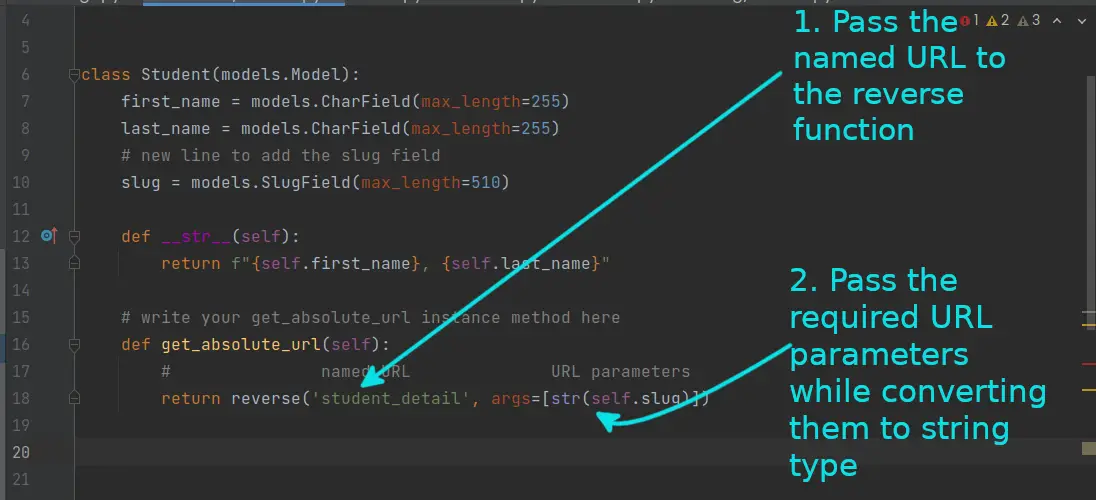
# 1. Django URL配置基础
Django框架中的URL配置是构建Web应用的基石,它涉及到将用户请求映射到对应的视图函数或类上。在本章节,我们将由浅入深地探讨如何在Django项目中设置和优化URL配置。
## Django URL配置概念
URL配置是通过Python字典
【揭秘pipenv锁文件】:安全依赖管理的新选择

# 1. pipenv简介与依赖管理
pipenv是Python开发人员广泛使用的依赖管理和虚拟环境管理工具。与传统的`pip`和`virtualenv`相比,pipenv提供了一个更加简洁和高效的依赖安装与管理机制。在本章中,我们将介绍pipenv的基本概念,以及如何使用它进行依赖管理,从而为Python项目的构建和部署打下坚实的基础。
## 1.1 pipenv的核心
httpie在自动化测试框架中的应用:提升测试效率与覆盖率

# 1. HTTPie简介与安装配置
## 1.1 HTTPie简介
HTTPie是一个用于命令行的HTTP客户端工具,它提供了一种简洁而直观的方式来发送HTTP请求。与传统的`curl`工具相比,HTTPie更易于使用,其输出也更加友好,使得开发者和测试工程师可以更加高效地进行API测试和调试。
## 1.2 安装
【App Engine微服务应用】:webapp.util模块在微服务架构中的角色
# 1. 微服务架构基础与App Engine概述
##
【Django国际化经验交流】:资深开发者分享django.utils.translation使用心得
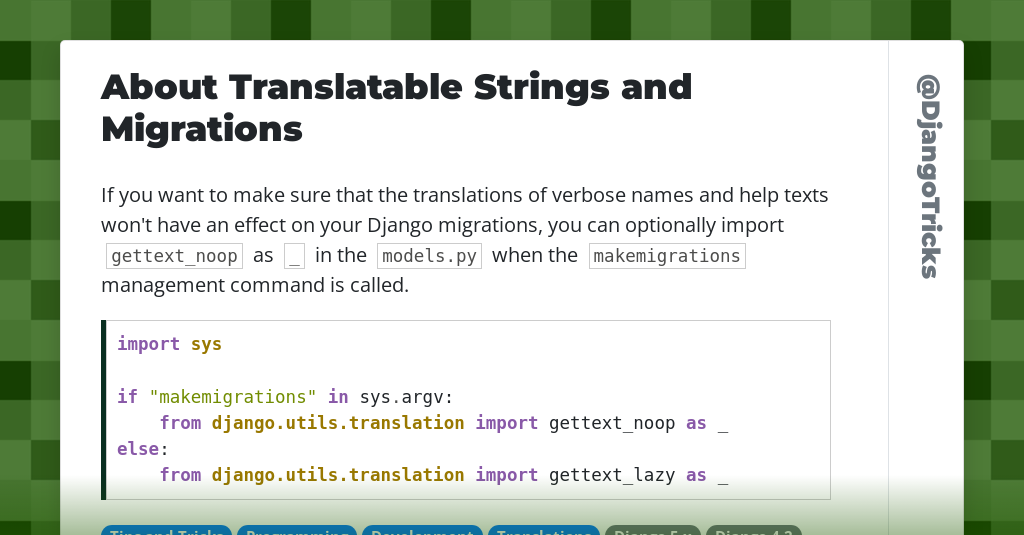
# 1. Django项目国际化概述
国际化(Internationalization),简称i18n,是指软件或网站等应用程序设计和实现过程中的支持多语言的过程。Django作为一个功能强大的Python Web框架,自然提供了一套完整的国际化解决方案,使得开发者能够轻松构建支持多种语言的Web应用。
## Django国际化的重要性
在
【lxml与数据库交互】:将XML数据无缝集成到数据库中

# 1. lxml库与XML数据解析基础
在当今的IT领域,数据处理是开发中的一个重要部分,尤其是在处理各种格式的数据文件时。XML(Extensible Markup Language)作为一种广泛使用的标记语言,其结构化数据在互联网上大量存在。对于数据科学家和开发人员来说,使用一种高效且功能强大的库来解析XML数据显得尤为重要。P
【XPath高级应用】:在Python中用xml.etree实现高级查询

# 1. XPath与XML基础
XPath是一种在XML文档中查找信息的语言,它提供了一种灵活且强大的方式来选择XML文档中的节点或节点集。XML(Extensible Markup Language)是一种标记语言,用于存储和传输数据。为了在Python中有效地使用XPath,首先需要了解XML文档的结构和XPath的基本语法。
## 1
定制你的用户代理字符串:Mechanize库在Python中的高级使用

# 1. Mechanize库与用户代理字符串概述
## 1.1 用户代理字符串的定义和重要性
用户代理字符串(User-Agent String)是一段向服务器标识客户浏览器特性的文本信息,它包含了浏览器的类型、版本、操作系统等信息。这些信息使得服务器能够识别请
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )