构建灵活的测试套件:pytest-selenium的fixture机制
发布时间: 2024-01-05 04:21:59 阅读量: 45 订阅数: 48 

pytest+selenium UI自動化實例練習
# 1. 介绍pytest-selenium测试框架
## 1.1 pytest-selenium的特点和优势
pytest-selenium是一个基于pytest框架的Selenium测试插件,它提供了一系列方便的功能来简化Web应用程序的UI测试。pytest-selenium具有以下特点和优势:
- **灵活性和可扩展性**:结合了pytest的灵活性和Selenium的功能,为测试提供了很大的灵活性和可扩展性。
- **简洁的语法**:利用pytest的简洁语法编写测试用例,易于阅读和维护。
- **丰富的fixture支持**:pytest-selenium提供了丰富的fixture支持,可以方便地进行测试环境的配置和数据准备。
- **并行执行测试**:pytest框架本身支持多线程和分布式执行测试,结合pytest-selenium可以实现并行执行Web UI测试。
## 1.2 pytest-selenium的安装和基本配置
要开始使用pytest-selenium,首先需要安装pytest和pytest-selenium插件。可以通过pip来进行安装:
```bash
pip install pytest pytest-selenium
```
安装完成后,可以使用pytest命令来运行测试。同时,在编写测试用例时,可以利用pytest-selenium提供的fixture来进行基本配置,例如配置浏览器驱动和URL等。接下来我们将在第三章中详细介绍如何利用fixture进行Selenium测试环境的配置。
# 2. 理解fixture的作用和用法
### 2.1 fixture在测试中的作用
在测试中,fixture是用来创建和配置测试环境的工具。它可以提供测试运行所需要的各种资源,例如数据库连接、网络连接、测试数据等。通过使用fixture,我们可以在不同的测试用例中共享公共的设置和资源,提高测试的效率和可维护性。
### 2.2 fixture的基本语法和用法
fixture可以被定义为一个函数,并使用特殊的装饰器来标识它。在pytest中,最常用的装饰器是`@pytest.fixture`。下面是一个简单的fixture的例子:
```python
import pytest
@pytest.fixture
def setup():
# 设置测试前的条件
print("执行测试前的准备工作")
yield # 在yield之前的代码是测试前的准备工作,在yield之后的代码是测试后的清理工作
# 执行测试后的清理工作
print("执行测试后的清理工作")
def test_example(setup):
# 使用fixture提供的资源进行测试
print("执行测试用例")
```
在上面的例子中,`setup`是一个fixture函数。在`test_example`函数中,我们可以通过将`setup`作为参数传递进去来使用fixture提供的资源。
### 2.3 如何在pytest中使用fixture
在pytest中,通过使用`@pytest.fixture`装饰器,我们可以将fixture应用到测试函数、测试类或测试模块上。下面是几种常用的fixture用法示例:
```python
import pytest
@pytest.fixture
def setup_function():
# 适用于函数级别的fixture
print("函数级别的fixture")
def test_example1(setup_function):
print("测试函数1")
def test_example2(setup_function):
print("测试函数2")
@pytest.fixture(scope="module")
def setup_module():
# 适用于模块级别的fixture
print("模块级别的fixture")
def test_example3(setup_module):
print("测试函数3")
def test_example4(setup_module):
print("测试函数4")
@pytest.fixture(scope="session")
def setup_session():
# 适用于会话级别的fixture
print("会话级别的fixture")
def test_example5(setup_session):
print("测试函数5")
def test_example6(setup_session):
print("测试函数6")
class TestClass:
@pytest.fixture
def setup_class(self):
# 适用于类级别的fixture
print("类级别的fixture")
def test_example7(self, setup_class):
print("测试函数7")
def test_example8(self, setup_class):
print("测试函数8")
```
在上述代码中,`setup_function`是一个函数级别的fixture,它通过在每个测试函数之前运行一次来提供资源。`setup_module`是一个模块级别的fixture,它通过在整个测试模块之前运行一次来提供资源。`setup_session`是一个会话级别的fixture,它通过在整个测试会话之前运行一次来提供资源。`setup_class`是一个类级别的fixture,它通过在每个测试类之前运行一次来提供资源。
pytest还支持更高级的fixture用法,例如自动应用多个fixture、用fixture装饰器给测试函数传递参数等。这些进阶用法可以在pytest的官方文档中找到更多示例和说明。
总结了fixture的作用、基本语法和用法后,我们现在可以进行下一章节:利用fixture进行Selenium测试环境的配置。在下一章节,我们将介绍如何使用fixture来配置浏览器驱动和测试环境的URL,以及如何利用fixture管理测试用例的前置条件和后置条件。
# 3. 利用fixture进行Selenium测试环境的配置
在这一章中,我们将深入探讨如何使用fixture来配置Selenium测试环境,包括配置浏览器驱动、测试环境的URL以及如何利用fixture管理测试用例的前置条件和后置条件。
#### 3.1 使用fixture配置浏览器驱动
在进行Selenium测试之前,我们首先需要配置浏览器驱动。pytest-selenium提供了fixture来简化这一过程。
首先,我们需要安装相应的浏览器驱动,比如Chrome浏览器对应的驱动是ChromeDriver,Firefox浏览器对应的驱动是GeckoDriver等。然后在fixture中配置驱动的初始化和销毁过程。
```python
# content of conftest.py
import pytest
from selenium import webdriver
@pytest.fixture(scope="module")
def browser(request):
driver = webdriver.Chrome()
def fin():
driver.quit()
request.addfinalizer(fin)
return driver
```
在上面的例子中, `@pytest.fixture(scope="module")` 装饰器表示这个fixture的作用域是模块级别,也就是每个测试模块(文件)只会初始化一次浏览器驱动。
#### 3.2 配置测试环境的URL
在进行Web应用测试时,经常需要指定测试的URL,通过fixture可以轻松地实现这一配置。
```python
# content of conftest.py
import pytest
from selenium import webdriver
@pytest.fixture(scope="module")
def browser(request):
driver = webdriver.Chrome()
# 设置测试URL
base_url = "http://www.example.com"
driver.get(base_url)
def fin():
driver.quit()
request.addfinalizer(fin)
return driver
```
在上面的例子中,我们在fixture中设置了测试的URL,并在测试开始时加载该URL。这样可以保证每个测试用例都从同一个起始点开始执行。
#### 3.3 如何利用fixture管理测试用例的前置条件和后置条件
除了配置测试环境的基本要素外,fixture还可以方便地管理测试用例的前置条件和后置条件。比如在测试之前进行一些数据准备或环境初始化,在测试结束后清理资源等。
```python
# content of conftest.py
import pytest
from selenium import webdriver
import some_custom_library
@pytest.fixture(scope="function")
def pre_condition(request):
# 进行一些测试前的数据准备
some_custom_library.prepare_data()
def fin():
# 清理测试前准备的数据
some_custom_library.cleanup_data()
request.addfinalizer(fin)
# 使用pre_condition fixture进行测试前置条件的管理
def test_example(pre_condition):
# 这里执行测试步骤
pass
```
在上面的例子中,我们定义了一个名为pre_condition的fixture,用于进行测试前的数据准备和清理工作。通过在测试用例中传入pre_condition参数,即可实现测试前置条件的管理。
通过以上的介绍,我们可以看到fixture在配置Selenium测试环境时的重要作用,它可以帮助我们简化配置过程,管理测试环境和测试用例的前置条件和后置条件,从而提高测试代码的灵活性和可维护性。
# 4. 使用fixture管理测试数据
在测试过程中,通常会涉及到对测试数据的管理,包括测试数据的准备和清理。pytest-selenium的fixture机制可以帮助我们高效地管理测试数据,确保每个测试用例都能够以可靠的测试数据进行验证。
#### 4.1 利用fixture管理测试数据
在pytest中,fixture不仅可以用于配置测试环境和资源,还可以用于管理测试数据。我们可以通过fixture来准备测试数据,并在测试用例中使用这些数据进行验证。
下面是一个使用fixture准备测试数据的示例:
```python
import pytest
@pytest.fixture
def user_data():
user = {
"username": "test_user",
"password": "123456",
"email": "test_user@example.com"
}
return user
def test_user_registration(driver, user_data):
# 使用user_data fixture中的测试数据进行用户注册操作
# ...
pass
```
在上面的示例中,我们定义了一个名为`user_data`的fixture,它返回一个包含用户信息的字典。然后,我们在`test_user_registration`测试用例中使用了`user_data` fixture提供的测试数据进行用户注册操作。
#### 4.2 数据准备和清理的最佳实践
除了准备测试数据外,有时还需要在测试用例执行完毕后清理测试数据,以确保下次测试时的环境是干净的。这时候,fixture也能够发挥作用。
下面是一个示例,展示了如何在fixture中进行数据清理:
```python
@pytest.fixture
def prepared_data():
# 准备测试数据
data = prepare_test_data()
yield data # 测试用例执行
# 清理测试数据
clean_up_test_data(data)
```
在上面的示例中,我们定义了一个名为`prepared_data`的fixture,它在yield语句前执行测试数据的准备操作,在yield语句后执行测试数据的清理操作。
通过fixture管理测试数据的准备和清理,能够确保测试用例执行时环境的稳定性,从而提高测试的可靠性和稳定性。
在本章中,我们介绍了如何使用fixture管理测试数据,包括准备测试数据和清理测试数据。通过合理地利用fixture,可以使测试数据的管理更加高效和可靠。
# 5. 提高测试灵活性的高级fixture用法
在前面的章节中,我们已经介绍了如何使用fixture进行基本的测试环境配置和测试数据管理。而在本章中,我们将探讨一些高级的fixture用法,以提高测试的灵活性和可维护性。
### 5.1 fixture之间的依赖关系
在实际的测试场景中,往往会存在多个fixture之间的依赖关系。例如,我们可能需要在测试开始之前先登录到系统,然后进行一系列的操作和验证。这时,可以通过在fixture中设置参数来实现依赖关系的管理。
```python
@pytest.fixture
def login():
# 模拟登录操作
login_user = "testuser"
return login_user
@pytest.fixture
def perform_action(login):
# 模拟其他操作
action_msg = f"Performing action as {login}"
return action_msg
def test_perform_action(perform_action):
assert perform_action == "Performing action as testuser"
```
在上述示例中,我们定义了两个fixture: `login`和`perform_action`。`perform_action`依赖于`login`,即在执行`perform_action`之前会先执行`login`,并将`login`的返回值作为参数传递给`perform_action`。
### 5.2 动态生成fixture
有时候,我们可能需要根据不同的测试场景动态生成fixture。pytest-selenium提供了一个装饰器`@pytest.fixture(params=[..])`来实现这个目的。通过指定不同的参数值,我们可以在测试运行之前根据不同的情景生成不同的fixture。
下面的示例演示了如何在不同的环境下使用不同的浏览器进行测试:
```python
@pytest.fixture(params=["chrome", "firefox"])
def browser(request):
driver = None
if request.param == "chrome":
driver = webdriver.Chrome()
elif request.param == "firefox":
driver = webdriver.Firefox()
request.addfinalizer(lambda *args: driver.quit())
return driver
def test_browser(browser):
browser.get("https://www.example.com")
assert browser.title == "Example Domain"
```
在上述示例中,我们定义了一个名为`browser`的fixture,并通过`@pytest.fixture(params=[..])`装饰器指定了两个参数:"chrome"和"firefox"。pytest-selenium会根据这两个参数分别生成两次测试,并且将生成的driver对象作为fixture在测试中使用。
### 5.3 多种fixture用法的组合
除了上述介绍的基本用法之外,pytest-selenium还支持多种fixture用法的组合。我们可以通过在测试函数中同时使用多个fixture来实现更加灵活的测试套件组织。
下面的示例展示了如何利用fixture来管理测试套件的前置条件和后置条件:
```python
@pytest.fixture(scope="module")
def setup_module():
# 模拟模块级别的前置条件
yield
# 模拟模块级别的后置条件
@pytest.fixture(scope="class")
def setup_class():
# 模拟类级别的前置条件
yield
# 模拟类级别的后置条件
@pytest.fixture
def setup_test():
# 模拟测试级别的前置条件
yield
# 模拟测试级别的后置条件
class TestExample:
def test_one(self, setup_test, setup_class, setup_module):
# 执行测试用例
def test_two(self, setup_test, setup_class, setup_module):
# 执行测试用例
```
在上述示例中,我们分别定义了三个fixture:`setup_module`、`setup_class`、`setup_test`,并通过不同的作用域(scope)来控制其生命周期。通过使用不同作用域的fixture,我们可以在不同的测试阶段进行前置条件和后置条件的设置,从而提高测试的灵活性。
通过在测试类中使用这些fixture,并指定它们的执行顺序,我们可以组织出一个灵活可扩展的测试套件。
## 总结
在本章中,我们介绍了一些高级的fixture用法,包括fixture的依赖关系、动态生成fixture以及fixture的组合使用。通过灵活运用这些技巧,我们可以轻松构建强大且灵活的测试套件,提高测试效率和可维护性。
# 6. 编写灵活的测试套件
在测试过程中,灵活的测试套件可以帮助我们更好地管理和组织测试用例,提高测试的效率和可维护性。利用fixture机制,我们可以轻松地构建灵活的测试套件,本章将介绍如何利用fixture编写灵活的测试套件。
#### 6.1 如何利用fixture构建灵活的测试套件
在编写测试用例时,fixture可以帮助我们准备测试环境、数据,以及清理测试过程中的各种资源。通过合理地组合fixture,我们可以构建出灵活、可复用的测试套件。
```python
# 示例代码:利用fixture构建灵活的测试套件
import pytest
# 定义浏览器初始化fixture
@pytest.fixture
def browser():
from selenium import webdriver
driver = webdriver.Chrome()
yield driver
driver.quit()
# 定义登录fixture
@pytest.fixture
def login(browser):
browser.get('https://www.example.com/login')
# 执行登录操作
yield
# 执行退出操作
# 测试用例1:验证登录后的首页展示信息
def test_home_page_display(browser, login):
# 执行测试步骤
pass
# 测试用例2:验证登录用户的个人信息页
def test_user_profile_page(browser, login):
# 执行测试步骤
pass
```
在上面的示例中,我们通过定义了`browser`和`login`两个fixture,分别用于初始化浏览器和登录操作。在后续的测试用例中,通过将这些fixture作为参数传入,我们可以轻松地构建出灵活的测试套件。
#### 6.2 编写可重复使用的fixture
为了提高fixture的复用性,我们可以将fixture定义在单独的文件中,并通过`conftest.py`文件进行统一管理。这样可以让fixture在不同的测试模块中都能够被引用和复用。
```python
# conftest.py
import pytest
# 定义浏览器初始化fixture
@pytest.fixture
def browser():
from selenium import webdriver
driver = webdriver.Chrome()
yield driver
driver.quit()
# 定义登录fixture
@pytest.fixture
def login(browser):
browser.get('https://www.example.com/login')
# 执行登录操作
yield
# 执行退出操作
```
通过将fixture定义在`conftest.py`中,我们可以在整个测试套件中都能够引用这些fixture,提高了fixture的可重复使用性。
#### 6.3 利用fixture优化测试代码的结构
在编写测试用例时,合理地使用fixture可以帮助我们优化测试代码的结构,提高代码的可读性和可维护性。通过将一些重复的测试准备和清理操作抽取成fixture,可以让测试用例的代码更加简洁明了。
```python
# 示例代码:利用fixture优化测试代码的结构
import pytest
# 定义数据准备fixture
@pytest.fixture
def prepare_data():
data = {'username': 'testuser', 'password': '123456'}
# 执行数据准备操作
yield data
# 执行数据清理操作
# 测试用例:验证用户注册功能
def test_user_registration(browser, prepare_data):
username = prepare_data['username']
password = prepare_data['password']
# 执行注册流程测试
pass
```
通过合理地使用fixture,我们可以将测试代码中的一些重复操作抽取成fixture,让测试用例的代码更加清晰和简洁。
通过上述章节内容,我们可以看到如何利用fixture机制来构建灵活的测试套件,提高测试代码的可维护性和可读性。fixture的合理运用可以极大地提升测试用例的编写效率和质量。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了高级自动化测试框架pytest-selenium,旨在帮助测试工程师快速上手并掌握其核心概念和最佳实践。专栏内容涵盖了初步认识pytest-selenium并快速上手的指南,解析了其基本概念和核心组件,以及构建灵活测试套件的fixture机制。此外,还介绍了参数化的使用、页面对象模式、元素定位、等待元素、处理表单和弹窗等技巧,以及文件操作、JavaScript执行、浏览器标记、测试报告生成、持续集成集成等方面的实践经验。专栏还涵盖了测试数据生成、性能测试、异常处理、测试环境管理等领域的技术。通过本专栏的学习,读者将掌握pytest-selenium中丰富的自动化脚本技术和测试环境配置技巧,为构建健壮可靠的自动化测试框架提供有力支持。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Vue Select选择框数据监听秘籍:掌握数据流与$emit通信机制

# 摘要
本文深入探讨了Vue框架中Select组件的数据绑定和通信机制。从Vue Select组件与数据绑定的基础开始,文章逐步深入到Vue的数据响应机制,详细解析了响应式数据的初始化、依赖追踪,以及父子组件间的数据传递。第三章着重于Vue Select选择框的动态数据绑定,涵盖了高级用法、计算属性的优化,以及数据变化监听策略。第四章则专注于实现Vue Se
【操作秘籍】:施耐德APC GALAXY5000 UPS开关机与故障处理手册
# 摘要
本文对施耐德APC GALAXY5000 UPS进行全面介绍,涵盖了设备的概述、基本操作、故障诊断与处理、深入应用与高级管理,以及案例分析与用户经验分享。文章详细说明了UPS的开机、关机、常规检查、维护步骤及监控报警处理流程,同时提供了故障诊断基础、常见故障排除技巧和预防措施。此外,探讨了高级开关机功能、与其他系统的集成以及高级故障处理技术。最后,通过实际案例和用户经验交流,强调了该UPS在不同应用环境中的实用性和性能优化。
# 关键字
UPS;施耐德APC;基本操作;故障诊断;系统集成;案例分析
参考资源链接:[施耐德APC GALAXY5000 / 5500 UPS开关机步骤
wget自动化管理:编写脚本实现Linux软件包的批量下载与安装
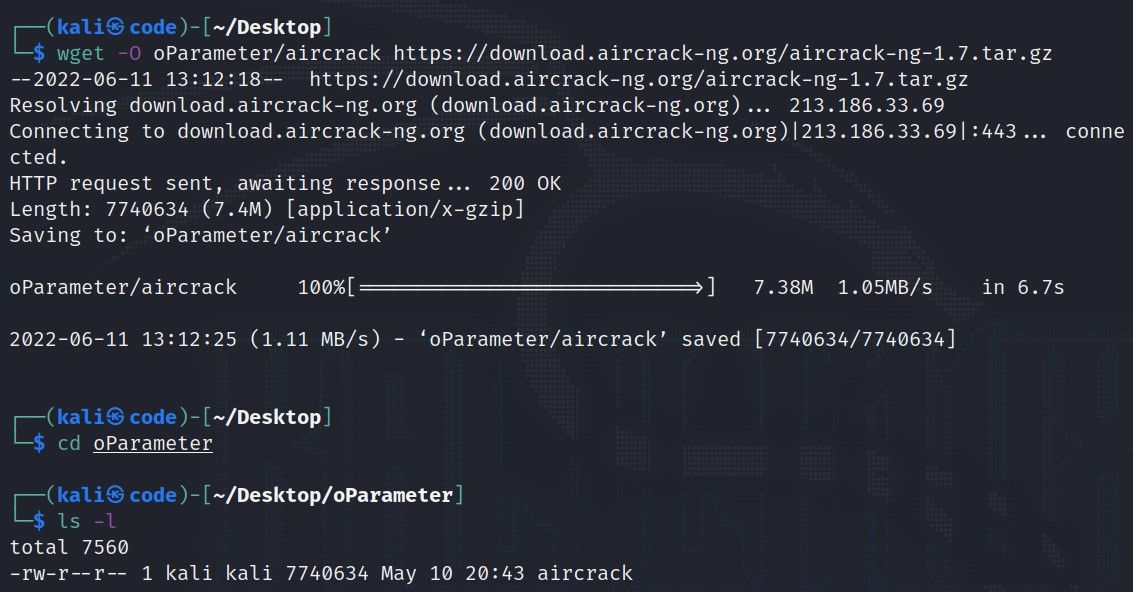
# 摘要
本文对wget工具的自动化管理进行了系统性论述,涵盖了wget的基本使用、工作原理、高级功能以及自动化脚本的编写、安装、优化和安全策略。首先介绍了wget的命令结构、选项参数和工作原理,包括支持的协议及重试机制。接着深入探讨了如何编写高效的自动化下载脚本,包括脚本结构设计、软件包信息解析、批量下载管理和错误
Java中数据结构的应用实例:深度解析与性能优化
# 摘要
本文全面探讨了Java数据结构的理论与实践应用,分析了线性数据结构、集合框架、以及数据结构与算法之间的关系。从基础的数组、链表到复杂的树、图结构,从基本的集合类到自定义集合的性能考量,文章详细介绍了各个数据结构在Java中的实现及其应用。同时,本文深入研究了数据结构在企业级应用中的实践,包括缓存机制、数据库索引和分布式系统中的挑战。文章还提出了Java性能优化的最佳实践,并展望了数据结构在大数据和人
SPiiPlus ACSPL+变量管理实战:提升效率的最佳实践案例分析

# 摘要
SPiiPlus ACSPL+是一种先进的控制系统编程语言,广泛应用于自动化和运动控制领域。本文首先概述了SPiiPlus ACSPL+的基本概念与变量管理基础,随后深入分析了变量类型与数据结构,并探讨了实现高效变量管理的策略。文章还通过实战技巧,讲解了变量监控、调试、性能优化和案例分析,同时涉及了高级应用,如动态内存管理、多线程变量同步以及面向对象的变
DVE基础入门:中文版用户手册的全面概览与实战技巧

# 摘要
本文旨在为初学者提供DVE(文档可视化编辑器)的入门指导和深入了解其高级功能。首先,概述了DVE的基础知识,包括用户界面布局和基本编辑操作,如文档的创建、保存、文本处理和格式排版。接着,本文探讨了DVE的高级功能,如图像处理、高级文本编辑技巧和特殊功能的使用。此外,还介绍了DVE的跨平台使用和协作功能,包括多用户协作编辑、跨平台兼容性以及与其他工具的整合。最后,通过
【Origin图表专业解析】:权威指南,坐标轴与图例隐藏_显示的实战技巧

# 摘要
本文系统地介绍了Origin软件中图表的创建、定制、交互功能以及性能优化,并通过多个案例分析展示了其在不同领域中的应用。首先,文章对Origin图表的基本概念、坐标轴和图例的显示与隐藏技巧进行了详细介绍,接着探讨了图表高级定制与性能优化的方法。文章第四章结合实战案例,深入分析了O
EPLAN Fluid团队协作利器:使用EPLAN Fluid提高设计与协作效率
# 摘要
EPLAN Fluid是一款专门针对流体工程设计的软件,它能够提供全面的设计解决方案,涵盖从基础概念到复杂项目的整个设计工作流程。本文从EPLAN Fluid的概述与基础讲起,详细阐述了设计工作流程中的配置优化、绘图工具使用、实时协作以及高级应用技巧,如自定义元件管理和自动化设计。第三章探讨了项目协作机制,包括数据管理、权限控制、跨部门沟通和工作流自定义。通过案例分析,文章深入讨论
【数据迁移无压力】:SGP.22_v2.0(RSP)中文版的平滑过渡策略

# 摘要
本文深入探讨了数据迁移的基础知识及其在实施SGP.22_v2.0(RSP)迁移时的关键实践。首先,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )