【C语言编译器开发实战】:打造个性化编译器工具链
发布时间: 2024-10-02 02:31:30 阅读量: 23 订阅数: 46 

集成开发C语言编译器:Code::Blocks

# 1. C语言编译器开发概述
## 1.1 C语言编译器的重要性
C语言作为编程世界中的经典语言,其编译器开发不仅涉及技术的深度,也是对程序设计语言理论的实践检验。在理解编译器如何将源代码转换为机器代码的过程中,我们可以更深入地理解计算机的工作原理和编程语言的设计哲学。
## 1.2 编译器的基本工作流程
一个典型的C语言编译器由多个阶段组成,包括预处理、编译、汇编和链接。编译阶段是核心,它又细分为词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成。
## 1.3 编译器开发的关键挑战
开发一个高性能的C语言编译器需要面对诸如代码生成效率、优化程度、跨平台兼容性等诸多挑战。这些挑战不仅需要深厚的理论知识,还需要灵活应用现代编程技术,以实现高效、稳定、可移植的编译器。
以上内容仅为第一章内容概述,每节内容都涉及了编译器开发的入门级概念,为后续章节深入讨论前端、后端以及高级话题等奠定基础。随着章节深入,我们将会逐一剖析编译器各个部分的实现细节和优化策略。
# 2. 编译器前端理论与实践
## 2.1 词法分析与扫描器
### 2.1.1 词法单元的定义和作用
词法分析是编译过程中的首要步骤,负责将源代码的字符序列转换成有意义的词法单元序列,这些词法单元又被称为“tokens”。每个token代表了程序中的一个词法单元,如关键字、标识符、字面量、运算符等。词法单元的定义是编译器前端处理的基础,直接影响到后续的语法分析阶段。
例如,在C语言中,关键字`int`、标识符`main`、分号`;`以及括号`()`都被视为不同的tokens。词法单元的作用包括:
- 确定程序的结构
- 提供语法分析的输入
- 隔离错误,便于后续处理
在词法分析中,扫描器(scanner)或词法分析器(lexer)根据预定义的词法规则(通常以正则表达式或类似的形式给出)来识别这些tokens。这一步骤对于编译器来说至关重要,因为只有正确的识别了程序的构造块,才能进一步解析程序的语法结构。
### 2.1.2 构建简单的扫描器实例
下面是一个简单的C语言扫描器实例,该实例使用正则表达式来匹配不同的tokens。这里使用伪代码来展示基本的构建过程:
```c
// 伪代码展示一个简单的词法分析器
function Scanner(source) {
this.source = source;
this.tokens = [];
this.currentPosition = 0;
this.length = source.length;
this.scan();
return this.tokens;
}
function scan() {
while (this.currentPosition < this.length) {
// 跳过空白字符
if (isWhitespace(this.currentChar())) {
this.currentPosition++;
continue;
}
// 检查是否是数字,如果是则处理为字面量
if (isDigit(this.currentChar())) {
this.tokens.push(this.processNumber());
continue;
}
// 检查是否是标识符
if (isIdentifier(this.currentChar())) {
this.tokens.push(this.processIdentifier());
continue;
}
// 其他情况
// ...
}
}
// 示例:处理数字的函数
function processNumber() {
let value = '';
while (this.currentPosition < this.length && isDigit(this.currentChar())) {
value += this.currentChar();
this.currentPosition++;
}
return { type: 'NUMBER', value: value };
}
// 其他辅助函数...
```
此伪代码展示了扫描器如何从源代码字符串中识别并生成tokens。每个token都有一个类型,如`NUMBER`、`IDENTIFIER`、`KEYWORD`等,并且可能有与之相关的值,比如标识符或字面量的值。
在实际的应用中,扫描器的构建会涉及到词法单元的详细分类和正则表达式的应用,复杂的编译器甚至会使用专门的工具如`flex`来生成扫描器。
## 2.2 语法分析与解析器
### 2.2.1 上下文无关文法的基础
语法分析阶段是编译器前端的一个核心环节,它根据词法分析器提供的tokens来构建程序的语法结构,即抽象语法树(AST)。这一阶段依赖于上下文无关文法(Context-Free Grammar, CFG)来描述程序的语法结构。
CFG由一组产生式(productions)组成,每个产生式描述了语言结构中的一种规则。产生式的左边是一个非终结符(non-terminal),右边是一系列的非终结符和终结符(terminals)的组合。例如,一个简单的表达式语法可能包含如下的产生式:
```
E -> E + T
E -> T
T -> T * F
T -> F
F -> ( E )
F -> id
```
其中`E`、`T`和`F`是非终结符,`+`、`*`、`(`、`)`和`id`是终结符。
### 2.2.2 解析器的设计与实现
解析器根据CFG来分析tokens流,并根据产生式规则构建出AST。解析器可分为自顶向下和自底向上两种策略。自顶向下的解析器从文法的起始符号开始,尝试匹配输入中的tokens。自底向上的解析器则从tokens开始,尝试归约到文法的起始符号。
在实现解析器时,经常使用递归下降解析(Recursive Descent Parsing)或者LL、LR解析算法等。下面展示了一个简单的递归下降解析器的伪代码:
```c
// 递归下降解析器伪代码
function parseExpression() {
parseTerm();
if (currentToken == '+') {
eat('+');
parseExpression();
}
}
function parseTerm() {
parseFactor();
if (currentToken == '*') {
eat('*');
parseTerm();
}
}
function parseFactor() {
if (currentToken == '(') {
eat('(');
parseExpression();
eat(')');
} else {
// match id or number
}
}
function eat(expectedToken) {
if (currentToken == expectedToken) {
currentToken = getNextToken();
} else {
// 引发错误处理逻辑
}
}
```
在这段伪代码中,`parseExpression`、`parseTerm`和`parseFactor`函数递归调用以匹配表达式的产生式规则,并构建出AST。`eat`函数用于消费掉已经匹配的tokens,并获取下一个token。
解析器的设计与实现是编译器开发中的一个难点,它需要精确的文法定义以及对可能出现的各种语法歧义的处理。
## 2.3 语义分析与符号表
### 2.3.1 语义规则的理解与应用
语义分析阶段是在语法分析的基础上,对程序的语义进行检查,确保程序符合语言定义的语义规则。这一阶段检查的规则包括但不限于:
- 类型一致性检查,如运算符和操作数的类型匹配
- 声明前的使用检查,确保所有变量都先声明再使用
- 作用域规则,如变量的可见性和生命周期
- 控制流检查,如确保所有的路径都有返回值(对于需要返回值的函数)
语义分析的结果是最终的AST,并可能伴随着符号表的更新,符号表记录了变量、函数等实体的声明信息。
### 2.3.2 符号表的结构设计与管理
符号表是编译器中的一个重要数据结构,用于存储程序中定义和引用的所有名字及其属性信息。设计良好的符号表对于编译器的性能至关重要。符号表通常以哈希表或平衡树等数据结构实现,以确保高效的查找和插入操作。
符号表在编译器的不同阶段被频繁地查询和更新。例如,在语义分析阶段,每当遇到一个新的名字声明时,编

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探究 C 语言编译器的内部运作机制,从源代码到可执行文件的转换过程。它涵盖了编译器前端的关键步骤,包括词法分析、语法分析、语义分析和中间表示生成。还探讨了编译器后端的技术,例如代码优化、代码生成和目标机器代码优化。此外,该专栏还介绍了编译器开发、错误处理、性能调优和扩展性的实践方面。通过深入了解 C 语言编译器的各个方面,读者将获得对编译器设计和实现的全面理解,并能够构建自己的定制编译器工具链。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【电子打印小票的前端实现】:用Electron和Vue实现无缝打印

# 摘要
电子打印小票作为商业交易中不可或缺的一部分,其需求分析和实现对于提升用户体验和商业效率具有重要意义。本文首先介绍了电子打印小票的概念,接着深入探讨了Electron和Vue.js两种前端技术的基础知识及其优势,阐述了如何将这两者结合,以实现高效、响应
【EPLAN Fluid精通秘籍】:基础到高级技巧全覆盖,助你成为行业专家
# 摘要
EPLAN Fluid是针对工程设计的专业软件,旨在提高管道和仪表图(P&ID)的设计效率与质量。本文首先介绍了EPLAN Fluid的基本概念、安装流程以及用户界面的熟悉方法。随后,详细阐述了软件的基本操作,包括绘图工具的使用、项目结构管理以及自动化功能的应用。进一步地,本文通过实例分析,探讨了在复杂项目中如何进行规划实施、设计技巧的运用和数据的高效管理。此外,文章还涉及了高级优化技巧,包括性能调优和高级项目管理策略。最后,本文展望了EPLAN Fluid的未来版本特性及在智能制造中的应用趋势,为工业设计人员提供了全面的技术指南和未来发展方向。
# 关键字
EPLAN Fluid
小红书企业号认证优势大公开:为何认证是品牌成功的关键一步
# 摘要
小红书企业号认证是品牌在小红书平台上的官方标识,代表了企业的权威性和可信度。本文概述了小红书企业号的市场地位和用户画像,分析了企业号与个人账号的区别及其市场意义,并详细解读了认证过程与要求。文章进一步探讨了企业号认证带来的优势,包括提升品牌权威性、拓展功能权限以及商业合作的机会。接着,文章提出了企业号认证后的运营策略,如内容营销、用户互动和数据分析优化。通过对成功认证案例的研究,评估
【用例图与图书馆管理系统的用户交互】:打造直观界面的关键策略
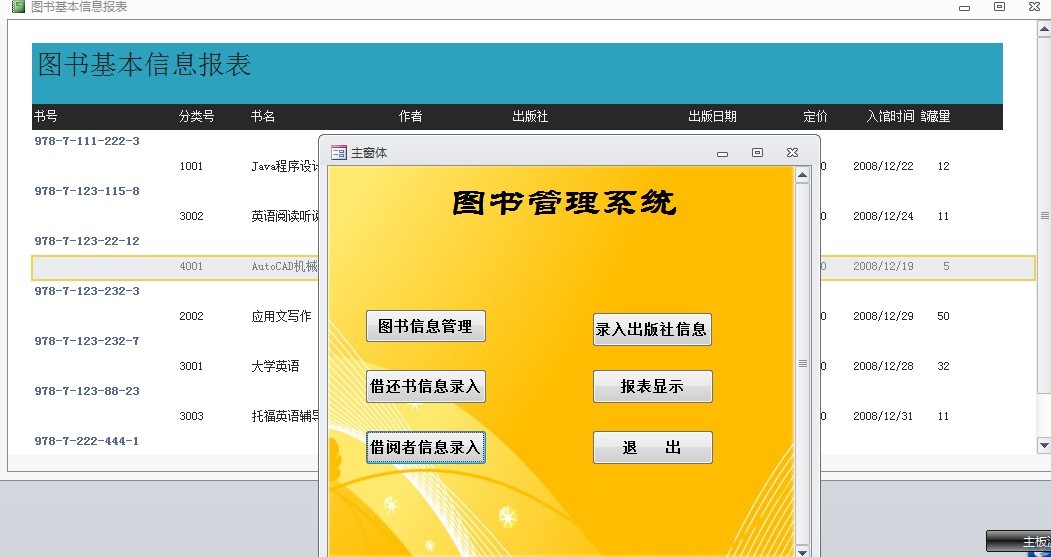
# 摘要
本文旨在探讨用例图在图书馆管理系统设计中的应用,从基础理论到实际应用进行了全面分析。第一章概述了用例图与图书馆管理系统的相关性。第二章详细介绍了用例图的理论基础、绘制方法及优化过程,强调了其在系统分析和设计中的作用。第三章则集中于用户交互设计原则和实现,包括用户界面布局、交互流程设计以及反馈机制。第四章具体阐述了用例图在功能模块划分、用户体验设计以及系统测试中的应用。
FANUC面板按键深度解析:揭秘操作效率提升的关键操作
# 摘要
FANUC面板按键作为工业控制中常见的输入设备,其功能的概述与设计原理对于提高操作效率、确保系统可靠性及用户体验至关重要。本文系统地介绍了FANUC面板按键的设计原理,包括按键布局的人机工程学应用、触觉反馈机制以及电气与机械结构设计。同时,本文也探讨了按键操作技巧、自定义功能设置以及错误处理和维护策略。在应用层面,文章分析了面板按键在教育培训、自动化集成和特殊行业中的优化策略。最后,本文展望了按键未来发展趋势,如人工智能、机器学习、可穿戴技术及远程操作的整合,以及通过案例研究和实战演练来提升实际操作效率和性能调优。
# 关键字
FANUC面板按键;人机工程学;触觉反馈;电气机械结构
华为SUN2000-(33KTL, 40KTL) MODBUS接口安全性分析与防护

# 摘要
本文深入探讨了MODBUS协议在现代工业通信中的基础及应用背景,重点关注SUN2000-(33KTL, 40KTL)设备的MODBUS接口及其安全性。文章首先介绍了MODBUS协议的基础知识和安全性理论,包括安全机制、常见安全威胁、攻击类型、加密技术和认证方法。接着,文章转入实践,分析了部署在SUN2
【高速数据传输】:PRBS的优势与5个应对策略

# 摘要
本文旨在探讨高速数据传输的背景、理论基础、常见问题及其实践策略。首先介绍了高速数据传输的基本概念和背景,然后详细分析了伪随机二进制序列(PRBS)的理论基础及其在数据传输中的优势。文中还探讨了在高速数据传输过程中可能遇到的问题,例如信号衰减、干扰、传输延迟、带宽限制和同步问题,并提供了相应的解决方案。接着,文章提出了一系列实际应用策略,包括PRBS测试、信号处理技术和高效编码技术。最后,通过案例分析,本文展示了PRBS在
【GC4663传感器应用:提升系统性能的秘诀】:案例分析与实战技巧
# 摘要
GC4663传感器是一种先进的检测设备,广泛应用于工业自动化和科研实验领域。本文首先概述了GC4663传感器的基本情况,随后详细介绍了其理论基础,包括工作原理、技术参数、数据采集机制、性能指标如精度、分辨率、响应时间和稳定性。接着,本文分析了GC4663传感器在系统性能优化中的关键作用,包括性能监控、数据处理、系统调优策略。此外,本文还探讨了GC4663传感器在硬件集成、软件接口编程、维护和故障排除方面的
NUMECA并行计算工程应用案例:揭秘性能优化的幕后英雄
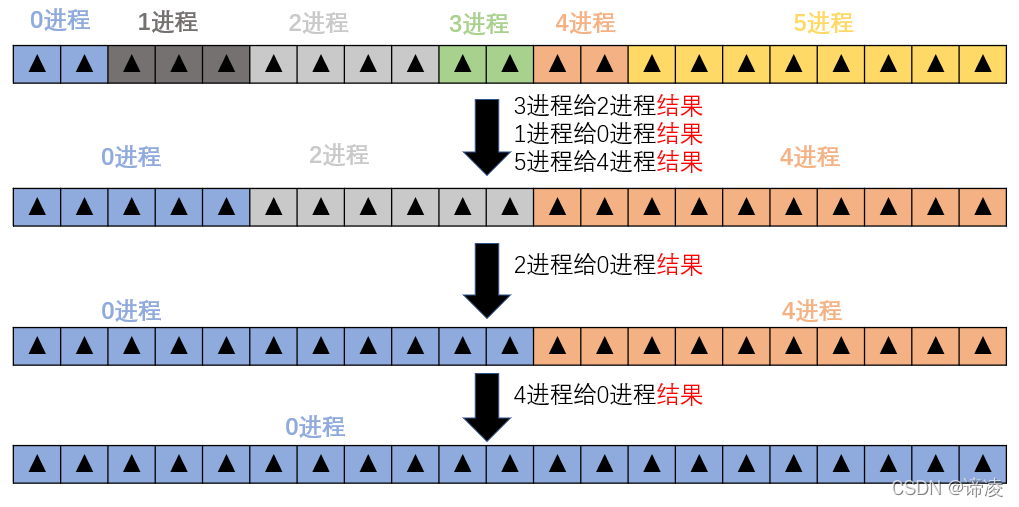
# 摘要
本文全面介绍NUMECA软件在并行计算领域的应用与实践,涵盖并行计算基础理论、软件架构、性能优化理论基础、实践操作、案例工程应用分析,以及并行计算在行业中的应用前景和知识拓展。通过探
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )