【GBFF文件应用最佳实践】:行业案例深度分享
发布时间: 2024-11-29 01:03:53 阅读量: 24 订阅数: 27 

参考资源链接:[解读GBFF:GenBank数据的核心指南](https://wenku.csdn.net/doc/3cym1yyhqv?spm=1055.2635.3001.10343)
# 1. GBFF文件格式概述
## 1.1 GBFF文件定义
GBFF(Generic Binary File Format)是一种通用的二进制文件格式,常用于数据密集型的应用中以提高存储效率和访问速度。其设计原则是兼顾跨平台兼容性和高效数据处理能力。GBFF格式特别适合于需要快速读写的场景,如实时数据处理、大数据分析等。
## 1.2 文件格式特点
GBFF文件格式具有以下特点:
- **高效性**:它使用二进制格式存储,相较于文本格式,减少了存储空间和提高了读写速度。
- **灵活性**:支持不同类型和大小的数据结构,包括复杂的数据嵌套和多维数组。
- **扩展性**:容易进行读写扩展,可以适应不同的应用需求和未来的升级。
## 1.3 文件格式结构
GBFF文件由以下几个关键部分组成:
- **头部信息**:包含文件版本、创建时间、数据类型定义等元数据。
- **数据块**:实际存储数据的地方,可以包含多个数据块,每个数据块由一系列的字节序列组成,以实现不同类型数据的存储。
- **索引信息**:为数据块提供快速检索机制,允许应用程序直接跳转到需要的数据。
了解GBFF文件格式为后续的处理打下基础,从下一章开始,我们将深入探讨GBFF文件的结构解析、读写操作以及文件的验证和校验等内容。
# 2. GBFF文件处理基础
### 2.1 GBFF文件结构解析
#### 2.1.1 标签和属性的理解
GBFF(Generic Binary File Format)是一种通用的二进制文件格式,它支持复杂的自定义标签系统和属性。理解标签和属性对于正确读取和解析GBFF文件至关重要。标签是指在GBFF文件中用于标识数据块类型的标识符。每个标签都与特定的数据类型相关联,比如整数、浮点数、字符串等。
例如,在GBFF文件中,一个表示客户ID的数据块可能会有一个特定的标签,比如`<cid:001>`,而这个标签可能会被定义为一个32位整数。属性则是额外的信息,提供了标签的上下文。比如,数据的创建时间、修改时间或数据所属的业务单元等。
```python
# Python示例代码:读取GBFF文件中的标签和属性
# 假设有一个函数read_tag()可以读取标签和相关的数据长度
def parse_tags_from_gbff(file_path):
tags = []
with open(file_path, 'rb') as gbff_file:
while True:
tag_info = read_tag(gbff_file)
if not tag_info:
break # 读到文件末尾
tags.append(tag_info)
return tags
# 读取标签信息(假设read_tag()是自定义函数,用于读取标签和数据长度)
tag_info = read_tag(gbff_file)
# tag_info可能是一个包含标签和数据长度的元组
tag, length = tag_info
# 打印标签和数据长度
print(f"Tag: {tag}, Length: {length}")
```
#### 2.1.2 数据块的组织和管理
在GBFF文件中,数据块是实际存储数据的单元,每个数据块由一个标签开始,后跟数据本身,最后是结束标识。数据块的组织和管理是理解文件结构的关键。数据块的大小可能会变化,这取决于数据的内容。
例如,一个简单的数据块可能包含用户的名字,其格式如下:
- 标签(如`<name:001>`)
- 数据长度(表示接下来有多少字节是数据内容)
- 数据内容(如字符串"John Doe")
- 结束符(通常是一个特定的字节序列,比如`0x0A`)
```python
# 该代码块将读取一个数据块的内容并分析其结构
def read_data_block(gbff_file):
data_block = {}
# 读取标签和长度信息
tag_info = read_tag(gbff_file)
if not tag_info:
return None # 如果读取失败,返回None
tag, length = tag_info
data_block['tag'] = tag
data_block['length'] = length
# 读取数据内容
data_content = gbff_file.read(length)
data_block['content'] = data_content
# 检查结束标识并确认数据块读取完成
end_marker = gbff_file.read(1)
assert end_marker == b'\x0A', 'Expected end marker not found'
data_block['end_marker'] = end_marker
return data_block
# 读取数据块
data_block = read_data_block(gbff_file)
# 打印数据块信息
print(data_block)
```
### 2.2 GBFF文件读写操作
#### 2.2.1 使用标准库进行文件读取
使用标准库进行GBFF文件的读取是基础操作,Python中的`open`函数配合`read`和`readinto`方法是常用的方式。在处理二进制文件时,需要特别注意字节序(endianess)和数据类型的转换。
```python
# Python示例代码:使用标准库读取GBFF文件
def read_gbff_with_standard_library(file_path):
with open(file_path, 'rb') as gbff_file:
# 读取文件所有内容到缓冲区
buffer = gbff_file.read()
# 处理缓冲区内容...
pass
# 读取GBFF文件
read_gbff_with_standard_library('example.gbff')
```
#### 2.2.2 高级文件写入技巧
在处理GBFF文件的写入操作时,不仅要关注数据格式的正确性,还需要考虑性能优化。一种常见的技巧是使用内存映射文件(memory-mapped file),它可以在不实际读取所有数据到内存的情况下对文件进行操作。这对于处理大型GBFF文件特别有用。
```python
# Python示例代码:使用内存映射文件写入GBFF数据
import mmap
def write_gbff_with_memory_mapping(file_path, data):
# 打开文件以供读写
with open(file_path, 'r+b') as gbff_file:
# 创建内存映射对象
with mmap.mmap(gbff_file.fileno(), 0) as gbff_map:
gbff_map.write(data)
# 写入GBFF数据
write_gbff_with_memory_mapping('example.gbff', 'data_to_write')
```
### 2.3 GBFF文件的验证和校验
#### 2.3.1 校验工具和方法
为了保证GBFF文件的数据完整性和一致性,通常需要使用校验工具进行文件校验。这些工具可能利用诸如哈希算法(如SHA256)来验证文件内容。
```python
import hashlib
# Python示例代码:计算GBFF文件的SHA256哈希值
def calculate_sha256(file_path):
hash_value = hashlib.sha256()
with open(file_path, 'rb') as gbff_file:
# 读取文件内容并更新哈希值
for chunk in iter(lambda: gbff_file.read(4096), b""):
hash_value.update(chunk)
return hash_value.hexdigest()
# 计算并打印GBFF文件的SHA256哈希值
sha256_hash = calculate_sha256('example.gbff')
print(f"SHA256: {sha256_hash}")
```
#### 2.3.2 常见错误类型及修复
在处理GBFF文件时,可能会遇到各种错误,如格式错误、数据损坏或文件不完整等。对于这类问题,通常需要具备专门的修复工具或方法来解决。有时,手动校验和修复是必要的。
```python
# Python示例代码:检测并修复GBFF文件中的常见错误
def repair_gbff(file_path, repair_tool_path):
# 调用校验工具进行检测
process = subprocess.Popen([repair_tool_path, file_path], stdout=subprocess.PIPE, stderr=subprocess.PIPE)
stdout, stderr = process.communicate()
if process.returncode != 0:
# 错误代码,尝试修复
process = subprocess.Popen([repair_tool_path, '--fix', file_path], stdout=subprocess.PIPE, stderr=subprocess.PIPE)
process.communicate()
pr
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0

专栏简介
欢迎来到“GBFF文件格式解析”专栏,您的全面指南,深入了解GBFF文件格式的方方面面。从基础到高级应用,我们将为您提供精通指南,揭开GBFF的秘密。掌握字节到字段的深度解析技巧,了解工具和环境搭建的秘籍。探索自主编写GBFF解析器的技术进阶和编码实践。揭秘编码规则和数据压缩机制,提升文件安全性,并分享行业最佳实践。学习编程和性能优化技巧,了解标准化流程,探索GBFF在大数据中的角色。应对大规模解析挑战,分析GBFF与其他格式的比较。了解GBFF在云存储中的应用和挑战,深入解析字段类型和处理技巧。发现GBFF在机器学习数据准备中的应用,掌握元数据管理和数据完整性策略。解决错误处理问题,自动化测试,并找到跨平台解析的终极解决方案。通过深入的案例研究、实用技巧和专家见解,本专栏将为您提供全面解析GBFF文件格式所需的知识和技能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【松下PLC与HMI交互艺术】:设计完美人机界面

# 摘要
本文旨在深入探讨松下PLC与HMI(人机界面)的基础知识、交互原理、设计实践以及高级应用。首先介绍了PLC与HMI的基本概念和工作原理,然后详细阐述了它们之间的数据通信类型、协议和实现方式。文章还探讨了设计人机界面时应遵循的基本原则、步骤和优化策略。在高级应用方面,本文讨论
TSPL性能优化实践:剖析性能瓶颈与20种实用解决方案
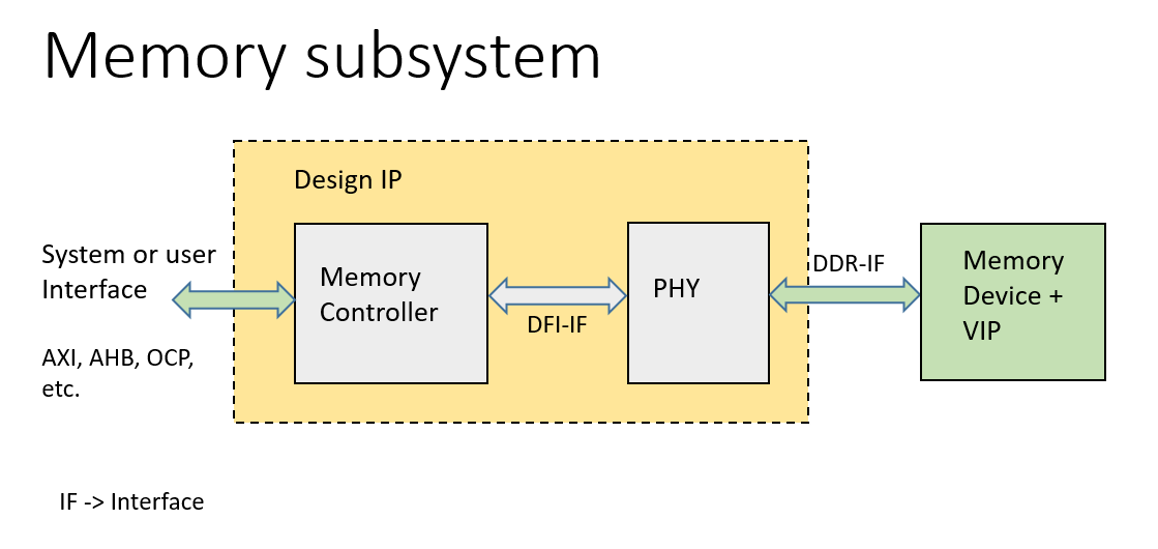
# 摘要
本文全面概述了TSPL(Transcendental Simplified Programming Language)的性能优化方法和实践技巧。首先介绍了性能优化的基本理论和重要性,接着探讨了分析性能瓶颈的方法论,包括工具使用和性能数据处理。第三章详细介绍了代码级和系统架构级的优化策略,强调了代码剖析、算法选择、资源分配和并发控制对性能提升的关键作用。第四章通过案
远程桌面管理新境界:RDSH与RDPWrap-v1.6.2的协同之道
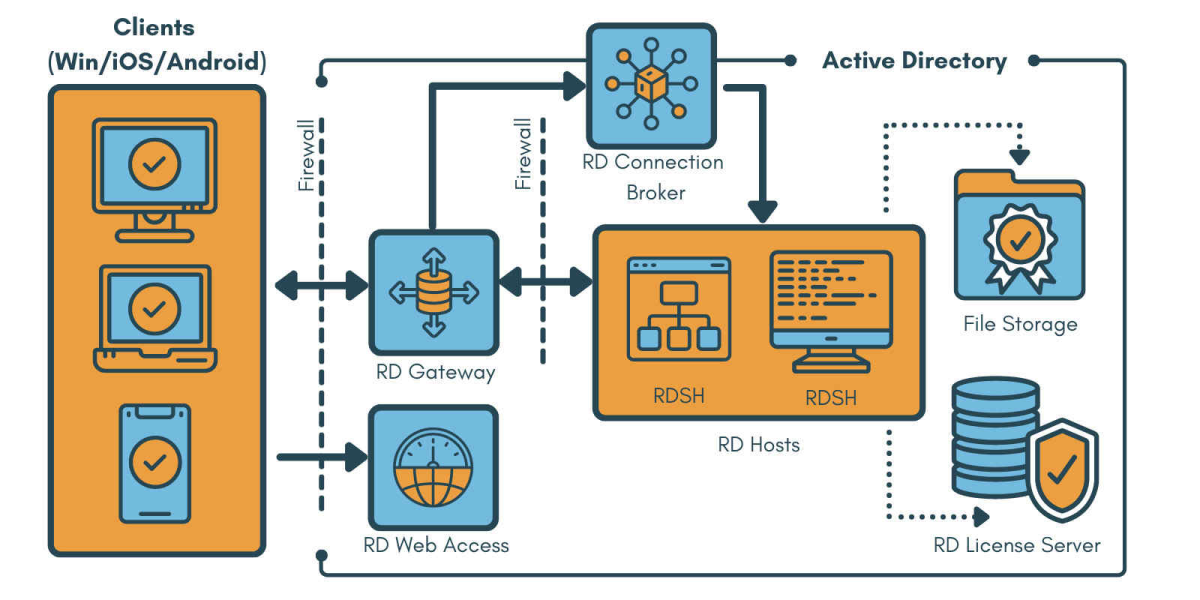
# 摘要
本文首先介绍了远程桌面协议(RDP)与远程桌面服务(RDSH)的基础知识,随后深入探讨了RDSH的工作机制及其优势,并分析了其在不同行业和企业场景中的应用。接着,文章详细说明了RDPWrap-v1.6.2的安装和高级配置过程,以及如何与RDSH协同工作以优化用户体验。文章还探讨了远程桌面管理的实践案例,包括大规模
提升AAO工程设计效率的软件工具与技术:让工程设计更加高效

# 摘要
AAO工程设计是一个复杂的过程,涉及多学科知识的综合应用与技术创新。本文对AAO工程设计的理论基础、效率提升、软件工具应用、实践策略以及未来趋势进行了全面探讨。通过分析工程设计流程与效率的关系,阐述了软件工程原则在提升设计效率中的作用。文章还探讨了高效设计软件工具如CAD/CAM和BIM技术在工程中的应用,并提出了一系列设计优化的实践策略,包括自动化、面向对象设
【渗透测试】:针对TRS-MAS系统testCommandExecutor.jsp漏洞的测试与防御

# 摘要
本论文首先对渗透测试的基础知识以及TRS-MAS系统的业务功能和架构进行了概述,接着深入分析了testCommandExecutor.jsp漏洞的发现、危害、技术原理和利用方法。通过具体实践技巧的探讨,本文指导如何搭建测试环境、复现漏洞并进行分析记录。进一步地,文章提出了漏洞防御策略与实践措施,并对防御效果的评估与监控提供了方法。最后,总结了渗透测试在网络安全中的
紧急疏散秘籍:AnyLogic行人流动模拟在危机中的应用

# 摘要
本文深入探讨了紧急疏散的理论基础以及AnyLogic软件在行人流动模拟中的应用和实践。首先介绍了紧急疏散模拟的重要性及其理论基础,然后详细阐述了A
华为企业架构设计案例深度解析:掌握企业架构设计挑战的终极解决方案
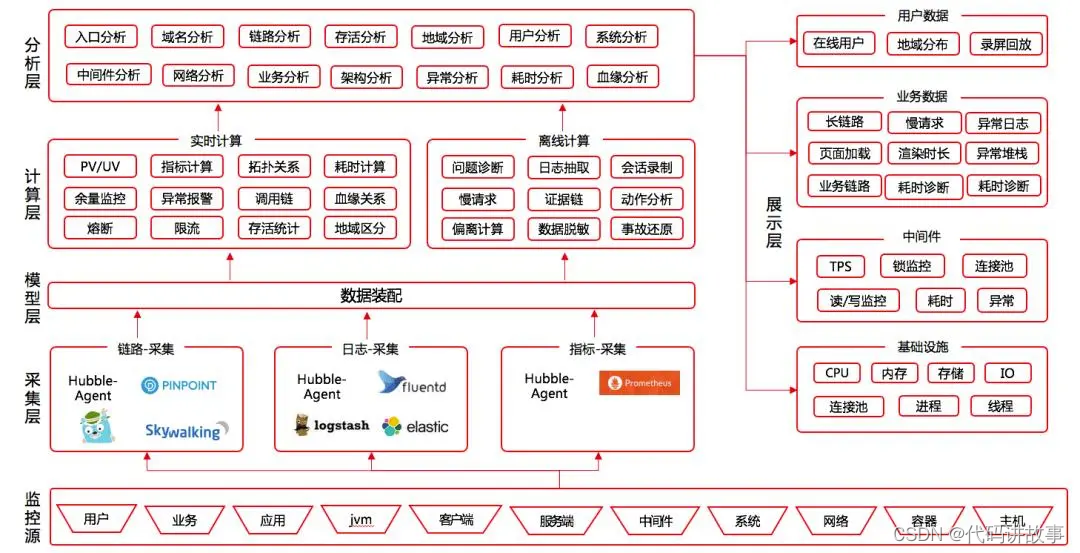
# 摘要
本文旨在探讨华为企业架构设计的现状和实践。第一章简要介绍了华为企业架构设计的整体概述,第二章则深入探讨了企业架构设计的理论基础,包括企业架构的定义、重要性、国际标准以及架构设计的关键原则和模式。第三章通过分析华为的实例,展示了企业在业务能力分析、技术架构构建和数据架构与治理方面的具体实践。接着,第四章讨论了在企业架构设计过程中遇到的挑战和相应的解决方案,重点在于组织结
【快速定位问题】:Oracle EBS故障排除与常见问题解决

# 摘要
Oracle E-Business Suite (EBS)作为广泛部署的企业级商务应用软件,其稳定性与性能对业务连续性至关重要。本文主要介绍Oracle EBS的故障排除、系统监控与日志分析、故障诊断流程、问题解决策略以及预防措施与优化建议。通过对监控工具的配置、日志文件的分析、系统故障的诊断与定位,以及针对性的问题解决方法,本文旨在提供一套完整的Oracle EBS维护和故障处理框架。同时,本文强调了建立故
【TP9950芯片故障排除】:视频监控故障不再怕,常见问题与解决方案指南

# 摘要
本文对TP9950芯片的功能、在视频监控系统中的作用及其故障定位与诊断进行了全面分析。首先介绍了TP9950芯片概述,接着分析了其在视频监控系统中扮演的角色,包括系统结构、基本功能以及故障诊断基础。第三章和第四章详细探讨了TP9950芯片常见故障类型、故障分析与诊断策略,并提出了软件和硬件层面的故障排除方法。第五章提出了预防措施与维护策略,以减少故障发生的可能性。
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )