【源码打包工具大PK】:从Git到Docker的演变与选择
发布时间: 2024-12-15 21:18:11 阅读量: 8 订阅数: 18 

精选毕设项目-微笑话.zip
参考资源链接:[50套企业级网站源码打包下载 - ASP模板带后台](https://wenku.csdn.net/doc/1je8f7sz7k?spm=1055.2635.3001.10343)
# 1. 源码打包工具的演进历程
软件开发过程中,源码打包是不可或缺的一环,它负责将源代码编译、组装成可分发的应用程序包。在信息技术的长河中,源码打包工具的发展经历了数次重要的演进。
## 早期的打包方式
在上世纪九十年代,开发者主要依赖于脚本和简单的构建工具,如 Makefiles 来编译和打包软件。这种方式在处理复杂项目时显得力不从心,难以自动化和复用。
## 到Ant和Maven的变革
随着Java的普及,Ant和随后的Maven开始流行。这些工具引入了项目对象模型的概念,并提供了依赖管理功能,极大地提升了项目构建的效率和可维护性。
```xml
<!-- 示例:Maven的pom.xml文件 -->
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>com.example.app</groupId>
<artifactId>my-app</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.example</groupId>
<artifactId>library</artifactId>
<version>1.0</version>
</dependency>
</dependencies>
</project>
```
Maven的XML配置文件定义了项目的结构和依赖关系,支持自动化构建流程,如编译、测试、打包等。
## 进阶到现代构建工具
随着时间的发展,现代构建工具如Gradle和SBT的出现,它们提供了更加强大和灵活的构建特性,例如动态依赖管理和多语言支持,为复杂的项目构建提供了更有效的解决方案。
```groovy
// 示例:Gradle的build.gradle文件
apply plugin: 'java'
repositories {
mavenCentral()
}
dependencies {
testCompile 'junit:junit:4.12'
}
```
通过这些工具的演进,我们可以看到源码打包从手动操作到自动化、从单一语言支持到多语言支持的过程。在未来,我们可以预见源码打包工具会继续朝着智能化、自动化的方向发展。
# 2. Git版本控制与代码管理
## 2.1 Git的基本概念与原理
### 2.1.1 版本控制系统简介
版本控制系统(VCS)是软件开发中不可或缺的工具,它帮助团队成员管理代码的变更历史。在Git出现之前,CVS和Subversion(SVN)是广泛使用的集中式版本控制系统。这些系统集中存储代码版本在单一服务器上,团队成员通过检出和提交的方式来协作开发。
Git的出现改变了这一格局,它作为一个分布式版本控制系统(DVCS),允许开发者在本地计算机上拥有代码的完整副本。这意味着每个开发者都可以在自己的机器上独立工作,无需持续连接到中央服务器。这样的设计显著提高了工作效率,尤其是在网络不稳定或远程协作的场合。
Git的这种分布式工作方式还带来了更高的数据安全性。在集中式版本控制系统中,单点故障或服务器崩溃可能导致整个项目历史的丢失。而在Git中,即使中央仓库受损,团队成员也可以从任何一个克隆(clone)的副本中恢复。
### 2.1.2 Git的分布式架构
Git的核心架构基于其强大的数据模型,该模型使用一系列不可变的快照来记录项目历史。每个提交(commit)都包含了项目的完整状态,包括所有文件和目录。
在Git中,所有的版本控制操作几乎都在本地执行。这意味着大多数操作都极为迅速,比如提交更改、查看历史记录和比较不同版本之间的差异。当需要与他人共享更改时,开发者会将更改推送(push)到远程仓库或从远程仓库拉取(pull)更新。
这种架构赋予了Git极高的灵活性和扩展性。团队可以自由地在不同的工作流程中使用Git,无论是完全分布式的协作,还是利用中央仓库作为集成点的模式。
Git的分布式架构还促成了一个活跃的贡献者生态系统,围绕Git开发出多种工具和服务,如GitHub、GitLab和Bitbucket等,这些平台提供了代码托管、问题跟踪和协作等丰富的功能。
## 2.2 Git的工作流程与操作实践
### 2.2.1 常用的Git命令
Git提供了一系列命令来管理代码库。熟悉以下命令是每个使用Git的开发者的基础:
- `git init`:创建一个新的Git仓库。
- `git clone`:复制一个远程仓库到本地。
- `git add`:将文件更改加入到暂存区(staging area)。
- `git commit`:将暂存区的更改创建一个新的提交。
- `git push`:将本地更改推送到远程仓库。
- `git pull`:从远程仓库拉取最新的更改并合并到本地分支。
- `git checkout`:切换分支或恢复文件。
- `git merge`:将两个分支合并在一起。
- `git diff`:比较文件或分支之间的差异。
```bash
# 初始化仓库
git init
# 添加所有更改到暂存区并提交
git add .
git commit -m "Initial commit"
# 添加远程仓库并推送到远程master分支
git remote add origin https://example.com/repo.git
git push -u origin master
# 拉取远程更改到本地分支
git pull origin master
```
### 2.2.2 分支管理与合并策略
分支管理是Git协作中的核心概念。分支允许开发者在不同的功能或主题上独立工作,而不会影响主分支(通常是master或main)。
在Git中创建和管理分支是十分方便的:
- `git branch`:列出、创建和删除分支。
- `git checkout`:切换分支。
- `git merge`:将一个分支的更改合并到当前分支。
```bash
# 创建并切换到新分支
git checkout -b feature-branch
# 合并feature-branch分支到master分支
git checkout master
git merge feature-branch
# 如果需要解决合并冲突,可以在文本编辑器中打开冲突文件手动解决后继续
```
合并策略的选择也非常重要。Git提供了多种合并选项,如`--no-ff`用于创建合并提交,即使没有发生冲突也能保留分支历史。
### 2.2.3 代码审查和协作流程
代码审查是提高代码质量、分享知识和团队协作的重要过程。在Git中,可以使用Pull Requests(PR)或Merge Requests(MR)来请求审查并合并分支。
GitHub和GitLab等平台集成了PR/MR功能,它们允许团队成员在合并前进行详细的代码审查。审查者可以在提交更改的上下文中添加评论、批准更改或要求修改。
```mermaid
graph TD;
A[开始新分支] --> B[开发更改]
B --> C[提交更改]
C --> D[推送分支到远程仓库]
D --> E[创建Pull Request]
E --> F[在PR中进行讨论和审查]
F --> G[审查者批准PR]
G --> H[合并PR到目标分支]
```
## 2.3 Git的高级用法与技巧
### 2.3.1 钩子(Hooks)的使用
钩子(Hooks)是内嵌在Git中的脚本,它们会在特定的Git事件发生时触发。比如,在提交之前检查代码风格、在推送之前运行测试或者自动生成文档等。
钩子分为客户端钩子和服务器端钩子:
- 客户端钩子用于控制本地操作,如`pre-commit`钩子会在提交执行前运行。
- 服务器端钩子用于控制服务器上的操作,如`pre-receive`钩子用于在推送操作执行前检查推送。
```bash
# 示例:一个pre-commit钩子脚本,用于检查Python代码风格
#!/bin/sh
if git rev-parse --verify HEAD >/dev/null 2>&1
then
protected_branch="$(git symbolic-ref refs/remotes/origin/HEAD)"
if expr "$protected_branch" : 'refs/remotes/origin/master$' >/dev/null
then
exit 1
fi
fi
```
### 2.3.2 子模块(Submodules)与子树合并(Subtree Merging)
在大型项目中,经常会遇到需要将一个仓库作为另一个仓库的一部分来维护的情况。Git提供了两种机制:子模块和子树合并。
- 子模块允许你将一个Git仓库作为另一个仓库的子目录来管理,使得可以在不同的项目间共享代码。
- 子树合并则是一种将两个仓库合并为一个单一仓库的方法,它将一个仓库视为另一个仓库的子目录。
```bash
# 添加一个Git子模块
git submodule add https://example.com/other-repo.git modules/other-repo
# 更新子模块到新版本
git submodule update --remote
# 子树合并的示例
git remote add -f subtree https://example.com/other-repo.git
git merge -s ours --no-commit --allow-unrelated-histories subtree/master
git read-tree --prefix=modules/other-repo -u subtree/master
git commit -m "Merge subtree of other-repo"
```
### 2.3.3 大型仓库的性能优化
随着项目规模的增长,Git仓库可能会变得庞大和缓慢。优化Git仓库的性能是维护大型项目的关键。
- 将大文件从Git仓库中移除并使用Git LFS(Large File Storage)来跟踪。
- 使用浅克隆(shallow clone)来减少克隆时间。
- 定期运行`git gc`来优化仓库数据结构。
```bash
# 使用浅克隆获取仓库的最新状态
git clone --depth=1 https://example.com/repo.git
# 启用Git LFS并配置
git lfs install
git lfs track "*.psd"
# 清理Git对象并优化性能
git gc --prune=now --aggressive
```
这些高级技巧可以帮助开发者在使用Git时更高效地处理大型项目,确保版本控制流程的顺畅和高效。
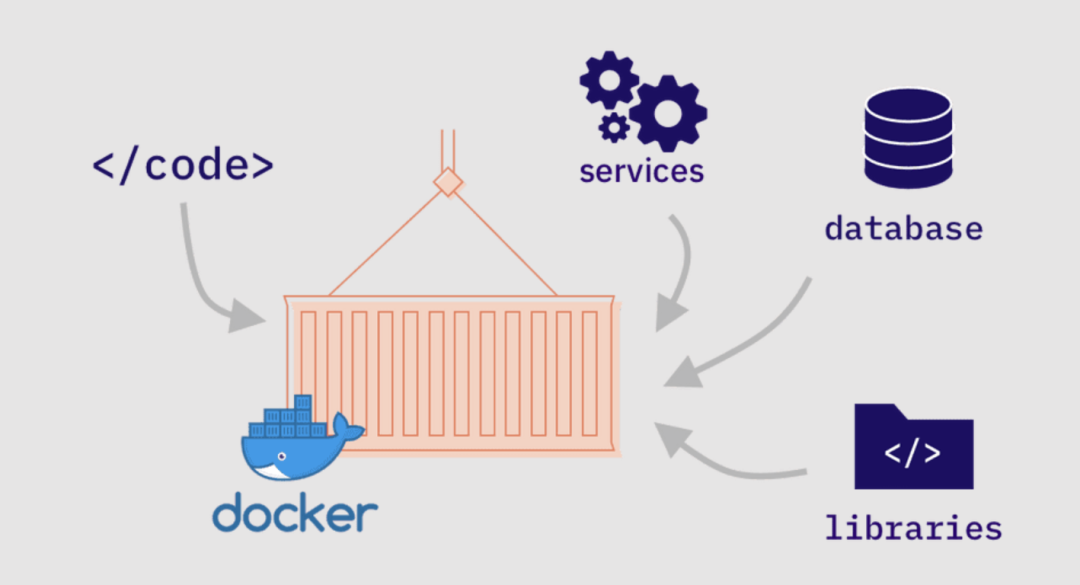
# 3. Docker容器技术与应用
## 3.1 Docker基础与容器概念
### 3.1.1 容器与虚拟机的对比
容器技术是一种轻量级的虚拟化技术,它与传统的虚拟机(VM)有着本质的区别。虚拟机依赖于虚拟硬件和完整的操作系统来实现隔离,而容器则是共享宿主机的操作系统内核,通过轻量级的隔离机制,运行独立的进程和应用。
容器的启动速度快,资源开销小,因为它们不需要启动一个完整的操作系统。此外,容器的可移植性也比虚拟机更高,因为它们不需要为不同的虚拟环境配置不同的驱动程序。Docker作为容器技术的代表,通过其容器引擎实现了高效的应用封装、分发和部署,成为了现代软件开发和运维中的核心工具。
### 3.1.2 Docker架构与组件
Docker的架构主要由以下几个组件构成:
- **Docker客户端与服务器(daemon)**:客户端通过发送指令与Docker守护进程交互,守护进程负责构建、运行和分发容器。通常使用`docker`命令作为客户端工具。
- **镜像(Image)**:是Docker构建容器的静态模板,包含了运行应用程序所需要的文件系统和配置信息。
- **容器(Container)**:是镜像的运行实例,可以通过Docker API或CLI(命令行接口)进行操作和管理。
- **仓库(Repository)**:用于存储和分发Docker镜像,可以是私有或者公开的,公开仓库如Docker Hub。
Docker利用Linux内核特性,如控制组(cgroups)和命名空间(namespaces),为每个容器提供独立的系统资源和隔离环境,使它们在宿主机上能够高效且安全地运行。
## 3.2 Docker镜像的创建与管理
### 3.2.1 Dockerfile基础
Dockerfile是一个文本文件,包含了所有构建Docker镜像所需的指令和说明。通过编写Dockerfile,开发者可以自定义镜像的创建过程,使得构建过程自动化并且可重复。一个基本的Dockerfile包含了以下几个核心指令:
- `FROM`:指定基础镜像,所有Dockerfile都会以`FROM`指令作为开始。
- `RUN`:执行命令,通常用于安装软件包和运行命令。
- `COPY`:复制本地文件到镜像中。
- `ADD`:与`COPY`相似,但可以处理远程URL和压缩文件。
- `CMD`:容器启动时执行的默认命令。
- `EXPOSE`:声明容器运行时监听的端口。
### 3.2.2 镜像构建与仓库管理
构建Docker镜像的过程是根据Dockerfile的指令序列逐步执行的,最终生成一个可以在任何支持Docker的环境中运行的镜像。可以通过`docker build`命令来构建镜像:
```bash
docker build -t myimage:tag .
```
构建完成后,可以使用`docker push`命令将镜像推送到Docker仓库中,如Docker Hub或其他私有仓库。
管理Docker镜像主要通过`docker images`和`docker rmi`命令进行。前者用于列出本地已有的镜像,后者用于删除镜像。
## 3.3 Docker网络与存储
### 3.3.1 容器网络配置
Docker提供了多种网络模式来满足不同的网络需求。Docker网络中的容器可以通过以下几种网络模式互相通信:
- **bridge**:默认的网络模式,容器之间通过桥接网络进行通信。
- **host**:容器使用宿主机的网络,无需额外配置。
- **overlay**:在多个Docker守护进程之间实现容器网络通信。
- **macvlan**:为每个容器分配一个MAC地址,让容器表现为宿主机网络上的物理设备。
网络配置通常在创建容器时通过`docker run`命令的`--network`参数指定。
### 3.3.2 数据持久化与卷管理
对于需要持久存储的数据,Docker支持多种卷管理机制:
- **绑定挂载(bind mounts)**:直接将宿主机目录挂载到容器中。
- **卷(volumes)**:由Docker管理的专门用于容器存储的数据卷。
- **tmpfs挂载(tmpfs mounts)**:仅存储在宿主机的内存中,适合存储临时数据。
使用`docker volume create`创建卷,并通过`docker run`命令的`-v`或`--mount`参数来挂载卷到容器中。
```bash
docker volume create mydata
docker run -v mydata:/data ...
```
数据卷不仅为数据持久化提供了便利,还支持数据备份、迁移和共享等操作。
# 4. 容器编排与自动化部署
## 4.1 Docker Compose的使用
### 4.1.1 Compose文件编写
Docker Compose是Docker的官方编排工具,它允许用户通过YAML文件来配置和定义应用的多容器Docker应用程序。通过一个单独的`docker-compose.yml`文件,可以定义一组相关的服务,从而简化多容器的配置和运行过程。该文件定义了项目的版本、服务、网络和卷。下面是一个基础的`docker-compose.yml`文件示例:
```yaml
version: '3'
services:
web:
image: nginx:alpine
ports:
- "80:80"
volumes:
- ./data:/usr/share/nginx/html
redis:
image: redis:alpine
```
在这个文件中,我们定义了两个服务:`web`和`redis`。`web`服务使用了`nginx:alpine`镜像,并映射了宿主机的80端口到容器的80端口。`redis`服务则使用了`redis:alpine`镜像。我们还在`web`服务中挂载了一个卷到`/usr/share/nginx/html`,以便我们可以在其中存储HTML内容。
编写`docker-compose.yml`文件时,要注意以下几点:
- **版本指定**:首先指定使用的Docker Compose文件版本,这决定了语法版本。
- **服务**:定义一个或多个服务,每个服务都包含用于运行容器的指令。
- **构建**:如果需要,可以在这里指定构建参数,如Dockerfile的路径。
- **环境**:定义环境变量,它们会被注入到容器中。
- **网络**:定义服务间的网络配置。
- **卷**:定义数据卷,用于持久化数据。
### 4.1.2 服务编排与管理
在`docker-compose.yml`文件编写完成后,就可以使用Docker Compose命令来管理服务了。例如,使用`docker-compose up`来启动所有服务,或者使用`docker-compose down`来停止并移除所有服务。
```bash
docker-compose up -d
```
这个命令会启动在`docker-compose.yml`文件中定义的所有服务,并且以分离模式运行(即在后台运行)。
在实际使用中,Docker Compose提供了丰富的子命令来管理服务,比如:
- `docker-compose start`:启动服务。
- `docker-compose stop`:停止服务。
- `docker-compose restart`:重启服务。
- `docker-compose ps`:列出运行的服务。
- `docker-compose logs`:查看服务的日志。
这些命令极大地简化了容器化应用的开发和测试工作流程,特别是对于涉及多个服务的应用。通过一个简单的`docker-compose.yml`文件,开发和运维人员可以快速地构建复杂的多容器环境。
## 4.2 Kubernetes基础与实践
### 4.2.1 Kubernetes架构概览
Kubernetes是一个开源的容器编排平台,它自动化了容器化应用的部署、扩展和管理过程。Kubernetes的设计思想是将一组容器构成一个单元来运行,这种单元被称为Pod。每个Pod可以包含一个或多个容器,它们共享存储、网络以及它们的配置。
Kubernetes架构由多个组件组成,主要分为Master节点和Worker节点:
- **Master节点**:负责整个集群的管理和决策,主要组件包括:
- API Server:集群管理的API入口。
- Scheduler:调度器,负责分配Pod到合适的Node上。
- Controller Manager:运行控制器进程。
- etcd:分布式键值存储,存储所有集群数据。
- **Worker节点**:运行用户的Pod,每个节点上都有以下组件:
- Kubelet:负责Node节点上Pod的创建、启停等任务。
- Kube-Proxy:负责Node内部的网络通信。
- Container Runtime:如Docker或Containerd,负责运行容器。
Kubernetes通过声明式API来管理应用的生命周期。开发者或运维人员通过定义一个期望状态,然后Kubernetes会使用各种控制器来确保当前状态与期望状态一致。
### 4.2.2 Pod、Service和Deployment
在Kubernetes中,Pod是应用的最小部署单位。每个Pod都由一个或多个容器组成,这些容器共享存储、网络和配置。Pod的设计理念是“一次性和不可变”,这意味着一旦创建了Pod,就不能更改其配置,如果需要更新或扩缩,就需要创建新的Pod。
**Service**是Kubernetes的一个抽象概念,用于定义一组Pod的访问策略。通过Service,可以实现网络上的服务发现和负载均衡。Service通过标签选择器将流量路由到Pods。
**Deployment**则是一种更高级别的抽象,它管理Pod和ReplicaSets。ReplicaSet确保一定数量的Pod副本在任何时刻都可用,而Deployment则提供声明式更新来Pods和ReplicaSets。
在部署一个简单的应用时,可能需要创建以下资源:
1. **Deployment**:定义应用的Pod模板和副本数量。
2. **Service**:定义一个稳定的网络端点,以便其他服务或外部访问。
3. **ConfigMap**和**Secrets**:存储配置信息和敏感信息。
例如,部署一个Nginx服务并暴露端口可以通过以下命令完成:
```bash
kubectl run nginx --image=nginx:alpine --port=80 --expose
```
或者通过一个声明性的`nginx-deployment.yml`文件:
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:alpine
ports:
- containerPort: 80
```
然后使用`kubectl apply -f nginx-deployment.yml`命令来应用该配置文件。
### 4.2.3 部署和扩展应用
部署和扩展应用是Kubernetes的核心功能之一。开发者和运维人员可以使用Deployment来声明性地更新应用。例如,滚动更新(rolling updates)是一个持续部署新版本Pod的过程,同时确保至少一部分旧版本的Pod仍然运行,以保证服务的可用性。
扩展应用可以通过更改ReplicaSet的副本数量来完成,这样Kubernetes的自动缩放器会根据负载自动调整Pod的数量:
```bash
kubectl scale deployment nginx-deployment --replicas=5
```
这个命令将会将`nginx-deployment`的副本数扩展到5个。Kubernetes提供了自动缩放功能,可以基于CPU利用率或其他度量来动态调整Pod数量。
为了确保应用的高可用性,Kubernetes支持多种类型的负载均衡:
- **ClusterIP**:在集群内部访问的Service类型。
- **NodePort**:通过静态端口在所有节点上访问的Service。
- **LoadBalancer**:外部负载均衡器访问的Service,常用于云环境。
通过将Service类型设置为LoadBalancer,可以自动创建一个云供应商的负载均衡器,并将流量转发到你的服务:
```yaml
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
type: LoadBalancer
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
```
应用这个配置文件将创建一个负载均衡器,外部流量可以通过这个负载均衡器访问到Nginx服务。
## 4.3 持续集成与持续部署(CI/CD)
### 4.3.1 CI/CD的概念与价值
持续集成(CI)和持续部署(CD)是现代软件开发中经常提及的术语,它们是DevOps实践的核心部分。CI指的是开发人员频繁地将代码集成到共享仓库中,通常每个成员至少每天进行一次提交,每次提交都会通过自动化的构建和测试来验证,从而尽早地发现集成错误。
CD通常指的是持续部署和持续交付。持续部署指的是自动将代码更改部署到生产环境,而持续交付指的是确保软件在生产环境中可用,但部署是由人工触发的。
CI/CD的价值在于:
- **加速反馈循环**:快速发现和修复错误。
- **减少集成问题**:频繁地集成减少了集成问题的复杂性。
- **自动化和一致性**:确保开发过程的一致性和可重复性。
- **提高部署频率**:可以更频繁地向用户交付更新。
### 4.3.2 Jenkins、GitLab CI等工具集成
实现CI/CD自动化的一种方式是使用Jenkins、GitLab CI等工具。这些工具提供了广泛的插件和定制功能,可以帮助自动化测试、构建、部署等过程。
以**Jenkins**为例,这是一个开源的自动化服务器,可以用来自动化各种任务,包括构建、测试和部署软件。通过Jenkins Pipeline,可以编写一个自动化的工作流程,定义从代码检出到测试再到部署的整个过程。
```groovy
pipeline {
agent any
stages {
stage('Checkout') {
steps {
checkout scm
}
}
stage('Test') {
steps {
sh 'make check'
junit 'reports/**/*.xml'
}
}
stage('Build') {
steps {
sh 'make build'
}
}
stage('Deploy') {
when { branch 'master' }
steps {
sh './deploy.sh'
}
}
}
}
```
在上面的Jenkins Pipeline脚本中,定义了一个从检出代码到测试、构建再到部署的过程。
**GitLab CI**是另一个流行的工具,它与GitLab紧密集成。每个项目都可以有一个`.gitlab-ci.yml`文件,用来定义自动化的测试、构建和部署流程。例如:
```yaml
stages:
- build
- test
- deploy
build_job:
stage: build
script:
- make build
test_job:
stage: test
script:
- make test
deploy_job:
stage: deploy
script:
- make deploy
only:
- master
```
在这个配置中,定义了三个阶段:构建、测试和部署。每个阶段都有自己的作业,并且`deploy_job`只在`master`分支上运行。
通过这些工具和配置,CI/CD流程可以高度自动化,大大加快了软件开发和交付的速度,同时保持了高质量和稳定性。
# 5. 源码打包工具的选择与比较
在当今IT行业,软件交付速度和应用可靠性对于企业的竞争力有着直接的影响。为了优化开发流程,各种源码打包工具应运而生,它们扮演着至关重要的角色。本章将从不同角度对源码打包工具的选择和比较进行深入探讨,帮助读者理解不同场景下的工具选择考量,了解工具集成与生态体系的重要性,并对安全性、稳定性和维护性进行分析。
## 5.1 不同场景下的工具选择
软件开发团队的规模、项目需求和工作流都会影响对源码打包工具的选择。开发者需要根据实际业务需求来决定最适合的工具。
### 5.1.1 小型团队与大型企业的需求差异
小型团队通常寻求轻量级、易于配置的打包工具,以便快速上手,集中精力于产品开发而非工具管理。例如,`npm`对于JavaScript项目的快速打包就是一个很好的选择。
在大型企业中,需求更加复杂,可能涉及多个团队协同工作。这时,更需要的是一个能够提供企业级支持、高度可扩展、并且有强大社区支持的工具。比如,`Maven`和`Gradle`是Java领域中常用的构建工具,它们支持大型项目的构建管理并可以配置复杂的依赖关系。
### 5.1.2 性能与可扩展性考量
在选择打包工具时,性能与可扩展性是不可忽视的因素。例如,`Webpack`为JavaScript项目提供模块打包功能,随着项目复杂性的增加,其性能和可扩展性依然可以满足需求。
对于大型应用,需要考虑工具的并发处理能力和并行构建性能。`Bazel`是由Google开发的构建工具,支持高度的并行执行,有利于缩短大型项目构建时间。
## 5.2 工具集成与生态体系
工具链的构建对于提高开发效率和软件质量至关重要,而工具链中的每个环节都需要与生态系统中其他工具良好集成。
### 5.2.1 工具链的构建与优化
理想中,一个源码打包工具应该能够和版本控制系统、代码审查工具、持续集成/持续部署(CI/CD)平台等无缝集成,形成一个统一的开发工作流。
以`Docker`为例,它不仅仅是一个容器化工具,还可以与`Kubernetes`、`Jenkins`等工具集成,为构建、部署和运行应用提供完整的工作流支持。
### 5.2.2 社区支持与插件生态
一个活跃的社区以及丰富的插件生态可以极大增强工具的功能性和易用性。开发者社区是新技术发展和知识传播的重要推手。例如,`Ansible`社区提供了大量的自动化脚本和模块,使得自动化部署更加灵活和高效。
插件或扩展是让工具适应不断变化需求的关键。`Visual Studio Code`拥有一个庞大的插件市场,支持开发者根据需要添加语言支持、调试工具和其他功能。
## 5.3 安全性、稳定性和维护性分析
安全性、稳定性和维护性是影响源码打包工具长期使用的关键因素,它们直接关系到软件的交付效率和质量。
### 5.3.1 安全漏洞与风险管理
随着技术的发展,新的安全漏洞被不断发现。选择一个安全性高的打包工具可以降低潜在风险。`OWASP`定期发布的安全漏洞报告是了解和防范工具安全漏洞的重要资源。
对于已知漏洞,工具的维护者需要提供及时的安全补丁,而用户也需要关注安全更新并及时升级。例如,`npm`和`yarn`这类的包管理器会频繁发布安全更新,用户应通过自动化工具定期检查和更新依赖。
### 5.3.2 更新维护与技术支持
打包工具的维护状况和社区活跃度是评估其长期可用性的重要指标。一个活跃的社区意味着有更多的贡献者参与工具的改进,也意味着技术问题能够得到及时解答。
企业用户还应考虑厂商提供的技术支持和定制化服务。例如,`IBM UrbanCode`这类企业级部署工具,通常提供专业的客户服务和技术支持。
以上内容展示了源码打包工具在不同使用场景中的选择考量,工具集成与生态体系的重要性,以及安全性、稳定性和维护性分析。通过本章节的讨论,我们希望读者能够更加深入地了解如何在实际开发中根据需求选择合适的打包工具,实现项目的高效和安全交付。
# 6. 未来趋势与技术展望
随着技术的快速发展,软件开发和部署正在经历一系列的变革。云原生和DevOps的概念逐渐深入人心,自动化和智能化在软件交付中的角色越来越重要。本章节将探索这些未来趋势与技术的走向,并为技术人员提供适应未来挑战的策略。
## 6.1 云原生与DevOps的融合
### 6.1.1 云原生概念的发展
云原生技术是构建和运行应用程序的一套最佳实践,它们利用云平台的优势,如可伸缩性、弹性、可观测性等。云原生的发展与云计算的发展密切相关,从最初的虚拟化技术到现在的容器化、微服务架构,以及服务网格和服务发现机制,云原生技术不断演进以支持大规模分布式系统的构建和运行。
### 6.1.2 DevOps文化在实践中的变革
DevOps是一种文化理念,旨在打破开发(Dev)和运维(Ops)之间的壁垒,通过流程、自动化和紧密的协作提高软件交付的速度和质量。随着云原生技术的融入,DevOps实践也发生了变化,例如引入了基础设施即代码(IaC)、持续部署、蓝绿部署和金丝雀发布等模式。这些实践不仅提升了效率,还加强了软件的稳定性和可靠性。
## 6.2 持续学习与适应新技术
### 6.2.1 技术人员的学习路径
在技术不断演变的时代,持续学习成为技术人员的必修课。学习路径应当包括基础知识的巩固、新兴技术的跟进、实际项目经验的积累以及与同行的交流和分享。掌握学习资源如在线课程、技术文档、开源项目和专业论坛,以及参加行业会议和技术研讨会,都是提升个人技术水平的有效方法。
### 6.2.2 适应未来技术的策略与方法
适应新技术需要策略性的规划,这包括了解市场趋势、评估技术的适用性和成熟度、以及为团队成员提供相应的培训和资源。同时,技术团队应保持敏捷性,快速响应技术变革,采用实验性的方法测试新技术的实际效用。实践证明,从原型开发到小范围试点,逐步扩展新技术的应用,可以有效降低风险。
## 6.3 源码打包与交付的未来方向
### 6.3.1 自动化与智能化的趋势
未来,源码打包和交付过程将更加自动化和智能化。自动化测试、自动化的代码审查、自动化的部署和运维将成为常态。智能化工具将能够基于历史数据预测部署风险,并提供最优的部署策略。机器学习算法在这一过程中扮演着越来越重要的角色,帮助自动化系统做出更精确的决策。
### 6.3.2 新兴技术如Serverless的融合可能性
Serverless架构提供了按需计算的能力,用户无需关心服务器的管理工作,而是专注于编写和部署业务逻辑代码。在源码打包与交付领域,Serverless技术将为按需构建、测试和部署提供新的可能性。开发者可以利用Serverless构建函数或微服务,集成到CI/CD流程中,实现更灵活、更低成本的交付模式。
本章介绍了当前技术发展的新趋势,强调了云原生和DevOps融合带来的变化,提出了适应新技术的策略,并探讨了源码打包与交付技术的未来方向。技术人员需要对这些变革保持敏感,并不断学习新技术,以便能够有效地利用这些工具和方法,为未来的挑战做好准备。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了企业网站源码打包的最佳实践,旨在帮助企业提升部署效率、优化开发流程并确保代码质量。从全方位的指南到构建可扩展打包系统的智慧,专栏涵盖了源码打包的各个方面。它提供了性能提升策略、多环境应用管理技巧、质量保证措施、持续集成集成、依赖管理、文档编写、代码优化以及源码打包与版本控制的协同策略。通过遵循这些最佳实践,企业可以实现无缝协作、快速部署和可扩展的打包系统,从而为规模化部署奠定坚实基础。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
FANUC宏程序的自定义功能:扩展命令与创建个性化指令的技巧
# 摘要
本论文首先对FANUC宏程序的基础知识进行了概述,随后深入探讨了宏程序中扩展命令的原理,包括其与标准命令的区别、自定义扩展命令的开发流程和实例分析。接着,论文详细介绍了如何创建个性化的宏程序指令,包括设计理念、实现技术手段以及测试与优化方法。第四章讨论了宏程序的高级应用技巧,涉及错误处理、模块化与代码复用,以及与FANUC系统的集成。最后,论文探讨了宏程序的维护与管理问题,包括版本控制、文档化和知识管理,并对FANUC宏程序在先进企业的实践案例进行了分析,展望了技术的未来发展趋势。
# 关键字
FANUC宏程序;扩展命令;个性化指令;错误处理;模块化;代码复用;维护管理;技术趋势
【集成电路设计标准解析】:IEEE Standard 91-1984在IC设计中的作用与实践
# 摘要
本文系统性地解读了IEEE Standard 91-1984标准,并探讨了其在集成电路(IC)设计领域内的应用实践。首先,本文介绍了集成电路设计的基础知识和该标准产生的背景及其重要性。随后,文章详细分析了标准内容,包括设计流程、文档要求以及测试验证规定,并讨论了标准对提高设计可靠性和规范化的作用。在应用实践方面,本文探讨了标准化在设计流程、文档管理和测试验证中的实施,以及它如何应对现代IC设计中的挑战与机遇。文章通过案例研究展示了标准在不同IC项目中的应用情况,并分析了成功案例与挑战应对。最后,本文总结了标准在IC设计中的历史贡献和现实价值,并对未来集成电路设计标准的发展趋势进行了展
【中间件使用】:招行外汇数据爬取的稳定与高效解决方案
# 摘要
本文旨在探究外汇数据爬取技术及其在招商银行的实际应用。第一章简要介绍了中间件技术,为后续章节的数据爬取实践打下理论基础。第二章详细阐述了外汇数据爬取的基本原理和流程,同时分析了中间件在数据爬取过程中的关键作用及其优势。第三章通过招商银行外汇数据爬取实践,讨论了中间件的选择、配置以及爬虫稳定性与效率的优化方法。第四章探讨了分布式爬虫设计与数据存储处理的高级应用,
【带宽管理,轻松搞定】:DH-NVR816-128网络流量优化方案
# 摘要
本文对DH-NVR816-128网络流量优化进行了系统性的探讨。首先概述了网络流量的理论基础,涵盖了网络流量的定义、特性、波动模式以及网络带宽管理的基本原理和性能指标评估方法。随后,文章详细介绍了DH-NVR816-128设备的配置和优化实践,包括设备功能、流量优化设置及其在实际案例中的应用效果。文章第四章进一步探讨
easysite缓存策略:4招提升网站响应速度

# 摘要
网站响应速度对于用户体验和网站性能至关重要。本文探讨了缓存机制的基础理论及其在提升网站性能方面的作用,包括缓存的定义、缓存策略的原理、数据和应用缓存技术等。通过分析easysite的实际应用案例,文章详细阐述了缓存策略的实施步骤、效果评估以及监控方法。最后,本文还展望了缓存策略的未来发展趋势和面临的挑战,包括新兴缓存技术的应用以及云计算环境下缓存策略的创新,同时关注缓存策略实施过程中的安全性问
Impinj用户权限管理:打造强大多级权限系统的5个步骤
# 摘要
本文对Impinj权限管理系统进行了全面的概述与分析,强调了权限系统设计原则的重要性并详细介绍了Impinj权限模型的构建。通过深入探讨角色与权限的分配方法、权限继承机制以及多级权限系统的实现策略,本文为实现高效的权限控制提供了理论与实践相结合的方法。文章还涉及了权限管理在
北斗用户终端的设计考量:BD420007-2015协议的性能评估与设计要点
# 摘要
北斗用户终端作为北斗卫星导航系统的重要组成部分,其性能和设计对确保终端有效运行至关重要。本文首先概述了北斗用户终端的基本概念和特点,随后深入分析了BD420007-2015协议的理论基础,包括其结构、功能模块以及性能指标。在用户终端设计方面,文章详细探讨了硬件和软件架构设计要点,以及用户界面设计的重要性。此外,本文还对BD420007-2015协议进行了性能评估实践,搭建了测试环境,采用了基准测试和场景模拟等方法论,提出了基于评估结果的优化建议。最后,文章分析了北斗用户终端在不同场景下的应用,并展望了未来的技术创新趋势和市场发展策略。
# 关键字
北斗用户终端;BD420007-2
DS8178扫描枪图像处理秘籍:如何获得最清晰的扫描图像

# 摘要
本文全面介绍了图像处理的基础知识,聚焦DS8178扫描枪的硬件设置、优化与图像处理实践。文章首先概述了图像处理的基础和DS8178扫描枪的特性。其次,深入探讨了硬件设置、环境配置和校准方法,确保扫描枪的性能发挥。第三章详述了图像预处理与增强技术,包括噪声去除、对比度调整和色彩调整,以及图像质量评估方法。第四章结合实际应用案例,展示了如何优化扫描图像的分辨率和使用高级图像处理技术。最后,第五章介绍了
SW3518S芯片电源设计挑战:解决策略与行业最佳实践

# 摘要
本文综述了SW3518S芯片的电源设计理论基础和面临的挑战,提供了解决方案以及行业最佳实践。文章首先介绍了SW3518S芯片的电气特性和电源管理策略,然后着重分析了电源设计中的散热难题、能源转换效率和电磁兼容性问题。通过对实际案例的
批量安装一键搞定:PowerShell在Windows Server 2016网卡驱动安装中的应用

# 摘要
本文详细探讨了PowerShell在Windows Server环境中的应用,特别是在网卡驱动安装和管理方面的功能和优势。第一章概括了PowerShell的基本概念及其在Windows Server中的核心作用。第二章深入分析了网卡驱动安装的需求、挑战以及PowerShell自动
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )