Python RESTful API设计与开发:构建可扩展、可维护的API
发布时间: 2024-06-19 02:44:38 阅读量: 77 订阅数: 35 
# 1. RESTful API基础**
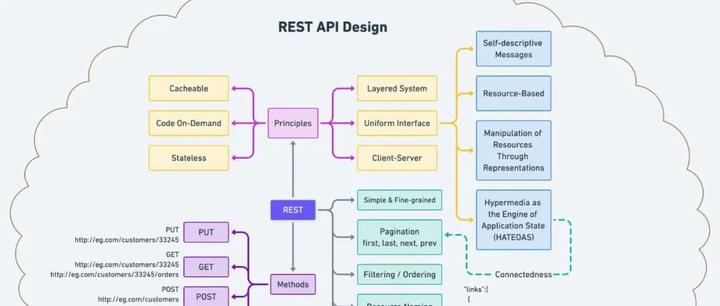
RESTful API(Representational State Transfer API)是一种基于HTTP协议的API设计风格,它遵循一系列约束,以确保API的可扩展性、可维护性和可移植性。RESTful API通过使用HTTP方法(如GET、POST、PUT、DELETE)来操作资源,并使用HTTP状态码来表示操作的结果。
RESTful API的设计原则包括:
* **无状态性:**每个请求都是独立的,不依赖于之前的请求。
* **资源导向:**API操作的是资源,而不是动作。
* **统一接口:**所有资源都通过统一的接口进行访问,无论其底层实现如何。
# 2. Python RESTful API设计
### 2.1 RESTful API架构和设计原则
RESTful API遵循表述性状态转移(REST)架构风格,该风格强调资源的统一接口和无状态性。RESTful API架构由以下关键组件组成:
- **资源:**API操作的对象,如用户、产品或订单。
- **URI:**用于标识资源的统一资源标识符。
- **HTTP方法:**用于对资源执行操作的HTTP方法,如GET、POST、PUT和DELETE。
- **状态码:**表示操作结果的HTTP状态码,如200(成功)或404(未找到)。
RESTful API设计原则包括:
- **统一接口:**所有资源都通过一致的URI和HTTP方法进行访问。
- **无状态性:**服务器不存储客户端会话状态,每个请求都包含所有必要信息。
- **可缓存性:**响应可以缓存,以提高性能。
- **分层系统:**API可以分层,以实现模块化和可扩展性。
### 2.2 HTTP方法和状态码
HTTP方法用于对资源执行特定操作:
| HTTP方法 | 操作 |
|---|---|
| GET | 检索资源 |
| POST | 创建新资源 |
| PUT | 更新现有资源 |
| DELETE | 删除资源 |
HTTP状态码表示操作的结果:
| 状态码 | 描述 |
|---|---|
| 200 | 成功 |
| 400 | 错误请求 |
| 401 | 未经授权 |
| 404 | 未找到 |
| 500 | 内部服务器错误 |
### 2.3 数据格式和序列化
RESTful API使用数据格式(如JSON或XML)来表示资源。序列化是将对象转换为数据格式的过程,而反序列化是将数据格式转换为对象的逆过程。
Python中常用的数据格式序列化库包括:
- **JSON:**用于JavaScript对象表示法,是一种轻量级、易于解析的数据格式。
- **XML:**用于可扩展标记语言,是一种结构化、可扩展的数据格式。
### 2.4 版本控制和错误处理
版本控制对于管理API的演变至关重要。版本控制策略包括:
- **URL版本控制:**在URI中包含版本号,如`/api/v1/users`。
- **标头版本控制:**在HTTP请求标头中指定版本号,如`Accept: application/json; version=1`。
错误处理对于提供用户友好的错误消息和诊断信息非常重要。RESTful API应返回标准化错误响应,包括:
- **状态码:**表示错误类型的HTTP状态码。
- **错误消息:**描述错误的简短、清晰的消息。
- **错误代码:**用于识别特定错误类型的可选代码。
**代码示例:**
```python
from flask import jsonify, make_response
@app.errorhandler(404)
def not_found(error):
return make_response(jsonify({'error': 'Not found'}), 404)
```
**代码逻辑分析:**
此代码使用Flask框架的`errorhandler`装饰器来处理404错误。它返回一个JSON响应,其中包含`error`字段,该字段包含错误消息,并设置HTTP状态码为404。
# 3.1 Flask框架简介和安装
Flask是一个轻量级、易于使用的Python Web框架,非常适合构建RESTful API。它提供了构建API所需的所有基本功能,例如路由、视图函数、数据模型和数据库集成。
**安装Flask**
要安装Flask,请使用pip命令:
```python
pip install Flask
```
**创建Flask应用**
创建一个名为`app.py`的新文件,并添加以下代码:
```python
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello, World!'
if __name__ == '__main__':
app.run()
```
此代码创建了一个Flask应用,并定义了一个简单的路由`/`,当访问该路由时,它将返回`"Hello, World!"`。
**运行Flask应用**
要运行Flask应用,请使用以下命令:
```bash
python app.py
```
这将在本地端口5000上启动Flask应用。
### 3.2 路由和视图函数
**路由**
路由是将HTTP请求映射到视图函数的规则。Flask使用`@app.route()`装饰器来定义路由。
例如,以下路由将`/users`请求映射到`get_users`视图函数:
```python
@app.route('/users')
def get_users():
return 'List of users'
```
**视图函数**
视图函数是处理HTTP请求并返回响应的函数。它们通常使用`flask.request`和`flask.Response`对象来获取请求数据和生成响应。
例如,以下视图函数返回所有用户的列表:
```python
from flask import Flask, jsonify
app = Flask(__name__)
@app.route('/users')
def get_users():
users = ['Alice', 'Bob', 'Carol']
return jsonify(users)
```
`jsonify()`函数将Python数据结构转换为JSON响应。
### 3.3 数据模型和数据库集成
**数据模型**
数据模型是表示应用程序中数据的类。它们定义了数据的结构和行为。Flask使用SQLAlchemy作为其对象关系映射器(ORM),它允许Python对象与数据库表进行交互。
例如,以下数据模型表示`User`表:
```python
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(80), unique=True, nullable=False)
password = db.Column(db.String(120), nu
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python 专栏,这里汇集了丰富的教程和指南,助你轻松踏入 Python 编程世界。从初学者入门到高级技巧,我们涵盖了 Python 的方方面面,包括函数、列表、字典、模块、异常处理、多线程、网络编程、数据分析、机器学习、Web 开发、自动化测试、性能优化、安全编程、并发编程和云计算。无论你是初学者还是经验丰富的开发者,你都能在这里找到有用的资源,提升你的 Python 技能,解锁编程的无限可能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
VisionPro故障诊断手册:网络问题的系统诊断与调试

# 摘要
网络问题诊断与调试是确保网络高效、稳定运行的关键环节。本文从网络基础理论与故障模型出发,详细阐述了网络通信协议、网络故障的类型及原因,并介绍网络故障诊断的理论框架和管理工具。随后,本文深入探讨了网络故障诊断的实践技巧,包括诊断工具与命令、故障定位方法以及
【Nginx负载均衡终极指南】:打造属于你的高效访问入口
.webp)
# 摘要
Nginx作为一款高性能的HTTP和反向代理服务器,已成为实现负载均衡的首选工具之一。本文首先介绍了Nginx负载均衡的概念及其理论基础,阐述了负载均衡的定义、作用以及常见算法,进而探讨了Nginx的架构和关键组件。文章深入到配置实践,解析了Nginx配置文件的关键指令,并通过具体配置案例展示了如何在不同场景下设置Nginx以实现高效的负载分配。
云计算助力餐饮业:系统部署与管理的最佳实践
# 摘要
云计算作为一种先进的信息技术,在餐饮业中的应用正日益普及。本文详细探讨了云计算与餐饮业务的结合方式,包括不同类型和部署模型的云服务,并分析了其在成本效益、扩展性、资源分配和高可用性等方面的优势。文中还提供餐饮业务系统云部署的实践案例,包括云服务选择、迁移策略以及安全合规性方面的考量。进一步地,文章深入讨论了餐饮业务云管理与优化的方法,并通过案例研究展示了云计算在餐饮业中的成功应用。最后,本文对云计算在餐饮业中
【Nginx安全与性能】:根目录迁移,如何在保障安全的同时优化性能
# 摘要
本文对Nginx根目录迁移过程、安全性加固策略、性能优化技巧及实践指南进行了全面的探讨。首先概述了根目录迁移的必要性与准备步骤,随后深入分析了如何加固Nginx的安全性,包括访问控制、证书加密、
RJ-CMS主题模板定制:个性化内容展示的终极指南

# 摘要
本文详细介绍了RJ-CMS主题模板定制的各个方面,涵盖基础架构、语言教程、最佳实践、理论与实践、高级技巧以及未来发展趋势。通过解析RJ-CMS模板的文件结构和继承机制,介绍基本语法和标签使用,本文旨在提供一套系统的方法论,以指导用户进行高效和安全的主题定制。同时,本文也探讨了如何优化定制化模板的性能,并分析了模板定制过程中的高级技术应用和安全性问题。最后,本文展望了RJ-CMS模板定制的
【板坯连铸热传导进阶】:专家教你如何精确预测和控制温度场

# 摘要
本文系统地探讨了板坯连铸过程中热传导的基础理论及其优化方法。首先,介绍了热传导的基本理论和建立热传导模型的方法,包括导热微分方程及其边界和初始条件的设定。接着,详细阐述了热传导模型的数值解法,并分析了影响模型准确性的多种因素,如材料热物性、几何尺寸和环境条件。本文还讨论了温度场预测的计算方法,包括有限差分法、有限元法和边界元法,并对温度场控制技术进行了深入分析。最后,文章探讨了温度场优化策略、
【性能优化大揭秘】:3个方法显著提升Android自定义View公交轨迹图响应速度

# 摘要
本文旨在探讨Android自定义View在实现公交轨迹图时的性能优化。首先介绍了自定义View的基础知识及其在公交轨迹图中应用的基本要求。随后,文章深入分析了性能瓶颈,包括常见性能问题如界面卡顿、内存泄漏,以及绘制过程中的性能考量。接着,提出了提升响应速度的三大方法论,包括减少视图层次、视图更新优化以及异步处理和多线程技术应用。第四章通过实践应用展示了性能优化的实战过程和
Python环境管理:一次性解决Scripts文件夹不出现的根本原因

# 摘要
本文系统地探讨了Python环境的管理,从Python安装与配置的基础知识,到Scripts文件夹生成和管理的机制,再到解决环境问题的实践案例。文章首先介绍了Python环境管理的基本概念,详细阐述了安装Python解释器、配置环境变量以及使用虚拟环境的重要性。随
通讯录备份系统高可用性设计:MySQL集群与负载均衡实战技巧

# 摘要
本文探讨了通讯录备份系统的高可用性架构设计及其实际应用。首先对MySQL集群基础进行了详细的分析,包括集群的原理、搭建与配置以及数据同步与管理。随后,文章深入探讨了负载均衡技术的原理与实践,及其与MySQL集群的整合方法。在此基础上,详细阐述了通讯录备份系统的高可用性架构设计,包括架构的需求与目标、双活或多活数据库架构的构建,以及监
【20分钟精通MPU-9250】:九轴传感器全攻略,从入门到精通(必备手册)

# 摘要
本文对MPU-9250传感器进行了全面的概述,涵盖了其市场定位、理论基础、硬件连接、实践应用、高级应用技巧以及故障排除与调试等方面。首先,介绍了MPU-9250作为一种九轴传感器的工作原理及其在数据融合中的应用。随后,详细阐述了传感器的硬件连
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )