树结构入门:二叉树的定义与遍历
发布时间: 2024-03-04 10:40:28 阅读量: 38 订阅数: 30 
# 1. 引言
## 1.1 什么是树结构
树(Tree)是一种抽象数据类型或数据结构,模拟具有树状结构特点的数据组织模型。它是由n(n>=1)个有限节点组成一个具有层次关系的集合。它具有以下特点:
- 每个节点有零个或多个子节点;
- 没有父节点的节点称为根节点;
- 每一个非根节点有且只有一个父节点;
- 除了根节点外,每个子节点可以分为多个不相交的子树。
树结构在计算机科学领域有着广泛的应用,例如文件系统、数据库索引、图形界面控件等。
## 1.2 为什么学习树结构
树结构是一种重要的数据结构,具有以下优点:
- 适合用来组织具有层次关系的数据,如组织架构、家谱等;
- 可以提高数据操作的效率,例如在数据库中使用树结构索引可以加快查询速度;
- 在算法设计中有着重要的应用,如树的遍历、搜索、排序等。
因此,学习树结构对于理解数据的组织与处理,以及算法设计与优化都具有重要意义。
## 1.3 二叉树作为树结构的代表
在树结构中,二叉树是一种最基本且常见的形式。二叉树的每个节点最多有两个子节点,分别称为左子节点和右子节点。由于其简单性和广泛应用性,二叉树常常作为树结构的代表来进行讲解和研究。
接下来,我们将深入学习二叉树的定义、遍历、应用等相关内容。
# 2. 二叉树的定义
二叉树是一种非常常见且重要的树结构,它由节点组成,每个节点最多有两个子节点,分别为左子节点和右子节点。在二叉树中,左子节点小于父节点,右子节点大于父节点,这种性质使得二叉树非常适合用于实现搜索和排序功能。
#### 2.1 二叉树概述
二叉树是一种特殊的树结构,其节点最多只能有两个子节点。空树也是二叉树。二叉树的子树也是二叉树。
#### 2.2 二叉树的基本性质
- 性质1:二叉树的第i层最多有2^(i-1)个节点(i>0)。
- 性质2:深度为k的二叉树最多有2^k - 1个节点(k>0)。
- 性质3:对于任意一棵二叉树,如果其叶节点数为n0,度数为2的节点数为n2,则n0 = n2 + 1。
- 性质4:具有n个节点的完全二叉树的深度为 log~2~(n + 1)向下取整。
#### 2.3 二叉树的节点定义
在编程中,通常会定义一个二叉树节点类,包含节点值和左右子节点的引用。
```java
class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) { val = x; }
}
```
#### 2.4 二叉树与数组、链表的关系
二叉树可以通过数组或链表来实现。对于数组实现,可以通过下标来表示节点间的父子关系。对于链表实现,每个节点包含左右子节点的引用。不同的实现方式适用于不同的场景,需要根据实际问题选择合适的数据结构来表示二叉树。
希望这样的输出对你有所帮助,如果需要的话,我可以继续输出其他章节的内容。
# 3. 二叉树的遍历
二叉树的遍历是指按照某种顺序访问树中的所有节点,分为前序遍历、中序遍历、后序遍历和层次遍历四种方式。下面将详细介绍这四种遍历方式的定义和实现。
#### 3.1 前序遍历
前序遍历按照"根左右"的顺序访问节点,即先访问根节点,然后按照前序遍历的方式递归访问左子树和右子树。
```python
# Python 代码示例
class TreeNode:
def __init__(self, value):
self.val = value
self.left = None
self.right = None
def preorderTraversal(root):
if not root:
return []
result = []
result.append(root.val)
result += preorderTraversal(root.left)
result += preorderTraversal(root.right)
return result
```
#### 3.2 中序遍历
中序遍历按照"左根右"的顺序访问节点,即先按照中序遍历的方式递归访问左子树,然后访问根节点,最后按照中序遍历的方式递归访问右子树。
```java
// Java 代码示例
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> result = new ArrayList<>();
if(root != null) {
result.addAll(inorderTraversal(root.left));
result.add(root.val);
result.addAll(inorderTraversal(root.right));
}
return result;
}
```
#### 3.3 后序遍历
后序遍历按照"左右根"的顺序访问节点,即先按照后序遍历的方式递归访问左子树,然后按照后序遍历的方式递归访问右子树,最后访问根节点。
```go
// Go 代码示例
func postorderTraversal(root *TreeNode) []int {
var result []int
if root != nil {
result = append(result, postorderTraversal(root.Left)...)
result = append(result, postorderTraversal(root.Right)...)
result = append(result, root.Val)
}
return result
}
```
#### 3.4 层次遍历
层次遍历按照从上到下、从左到右的顺序逐层访问节点。
```javascript
// JavaScript 代码示例
function levelOrder(root) {
let result = [];
if (!root) {
return result;
}
let queue = [root];
while (queue.length) {
let level = [];
let len = queue.length;
for (let i = 0; i < len; i++) {
let node = queue.shift();
level.push(node.val);
if (node.left) {
queue.push(node.left);
}
if (node.right) {
queue.push(node.right);
}
}
result.push(level);
}
return result;
}
```
以上是四种常用的二叉树遍历方式的定义和实现,它们在实际编程中具有重要的应用价值。
# 4. 二叉树遍历算法及其实现
在这一章中,我们将深入探讨二叉树的遍历算法以及它们的实现方式。二叉树的遍历是对树中所有节点进行访问的过程,常见的遍历方式包括前序遍历、中序遍历、后序遍历和层次遍历。针对每种遍历方式,我们将介绍其递归算法和迭代算法,并附上实际的代码示例。
#### 4.1 递归算法
递归是最直观的二叉树遍历方法之一。对于前序遍历、中序遍历和后序遍历,递归算法的实现相对简单,并且易于理解。以下是一个用Python实现的二叉树前序遍历的示例代码:
```python
# 定义二叉树节点
class TreeNode:
def __init__(self, val=0, left=None, right=None):
self.val = val
self.left = left
self.right = right
# 前序遍历函数
def preorderTraversal(root):
if root:
print(root.val) # 访问当前节点
preorderTraversal(root.left) # 递归遍历左子树
preorderTraversal(root.right) # 递归遍历右子树
# 构建二叉树
root = TreeNode(1)
root.left = TreeNode(2)
root.right = TreeNode(3)
root.left.left = TreeNode(4)
root.left.right = TreeNode(5)
# 执行前序遍历
preorderTraversal(root)
```
#### 4.2 迭代算法
与递归算法相比,迭代算法通常使用栈或队列来辅助实现二叉树的遍历,这在一些情况下能够提高性能并减少内存消耗。以下是一个用Java实现的二叉树中序遍历的示例代码:
```java
// 定义二叉树节点
class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) { val = x; }
}
// 中序遍历函数
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
Stack<TreeNode> stack = new Stack<>();
TreeNode curr = root;
while (curr != null || !stack.isEmpty()) {
while (curr != null) {
stack.push(curr);
curr = curr.left;
}
curr = stack.pop();
res.add(curr.val);
curr = curr.right;
}
return res;
}
// 构建二叉树
TreeNode root = new TreeNode(1);
root.left = new TreeNode(2);
root.right = new TreeNode(3);
root.left.left = new TreeNode(4);
root.left.right = new TreeNode(5);
// 执行中序遍历
List<Integer> result = inorderTraversal(root);
System.out.println(result);
```
#### 4.3 实际代码示例
以上是关于二叉树遍历的递归和迭代算法的简单示例,实际应用中可以根据具体情况选择合适的遍历方式。递归算法通常更直观易懂,而迭代算法常常更高效。在编写二叉树遍历代码时,可以根据实际需求灵活选择合适的方法进行实现。
# 5. 二叉树在程序设计中的应用
二叉树作为一种重要的数据结构,在程序设计中有着广泛的应用。下面将介绍一些常见的应用场景及实现方法。
### 5.1 二叉搜索树
#### 5.1.1 定义
二叉搜索树(Binary Search Tree,BST)是一种特殊的二叉树,对于每个节点,其左子树中的所有节点值小于该节点,右子树中的所有节点值大于该节点。
#### 5.1.2 实现
```python
class TreeNode:
def __init__(self, val=0, left=None, right=None):
self.val = val
self.left = left
self.right = right
class BST:
def __init__(self):
self.root = None
def insert(self, val):
if not self.root:
self.root = TreeNode(val)
else:
self._insert(self.root, val)
def _insert(self, node, val):
if val < node.val:
if not node.left:
node.left = TreeNode(val)
else:
self._insert(node.left, val)
else:
if not node.right:
node.right = TreeNode(val)
else:
self._insert(node.right, val)
```
#### 5.1.3 总结
二叉搜索树的插入操作时间复杂度为O(logN),其中N为树的节点个数。但如果树高度不平衡,最坏情况下可能退化为链表,时间复杂度会退化为O(N)。
### 5.2 平衡二叉树
#### 5.2.1 定义
平衡二叉树(Balanced Binary Tree)是一种二叉搜索树,其任意节点的两棵子树的高度差不超过1。
#### 5.2.2 实现
```java
class TreeNode {
int val;
TreeNode left;
TreeNode right;
int height;
TreeNode(int val) {
this.val = val;
this.height = 1;
}
}
class AVLTree {
TreeNode root;
// AVL树的插入、旋转等操作
}
```
#### 5.2.3 总结
平衡二叉树通过旋转操作,保持树的平衡,从而提高了插入、删除等操作的效率。但相比普通二叉搜索树,实现相对复杂。
### 5.3 堆
#### 5.3.1 定义
堆(Heap)是一种特殊的树形数据结构,通常用于实现优先队列。堆分为最大堆和最小堆,最大堆保证父节点的值大于等于子节点,最小堆保证父节点的值小于等于子节点。
#### 5.3.2 实现
```javascript
class MaxHeap {
constructor() {
this.heap = [];
}
insert(value) {
this.heap.push(value);
this._heapifyUp();
}
_heapifyUp() {
// 上浮操作
}
extractMax() {
// 弹出最大值
}
}
```
#### 5.3.3 总结
堆常用于实现优先队列等场景,插入、删除操作的时间复杂度为O(logN),获取最值的时间复杂度为O(1)。
### 5.4 应用示例
在实际应用中,二叉树结构可以用于实现数据的快速查找、排序等操作。比如在数据库索引、图形图像处理等领域都有广泛应用。
以上是二叉树在程序设计中的部分应用,通过合适的场景选择合适的二叉树结构,可以提高代码的效率和性能。
# 6. 其他树结构及扩展阅读
树结构作为一种重要的数据结构,在计算机科学领域有着广泛的应用。除了二叉树之外,还有许多其他类型的树结构,它们在不同的场景下发挥着重要作用。
#### 6.1 多路树
多路树是一种每个节点可以拥有多个子节点的树结构。常见的多路树包括二叉树、三叉树、四叉树等。多路树在一些特定的应用场景中具有独特的优势,例如四叉树常用于图像处理领域,用于实现二维空间数据的高效存储和检索。
#### 6.2 B树、B+
树
B树和B+树是一种平衡的多路搜索树,通常用于数据库和文件系统中。它们能够保持数据有序,并且能够进行快速的查找、插入和删除操作,是许多存储系统的核心数据结构。
#### 6.3 红黑树
红黑树是一种自平衡的二叉搜索树,它保持了较好的平衡性能,能够在动态更新的过程中自我调整以保持树的平衡。红黑树被广泛应用于C++ STL中的map和set等容器中,保证了高效的插入、删除和查找操作。
#### 6.4 其他常见树结构的介绍
除了上述提到的树结构外,还有许多其他常见的树结构,如AVL树、伸展树、Trie树等。它们在不同的应用领域都有着重要的作用,例如Trie树常用于实现高效的字符串检索和前缀匹配。
这些树结构在实际的程序设计中发挥着重要作用,对它们的深入理解能够帮助我们更好地解决各种实际问题。如果你对树结构感兴趣,推荐阅读《算法导论》等经典教材,深入学习相关的数据结构与算法知识。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【ACC自适应巡航软件功能规范】:揭秘设计理念与实现路径,引领行业新标准

# 摘要
自适应巡航控制(ACC)系统作为先进的驾驶辅助系统之一,其设计理念在于提高行车安全性和驾驶舒适性。本文从ACC系统的概述出发,详细探讨了其设计理念与框架,包括系统的设计目标、原则、创新要点及系统架构。关键技术如传感器融合和算法优化也被着重解析。通过介绍ACC软件的功能模块开发、测试验证和人机交互设计,本文详述了系统的实现
敏捷开发与DevOps的融合之道:软件开发流程的高效实践

# 摘要
敏捷开发与DevOps是现代软件工程中的关键实践,它们推动了从开发到运维的快速迭代和紧密协作。本文深入解析了敏捷开发的核心实践和价值观,探讨了DevOps的实践框架及其在自动化、持续集成和监控等方面的应用。同时,文章还分析了敏捷开发与DevOps的融合策略,包括集成模式、跨功能团队构建和敏捷DevOps文化的培养。通过案例分析,本文提供了实施敏捷DevOps的实用技巧和策略
【汇川ES630P伺服驱动器终极指南】:全面覆盖安装、故障诊断与优化策略
# 摘要
汇川ES630P伺服驱动器是工业自动化领域中先进的伺服驱动产品,它拥有卓越的基本特性和广泛的应用领域。本文从概述ES630P伺服驱动器的基础特性入手,详细介绍了其主要应用行业以及与其他伺服驱动器的对比。进一步,探讨了ES630P伺服驱动
AutoCAD VBA项目实操揭秘:掌握开发流程的10个关键步骤
# 摘要
本文旨在全面介绍AutoCAD VBA的基础知识、开发环境搭建、项目实战构建、编程深入分析以及性能优化与调试。文章首先概述AutoCAD VBA的基本概念和开发环境,然后通过项目实战方式,指导读者如何从零开始构建AutoCAD VBA应用。文章深入探讨了VBA编程的高级技巧,包括对象模型、类模块的应用以及代码优化和错误处理。最后,文章提供了性能优化和调试的方法,并
NYASM最新功能大揭秘:彻底释放你的开发潜力
# 摘要
NYASM是一个功能强大的汇编语言工具,支持多种高级编程特性并具备良好的模块化编程支持。本文首先对NYASM的安装配置进行了概述,并介绍了其基础与进阶语法。接着,本文探讨了NYASM在系统编程、嵌入式开发以及安全领域的多种应用场景。文章还分享了NYASM的高级编程技巧、性能调优方法以及最佳实践,并对调试和测试进行了深入讨论。最后,本文展望了NYASM的未来发展方向,强调了其与现代技
ICCAP高级分析:挖掘IC深层特性的专家指南
# 摘要
本文全面介绍了ICCAP的理论基础、实践应用及高级分析技巧,并对其未来发展趋势进行了展望。首先,文章介绍了ICCAP的基本概念和基础知识,随后深入探讨了ICCAP软件的架构、运行机制以及IC模型的建立和分析方法。在实践应用章节,本文详细阐述了ICCAP在IC参数提取和设计优化中的具体应用,包括方法步骤和案例分析。此外,还介绍了ICCAP的脚本编程技巧和故障诊断排除方法。最后,文章预测了ICCAP在物联网和人工智能
【Minitab单因子方差分析】:零基础到专家的进阶路径
# 摘要
本文详细介绍了Minitab单因子方差分析的各个方面。第一章概览了单因子方差分析的基本概念和用途。第二章深入探讨了理论基础,包括方差分析的原理、数学模型、假设检验以及单因子方差分析的类型和特点。第三章则转向实践操作,涵盖了Minitab界面介绍、数据分析步骤、结果解读和报告输出。第四章讨论了高级应用,如多重比较、方差齐性检验及案例研究。第五章关注在应用单因子方差分析时可能
FTTR部署实战:LinkHome APP用户场景优化的终极指南
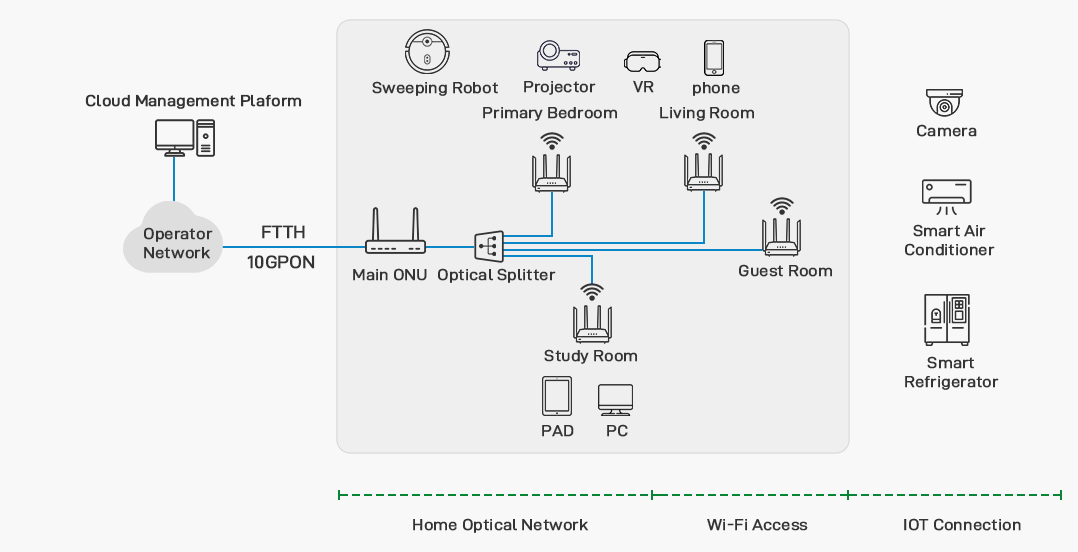
# 摘要
本论文首先介绍了FTTR(Fiber To The Room)技术的基本概念及其背景,以及LinkHome APP的概况和功能。随后详细阐述了在FTTR部署前需要进行的准备工作,包括评估网络环境与硬件需求、分析LinkHome APP的功能适配性,以及进行预部署测试与问题排查。重点介绍了FTTR与LinkHome APP集成的实践,涵盖了用户场景配置、网络环境部署实施,以及网络性能监
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )