创建第一个Github仓库及文件上传操作详解
发布时间: 2023-12-18 17:36:56 阅读量: 67 订阅数: 34 

github上传文件方法教程,超详细,带图说明
# 1. 简介
## 1.1 什么是GitHub仓库
GitHub仓库是指在GitHub平台上创建的用于存储、管理和分享代码或文档的空间。每个仓库都包含与项目相关的所有文件,以及每个文件的版本历史记录。
## 1.2 为什么要创建GitHub仓库
创建GitHub仓库可以方便地进行代码版本管理、团队协作和项目开发。GitHub提供了强大的版本控制功能,使开发者能够追踪和管理代码的变化,同时也提供了方便的协作工具,有利于团队成员之间的交流与合作。同时,GitHub还允许用户按照开源或私有设置来共享他们的代码,便于他人参与贡献或观摩学习。GitHub仓库还提供了多种特性,如Issue跟踪、Pull Request处理等,全方位支持开发流程的管理和优化。
## 注册GitHub账号
### 3. 创建新仓库
在GitHub上创建新的仓库是开始使用GitHub的第一步。仓库是用来存储项目源代码和相关文件的地方。下面是创建新仓库的详细步骤。
#### 3.1 登录GitHub账号
首先,打开你注册的GitHub账号并登录。
#### 3.2 到仓库页面
在登录后,点击右上角的加号按钮,然后选择“New repository”选项,即可进入创建仓库的页面。
#### 3.3 点击"New"按钮创建新仓库
在创建仓库的页面,你会看到一个绿色的按钮,上面写着“New”字样,点击该按钮来创建新的仓库。
#### 3.4 填写仓库信息
创建新仓库时,需要填写一些基本信息。包括仓库的名称、描述、公开/私有等选项。你可以根据你的需求填写相应的信息。一般来说,仓库名称应该简洁明了,能够准确描述该仓库的内容。
填写完信息后,点击页面底部的“Create repository”按钮即可完成仓库的创建。
创建成功后,你会被重定向到仓库的页面。在这个页面上可以执行一些仓库相关的操作,如创建分支、上传文件、编辑文件等。
### 4. 上传文件
在这一节中,我们将学习如何将本地文件上传到GitHub仓库中。
#### 4.1 下载并安装Git
首先,我们需要下载并安装Git,Git是一个分布式版本控制系统,我们可以使用它来管理GitHub仓库中的文件。你可以在 [Git官网](https://git-scm.com/) 上找到适合你操作系统的安装包,并按照提示进行安装。
#### 4.2 设置Git的全局配置
安装完成Git后,打开命令行工具,输入以下命令来配置你的Git用户名和邮箱:
```bash
git config --global user.name "Your Name"
git config --global user.email "youremail@example.com"
```
将命令中的"Your Name"替换成你在GitHub注册时使用的名字,"youremail@example.com"替换成你在GitHub注册时使用的邮箱。
#### 4.3 克隆仓库到本地
在GitHub仓库页面中找到"Clone or download"按钮,复制仓库的URL。然后在命令行中进入你想要将仓库克隆到的文件夹中,输入以下命令来克隆仓库到本地:
```bash
git clone <仓库URL>
```
将`<仓库URL>`替换成你复制的仓库URL。
#### 4.4 添加文件到Git仓库
将你想要上传的文件复制到本地仓库的文件夹中,在命令行中进入该文件夹,输入以下命令将文件添加到Git仓库:
```bash
git add <filename>
```
将`<filename>`替换成你要添加的文件名。
#### 4.5 提交文件
输入以下命令来提交文件到GitHub仓库:
```bash
git commit -m "Add some files"
```
这段命令将你添加的文件提交到本地仓库。
现在,输入以下命令将文件推送到远程GitHub仓库中:
```bash
git push origin master
```
输入你的GitHub账号和密码,即可将文件上传到GitHub仓库。
### 5. 查看提交记录
Git提供了丰富的功能来帮助用户查看仓库的提交记录,比较不同版本的文件等操作。接下来,我们将详细介绍如何使用这些功能。
#### 5.1 查看仓库提交记录
在Git中,可以使用以下命令来查看仓库的提交记录:
```bash
git log
```
这会列出所有的提交记录,包括提交作者、提交时间、提交信息等。
#### 5.2 查看具体文件的提交记录
如果希望查看某个文件的提交记录,可以使用以下命令:
```bash
git log <file>
```
这会列出特定文件的提交记录,包括提交作者、提交时间、提交信息等。
#### 5.3 比较不同版本的文件
Git提供了`git diff`命令来比较不同版本的文件,比如:
```bash
git diff <commit1> <commit2> <file>
```
这会展示两个不同版本之间的具体差异。
### 6. 总结
GitHub仓库对于程序员来说是一个非常重要的工具,能够帮助我们更好地管理代码、协作开发、记录项目历史等。通过本文的介绍,你已经学会了如何注册GitHub账号、创建新仓库、上传文件以及查看提交记录等基本操作。
#### 6.1 善用GitHub仓库的好处
- 可以方便地进行版本控制,记录每一次的代码变动,帮助团队合作开发;
- 可以创建分支进行新功能开发和bug修复,不会影响主代码;
- 可以方便地查看代码的变动历史,追溯问题产生的根源;
- 可以托管开源项目,与全球的开发者共同学习、交流;
- 可以作为自己的代码仓库,随时随地安全存放个人项目代码。
#### 6.2 继续学习Git和GitHub的内容
本文只是Git和GitHub的入门介绍,Git和GitHub还有很多高级功能和操作,比如分支管理、协作开发、解决代码冲突等。建议你继续深入学习,掌握更多高级的Git和GitHub技巧,这将对你日后的工作和学习大有裨益。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏《Github与TortoiseGit入门》深入系统地介绍了Github和TortoiseGit的基本操作和高级应用。在《Github简介与基本操作入门》中,我们将带您了解Github背后的概念和核心功能,并提供详细的操作指南。在《TortoiseGit安装与配置指南》一文中,我们将教您如何正确安装和配置TortoiseGit,以充分利用其强大的版本控制功能。《创建第一个Github仓库及文件上传操作详解》详细介绍了如何创建Github仓库,并演示了文件上传的操作步骤。在《TortoiseGit中的分支与合并操作技巧》中,我们将向您展示如何利用TortoiseGit进行分支管理和合并操作,以提高代码的可维护性和团队协作效率。其他文章中,我们还将涉及Github上的Issues与Pull Requests管理、TortoiseGit中的标签与版本管理、Github Pages搭建个人博客等相关内容。无论您是初学者还是有一定经验的开发者,本专栏都能够满足您探索和应用这两个重要工具的需求。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
电力系统设计:如何确保数据中心的稳定性和效率(IT专家策略)

# 摘要
数据中心作为现代计算的基石,其电力系统设计对于保证数据中心的稳定运行和高效能效至关重要。本文首先介绍了数据中心电力系统设计的基础知识,然后深入探讨了设计原则,包括电力需求理解、动态负载管理、关键参数选择以及高效电力分配的重要性。接着,文章详细分析了数据中心电力系统的主要组件与技术,包括UPS
【速达3000Pro数据库优化速成课】:掌握性能调优的捷径
# 摘要
本文围绕速达3000Pro数据库优化技术展开全面探讨,旨在为读者提供入门指导与深入的理论知识。首先介绍了数据库性能调优的重要性,阐述了识别性能瓶颈和优化目标的意义。随后,探讨了数据库设计优化原则,包括数据模型的重要性和正规化与反正规化的平衡。在实践调优技巧章节中,详细讨论了查询优化技术、系统配置优化以及数据库维护与管理的策略。高级优化技术章节进一步涵盖了分布式数据库优化、事务处理优化以及
易语言与API深度结合:实现指定窗口句柄的精准获取

# 摘要
本文系统地介绍了易语言与API的基础概念和在易语言中的基础运用,重点探讨了窗口句柄的精准获取及其在实践应用中的高级技巧。文中首先概述了API的基本
VSS安装使用指南:新手入门的终极向导,零基础也能搞定

# 摘要
本文系统地介绍了版本控制系统(VSS)的基础知识、安装流程、使用技巧、实践应用、进阶应用以及与其他工具的集成方法。首先,概述了VSS的基本概念和安装步骤,随后详细阐述了用户界面功能、文件操作、版本管理以及高级功能如标签和分支的使用。进一步地,本文探讨了VSS在软件开发和项目管理中的应用实例
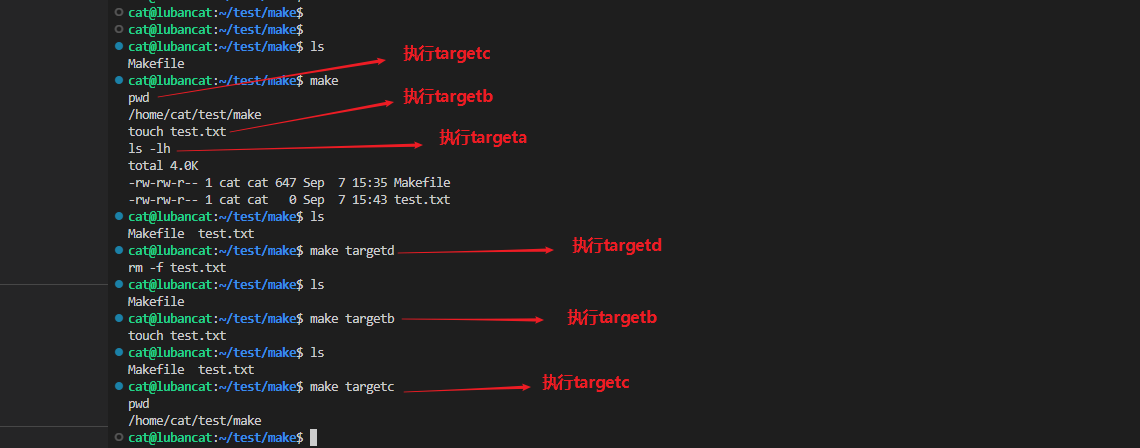
【Linux性能提升】:makefile编写技巧大公开,优化指南助你提高编译效率
# 摘要
本文详细探讨了Makefile在软件编译过程中的基础原理与高级编写技巧,并分析了在复杂项目构建、团队协作以及优化编译效率方面的应用实践。通过对Makefile核心概念的解析,包括规则、目标、变量、函数以及模式规则和自动化变量的运用,本文进一步阐述了条件判断、多目标构建、静态与动态模式规则、以及自
【高级性能调优策略】:掌握AVX-SSE转换penalty的应对艺术

# 摘要
随着处理器技术的不断进步,AVX指令集作为新一代的向量指令集,相较于SSE指令集,提供了更强大的计算能力和更优的数据处理效率。然而,在从SSE向AVX转换的过程中,存在着性能损失(penalty),这一现象在数据密集型和计算密集型应用中尤为显著。本文深入探讨了AVX-SSE转换的背景、影响、penalty的定义及影响因素,并对不同应用场景中转换的性能表现进行了分析。同时,
企业级Maven私服构建指南:Nexus的高级扩展与定制技术

# 摘要
本文全面介绍了Nexus作为企业级存储库管理工具的部署、高级配置、优化、扩展开发以及在企业级环境中的应用实践。首先概述了Nexus的基本概念和基础部署方法,然后深入探讨了其高级配置选项,包括存储库管理、用户权限设置以及性能调优。接着,本文详细
VMware与ACS5.2河蟹版协同工作指南:整合与最佳实践
# 摘要
本文旨在探讨VMware与ACS5.2河蟹版如何实现协同工作,以及如何在虚拟环境中整合这两种技术以提升网络管理和安全性。文章首先介绍了VMware的基础知识与配置,包括虚拟化技术原理、产品系列、安装步骤以及高级配置技巧。接着,文章概述了ACS5.2河蟹版的功能优势,并详细阐述了其安装、配置和管理方法。最后,文章着
【Docker容器化快速入门】:简化开发与部署的九个技巧
# 摘要
Docker作为当前主流的容器化技术,极大地推动了软件开发、测试和部署流程的自动化和简化。本文对Docker容器化技术进行了全面的概述,从基础命令与镜像管理到Dockerfile的编写与优化,再到网络配置、数据管理和高级应用。通过细致地探讨容器生命周期管理、安全镜像构建和网络数据持久化策略,本文旨在为开发人员提供实用的容器化解决方案
LIN 2.0协议安全宝典:加密与认证机制的全方位解读

# 摘要
本文旨在全面分析LIN 2.0协议的安全特性,包括其加密技术和认证机制。首先介绍了LIN 2.0协议的基础知识及其在安全背景下的重要性。随后,深入探讨了LIN 2.0协议所采用的加密技术,如对称加密、非对称加密、DES、AES以及密钥管理策略。在认证机制方面,分析了消息摘要、哈希函
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )