【StringIO的内存限制挑战】:大文件处理的终极解决方案
发布时间: 2024-10-08 02:47:34 阅读量: 45 订阅数: 29 

Python StringIO如何在内存中读写str
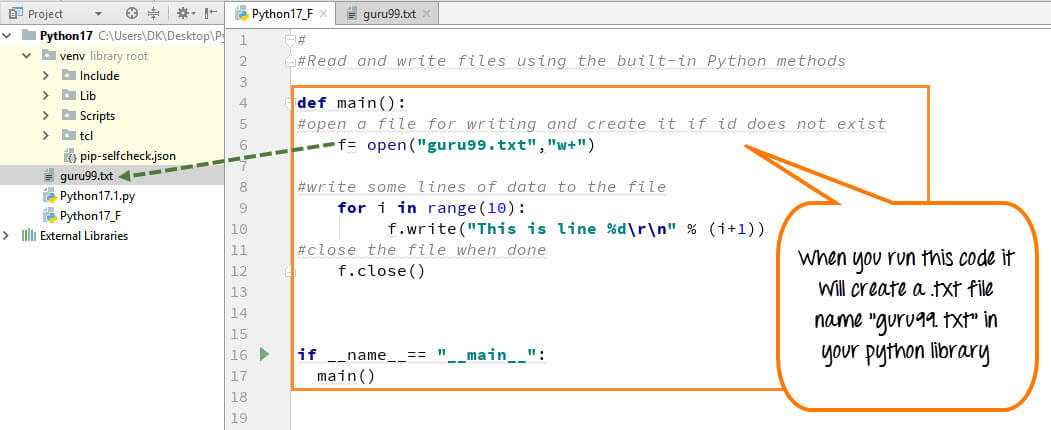
# 1. StringIO的内存限制挑战概述
在当今的IT行业中,数据处理已成为日常任务的核心部分。随着数据量的急剧增加,处理大量数据的能力正变得越来越关键。本章将概述StringIO在内存限制方面的挑战,为读者揭示为何这一经典内存I/O库在处理大文件时遇到了性能瓶颈。
## 1.1 StringIO的内存限制问题
StringIO是一种在内存中模拟文件I/O操作的对象,它为字符串数据提供了类似于文件的处理方式。然而,StringIO的内存限制问题开始显现,特别是在处理大规模数据集时。随着数据量的增加,StringIO开始暴露出显著的性能短板,因为它将全部数据加载到内存中,这在有限的物理内存面前成为了显著的瓶颈。
## 1.2 内存限制对实际应用的影响
在处理大文件时,StringIO的内存限制可能会导致内存溢出错误或性能下降,这直接影响到了应用程序的稳定性和效率。开发者在尝试进行高效数据处理和分析时,必须考虑到这些限制,这迫使他们寻找替代方案或对现有方法进行优化。
接下来的章节将深入探讨StringIO的理论基础和内存管理机制,并分析大数据处理中遇到的具体问题和现有解决方案的不足,为理解和解决这些挑战提供全面的视角。
# 2. StringIO理论基础与内存机制
### 2.1 StringIO的概念和作用
StringIO 是 Python 中用于在内存中读写字符串的一种库,是标准的文件操作的一种模拟。由于在内存中进行操作,StringIO 对象比传统的磁盘 I/O 更快、更高效,但同时它也有一些局限性。
#### 2.1.1 StringIO的定义和应用场景
StringIO 对象被创建为一个可读写的文本流,可以用于任何需要字符串 I/O 的场景。它可以在程序中实现快速的字符串处理,无需实际地写入或读取文件系统。
```python
from io import StringIO
# 创建一个StringIO对象
string_io = StringIO()
# 写入数据
string_io.write('Hello World\n')
# 读取数据
print(string_io.getvalue())
```
这个简单的例子演示了 StringIO 的基本用法。`StringIO()` 创建了一个内存中的文本流对象,`write()` 方法将字符串写入流,`getvalue()` 读取全部内容。
#### 2.1.2 StringIO与传统I/O的比较
与传统的文件 I/O 相比,StringIO 无需打开文件和进行磁盘 I/O 操作,从而大大减少了 I/O 开销。此外,StringIO 操作不会产生磁盘碎片,而文件操作可能会导致磁盘碎片化。
### 2.2 StringIO的内存管理机制
#### 2.2.1 内存分配与释放原理
StringIO 在内部通过一块动态分配的缓冲区来存储数据。当写入数据时,如果缓冲区空间不足,会自动扩展缓冲区以存储更多数据。释放数据时,内存会根据 Python 的垃圾回收机制进行回收。
```python
string_io = StringIO()
string_io.write(' ' * (1024 * 1024)) # 分配1MB空间
string_io.close() # 释放StringIO对象,触发内存回收
```
在这个代码块中,创建了1MB的空格字符串并写入StringIO对象,随后关闭对象以触发内存释放。
#### 2.2.2 内存限制产生的原因与后果
内存限制通常是由缓冲区大小所决定的。当单个 StringIO 对象需要处理的数据量超过分配的缓冲区限制时,就会遇到内存限制的问题。这可能导致数据丢失或程序崩溃。
### 2.3 StringIO在大数据处理中的局限性
#### 2.3.1 大文件处理的问题分析
在处理大文件时,StringIO可能因为内存限制而无法直接使用。内存中单个实例的数据量需要限制在缓冲区大小之内,否则会引发异常。
#### 2.3.2 现有解决方案的不足
现有的解决方案包括分块处理和更换为其他类型的内存中数据结构,但这些方法通常会增加复杂性或降低性能。因此,对于大数据场景,直接使用 StringIO 会有一定的局限性。
在下一章节中,我们将探索突破 StringIO 内存限制的理论和实践方法,以解决大数据处理的挑战。
# 3. 突破StringIO内存限制的理论探索
## 3.1 内存管理的理论基础
### 3.1.1 内存分页和虚拟内存机制
在现代操作系统中,内存管理是通过内存分页(Paging)和虚拟内存(Virtual Memory)机制来实现的。内存分页是一种内存管理技术,用于控制程序如何访问物理内存。系统将物理内存划分为固定大小的块,称为“页”(Page),而进程使用的内存地址被映射到这些页上。虚拟内存进一步扩展了这一概念,允许程序使用比实际物理内存更大的地址空间。程序的代码和数据在需要时才被加载到物理内存中,如果物理内存不足,操作系统会将暂时不需要的数据写入磁盘的交换空间(Swap Space),当再次需要时再读回内存。
**代码示例:虚拟内存与物理内存映射**
```c
// C语言代码示例:展示虚拟内存地址映射到物理内存地址的过程
#include <stdio.h>
int main() {
// 假设虚拟内存地址被映射到物理内存地址
int virtualAddress = 0x***; // 虚拟地址
int physicalAddress = virtualToPhysical(virtualAddress); // 假设存在一个函数,可以完成映射
printf("虚拟地址 0x%X 映射到物理地址 0x%X\n", virtualAddress, physicalAddress);
return 0;
}
// 这里仅为示意,实际情况下,操作系统内核负责处理虚拟地址到物理地址的映射。
```
### 3.1.2 垃圾回收与内存优化策略
垃圾回收(Garbage Collection,GC)是内存管理中的一个重要组成部分,它自动回收程序不再使用的内存。在Python这类高级语言中,垃圾回收机制被内建在语言的运行时环境中,而在底层语言如C/C++中,则需要手动管理内存。随着编程语言的发展,自动垃圾回收机制在提高开发效率的同时,也带来了一定的性能开销。为了优化内存使用,开发者应当:
- 减少内存泄漏,避免对象在不再需要时仍被占用;
- 合理安排数据结构的生命周期;
- 使用弱引用(Weak Reference)来避免循环引用导致的对象无法被回收。
**代码示例:Python中的垃圾回收**
```python
import gc
def create_data():
# 创建数据
return [i for i in range(1000000)]
data = create_data()
# 这里我们不再需要data对象,Python的垃圾回收机制将在未来某个时刻回收它
del data
# 强制进行垃圾回收
gc.collect()
```
## 3.2 高效内存使用的算法设计
### 3.2.1 算法优化原则与案例分析
高效内存使用的算法设计是突破内存限制的关键。算法优化的原则包括减少不必要的数据拷贝、使用空间换时间的策略、避免重复计算等。例如,在处理字符串时,可以使用生成器表达式代替列表推导式来减少内存占用。
**代码示例:优化内存使用的算法**
```python
# 列表推导式可能会占用大量内存
data_list = [x * 2 for x in range(1000000)]
# 使用生成器表达式减少内存占用
data_generator = (x * 2 for x in range(1000000))
# 示例展示如何使用生成器表达式来逐步处理数据
for item in data_generator:
# 这里可以对item进行处理,无需一次性将所有数据加载到内存中
pass
```
### 3.2.2 避免内存泄漏的方法和技巧
内存泄漏是指程序中分配的内存在不再需要时未被释放。长期的内存泄漏会导致系统可用内存逐渐减少,最终影响程序的性能甚至稳定性。为了避免内存泄漏:
- 使用编程语言提供的内存管理工具,如Python中的`gc`模块;
- 在C/C++中,使用智能指针如`std::shar

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 中强大的 StringIO 库,它提供了高效的内存文件操作功能。从基础知识到高级技巧,本专栏涵盖了 StringIO 的各个方面,包括与 BytesIO 的对比、进阶技能、与 open 的比较、自定义 StringIO 的构建、多线程操作、实战案例、与字符串的融合、在 Web 框架中的应用、I/O 管道构建、内存限制挑战、数据处理中的作用以及与 contextlib 的集成。通过深入的剖析和实战技巧,本专栏将帮助 Python 开发人员充分利用 StringIO,提高内存文件操作的效率和灵活性。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【MATLAB C4.5算法性能提升秘籍】:代码优化与内存管理技巧

# 摘要
本论文首先概述了MATLAB中C4.5算法的基础知识及其在数据挖掘领域的应用。随后,探讨了MATLAB代码优化的基础,包括代码效率原理、算法性能评估以及优化技巧。深入分析了MATLAB内存管理的原理和优化方法,重点介绍了内存泄漏的检测与预防
【稳定性与混沌的平衡】:李雅普诺夫指数在杜芬系统动力学中的应用

# 摘要
本文旨在介绍杜芬系统的概念与动力学基础,深入分析李雅普诺夫指数的理论和计算方法,并探讨其在杜芬系统动力学行为和稳定性分析中的应用。首先,本文回顾了杜芬系统的动力学基础,并对李雅普诺夫指数进行了详尽的理论探讨,包括其定义、性质以及在动力系统中的角色。
QZXing在零售业中的应用:专家分享商品快速识别与管理的秘诀

# 摘要
QZXing作为一种先进的条码识别技术,在零售业中扮演着至关重要的角色。本文全面探讨了QZXing在零售业中的基本概念、作用以及实际应用。通过对QZXing原理的阐述,展示了其在商品快速识别中的核心技术优势,例如二维码识别技术及其在不同商品上的应用案例。同时,分析了QZXing在提高商品识别速度和零售效率方面的实际效果
【AI环境优化高级教程】:Win10 x64系统TensorFlow配置不再难

# 摘要
本文详细探讨了在Win10 x64系统上安装和配置TensorFlow环境的全过程,包括基础安装、深度环境配置、高级特性应用、性能调优以及对未来AI技术趋势的展望。首先,文章介绍了如何选择合适的Python版本以及管理虚拟环境,接着深入讲解了GPU加速配置和内存优化。在高级特性应用
【宇电温控仪516P故障解决速查手册】:快速定位与修复常见问题

# 摘要
本文全面介绍了宇电温控仪516P的功能特点、故障诊断的理论基础与实践技巧,以及常见故障的快速定位方法。文章首先概述了516P的硬件与软件功能,然后着重阐述了故障诊断的基础理论,包括故障的分类、系统分析原理及检测技术,并分享了故障定位的步骤和诊断工具的使用方法。针对516P的常见问题,如温度显示异常、控制输出不准确和通讯故障等,本文提供了详尽的排查流程和案例分析,并探讨了电气组件和软件故障的修复方法。此外
【文化变革的动力】:如何通过EFQM模型在IT领域实现文化转型

# 摘要
EFQM模型是一种被广泛认可的卓越管理框架,其在IT领域的适用性与实践成为当前管理创新的重要议题。本文首先概述了EFQM模型的核心理论框架,包括五大理念、九个基本原则和持续改进的方法论,并探讨了该模型在IT领域的具体实践案例。随后,文章分析了EFQM模型如何在IT企业文化中推动创新、强化团队合作以及培养领导力和员工发展。最后,本文研究了在多样化
RS485系统集成实战:多节点环境中电阻值选择的智慧
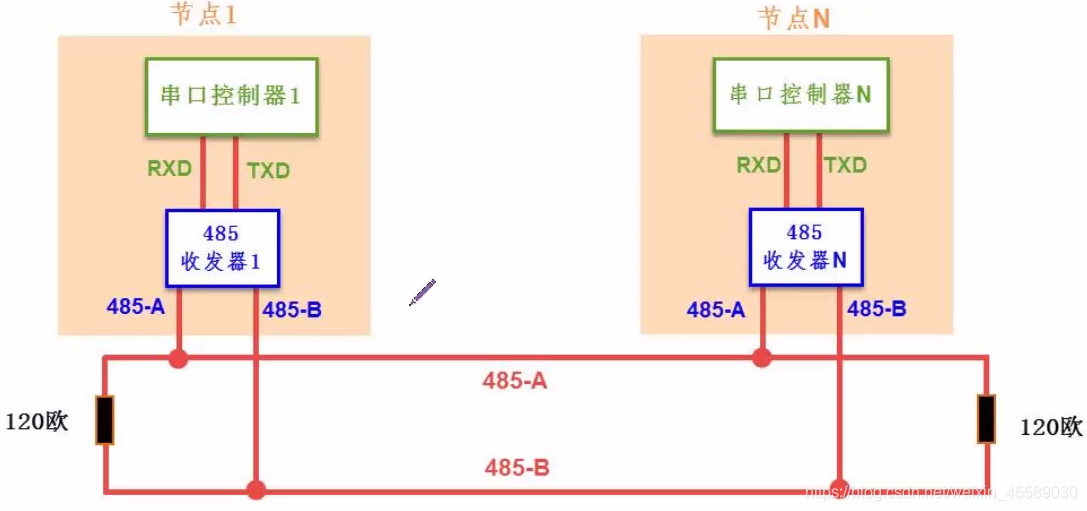
# 摘要
本文系统性地探讨了RS485系统集成的基础知识,深入解析了RS485通信协议,并分析了多节点RS485系统设计中的关键原则。文章
【高级电磁模拟】:矩量法在复杂结构分析中的决定性作用
# 摘要
本文全面介绍了电磁模拟与矩量法的基础理论及其应用。首先,概述了矩量法的基本概念及其理论基础,包括电磁场方程和数学原理,随后深入探讨了积分方程及其离散化过程。文章着重分析了矩量法在处理多层介质、散射问题及电磁兼容性(EMC)方面的应用,并通过实例展示了其在复杂结构分析中的优势。此外,本文详细阐述了矩量法数值模拟实践,包括模拟软件的选用和模拟流程,并对实际案例
SRIO Gen2在云服务中的角色:云端数据高效传输技术深度支持

# 摘要
本文旨在深入探讨SRIO Gen2技术在现代云服务基础架构中的应用与实践。首先,文章概述了SRIO Gen2的技术原理,及其相较于传统IO技术的显著优势。然后,文章详细分析了SRIO Gen2在云服务中尤其是在数据中心的应用场景,并提供了实际案例研
先农熵在食品质量控制的重要性:确保食品安全的科学方法

# 摘要
本文深入探讨了食品质量控制的基本原则与重要性,并引入先农熵理论,阐述其科学定义、数学基础以及与热力学第二定律的关系。通过对先农熵在食品稳定性和保质期预测方面作用的分析,详细介绍了先农熵测量技术及其在原料质量评估、加工过程控制和成品质量监控中的应用。进一步,本文探讨了先农熵与其他质量控制方法的结合,以及其在创新食品保存技术和食品安全法规标准中的应用。最后,通过案例分析,总结了先农熵在食品质量控制中
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )