强化学习中的时间差学习:理论与实践的完美结合(完整教程)
发布时间: 2024-08-22 19:26:39 阅读量: 35 订阅数: 40 

无人机.zip
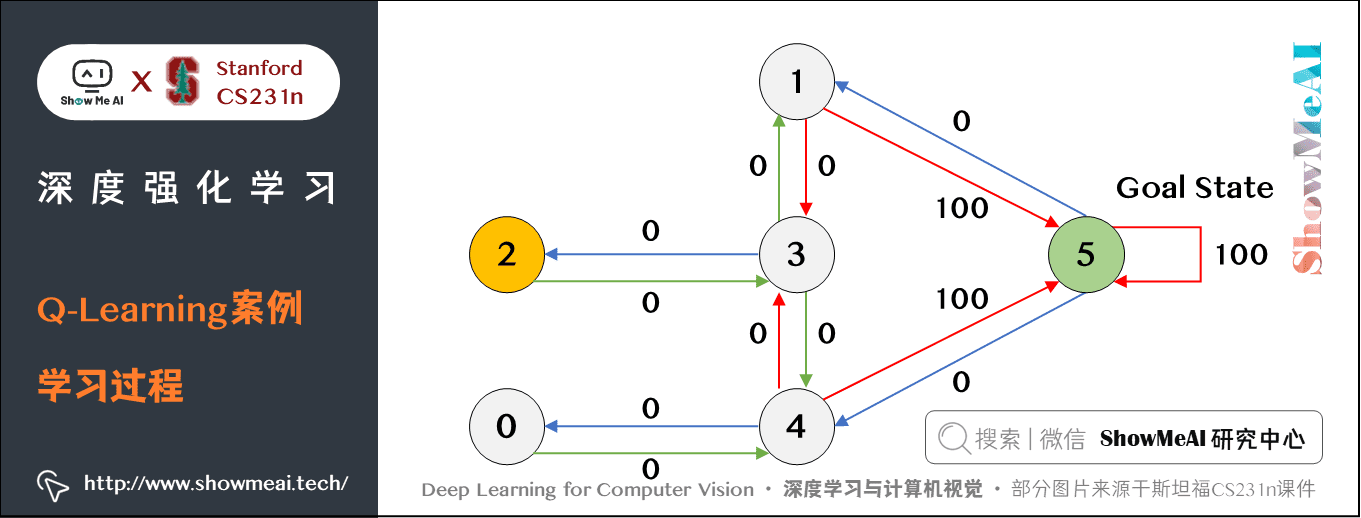
# 1. 时间差学习简介**
时间差学习是一种强化学习技术,它通过估计未来奖励的价值来指导当前决策。与传统监督学习不同,时间差学习不需要明确的标签,而是通过试错来学习最佳行动策略。
时间差学习的关键思想是,当前决策的价值不仅取决于立即奖励,还取决于未来潜在的奖励。通过考虑未来奖励,时间差学习算法可以做出更明智的决策,从而最大化长期回报。
# 2. 时间差学习理论基础
### 2.1 时间差学习的数学原理
时间差学习是一种基于马尔可夫决策过程(MDP)的强化学习方法。MDP是一个五元组(S, A, P, R, γ),其中:
- S是状态空间,包含所有可能的状态。
- A是动作空间,包含所有可能采取的动作。
- P是状态转移概率函数,定义了从状态s采取动作a后进入状态s'的概率。
- R是奖励函数,定义了采取动作a后获得的奖励。
- γ是折扣因子,用于权衡未来奖励的价值。
时间差学习的目标是找到一个策略π,该策略可以最大化从初始状态开始的期望累积奖励。策略π定义了在每个状态下采取的最佳动作。
### 2.2 贝尔曼方程和价值函数
贝尔曼方程是时间差学习的理论基础。它描述了在给定策略π下,从状态s开始的期望累积奖励:
```
V_π(s) = E_π[R_t + γV_π(S_{t+1}) | S_t = s]
```
其中:
- V_π(s)是状态s的价值函数,表示从s开始并遵循策略π的期望累积奖励。
- R_t是时间步t获得的奖励。
- S_{t+1}是时间步t+1的状态。
价值函数可以用来评估策略π的优劣。一个好的策略将具有较高的价值函数。
### 2.3 时间差学习算法
时间差学习算法通过迭代更新价值函数来学习最佳策略。最常用的时间差学习算法包括:
- **Q学习算法:**Q学习算法更新每个状态-动作对的Q值,表示从该状态采取该动作的期望累积奖励。
- **SARSA算法:**SARSA算法与Q学习算法类似,但它使用当前状态和动作来更新Q值,而不是当前状态和所有可能的动作。
#### 代码块:Q学习算法
```python
def q_learning(env, episodes, learning_rate, discount_factor):
"""
Q学习算法
参数:
env: 强化学习环境
episodes: 训练回合数
learning_rate: 学习率
discount_factor: 折扣因子
"""
# 初始化Q表
q_table = np.zeros((env.observation_space.n, env.action_space.n))
for episode in range(episodes):
# 重置环境
state = env.reset()
# 循环直到终止状态
while True:
# 根据Q表选择动作
action = np.argmax(q_table[state, :])
# 执行动作并获取奖励和下一状态
next_state, reward, done, _ = env.step(action)
# 更新Q表
q_table[state, action] += learning_rate * (reward + discount_factor * np.max(q_table[next_state, :]) - q_table[state, action])
# 更新状态
state = next_state
# 如果终止状态,则退出循环
if done:
break
return q_table
```
#### 代码逻辑分析:
- `q_learning`函数接受环境、训练回合数、学习率和折扣因子作为参数。
- 它初始化一个Q表,其中每个元素表示状态-动作对的Q值。
- 对于每个训练回合,它从环境的初始状态开始。
- 在每个时间步,它根据当前Q表选择动作。
- 它执行动作并获取奖励和下一状态。
- 它使用Q学习更新公式更新Q表。
- 它更新状态并重复该过程

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了强化学习中的时间差学习,这一时序建模利器。专栏涵盖了时间差学习的原理、应用场景、算法选择、性能优化、实战指南和案例研究。通过权威指南、详细解析、专家建议和完整教程,专栏从入门到精通,全面解读了时间差学习在强化学习中的应用。专栏还探讨了时间差学习的优势、局限和理论与实践的结合,为读者提供了深入理解和应用这一重要技术的全面指南。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
霍尼韦尔SIS系统性能优化大揭秘:可靠性提升的关键步骤

# 摘要
霍尼韦尔安全仪表系统(SIS)作为保障工业过程安全的关键技术,其性能优化对于提高整体可靠性、可用性和可维护性至关重要。本文首先介绍了SIS系统的基础知识、关键组件
【Ansys电磁场分析】:掌握网格划分,提升仿真准确度的关键
# 摘要
本文详细探讨了Ansys软件中电磁场分析的网格划分技术,从理论基础到实践技巧,再到未来发展趋势。首先,文章概述了网格划分的概念、重要性以及对电磁场分析准确度的影响。接着,深入分析了不同类型的网格、网格质量指标以及自适应技术和网格无关性研究等实践技巧。通过案例分析,展示了网格划分在平面电磁波、复杂结构和高频电磁问题中的应用与优化策略。最后,讨论了网格划分与仿真准确度的关联,并对未来自动网
故障排查的艺术:H9000系统常见问题与解决方案大全

# 摘要
H9000系统作为本研究的对象,首先对其进行了全面的概述。随后,从理论基础出发,分析了系统故障的分类、特点、系统日志的分析以及故障诊断工具与技巧。本研究深入探讨了H9000系统在实际运行中遇到的常见问题,包括启动失败、性能问题及网络故障的排查实例,并详细阐述了这些问题的解决策略。在深入系统核心的故障处理方面,重点讨论
FSCapture90.7z跨平台集成秘籍:无缝协作的高效方案
# 摘要
本文旨在详细介绍FSCapture90.7z软件的功能、安装配置以及其跨平台集成策略。首先,文中对FSCapture90.7z的基本概念、系统要求和安装步骤进行了阐述,接着探讨了配置优化和文件管理的高级技巧。在此基础上,文章深入分析了FSCapture90.
【N-CMAPSS数据集深度解析】:实现大规模数据集高效存储与分析的策略
# 摘要
N-CMAPSS数据集作为一项重要资源,提供了深入了解复杂系统性能与故障预测的可能性。本文首先概述了N-CMAPSS数据集,接着详细探讨了大规模数据集的存储与分析方法,涵盖了存储技术、分析策略及深度学习应用。本文深入研究了数据集存储的基础、分布式存储系统、存储系统的性能优化、数据预处理、高效数据分析算法以及可视化工具的使用。通过案例分析,本文展示了N
【Spartan7_XC7S15硬件设计精讲】:精通关键组件与系统稳定性
# 摘要
本文对Xilinx Spartan7_XC7S15系列FPGA硬件进行了全面的分析与探讨。首先概述了硬件的基础架构、关键组件和设计基础,包括FPGA核心架构、输入/输出接口标准以及电源与散热设计。随后,本文深入探讨了系统稳定性优化的策略,强调了系统级时序分析、硬件故障诊断预防以及温度和环境因素对系统稳定性的影响。此外,通过案例分析,展示了S
MAX7000芯片时序分析:5个关键实践确保设计成功

# 摘要
本文系统地介绍了MAX7000芯片的基础知识、时序参数及其实现和优化。首先概述了MAX7000芯片的基本特性及其在时序基础方面的重要性。接着,深入探讨了时序参数的理论概念,如Setup时间和Hold时间,时钟周期与频率,并分析了静态和动态时序分析方法以及工艺角对时序参数
Acme财务状况深度分析:稳健增长背后的5大经济逻辑

# 摘要
本论文对Acme公司进行了全面的财务分析,涵盖了公司的概况、收入增长、盈利能力、资产与负债结构以及现金流和投资效率。通过对Acme主营业务的演变、市
机器人集成实战:SINUMERIK 840D SL自动化工作流程高效指南
# 摘要
本文旨在全面介绍SINUMERIK 840D SL自动化系统,从理论基础与系统架构出发,详述其硬件组件和软件架构,探讨自动化工作流程的理论以及在实际操作中的实现和集成。文中深入分析了SINUMERIK 840D SL的程序设计要点,包括NC程序的编写和调试、宏程序及循环功能的利用,以及机器人通信集成的机制。同时,通过集成实践与案例分析,展示自动化设备集成的过程和关键成功因素。此外,本文还提出了维护与故障诊断的策略,并对自动化技术的未来趋势与技术创新进行了展望。
# 关键字
SINUMERIK 840D SL;自动化系统;程序设计;设备集成;维护与故障诊断;技术革新
参考资源链接:
单片机与HT9200A交互:数据流与控制逻辑的精妙解析

# 摘要
本文旨在全面介绍单片机与HT9200A芯片之间的交互原理及实践应用。首先概述了单片机与HT9200A的基本概念和数据通信基础知识,随后深入解析了HT9200A的串行通信协议、接口电路设计以及关键引脚功能。第二部分详细探讨了HT9200A控制逻辑的实现,包括基本控制命令的发送与响应、复杂控制流程的构建,以及错误检测和异常处理机制。第三章将理论应用于实践,指导读者
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )